
Deep learning with Theano 官方中文教程(翻译)(四)—— 卷积神经网络(CNN)
供大家相互交流和学习,本人水平有限,若有各种大小错误,还请巨牛大牛小牛微牛们立马拍砖,这样才能共同进步!若引用译文请注明出处http://www.cnblogs.com/charleshuang/。
本文译自:http://deeplearning.net/tutorial/lenet.html
文章中的代码截图不是很清晰,可以去上面的原文网址去查看。
1、动机
卷积神经网络(CNN)是多层感知机(MLP)的一个变种模型,它是从生物学概念中演化而来的。从Hubel和Wiesel早期对猫的视觉皮层的研究工作,我们知道在视觉皮层存在一种细胞的复杂分布,,这些细胞对于外界的输入局部是很敏感的,它们被称为“感受野”(细胞),它们以某种方法来覆盖整个视觉域。这些细胞就像一些滤波器一样,它们对输入的图像是局部敏感的,因此能够更好地挖掘出自然图像中的目标的空间关系信息。
此外,视觉皮层存在两类相关的细胞,S细胞(Simple Cell)和C(Complex Cell)细胞。S细胞在自身的感受野内最大限度地对图像中类似边缘模式的刺激做出响应,而C细胞具有更大的感受野,它可以对图像中产生刺激的模式的空间位置进行精准地定位。
视觉皮层作为目前已知的最为强大的视觉系统,广受关注。学术领域出现了很多基于它的神经启发式模型。比如:NeoCognitron [Fukushima], HMAX [Serre07] 以及本教程要讨论的重点 LeNet-5 [LeCun98]。
2、稀疏连接
CNNs通过加强神经网络中相邻层之间节点的局部连接模式(Local Connectivity Pattern)来挖掘自然图像(中的兴趣目标)的空间局部关联信息。第m层隐层的节点与第m-1层的节点的局部子集,并具有空间连续视觉感受野的节点(就是m-1层节点中的一部分,这部分节点在m-1层都是相邻的)相连。可以用下面的图来表示这种连接。
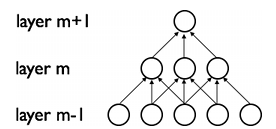
假设,m-1层为视网膜输入层(接受自然图像)。根据上图的描述,在m-1层上面的m层的神经元节点都具有宽度为3的感受野,m层每一个节点连接下面的视网膜层的3个相邻的节点。m+1层的节点与它下面一层的节点有着相似的连接属性,所以m+1层的节点仍与m层中3个相邻的节点相连,但是对于输入层(视网膜层)连接数就变多了,在本图中是5。这种结构把训练好的滤波器(corresponding to the input producing the strongest response)构建成了一种空间局部模式(因为每个上层节点都只对感受野中的,连接的局部的下层节点有响应)。根据上面图,多层堆积形成了滤波器(不再是线性的了),它也变得更具有全局性了(如包含了一大片的像素空间)。比如,在上图中,第m+1层能够对宽度为5的非线性特征进行编码(就像素空间而言)。
3、权值共享
在CNNs中,每一个稀疏滤波器hi在整个感受野中是重复叠加的,这些重复的节点形式了一种特征图(feature map),这个特种图可以共享相同的参数,比如相同的权值矩阵和偏置向量。
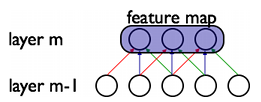
在上图中,属于同一个特征图的三个隐层节点,因为需要共享相同颜色的权重, 他们的被限制成相同的。在这里, 梯度下降算法仍然可以用来训练这些共享的参数,只需要在原算法的基础上稍作改动即可。共享权重的梯度可以对共享参数的梯度进行简单的求和得到。
为什么对权值共享如此感兴趣呢?无论重复单元在感受野的什么位置,他们都可以检测到特征。此外,权值共享提供了一种高效的方式来实现这个,因为这种方式大大减少了需要学习(训练)的参数数目。如果控制好模型的容量,CNN在解决计算机视觉问题上会有更好的泛化能力。
4、详细说明和标注说明
从概念上来说,特征图是通过对输入图像在一个线性滤波器上做卷积,增加一个偏置项,在此结果上再作用一个非线性函数得到的。如果我们把某一层的第k个特征图记为hk,它的滤波器由权值Wk和偏置bk所决定,所以特征图的由下面公式定义(非线性函数取tanh):
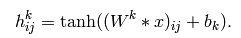
卷积说明:

为了更好地表示数据,隐层由多个特征图构成,{hk,k=1,2,3 ...K}.权值W由4个参数决定(目标特征图的索引、源特征图的索引、源垂直位置的索引、源水平位置的索引)(可以说W是一个4维的张量),偏置b为一个向量,向量中的每一个元素对应一个特征图的索引。我们用下图来表示:
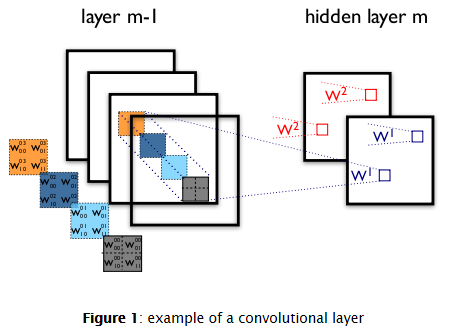
上图是一个包含2层神经元节点的CNN,包括m-1层的4个特征图和m层的2个特征图(h0,h1)。神经元在h0,h1的输出(像素)是由m-1层中在其2*2的感受野中的像素计算得到的。这里注意感受野是如何跨越4个特征图的,权值W0,W1是3维的张量(3D tensor),一个表示输入特征图的索引,另外两个表示像素坐标。总的来说,表示连接第m层第k个特征图的特征图上的每一个像素的权重,与之连接的是m-1层上第l个特征图中坐标为(i,j)的像素。
5、ConvOp
ConvOp是Theano中对卷积层的一个实现。它重复了Scipy中scipy.signal.convolve2d的函数功能,总的来讲,ConvOp包含了两个输入(参数):
(1)对应输入图像的mini-batch的4D张量。每个张量的大小为:[mini-batch的大小,输入的特征图的数量,图像的高度,图像的宽度]。
(2)对应于权值W的4D张量。每个张量的大小为:[m层的特征图数量,m-1层的特征图数量,滤波器的高度,滤波器的宽度]。
下面代码实现了Figure 1中的卷积层,输入包括了大小为120*160的3个特征图(对应RGB). 我们可以用两个具有9*9的感受野的卷积过滤器。
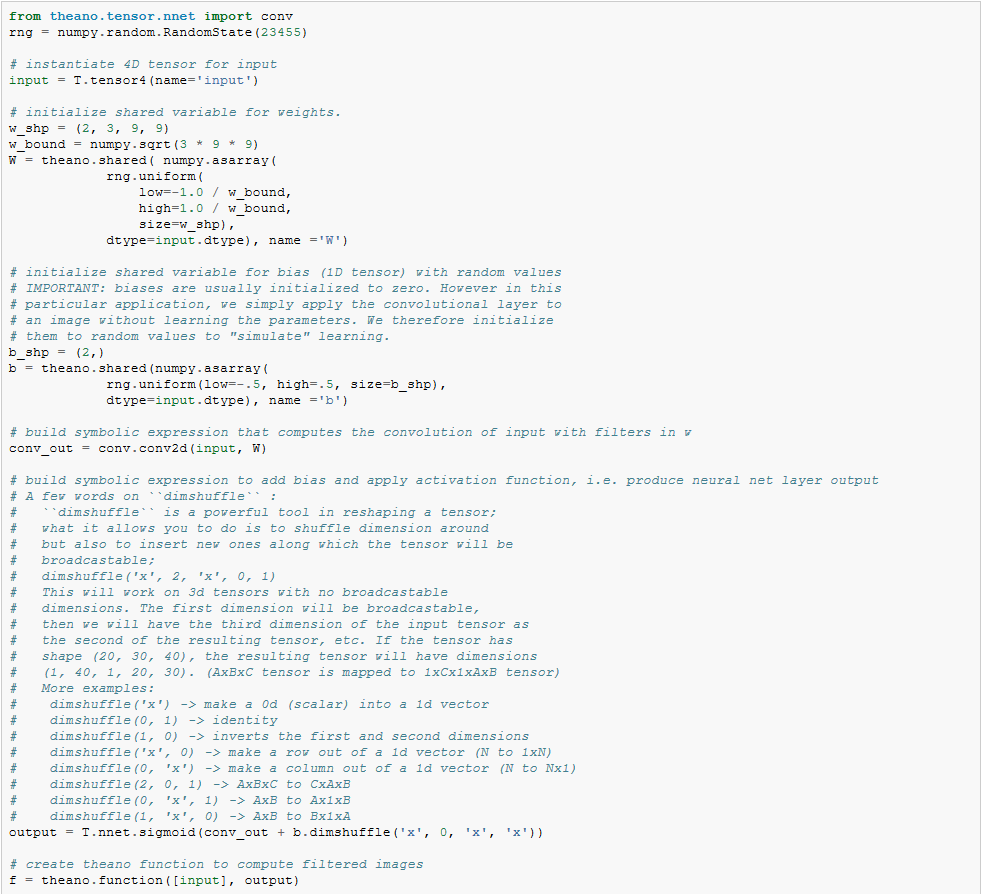
我们发现,随机初始化的的滤波器能够产生边缘检测算子的作用。
另外,我们使用了相同的公式对权值进行初始化,这些权值都是从一个范围为[-1/fan-in, 1/fan-in]的均匀分布中采样得到的,fan-in是隐层的输入节点数目,在MLP中,这个fan-in就是下面那一层的节点数目,然而对于CNN来说,我们需要考虑到输入特征图的数量,以及感受野的大小。
6、最大池化
CNNs中另一个很重要的概念是最大池化(max-pooling),这是一种非线性的下采样的方法。最大池化把输入图像分割成为不重叠的矩阵,每一个子区域(矩形区域),都输出最大值。
最大池化技术在视觉问题中是很有用的,原因有两个:(1)降低了上层的计算复杂度。(2)提出了一种变化的不变性形式。为了理解这种不变性,我们假设把最大池化层和一个卷基层结合起来,对于单个像素,有8个变换的方向,如果共有最大层在2*2的窗口上面实现,这8个可能的配置中,有3个可以准确的产生和卷积层相同的结果。如果窗口变成3*3,则产生精确结果的概率变成了5/8。
