Linux 伙伴算法简介
本文将简要介绍一下Linux内核中的伙伴分配算法。
算法作用
它要解决的问题是频繁地请求和释放不同大小的一组连续页框,必然导致在已分配页框的块内分散了许多小块的空闲页面,由此带来的问题是,即使有足够的空闲页框可以满足请求,但要分配一个大块的连续页框可能无法满足请求。
伙伴算法(Buddy system)把所有的空闲页框分为11个块链表,每块链表中分布包含特定的连续页框地址空间,比如第0个块链表包含大小为2^0个连续的页框,第1个块链表中,每个链表元素包含2个页框大小的连续地址空间,….,第10个块链表中,每个链表元素代表4M的连续地址空间。每个链表中元素的个数在系统初始化时决定,在执行过程中,动态变化。
伙伴算法每次只能分配2的幂次页的空间,比如一次分配1页,2页,4页,8页,…,1024页(2^10)等等,每页大小一般为4K,因此,伙伴算法最多一次能够分配4M的内存空间。
核心概念和数据结构
两个内存块,大小相同,地址连续,同属于一个大块区域。(第0块和第1块是伙伴,第2块和第3块是伙伴,但第1块和第2块不是伙伴)
伙伴位图:用一位描述伙伴块的状态位码,称之为伙伴位码。比如,bit0为第0块和第1块的伙伴位码,如果bit0为1,表示这两块至少有一块已经分配出去,如果bit0为0,说明两块都空闲,还没分配。
Linux2.6为每个管理区使用不同的伙伴系统,内核空间分为三种区,DMA,NORMAL,HIGHMEM,对于每一种区,都有对于的伙伴算法,
1. free_area数组:

1: struct zone{
2: ....
3: struct free_area free_area[MAX_ORDER];
4: ....
5: }
struct free_area free_area[MAX_ORDER] #MAX_ORDER 默认值为11
2. zone_mem_map数组
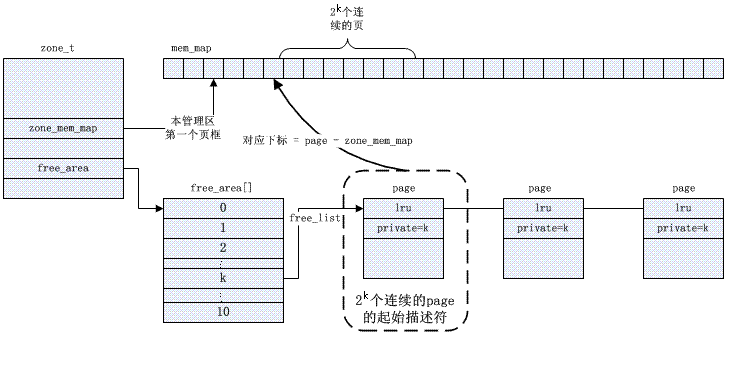
free_area数组中,第K个元素,它标识所有大小为2^k的空闲块,所有空闲快由free_list指向的双向循环链表组织起来。其中的nr_free,它指定了对应空间剩余块的个数。
整个分配图示,大概如下:

申请和回收过程
比如,我要分配4(2^2)页(16k)的内存空间,算法会先从free_area[2]中查看nr_free是否为空,如果有空闲块,则从中分配,如果没有空闲块,就从它的上一级free_area[3](每块32K)中分配出16K,并将多余的内存(16K)加入到free_area[2]中去。如果free_area[3]也没有空闲,则从更上一级申请空间,依次递推,直到free_area[max_order],如果顶级都没有空间,那么就报告分配失败。
释放是申请的逆过程,当释放一个内存块时,先在其对于的free_area链表中查找是否有伙伴存在,如果没有伙伴块,直接将释放的块插入链表头。如果有或板块的存在,则将其从链表摘下,合并成一个大块,然后继续查找合并后的块在更大一级链表中是否有伙伴的存在,直至不能合并或者已经合并至最大块2^10为止。
内核试图将大小为b的一对空闲块(一个是现有空闲链表上的,一个是待回收的),合并为一个大小为2B的单独块,如果它成功合并所释放的块,它会试图合并2b大小的块,
内核使用_rmqueue()函数来在管理区中找到一个空闲块,成功返回第一个被分配页框的页描述符,失败返回NULL。

内核使用
__free_pages_bulk()函数按照伙伴系统的策略释放页框。它使用3个基本输入参数:
page:被释放块中所包含的第一个页框描述符的地址。
zone:管理区描述符的地址。
order:块大小的对数。
伙伴算法的优缺点
优点:
较好的解决外部碎片问题
当需要分配若干个内存页面时,用于DMA的内存页面必须连续,伙伴算法很好的满足了这个要求
只要请求的块不超过512个页面(2K),内核就尽量分配连续的页面。
针对大内存分配设计。
缺点:
1. 合并的要求太过严格,只能是满足伙伴关系的块才能合并,比如第1块和第2块就不能合并。
2. 碎片问题:一个连续的内存中仅仅一个页面被占用,导致整块内存区都不具备合并的条件
3. 浪费问题:伙伴算法只能分配2的幂次方内存区,当需要8K(2页)时,好说,当需要9K时,那就需要分配16K(4页)的内存空间,但是实际只用到9K空间,多余的7K空间就被浪费掉。
4. 算法的效率问题: 伙伴算法涉及了比较多的计算还有链表和位图的操作,开销还是比较大的,如果每次2^n大小的伙伴块就会合并到2^(n+1)的链表队列中,那么2^n大小链表中的块就会因为合并操作而减少,但系统随后立即有可能又有对该大小块的需求,为此必须再从2^(n+1)大小的链表中拆分,这样的合并又立即拆分的过程是无效率的。
Linux针对大内存的物理地址分配,采用伙伴算法,如果是针对小于一个page的内存,频繁的分配和释放,有更加适宜的解决方案,如slab和kmem_cache等,这不在本文的讨论范围内。
参考链接:伙伴算法剖析(原创)
