
软工1816 · 作业(五)结对项目2
Github 项目地址
具体分工
- 王源 : 主要框架设计、 内容过滤实现、 权重功能实现、 输出个数功能实现、 词组功能实现、编写文档
- 佘岳昕 : 爬虫设计、爬虫实现、命令行解析实现、给队友精神上的支持、编写文档
代码规范
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 15 | 8 |
| · Estimate | · 估计这个任务需要多少时间 | 15 | 8 |
| Development | 开发 | 1355 | 1605 |
| · Analysis | · 需求分析 (包括学习新技术) | 30 | 30 |
| · Design Spec | · 生成设计文档 | 40 | 20 |
| · Design Review | · 设计复审 | 20 | 20 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 15 | 15 |
| · Design | · 具体设计 | 800 | 950 |
| · Coding | · 具体编码 | 310 | 400 |
| · Code Review | · 代码复审 | 20 | 20 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 120 | 150 |
| Reporting | 报告 | 120 | 85 |
| · Test Repor | · 测试报告 | 115 | 10 |
| · Size Measurement | · 计算工作量 | 20 | 15 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 90 | 60 |
| | 合计 | 1490 | 1698
解题思路描述 && 设计实现说明
拿到题目后,我们首先基于各自的框架思考了一下如何实现,并进行对比。从而得出第一张初步的流程图。
经过了n次迭代以及代码完成后的细节修补↓, 终于得到了最后的类图,见后面的部分。

爬虫使用说明
最开始打算采取的是C++爬虫,后来国庆跟家里出去旅游花了一半的时间之后,试了一天发现再开始学习来不及了,所以最终采用了python编写爬虫。爬完之后发现队友很给力其他任务都做完了,然后想了想不甘心只用了python,突然想起之前用过java爬过,故另写了一版java的爬虫。
python爬虫流程图

爬虫主要代码:(python版)
//打开链接
page = request.Request(url, headers=headers)
titles = soup.find_all(href=re.compile(".html")) # 查找所有a标签中.html的语句
# 打印查找到的每一个a标签的string
f = open("result.txt","w",encoding='utf-8')
i = -1
for title in titles:
i = i+1
print("Number:"+str(i))
print('Title:'+title.string)
f.write(str(i)+'\n')
f.write('Title: '+title.string+'\n')
pUrl = r'http://openaccess.thecvf.com/'+ (title.get('href'))
pPage = request.Request(pUrl, headers=headers)
pPage_info = request.urlopen(pPage).read()
pPage_info = pPage_info.decode('utf-8')
pSoup = BeautifulSoup(pPage_info, 'html.parser')
pAbstracts = pSoup.find_all(id = 'abstract')
