
记一次企业级爬虫系统升级改造(四):爬取微信公众号文章(通过搜狗与新榜等第三方平台)
首先表示抱歉,年底大家都懂的,又涉及SupportYun系统V1.0上线。故而第四篇文章来的有点晚了些~~~对关注的朋友说声sorry!
SupportYun系统当前一览:
首先说一下,文章的进度一直是延后于系统开发进度的。
当前系统V1.0 已经正式上线服役了,这就给大家欣赏几个主要界面~~
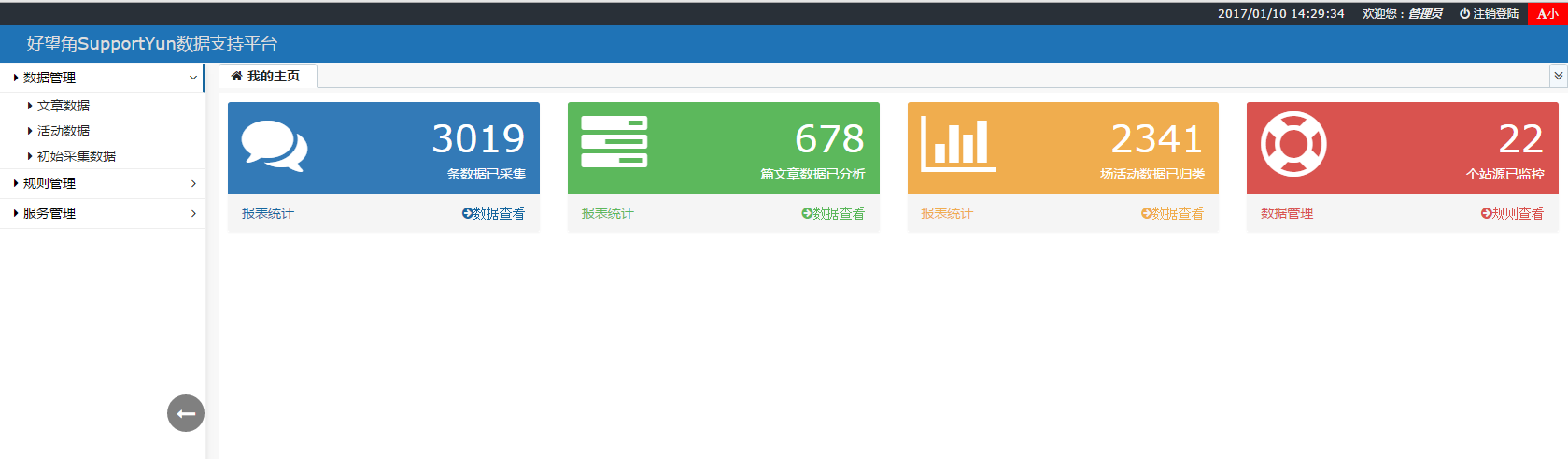
哈哈~这是系统主页,极简风格。主体框架使用的是 B-JUI ,偶然间看到的一个开源框架,相信它的作者会把它做得越来越好!

这是数据列表的功能页面,大家对这个table应该非常熟悉哈,我使用的是easyUI的datagrid,没办法谁叫他简单便捷呢~~
再给大家秀一秀V1.1版本正在开发的一个界面:【搜一搜】
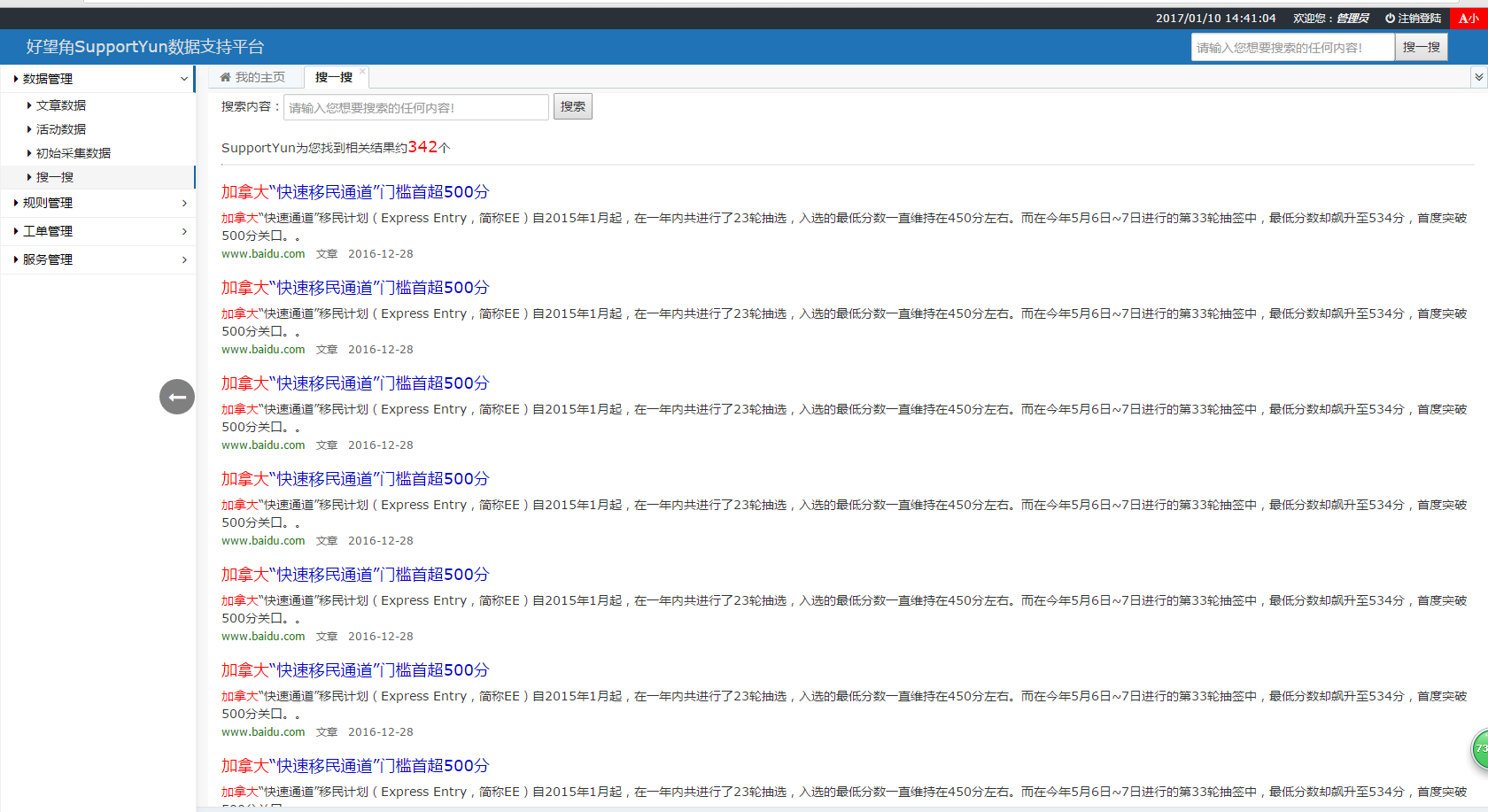
嘿嘿~有木有一种百度搜索结果的既视感...没办法,谁叫俺是个程序员呢,也设计不出来啥好样式,只有照着百度自己拼凑了一个!
技术只是解决问题的选择,而不是解决问题的根本。
爬取微信公众号方案:
不知道为什么,这个系统做着做着我身上就又多了一个使命:爬取微信文章。
谁叫咱是拿钱干活,而不是拿钱吩咐人干活的呢!哎~还非得作为紧急任务添加到了即将上线的V1.0版本,哭>>>>>
“工欲善其事,必先利其器!”
“说人话!”
“我先百度一下怎么做~~~”
所以啊,程序员最离不开的还是万能的搜索引擎。借助几个小时在搜索引擎看的相关帖子、博客、文章等等内容,我也大致总结了一下网友们提到的可以实现的方案:
1.微信API获取 ——想想都是醉了,肿么可能...
2.抓取微信历史文章页面 ——据说每个微信公众号都有一个固定地址的历史文章页面,嗯,我看行...
3.通过搜狗搜索微信,抓取结果列表 ——啊哦,这不就成了抓网页了么,我的系统有现成的方案啊...
4.使用类似新榜这样的内容网站平台 ——本质和搜狗应该想差不大...
5.能搜到很多各式各样的抓取软件,看介绍是有类似功能的,不过不是要钱就是要各种币,故我也没做尝试...
嗯,刀磨锋利了,该选几棵树试试效果了。
以博主这几个小时摄取的知识来看,第3/4两条,通过搜狗、新榜来爬取它们的网页比较靠谱,也和SupportYun当前系统相符(本来咱就是一个单纯的网站爬取系统)。至于第二条,爬历史文章,这个由于BOSS的关注点更在于能抓取到最新的文章,而不是大量的历史文章,故而放弃尝试。
我到底该学什么?------别问,学就对了;
我到底该怎么做?------别问,做就对了。
初尝搜狗搜索,抓取微信公众号文章:
打开搜狗搜索,我们可以看到,搜索微信文章分两种模式:搜文章、搜公众号
先来看搜文章:

根据搜索结果,我们发现,这相当于内容搜索,结果不局限于任何公众号。由于博主的BOSS要求的是爬取指定的一堆微信公众号的最新文章...所以,放弃搜文章。不过大家要是有其他需求,还是可以通过这个方案来构建url抓取数据的。
我们再来看搜公众号是个什么鬼:
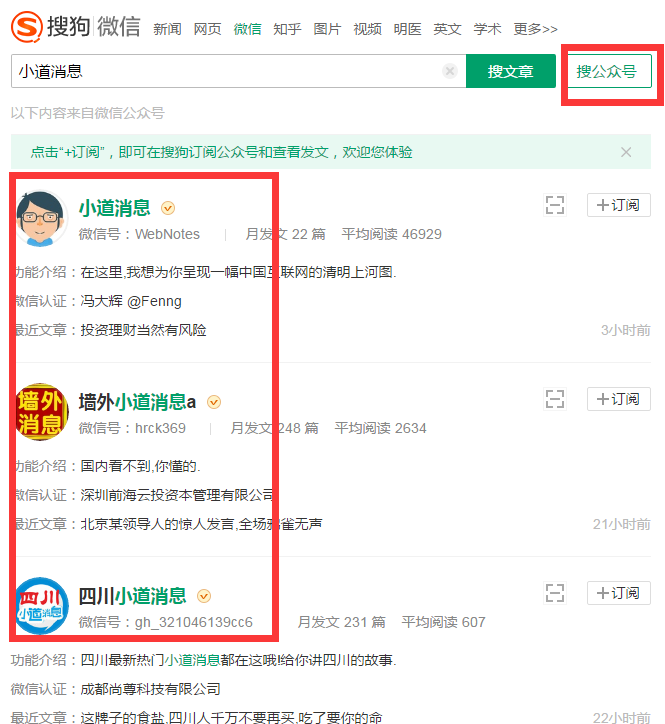
OK,我们点击某一个公众号进去看看。额~~~居然让输入验证码。好万恶!
进去后我们发现是直接到了微信的列表页,观察url,有过时的风险。以小道消息的url为例:
http://mp.weixin.qq.com/profile?src=3×tamp=1484034436&ver=1&signature=5ANAj3eXwUD5KImAqpqhfnnzIx49V9*lzIc-MKxq21VwMoq51PCrd2NxcOqQPbt35Zg5SrRXDB418Rj48HCV5Q==
在url中看见timestamp=1484034436这种带有时间戳的参数,一般都会存在过期问题,博主多次尝试对该url的时间戳进行替换,发现signature参数的值应该是与时间戳有所关联,故而很难自己重新构建url。
假如我们先忽略掉验证码与列表url过期问题,毕竟我们还有搜索文章那一条路,是不存在这两个问题的。那么我们看到的就是一个标准的列表页面:

抓取这种页面是SupportYun系统的强项,具体代码大家可以看第二篇文章:
记一次企业级爬虫系统升级改造(二):基于AngleSharp实现的抓取服务
注:此处详情页的url也是会过时的,经过博主试验,我们只需要在url后面统一加上&devicetype=Windows-QQBrowser&version=61030004&pass_ticket=qMx7ntinAtmqhVn+C23mCuwc9ZRyUp20kIusGgbFLi0=&uin=MTc1MDA1NjU1&ascene=1 ,这样,浏览器访问时就会自动改变url地址为该文章固定地址。
所以,利用搜狗搜索来爬取微信公众号文章,比较可取的方案是通过关键词搜索文章列表,然后爬取列表。切记详情页url过时处理。
当你试图解决一个你不理解的问题时,复杂化就产成了。
基于新榜API爬取微信公众号文章:
我们首先在新榜平台搜索想要抓取的公众号,例:互联网扒皮哥

点击进入该公众号页面,我们看到此时url:http://www.newrank.cn/public/info/detail.html?account=hlwbpg
经多次测试,该格式固定为参数account值是公众号中文拼音(或全拼或首字母缩写),OK,省略掉url过时的忧伤。

我们看到新榜一共为该公众号展示20篇文章,10篇最新,10篇7天最热...这不正是博主千辛万苦想要的数据么~~
Ok~我们F12查看,该20条数据为ajax异步请求api渲染,该api情况如下:
地址:http://www.newrank.cn/xdnphb/detail/getAccountArticle
请求方式:POST
参数:
经多次试验,我们会发现每次请求,flag的值永远为true,uuid的值每个公众号固定不变,而nonce与xyz的值刷新一次变化一次。
我们可以大胆的猜测uuid的值是该公众号在新榜库的唯一标识,而nonce与xyz的值变化不影响结果输出...
然后使用在线http模拟工具一测试,果然如我们所料...