因此,它对于位移变化有着不错的鲁棒性,最大池化用一种很灵活的方式降低了中间表示层的维度。
最大池化在Theano中的theano.tensor.signal.downsample.max_pool_2d实现了。这个函数以一个N维的张量作为输入(N>2),和一个缩放因子用来对这个张量进行最大池化的变换。下面是例程代码:
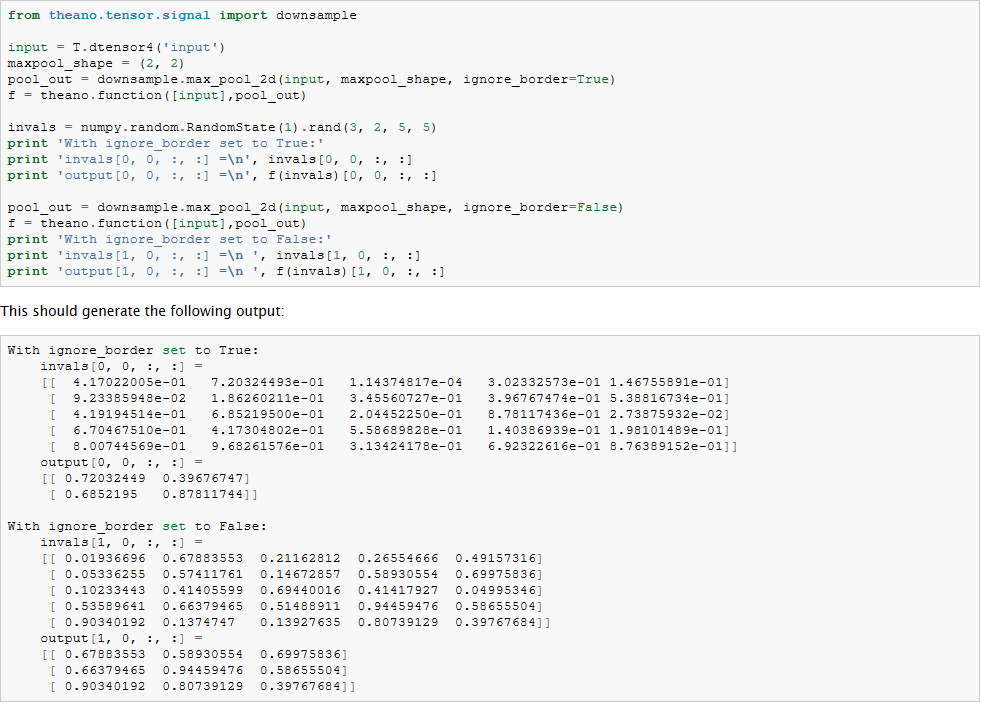
注意到和大部分代码不同的是,这个函数max_pool_2d 在创建Theano图的时候,需要一个向下采样的因子ds (长度为2的tuple变量,表示了图像的宽和高的缩放. 这个可能在以后的版本中升级。
7、一个完整的CNN模型:LeNet
稀疏性、卷积层和最大池化是LeNet系列模型的核心概念。犹豫模型细节变化较大,我们用下图来展示整个LeNet模型。
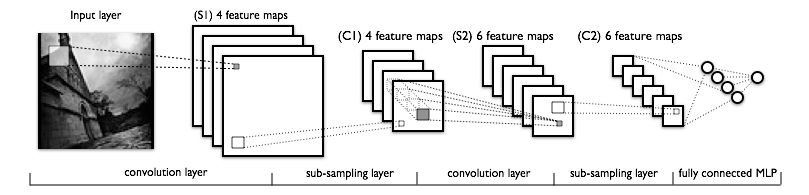
模型的低层由卷基层和最大池化曾组成,高层是一个全连接的MLP神经网络(隐层+逻辑回归,ANN),高层的输入是下层特征图的集合。
从实现的角度讲,这意味着低层操作了4D的张量,这个张量被压缩到了一个2D矩阵表示的光栅化的特征图上,以便于和前面的MLP的实现兼容。
8、全部代码
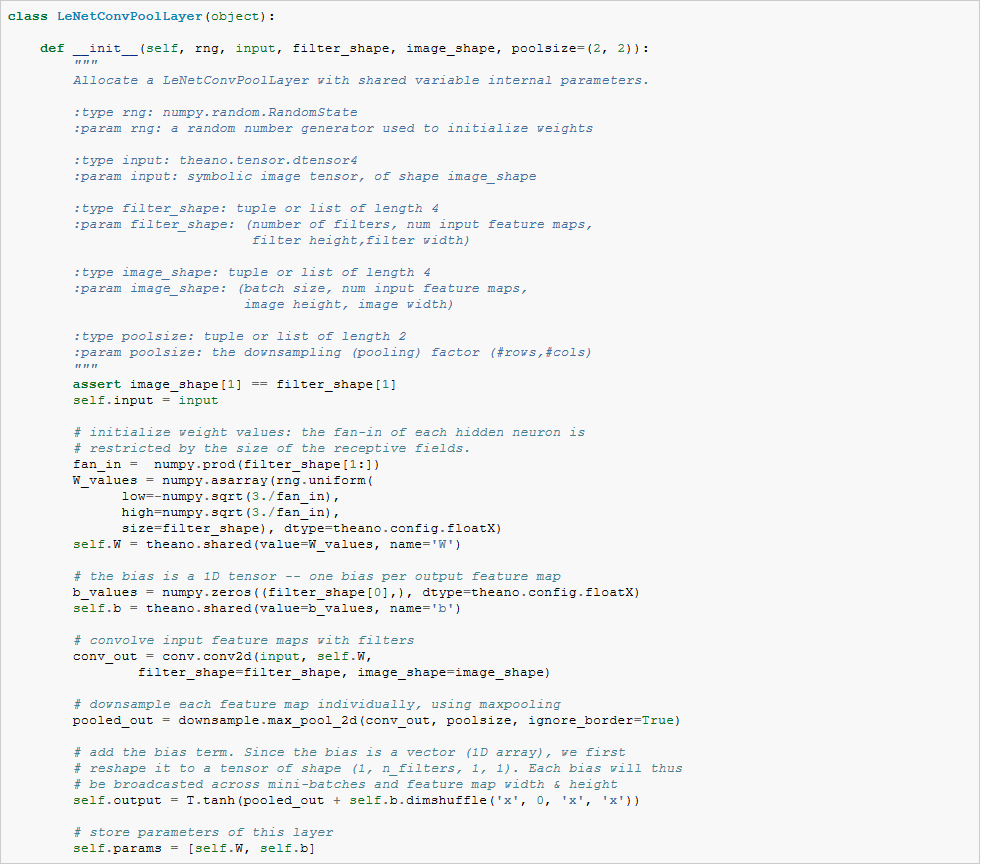

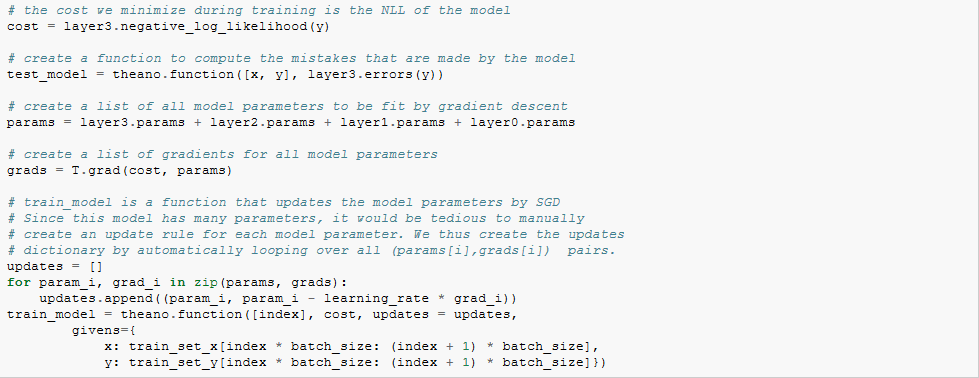
应该注意的是,在初始化权重的时候,fan-in是由感知野的大小和输入特征图的数目决定的。最后,采用前面章节定义的LogisticRegression和HiddenLayer类,LeNet就可以工作了。
9、注意要点和技巧
超参数选择:由于CNNs比标准的MLP有着更多的超参数,所以CNNs的模型训练是很需要技巧的。不过传统的学习率和惩罚项仍然是需要使用的,下面说的的这些技巧在优化CNNs模型的过程中需要牢记。
(1)滤波器的数量选择:在选定每一层的滤波器的数量的时候,要牢记计算一个卷积层滤波器的激活函数比计算传统的MLPs的激活函数的代价要高很多!假设第(i-1)层包含了Ki-1个特征图和M*N个像素坐标(如坐标位置数目乘以特征图数目),在l层有Kl个m*n的滤波器,所以计算特征图的代价为:(M-m)*(N-n)*m*n*Kl-1。整个代价是Kl乘级的。