for abstract in pAbstracts:
#print(abstract.string[1:])
f.write('Abstract: '+abstract.string[1:]+'\n')
f.write('\n')
f.write('\n')
f.close()
(java版)
//从一个网站获取和解析一个HTML文档
Document document = Jsoup.connect(resourceURL).get();
//获取所有的连接图片
Elements elements = document.select("a[href]");
PrintWriter printWriter =new PrintWriter(new FileWriter("E:/a.txt",true),true);//第二个参数为true,从文件末尾写入 为false则从开
for(Element element : elements) {
//筛选论文链接
if (element.attr("abs:href").endsWith(".html")) {
count=count+1;
String paperUrl = element.attr("abs:href");
System.out.println(paperUrl);
Document paperDoc = Jsoup.connect(paperUrl).get();
printWriter.println(count);
System.out.println(count);
//打印论文标题
Elements paperTitles = paperDoc.select("#papertitle");
for(Element paperTitle : paperTitles) {
System.out.println(paperTitle.text());
printWriter.println("Title: "+paperTitle.text());
}
//打印论文摘要
Elements paperAbs = paperDoc.select("#abstract");
for(Element paperAbstract : paperAbs) {
System.out.println(paperAbstract.text());
printWriter.println("Abstract: "+paperAbstract.text());
}
printWriter.println("\n");
printWriter.println("\n");
}
代码组织与内部实现设计
类图
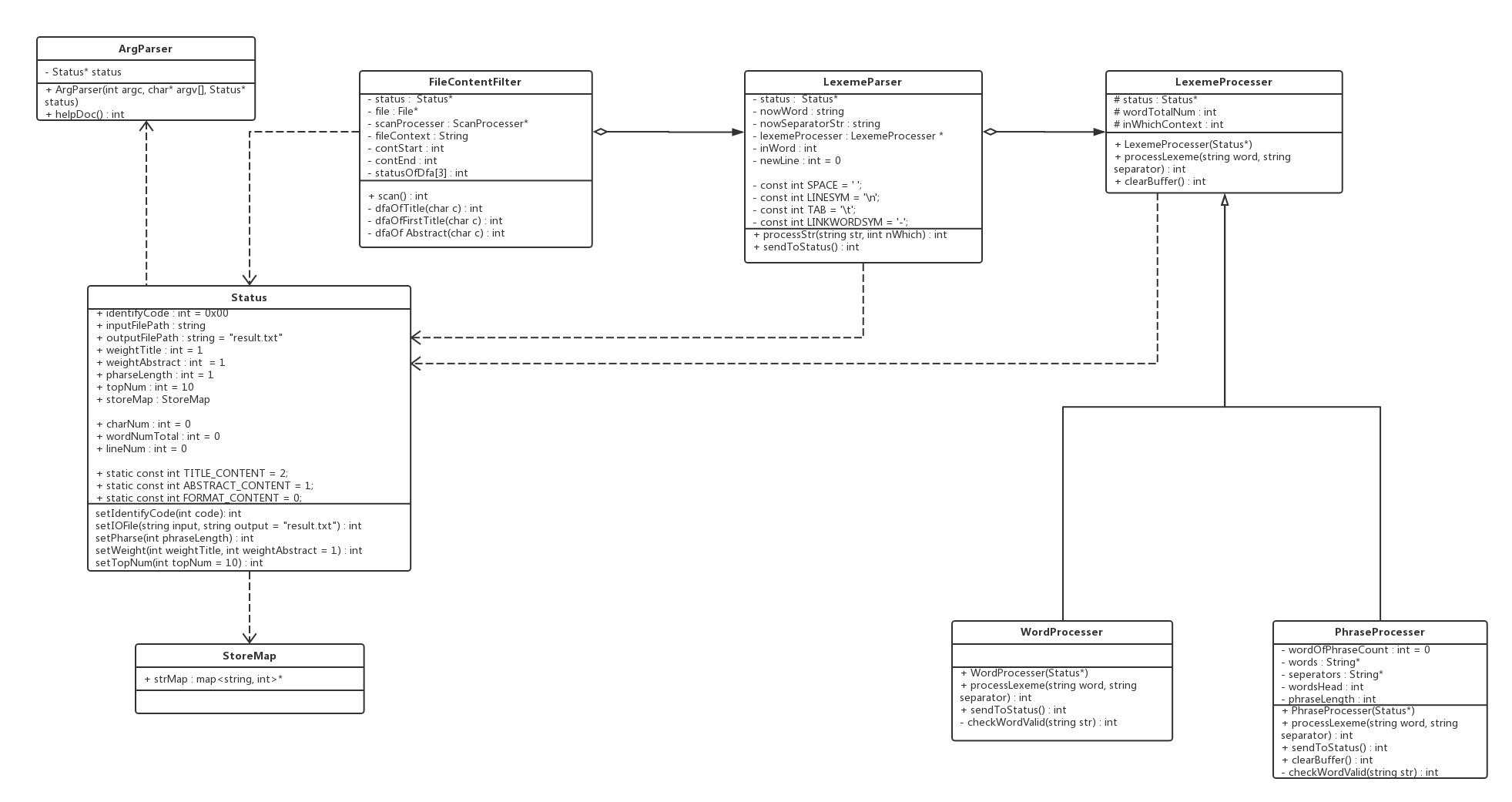
Status类
存储各个设置、运行结果、常量
ArgParse类
解析用户的输入参数并验证其合法性,根据解析结果设置Status类
FileContentFilter类
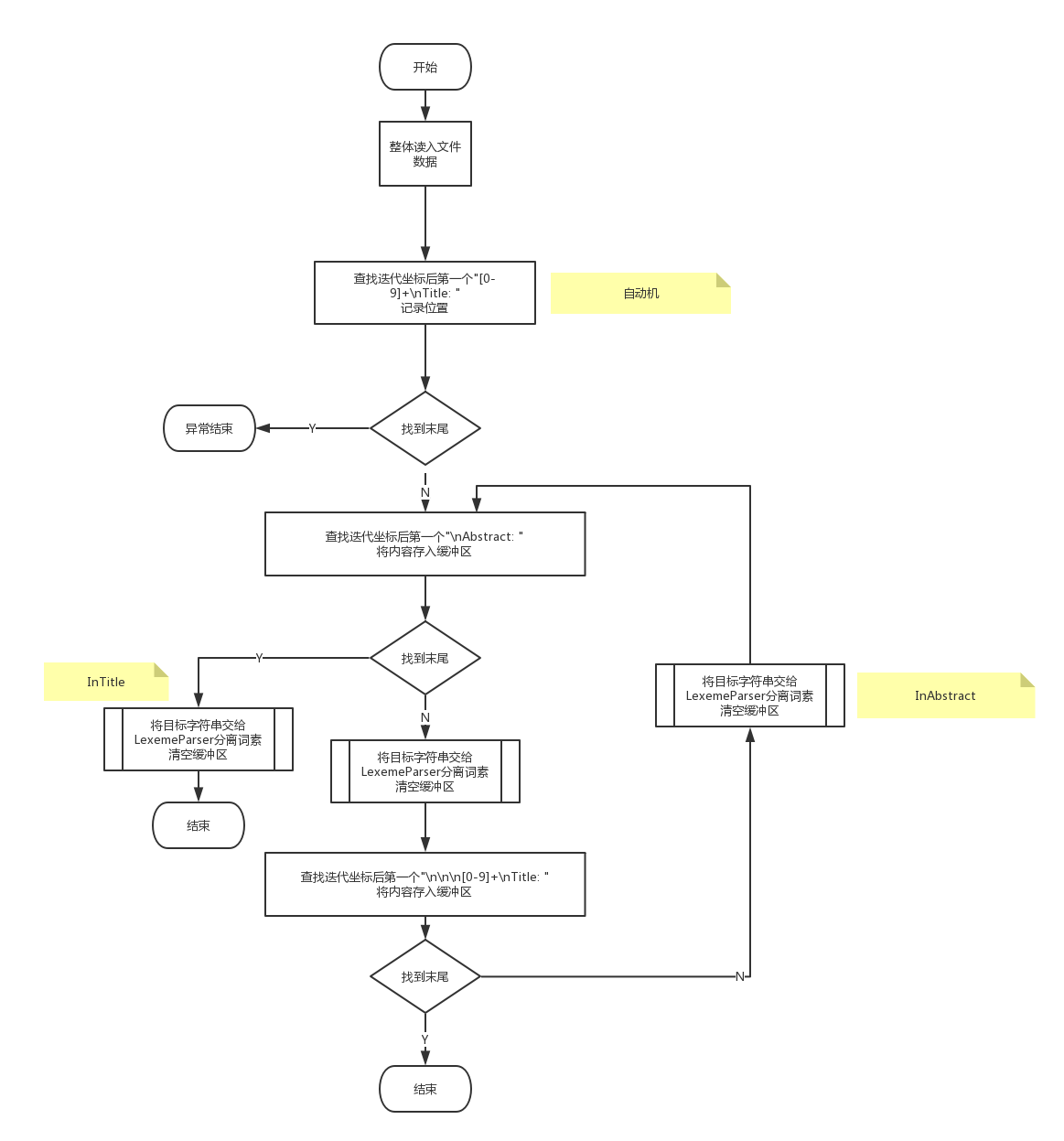
过滤输入文件中"Title: "等无用部分,分割"Title"串和"Abstract"串,将串送给LexemeParser类
LexemeParser类
- 分离字符串为字母串和分隔符串(对换行符特殊处理),送给
LexemeProcesser类 - 统计字符总数、行数

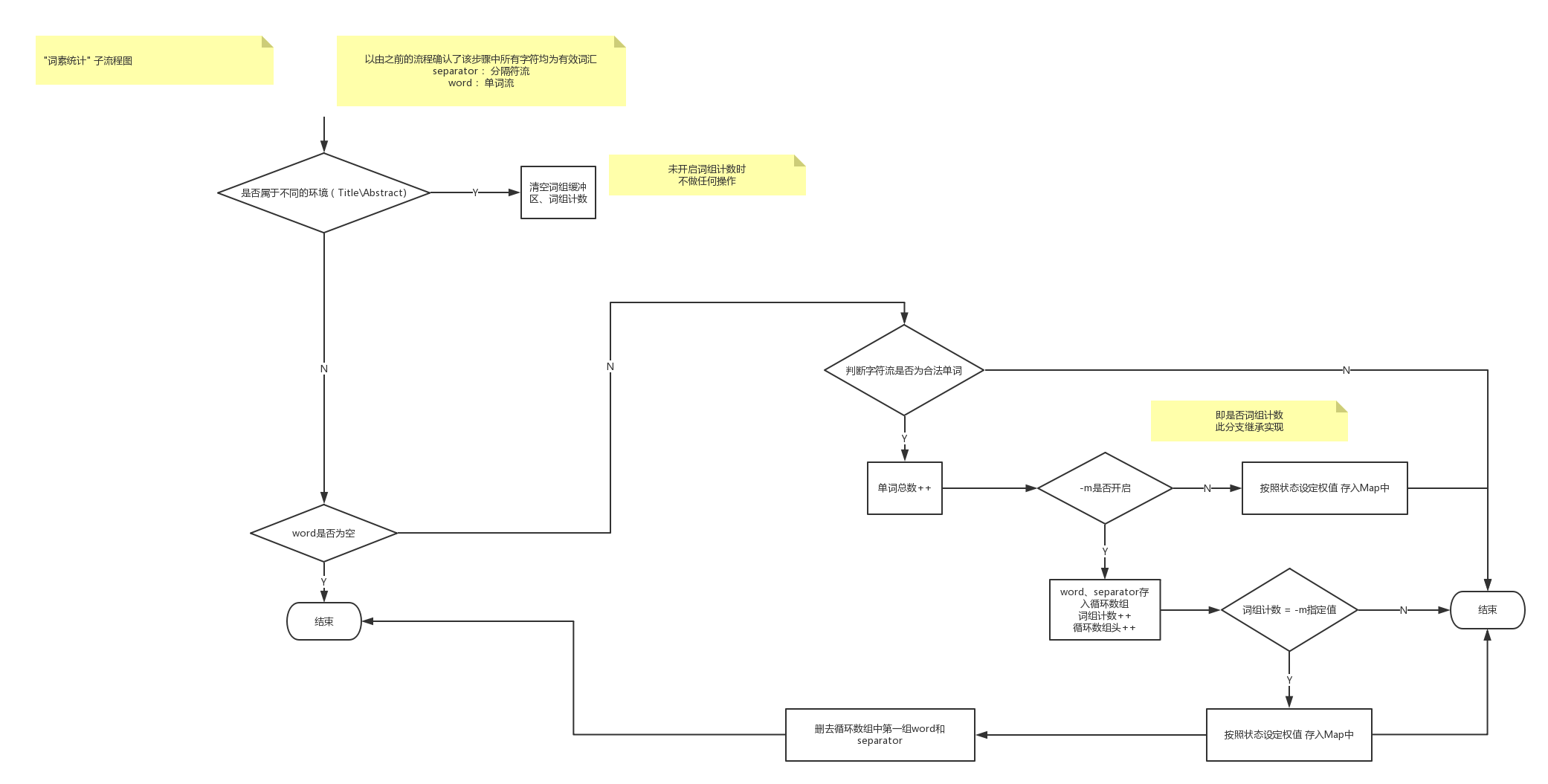
LexemeProcesser类
WordProcesser类和PhraseProcesser类的父类- 对字母串和分隔符串组成的词素进行合法性判断, 并存储
附加题设计与展示
设计的创意独到之处
对一个文件列表生成热词报告,生成热词图。
实现思路
将文件列表送入主程序中,通过'-g'选项生成本过程所需数据。之后借助ECharts生成图表。
实现成果展示
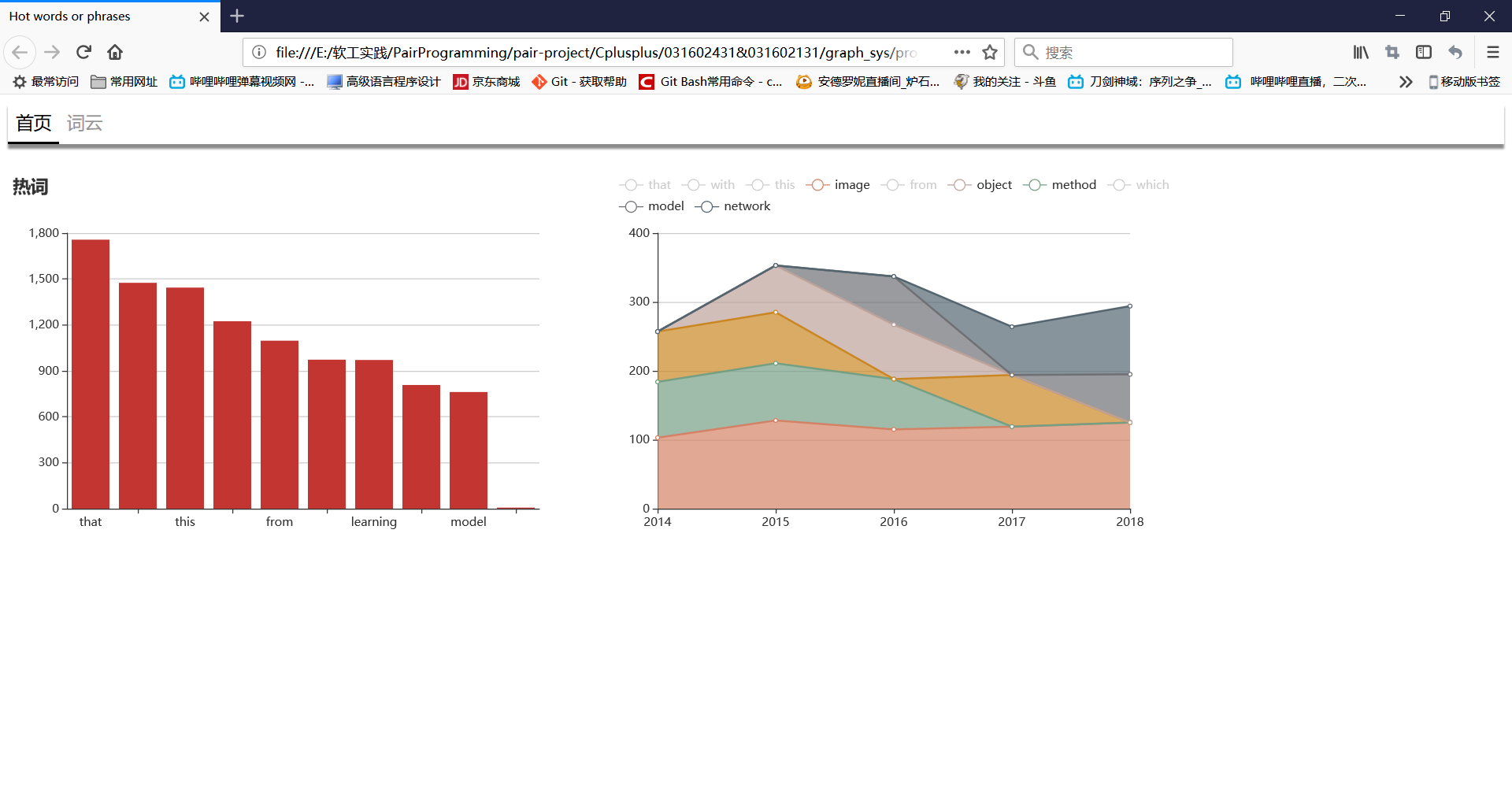
