
利用R语言+逻辑回归实现自动化运营
摘要
逻辑回归是最常见的二分类算法之一,由于是有监督学习,训练阶段需要输入标签,而同时在变量较多的情况下,需要先经过一些降维处理,本文主要讲解如果通过R语言来自动化实现变量的降维以及变量转换,训练,测试,覆盖率以及准确度效果评估,以及生成最终评分配置表,而在标签与训练数据在可以自动化生成的情况下,配置表是能自动生成的。其中每个步骤都有详细的实现代码。
主要步骤

实现细节
1.生成训练数据
如类似下面的格式
lable var1 var2 var3 var4 var5 var6 var7 var8 var9 var10
37 0 1012512056 1 158 2 5 1 2 250 2 40
48 0 1028191324 1 158 5 1 0 1 100 0 0
82 0 1042100363 1 158 3 15 8 17 88 7 46
105 0 1059904293 1 158 3 17 4 10 170 5 29
215 0 1056562444 1 158 3 20 10 15 133 3 15
219 1 405594373 1 158 2 8 5 1 800 0 0
309 0 1015664693 1 158 4 18 11 6 300 3 16
312 0 1032736990 1 158 2 6 3 14 42 0 0
319 1 1310159241 1 158 3 8 4 2 400 2 25
350 0 1026266596 1 158 5 34 18 15 226 5 14
380 0 1028432195 1 158 4 19 7 9 211 1 5
如该例子中,包含了10个特征var1-var10,以及一个标签,第一行是变量名,第二行开始多了一列,因为第一列是行号(这里数据不全,简单做了挑选,为了说明问题)。
生成这样的格式,主要是为了方便利用如下的代码来载入:
#读取数据
data<-read.table("test_tranning.txt",header=T)
这里的data就是载入的原始数据框
2.降维及变量转换
先讲解两个基本概念,IV值以及WOE值,IV的全称是Information Value信息量,IV值是逻辑回归挑选变量中一个主要的方法之一,WOE的全称是Weight of Evidence权重,计算WOE是计算IV值的前提,计算WOE的时候一般需要先对某个变量进行分段,如等量分段,每个分段的woe值实际就是这个分段中坏人与好人比例的对数值,即:
woe_i=ln(bad_num/good_num)
对应该分段的iv值为:
Iv_i = (bad_num-good_num)woe_i
那么该变量整体的IV值为:
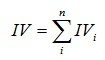
一般情况下IV值越大,说明该变量区分好坏人的能力越强,所以一般会挑选IV值较大的变量作为模型输入。而实际上在本文中,我们不是利用IV值来挑选变量,而是利用glm函数返回的p值来挑选,这里引入WOE的概念,主要是为了进行变量转换,即我们的本意是把原始变量转换为它对应的woe值,把这个woe值作为新的输入变量,在进行训练测试。这样做主要的好处就是能把一些不是正态分布的变量转换为正态分布。
1) 第一个步骤就是分段

2) 接着就是求出变量的WOE以及IV值



3)接着合并woe值
这里简单解释下为什么要合并woe值,因为我们默认对所有变量都进行了等量分段,比如10段,而实际上有些相邻分段的woe值(也就是区分好坏人的能力)相差不大,那么我们实际上是可以合并这些分段的,也就是不需要分那么多段。


4)把变量转变为woe值

5)汇总
把步骤汇总起来就是如下的代码:

3.训练及测试
构造训练公式,随机挑选其中70%左右训练数据,30%作为测试数据。使用glm函数来训练。

4.生成评分配置表

结果如如下类似情况:
Woe名字,index,intercept,coefficients,变量分段的起始值,变量分段的终点值,对应评分权重

5.效果评估
实际上最关键的两个指标就是覆盖率以及准确度,也可以同时加上ks的指标评估,比如在自动化的过程中,可以挑选准确度高于95%的或者覆盖率大于90%的,或者ks指标如何的,这个根据自己的应用来决定。



直接这样调用:

得到的评估结果如下类似:

