
Logistic Regression理论总结
简述:
1. LR 本质上是对正例负例的对数几率做线性回归,因为对数几率叫做logit,做的操作是线性回归,所以该模型叫做Logistic Regression。
2. LR 的输出可以看做是一种可能性,输出越大则为正例的可能性越大,但是这个概率不是正例的概率,是正例负例的对数几率。
3. LR的label并不一定要是0和1,也可以是-1和1,或者其他,只是一个标识,标识负例和正例。
4. Linear Regression和Logistic Regression的区别: 这主要是由于线性回归在整个实数域内敏感度一致,而分类范围,需要在[0,1]之内。而逻辑回归就是一种减小预测范围,将预测值限定为[0,1]间的一种回归模型,其回归方程与回归曲线如下图所示。逻辑曲线在z=0时,十分敏感,在z>>0或z<<0处,都不敏感,将预测值限定为(0,1)。
5. 模型非常简单。应用到线上时,prediction的计算非常容易做。在O(1)的时间复杂度之内就能够给出模型的预测值,这对于线上数据暴风雨般袭来的时候非常有用。
6. 模型可解释性强。对于LR模型,每个特征xi的参数wi就是该特征的权重,wi越大,则特征权重越大;越小,则特征权重越小。因此LR的模型往往非常直观,而且容易debug,而且也容易手动修改。
7. 模型的输出平滑。由于Logistic function的作用,LR的输出值是(0,1)之间的连续值,更重要的是,这个值能从某种角度上表示样本x是正例的可能性, 输出值越接近1,则样本是正例的可能性就越大,输出值越接近0,样本是负例的可能性就越大。
详细理解Logistic Regression:
1. 从最大似然估计 (MLE)来理解:(以正负label为1,0来举例)
直觉上,一个线性模型的输出值 y 越大,这个事件 P(Y=1|x) 发生的概率就越大。 另一方面,我们可以用事件的几率(odds)来表示事件发生与不发生的比值,假设发生的概率是 p ,那么发生的几率(odds)是 p/(1-p) , odds 的值域是 0 到正无穷,几率越大,发生的可能性越大。将我们的直觉与几率联系起来的就是下面这个(log odds)或者是 logit 函数:
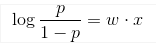
进而可以求出概率 p 关于 w 点乘 x 的表示:

这就是传说中的 sigmoid function 了,以 w 点乘 x 为自变量,函数图像如下:
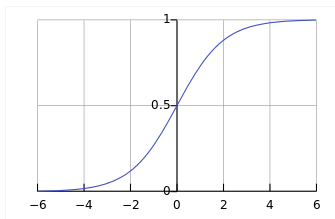
Logsitic regression 输出的是分到每一类的概率,参数估计的方法自然就是最大似然估计 (MLE) 咯。对于训练样本来说,假设每个样本是独立的,输出(标签)为 y = {0, 1},样本的似然函数就是将所有训练样本 label 对应的输出节点上的概率相乘, 令 p = P(Y=1|x) ,如果 y = 1, 概率就是 p, 如果 y = 0, 概率就是 1 - p , 将这两种情况合二为一,得到似然函数:

下面就是求极值,逻辑回归学习中通常采用的方法是梯度下降法 和 牛顿法。

2. 从最小化损失函数来理解:(以正负label为1,-1来举例)
LR 的基本假设是数据类别间是由一个线性的 decision boundary 隔开的,换句话说

再结合
![]()
可以解得:

在 training data 上进行 maximum log-likelihood 参数估计是
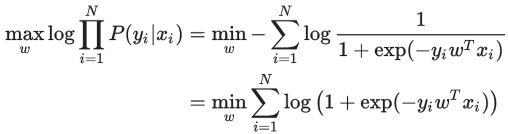
这个 binary 的情况所具有的特殊形式还可以从另一个角度来解释:先抛开 LR,直接考虑 Empirical Risk Minimization (ERM) 的训练规则,也就是最小化分类器在训练数据上的 error:

但是这是个离散的目标函数优化非常困难,所以我们寻求函数![]() 的一个 upper bound
的一个 upper bound![]() ,然后去最小化
,然后去最小化
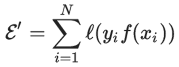
当取 (该函数通常称作 log loss)时 (如果要严格地作为一个 upper bound,我们需要使用以 2 为底的对数。不过由于只是对 loss function 做一个常数缩放,对优化结果并没有什么影响,所以方便起见我们实际使用自然对数。),即得到同上述一样的式子,也就是 LR 的目标函数,并且我们接下来会看到,这个 ERM 的 upper bound 是易于优化的。顺便提一句,通过选择其他的 upper bound,我们会导出其他一些常见的算法,例如 Hinge Loss 对应 SVM、exp-loss 对应 Boosting。注意到 log loss 是 convex 的,有时候我们还会加上一个 regularizer:
(该函数通常称作 log loss)时 (如果要严格地作为一个 upper bound,我们需要使用以 2 为底的对数。不过由于只是对 loss function 做一个常数缩放,对优化结果并没有什么影响,所以方便起见我们实际使用自然对数。),即得到同上述一样的式子,也就是 LR 的目标函数,并且我们接下来会看到,这个 ERM 的 upper bound 是易于优化的。顺便提一句,通过选择其他的 upper bound,我们会导出其他一些常见的算法,例如 Hinge Loss 对应 SVM、exp-loss 对应 Boosting。注意到 log loss 是 convex 的,有时候我们还会加上一个 regularizer:
![]()
此时目标函数是 strongly convex 的。接下来我们考虑用 gradient descent 来对目标函数进行优化。首先其 Gradient 是
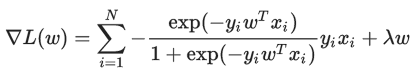
PS:下图中是各个损失函数,有最原始的0-1损失函数,以及用来在实际情况中作为其upper bound的替代损失函数,如 log loss,hinge loss,exp loss。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号