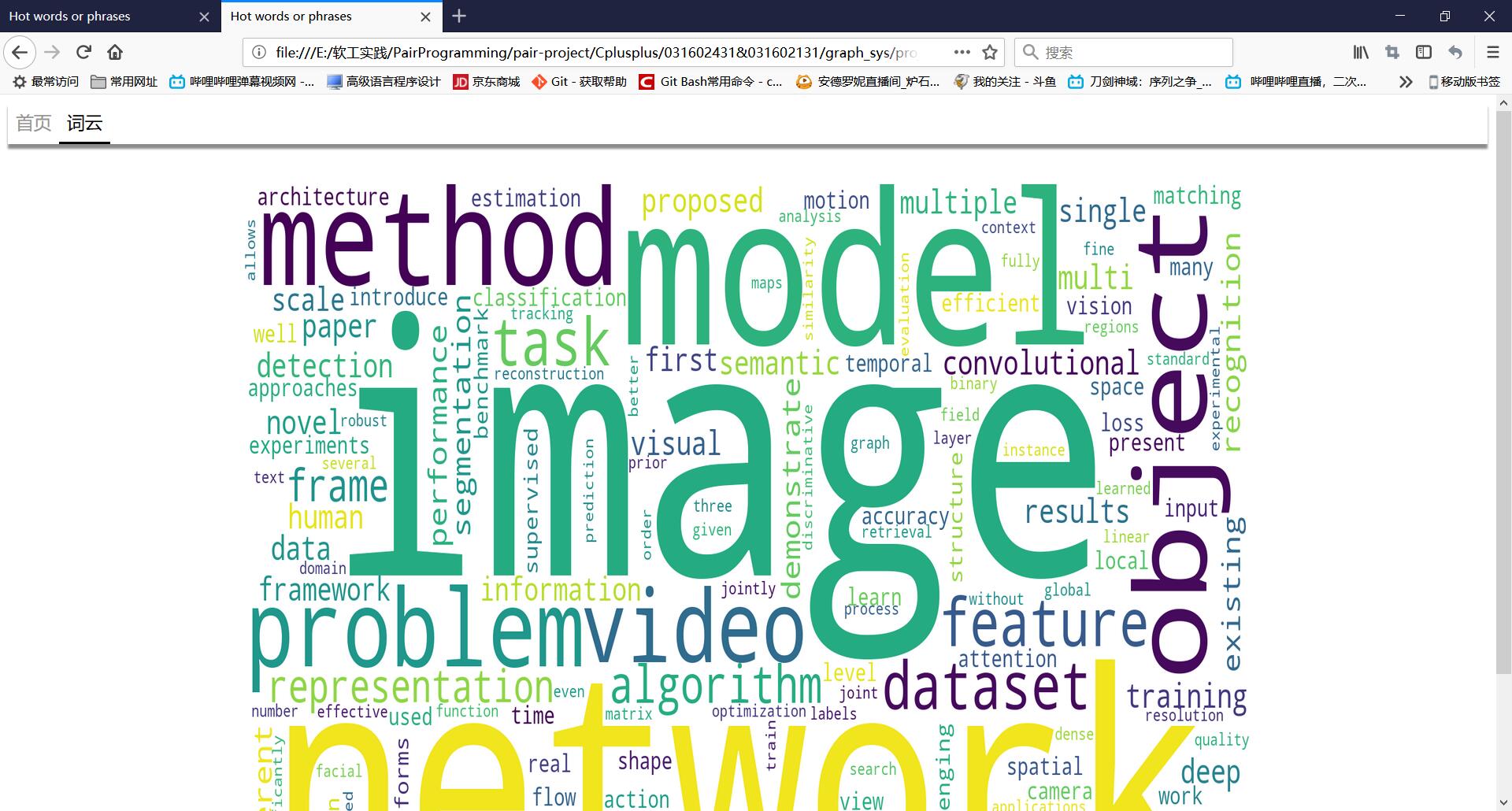
关键代码解释
代码说明
通过三台自动机完成对"\nTitle: "和"\nAbstract: "的过滤和处理
int FileContentFilter::scan() {
char peekChar;
while ((peekChar = fgetc(file)) != EOF) {
if (statusOfDFA[0] == -1) {// cannot find the first "Title: "
return -1;
}
else if (statusOfDFA[0] != 10) { // find the first "Title: "
int ans = dfaOfFirstTitle(peekChar);
if (ans == -1) {
printf("The file format is error\n");
}
}
else if (statusOfDFA[1] != 13) {//find "\n\n\n[0-9]+\nTitle"
fileContent.append(1, peekChar);
dfaOfTitle(peekChar);
if (statusOfDFA[1] == 13) {
int index = fileContent.length() - 12;
for (; index >= 0; index--) {
if (fileContent[index] == '\n')
break;
}
fileContent = fileContent.substr(0, index + 1);
processer->processStr(fileContent, Status::ABSTRACT_CONTENT);
fileContent.clear();
}
}
else {
fileContent.append(1, peekChar);