这就很清晰明了了,针对不同的微信公众号,我们只需要找到它在新榜平台的唯一标识uuid,就可以通过定时轮询扫描该API来爬取最新的微信文章。
我们新建一个基于api的抓取服务:BasedOnAPIGrabService
核心抓取方法:
1 public void OprGrab(Guid ruleId) 2 { 3 using (var context = new SupportYunDBContext()) 4 { 5 var ruleInfo = context.CollectionRule.Find(ruleId); 6 if (ruleInfo == null) 7 { 8 throw new Exception("抓取规则已不存在!"); 9 } 10 11 var listUrl = ruleInfo.ListUrlRule.Split(new[] { ',' }); 12 // 获取列表 13 //var client = new HttpClient(); 14 //HttpContent content = new StringContent("flag=" + listUrl[0] + "&uuid=" + listUrl[1],Encoding.UTF8); 15 //var responseJson = client.PostAsync(ruleInfo.WebListUrl, content).Result.Content.ReadAsStringAsync().Result; 16 var responseJson = new HttpHelper().PushToWeb(ruleInfo.WebListUrl, "flag=" + listUrl[0] + "&uuid=" + listUrl[1], 17 Encoding.UTF8); 18 var responseModel = new JavaScriptSerializer().Deserialize<ResponseModel>(responseJson); 19 20 if (responseModel.success == "True" && responseModel.value != null && 21 (responseModel.value.lastestArticle.Any() || responseModel.value.topArticle.Any())) 22 { 23 var newList = new List<DataModel>(); 24 newList.AddRange(responseModel.value.lastestArticle); 25 newList.AddRange(responseModel.value.topArticle); 26 newList = newList.Distinct(i => i.title, StringComparer.CurrentCultureIgnoreCase).ToList(); 27 foreach (var list in newList) 28 { 29 angleSharpGrabService.GrabDetail(ruleInfo, list.url, list.title, context); 30 } 31 } 32 } 33 }
其中第18行,是讲json字符串序列化为对应的object。需要引用System.Web.Extensions
注释掉的几行是准备使用HttpClient来实现Post请求,但该接口使用该方法一直报错,无法获取参数。故而自己写了一个PushToWeb方法来实现Post请求:
1 public string PushToWeb(string weburl, string data, Encoding encode) 2 { 3 var byteArray = encode.GetBytes(data); 4 5 var webRequest = (HttpWebRequest)WebRequest.Create(new Uri(weburl)); 6 webRequest.Method = "POST"; 7 webRequest.ContentType = "application/x-www-form-urlencoded"; 8 webRequest.ContentLength = byteArray.Length; 9 var newStream = webRequest.GetRequestStream(); 10 newStream.Write(byteArray, 0, byteArray.Length); 11 newStream.Close(); 12 13 //接收返回信息: 14 var response = (HttpWebResponse)webRequest.GetResponse(); 15 var aspx = new StreamReader(response.GetResponseStream(), encode); 16 return aspx.ReadToEnd(); 17 }
抓取详情页的方法GrabDetail,是重构AngleSharpGrabService服务的OprGrab方法提取出来的,具体的AngleSharpGrabService服务源码及思路请参考第二篇文章:
记一次企业级爬虫系统升级改造(二):基于AngleSharp实现的抓取服务
1 public void GrabDetail(CollectionRule ruleInfo, string realUrl,string title,SupportYunDBContext context) 2 { 3 if (!IsRepeatedGrab(realUrl, ruleInfo.Id, title)) 4 { 5 string contentDetail = GetHtml(realUrl, ruleInfo.GetCharset()); 6 var detailModel = DetailAnalyse(contentDetail, title, ruleInfo); 7 8 if (!string.IsNullOrEmpty(detailModel.FullContent)) 9 { 10 var ruleModel = context.CollectionRule.Find(ruleInfo.Id); 11 ruleModel.LastGrabTime = DateTime.Now; 12 var newData = new CollectionInitialData() 13 { 14 CollectionRule = ruleModel, 15 CollectionType = ruleModel.CollectionType, 16 Title = detailModel.Title, 17 FullContent = detailModel.FullContent, 18 Url = realUrl, 19 ProcessingProgress = ProcessingProgress.未处理 20 }; 21 if (!IsRepeatedGrab(realUrl, ruleInfo.Id, newData.Title)) 22 { 23 context.CollectionInitialData.Add(newData); 24 context.SaveChanges(); 25 } 26 } 27 } 28 }
该服务我关联到了每日查询6次的group下面,windows服务就会自动每日扫描配置了该api规则的公众号6次,以满足尽快抓取公众号最新文章的需求。
如果你交给某人一个程序,你将折磨他一整天;如果你教给某人如何编写程序, 你将折磨他一辈子!
哈哈,我想到了从小听到大的至理名言:授人以鱼,不如授人以渔!
过程中参考了很多资料,这里列出博主认为收获最多的一个链接,以供大家参考:
https://www.zhihu.com/question/31285583
原创文章,代码都是从自己项目里贴出来的。转载请注明出处哦,亲~~~
