
LMDB中的mmap、Copy On Write、MVCC深入理解——讲得非常好,常来看看!
LMDB基本架构
lmdb的基本架构如下: 
lmdb的基本做法是使用mmap文件映射,不管这个文件存储实在内存上还是在持久存储上。lmdb的所有读取操作都是通过mmap将要访问的文件只读的映射到虚拟内存中,直接访问相应的地址.因为使用了read-only的mmap,同样避免了程序错误将存储结构写坏的风险。并且IO的调度由操作系统的页调度机制完成。而写操作,则是通过write系统调用进行的,这主要是为了利用操作系统的文件系统一致性,避免在被访问的地址上进行同步。
lmdb把整个虚拟存储组织成B+Tree存储,索引和值读存储在B+Tree的页面上.对外提供了关于B+Tree的操作方式,利用cursor游标进行。可以进行增删改查。
使用Memory Map
Memory Map原理
内存映射就是把物理内存映射到进程的地址空间之内,这些应用程序就可以直接使用输入输出的地址空间.由此可以看出,使用内存映射文件处理存储于磁盘上的文件时,将不需要由应用程序对文件执行I/O操作,这意味着在对文件进行处理时将不必再为文件申请并分配缓存,所有的文件缓存操作均由系统直接管理,由于取消了将文件数据加载到内存、数据从内存到文件的回写以及释放内存块等步骤,使得内存映射文件在处理大数据量的文件时能起到相当重要的作用。
Linux下mmap的实现过程与普通文件io操作
mmap映射原理与过程1: 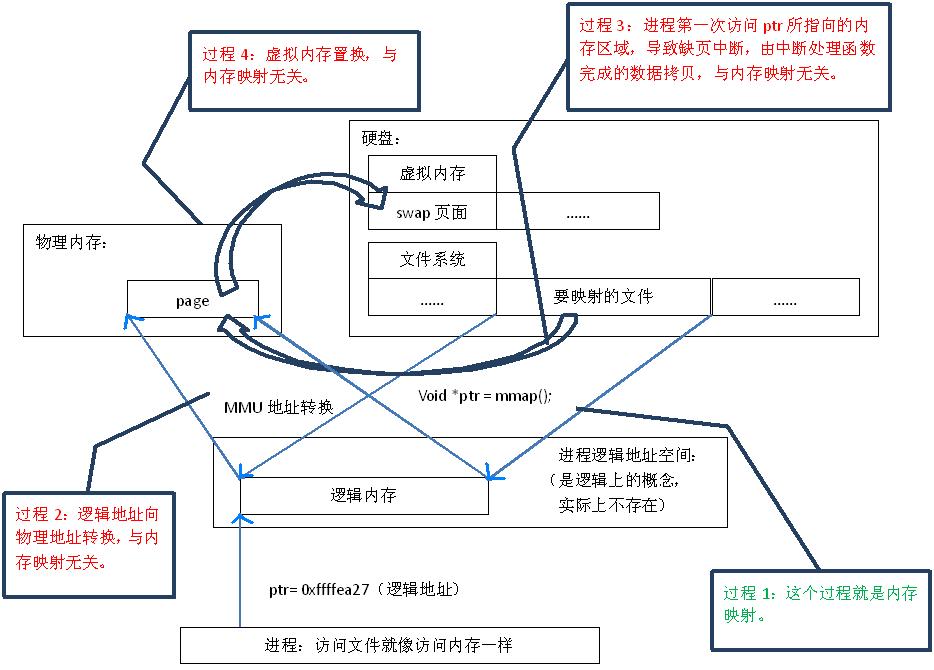
一般文件io操作方式: 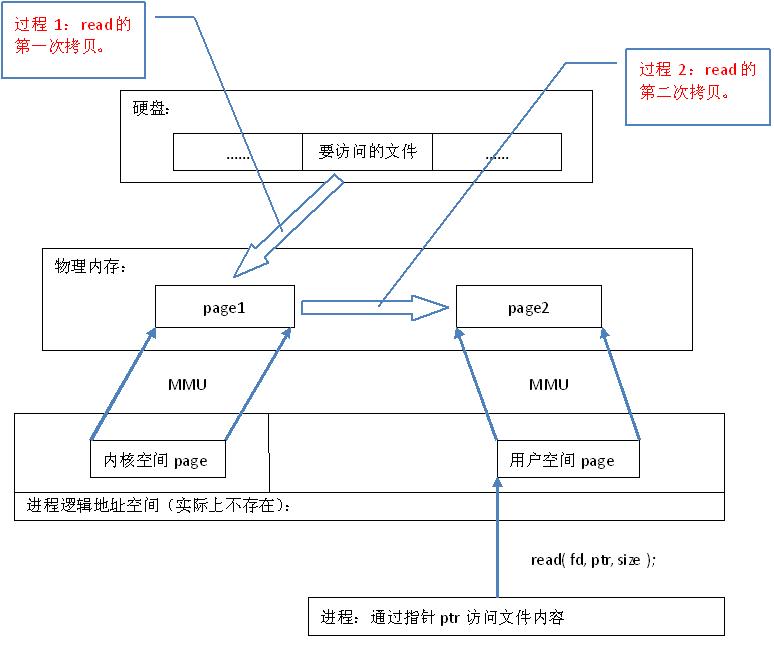
通过内存映射的方法访问硬盘上的文件,效率要比read和write系统调用高, read()是系统调用,其中进行了数据拷贝,它首先将文件内容从硬盘拷贝到内核空间的一个缓冲区,然后再将这些数据拷贝到用户空间,在这个过程中,实际上完成了 两次数据拷贝 ;而mmap()也是系统调用,如前所述,mmap()中没有进行数据拷贝,真正的数据拷贝是在缺页中断处理时进行的,由于mmap()将文件直接映射到用户空间,所以中断处理函数根据这个映射关系,直接将文件从硬盘拷贝到用户空间,只进行了 一次数据拷贝 。因此,内存映射的效率要比 read/write效率高。
lmdb使用mmap过程
lmdb创建完env对象,打开时,会做data file和lock file的mmap映射:
env->me_lfd = open(lpath, O_RDWR|O_CREAT|MDB_CLOEXEC, mode);
void *m = mmap(NULL, rsize, PROT_READ|PROT_WRITE, MAP_SHARED,
env->me_lfd, 0);
env->me_txns = m;
env->me_fd = open(dpath, oflags, mode);
env->me_map = mmap(addr, env->me_mapsize, prot, MAP_SHARED,
env->me_fd, 0);
其他时刻都直接使用内存指针,通过系统级别的缺页异常获取对应的数据。页面内数据的获取和使用 MDB_CURSOR_GET 进行。页面的获取和key查询通过 mdb_page_get/mdb_page_search 完成.
页面头部大小及内容是固定的,具体的含义代表根据flags决定,在头部之后紧接的是node,真正的key-value值对所在位置的索引,因此访问这些node时通过指针计算即可得到对应的位置。
lmdb 之后是如何将页面给映射进进程地址空间呢.lmdb通过 mdb_page_get 函数以 pgno 为主要参数获得页面并返回页面指针。若仅仅是只读事务且环境对象是以只读方式打开的,page的获取很简单,根据 page= (MDB_page *)(env->me_map + env->me_psize * pgno); 获得。
在lmdb中B+Tree的是基于append-only B+Tree改造的。对于数据增加、修改、删除导致页面增加时,pageno也增加,当旧页面(数据旧版本)被重用时,pageno 保持不变,因此pageno保持了在数据文件中的顺序性,从而在获取页面时,只需要进行简单计算即可以。同时在创建env对象时,数据库已经被整个映射进整个进程空间,因此系统在映射时,会给数据库文件保留全部地址空间,从而在根据上述算法获取真实数据库,系统触发缺页错误,进而从数据文件中获取整个页面内容。此为最简单有效方式,否则不将全部数据映射进地址空间,对于未映射部分还需要在访问页面时判断是否已经被映射,未被映射时进行映射。
在需要时在通过文件方式写入。lmdb保证任意时刻只有一个写操作在进行,从而避免了并发时数据被破坏。
COW(Copy-on-write)
写入时复制(Copy-on-write,COW)是一种计算机程序设计领域的优化策略。其核心思想是,如果有多个调用者(callers)同时要求相同资源(如内存或磁盘上的数据存储),他们会共同获取相同的指针指向相同的资源,直到某个调用者试图修改资源的内容时,系统才会真正复制一份专用副本(private copy)给该调用者,而其他调用者所见到的最初的资源仍然保持不变。这过程对其他的调用者都是透明的(transparently)。此作法主要的优点是如果调用者没有修改该资源,就不会有副本(private copy)被创建,因此多个调用者只是读取操作时可以共享同一份资源。4
VCC/COW在LMDB中的实现
LMDB对MVCC加了一个限制,即只允许一个写线程存在,从根源上避免了写写冲突,当然代价就是写入的并发性能下降。因为只有一个写线程,所以不会不需要wal 日志、读写依赖队列、锁队列等一系列控制并发、事务回滚、数据恢复的基础工具。
MVCC的基础就是COW,对于不同的用户来说,若其在整个操作过程中不进行任何的数据改变,其就使用同一份数据即可,若需要进行改变,比如增加、删除、修改等,就需要在私有数据版本上进行,修改完成提交之后才给其他事务可见。
LMDB中,数据操作的基本单元是页,因此COW也是以页为单位,对应函数是 mdb_page_touch, mdb_page_copy ,copy真正实现页面复制,touch调用copy完成复制,然后修改pgno后插入到B+Tree当中,这样对于此次事务,后续的操作访问的数据页就是最新的数据页面,而非事务启动时对应的数据页面,且此页面与其他页面的关联关系仅在本事务页面列表中可见,对其他事务不可见。
实际上通过以上两个函数实现了MVCC的核心,对于读写的控制,通过 mdb_txn_begin 控制,在其中,事务启动时会检查读写锁的情况,若事务需要更新数据,则会被阻止,若只是读数据,则不管是否有写事务存在,读锁都可以获得。
MVCC的一个副作用就是对于存在大量写的应用,其数据版本很多,因此旧数据会占用大量空间,LMDB中通过freedb解决,即将不再使用的旧的数据页面空间插入到一棵B+Tree当中,这样旧空间在所有事务不再访问之后就可以被LMDB使用,从而避免了需要定期执行清理操作。当然其副作用是数据只能保持最新不能恢复到任意时刻.
摘自:http://wiki.dreamrunner.org/public_html/C-C++/Library-Notes/LMDB.html