dfaOfAbstract(peekChar);
if (statusOfDFA[2] == 12) {
fileContent = fileContent.substr(0, (fileContent.length() - 10));
processer->processStr(fileContent, Status::TITLE_CONTENT);
fileContent.clear();
statusOfDFA[1] = 1;
statusOfDFA[2] = 1;
}
}
}
if (peekChar == EOF) {
processer->processStr(fileContent, Status::ABSTRACT_CONTENT);
fileContent.clear();
}
return 0;
}
性能分析与改进
这次工程中,对程序的改进大规模出现在类图、流程图的制作过程中,小规模出现在程序实现时。
在性能分析之后,发现占比最大的依然分别是std::string和std::map。
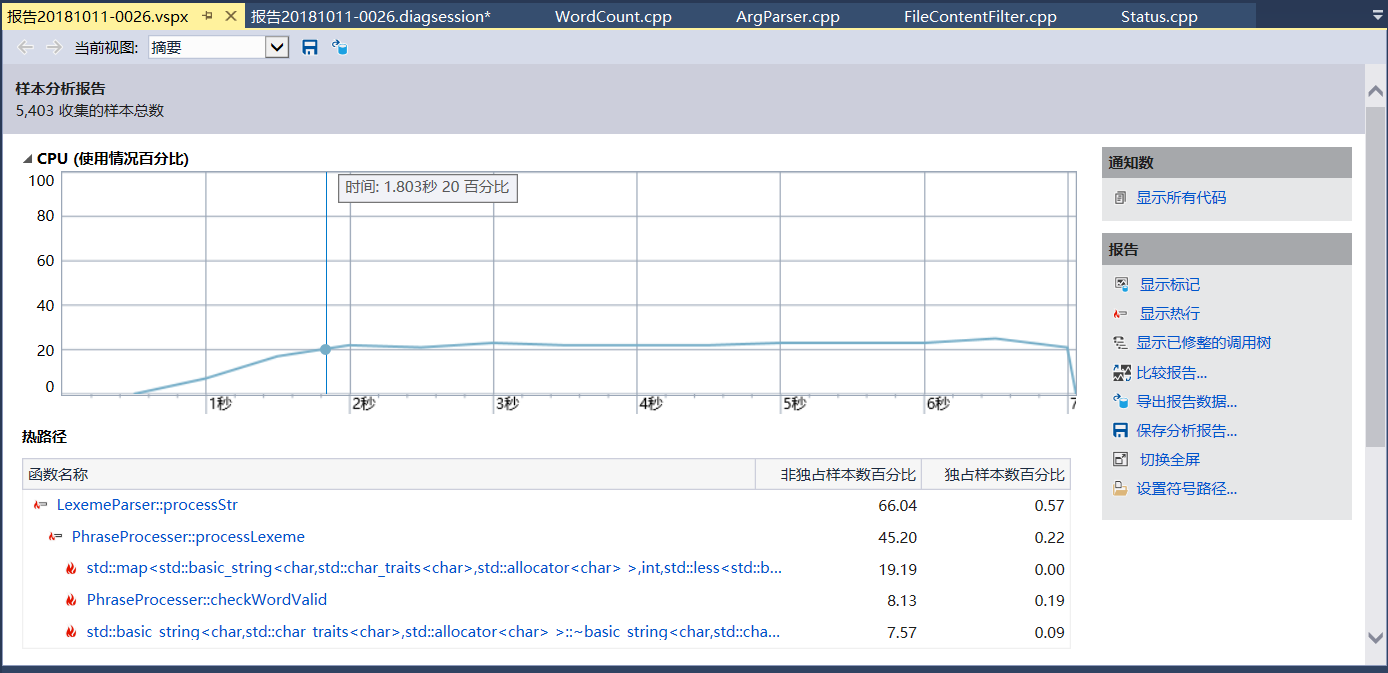
单元测试
测试采用Microsoft本机测试框架
测试数据先测试基本情况的正确性,之后测试更难一点的情况的正确性
// path: /test/UnitTest_LexemeParser/unittest1.cpp
namespace UnitTest_LexemeParser
{
TEST_CLASS(UnitTest1)
{
public:
TEST_METHOD(TestMethod1)
{
Status* status = new Status();
WordProcesser* lexProcesser = new WordProcesser(status);
LexemeParser* lexer = new LexemeParser(status, lexProcesser);
