
word2-寻找社交新浪微博中的目标用户
项目简述:
为了进行更加精准的营销, 利用数据挖掘相关算法, 利用开放API或自行编写爬虫获得新浪微博, 知乎等社交网络(可能需要破解验证码)中用户所发布的数据, 利用数据挖掘的相关算法进行分析, 从大规模的用户群体中, 分别找出其中具有海淘或母婴购物意向的用户
使用语言:
java
工具:
eclipse
项目过程论述:
1.收集新浪微博用户的数据
2.对这些用户数据进行分析,判断其是否具有母婴的购物意向。
3.对这些具有母婴购物意向的用户进一步分类,分成衣食住行四类。
4.给分好类之后的用户进行推荐相应的母婴商品。
工作流程图如图所示:

----------------------------------------------------------------------------------------------
过程1-----收集新浪微博用户的数据
目的:收集每个用户至少300条微博,不足收集全部,太少则放弃。
收集工具:八爪鱼收集器
收集方法:按照关键词收集,利用新浪微博强大的搜索引擎。
收集规则:
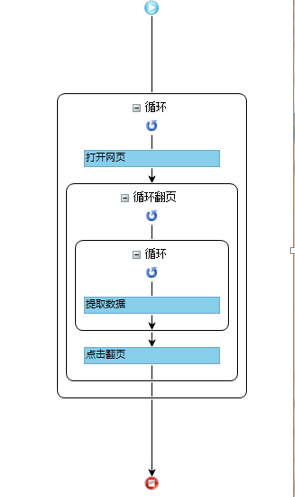
收集结果(存放到mysql):
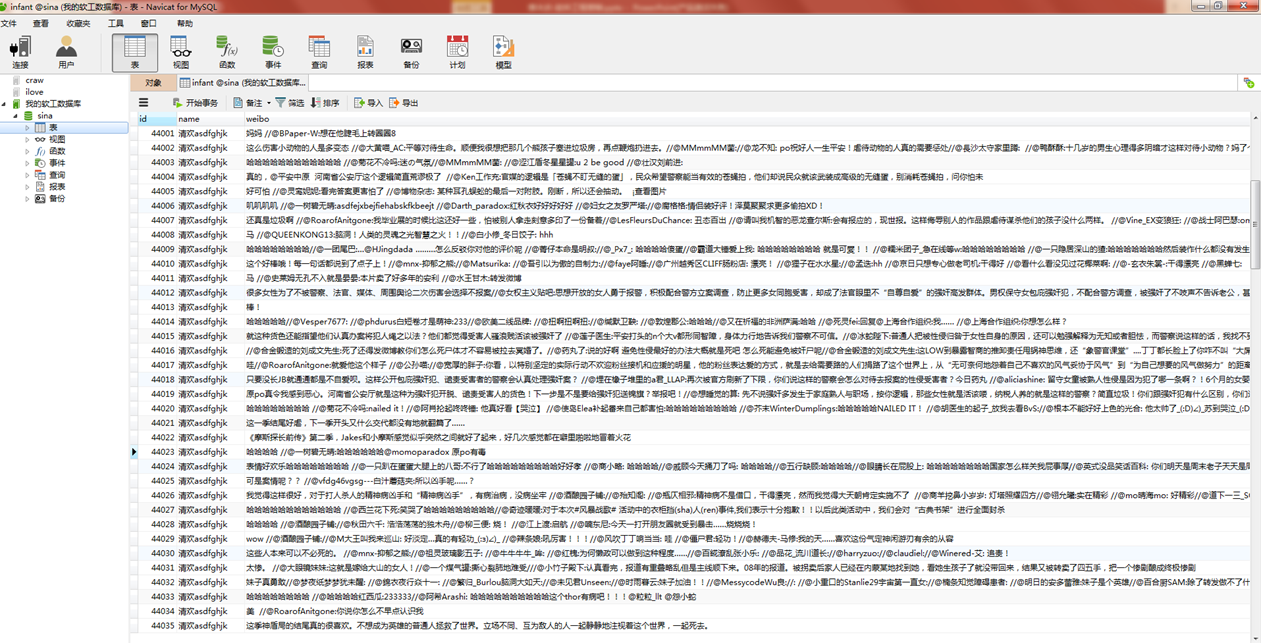
-------------------------------------------------------------------------------------------------------------------------------------------------------------
过程2-----对收集到的新浪微博用户进行分析,判断其是否具有母婴的购物意向
目的:对一个用户分析,判断是/否具有母婴购物意向
方法:使用向量空间模型的余弦相似度,即两个向量之间的夹角越小,则余弦值越大,这两个向量就越相似
实现过程:
前提:收集数据的时候收集两部分数据,一部分人工判断已知具有母婴购物意向,另一部分是未知购物意向的用户。
1.将每个用户的向量都抽象成N维向量。
方法:参考石延君的博客参考石延君的博客http://shiyanjun.cn/archives/548.html
具体如下:
1)先找出能代表这个用户微博的关键词,将这个用户的微博都存储在一个txt文件中,大致过程如下

2)找出特征向量后,给特征向量的每一维都赋予权重,可以得到初步的N维具有权重的向量。

3)对N维向量进行归一化,直接利用libsvm的scale函数即可(可以参考libsvm的使用方法)。
2.计算未知用户向量与已知购物意向用户向量之间的余弦相似度,如果超过0.5,则认为其是相似的,则有理由认为这些未知用户是具有母婴购物意向的。
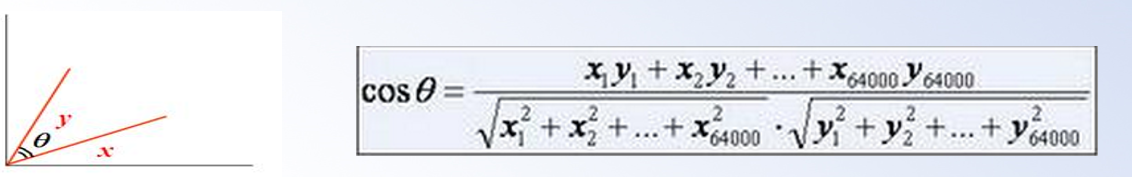
---------------------------------------------------------------------------------------------------------------------------------------------------
过程3--------对分析出来具有母婴购物意向的用户进一步分类,分成衣食住行四类
理论基础:使用libsvm来分类

训练集是预先收集好的,分成衣食住行四类的新浪微博用户,带预测集是过程1和2分析出来的具有母婴购物意向的用户。
-----------------------------------------------------------------------------------------------------------------------------------------
过程4------推荐商品


