快速理解数据库中的索引(Indexes in Database)
摘要
关于数据库中的索引有很多文章,本文希望向读者提供一个对索引的快速认识途径,以及对相关问题的全面陈述,另外,本文是为讨论JDO下索引问题的引文。
索引的基本价值
索引的根本目的是快速检索,我们以一个例子来说明,索引如何做到这一点,我们假定有一张产品数据表product(id,name,location,price),并且当每一个新的product插入到产品这个表中,就会放到最后一行。在这种情况下,当我们根据产品名搜索一条产品记录时,如:“SELECT * FROM product WHERE name='tea'”,数据库就会从该表的第一行开始一个一个地去查找相匹配的名字。如果,这种请求非常之多,那么这种查询方式就显得很低效了,那么,索引是是解决这个问题的好办法。
首先,我们可以通过"CREATE INDEX product_name_index ON product(name)",就可以创建一个关于product的name的索引了,建立了这个索引以后,直观上来看,数据库系统会建立一个新的表,这个表只有一列,就是指向所有的product中name的指针,如下图所示,实际上,后台还会建立一个相应的数据结构如B+Tree,以为快速检索提供基础,当发起查询请求时,如:“SELECT * FROM product WHERE name='tea'”,数据库就直接再product_name_index的基础上执行检索(也称搜索、查询)算法,然后快速地找到tea的记录。
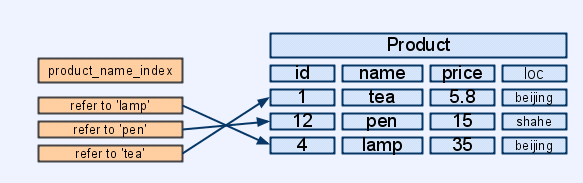
组合索引
我们进一步来看我们的需求,当我们想执行这样的检索就是“SELECT * FROM product WHERE name='tea' AND loc='beijing'”,那么这个时候,product_name_index在一定程度上还能起作用,当检索'tea' AND ’beijing‘ 时,数据库系统可以帮你快速找到所有的tea,在这个例子里,就只有一条,然后比较产地找出最终结果,但是,当我们对price和loc进行联合搜索时,如:SELECT * FROM Product WHERE price >1 AND price < 50 AND loc = 'beijing',我们若只对某一列单独建立索引,及product_price_index和product_loc_index,在联合查询的时候,数据库可以先分别根据各列的单独索引分别快速定位相应的记录,如找到对应价格的所有条目,和相应产地的所有条目,然后再将两组记录放到一起,逐一比对,这个时候,若两组记录数目极大,那么这个逐一比对过程变得非常耗时,单独索引就不能完成对联合查询的加速任务,这是我们需要采用新的手段,那就是:组合索引。我们可以通过 CREATE INDEX product_price_loc ON product(price, loc) 建立price和loc的组合索引,该索引会为每个组合建立一条记录指向product中的各条记录
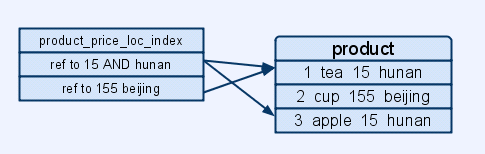
聚簇索引
诸位注意我们前面这些问题的前提“当每一个新的product插入到产品这个表中,就会放到最后一行”,也就是说,真正的所有的记录在物理存储上是乱序的,如果在物理存储上做改进,我们能否做到更快呢? 答案是肯定的。那就是聚簇索引,聚簇索引实际上是告诉数据库系统,我们这个表应该怎样存储以便我去查询,所以一个表只能有一个聚簇索引,因为只能有一种物理存储方式。这样有的人就将索引分成了聚簇索引和非聚簇索引两类,[4]中给出了一个关于聚簇索引和非聚簇索引示例性的比较。
进一步阅读
看过本文之后,如果你对文章的易读性有什么意见欢迎大家在下面留言,关于索引的更高级议题,大家可以参考Oracle or Mysql等数据库的索引实战,索引建立的原则,另有图书《关系型数据库索引的设计与优化》。
参考文献
[1] http://en.wikipedia.org/wiki/Index_(database)
[2] http://www.websitedatabases.com/database-index.html
[3] http://www.builder.com.cn/2007/0913/504260.shtml
[4] http://www.cnblogs.com/zhenyulu/articles/25794.html
[5] http://20bits.com/articles/interview-questions-database-indexes/