lexer->processStr("We present a new AI task -- Embodied Question Answering (E"
"mbodiedQA) -- where an agent is spawned at a random location in a 3D envi"
"ronment and asked a question", Status::TITLE_CONTENT);
lexer->sendToStatus();
lexProcesser->sendToStatus();
Assert::AreEqual<int>(159, status->charNum);
Assert::AreEqual<int>(1, status->lineNum);
}
TEST_METHOD(TestMethod2)
{
Status* status = new Status();
status->setPharse(3);
PhraseProcesser* lexProcesser = new PhraseProcesser(status);
LexemeParser* lexer = new LexemeParser(status, lexProcesser);
lexer->processStr("adbda \n afasdf asdfasdf aqsf", Status::TITLE_CONTENT);
lexer->sendToStatus();
lexProcesser->sendToStatus();
Assert::AreEqual<int>(28, status->charNum);
Assert::AreEqual<int>(2, status->lineNum);
Assert::AreEqual<int>(1, ((status->storeMap).strMap->size()));
}
};
}
Github的代码签入记录

遇到的代码模块异常或结对困难及解决方法
爬虫方面
问题描述
爬虫过程中遇到的最多次出现的错误是:[Errno 11001] getaddrinfo failed,URLError: <urlopen error [WinError 10060] 由于连接方在一段时间后没有正确答复或连接的主机没有反应,连接尝试失败。
做过哪些尝试
上百度查资料,尝试了time.sleep(),str()等函数,FQ
是否解决
已解决
有何收获
一个是查阅资料时收获了URLError和HTTPError的错误情况,以及python如何进行异常处理。
另一个是尝试了众多办法后最终发现,错误原因只是爬取到的链接并不是一个完整链接。这启示了我,细心也是一个很重要的品质。
解析方面
没有有深刻印象的问题
评价你的队友
值得学习的地方
对知识的钻研能力,钻研下去不眠不休的精神。以及FQ看文档的能力。
需要改进的地方
不要一个人埋头苦干哇,可以多把活扔给我。
学习进度条
| 第N周 | 新增代码(行) | 累计代码(行) | 本周学习耗时(小时) | 累计学习耗时(小时) | 重要成长 |
| 1 | 278 | 278 | 6 | 6 | 复习了C++,学习了文件读入读写,字符操作 |
| 2 | 0 | 278 | 5 | 11 | 学习了Axure RP的使用,以及NABCD模型 |
| 3 | 113 | 391 | 15 | 26 | 复习了python爬虫和java的爬虫 |
附:ECharts引用
ECharts: A Declarative Framework for Rapid Construction of Web-based Visualization
Deqing Li, Honghui Mei, Yi Shen, Shuang Su, Wenli Zhang, Junting Wang, Ming Zu, Wei Chen.
Visual Informatics, 2018 PDF