如果一层的所有特征图没有和前一层的所有的特征图全部连起来,情况可能会更加复杂一些。对于标准的MLP,这个代价为Kl * Kl-1,Kl是第l层上的不同的节点。所以,CNNs中的特征图数目一般比MLPs中的隐层节点数目要少很多,这还取决于特征图的尺寸大小。因为特征图的尺寸随着层次深度的加大而变小,越靠近输入,所在层所包含的特征图越少,高层的特征图会越多。实际上,把每一次的计算平均一下,输出的特征图的的数目和像素位置的数目在各层是大致保持不变的。To preserve the information about the input would require keeping the total number of activations (number of feature maps times number of pixel positions) to be non-decreasing from one layer to the next (of course we could hope to get away with less when we are doing supervised learning).所以特征图的数量直接控制着模型的容量,它依赖于样本的数量和任务的复杂度。
(2)滤波器的模型属性(shape):一般来说,在论文中,由于所用的数据库不一样,滤波器的模型属性变化都会比较大。最好的CNNs的MNIST分类结果中,图像(28*28)在第一层的输入用的5*5的窗口(感受野),然后自然图像一般都使用更大的窗口,如12*12,15*15等。为了在给定数据库的情况下,获得某一个合适的尺度下的特征,需要找到一个合适的粒度等级。
(3)最大池化的模型属性:典型的取值是2*2或者不用最大池化。比较大的图像可以在CNNs的低层用4*4的池化窗口。但是要需要注意的是,这样的池化在降维的同事也有可能导致信息丢失严重。
(4)注意点:如果想在一些新的数据库上用CNN进行测试,可以对数据先进行白化处理(如用PCA),还有就是在每次训练迭代中减少学习率,这样可能会得到更好的实验效果。
posted on 2014-04-08 13:53 Charles Huang @ CAS 阅读(66357) 评论(4) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号