
Percona Xtradb Cluster的设计与实现
2014-02-10 17:48 竹 石 阅读(6734) 评论(9) 收藏 举报Percona Xtradb Cluster的设计与实现
Percona Xtradb Cluster的实现是在原mysql代码上通过Galera包将不同的mysql实例连接起来,实现了multi-master的集群架构,如下图所示:
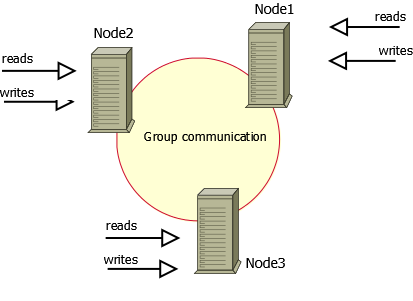
上图中有三个实例,组成了一个集群,而这三个节点与普通的主从架构不同,它们都可以作为主节点,三个节点是对等的,这种一般称为multi-master架构,当有客户端要写入或者读取数据时,随便连接哪个实例都是一样的,读到的数据是相同的,写入某一个节点之后,集群自己会将新数据同步到其它节点上面,这种架构不共享任何数据,是一种高冗余架构。
一般的使用方法是,在这个集群上面,再搭建一个中间层,这个中间层的功能包括负责根据指点算法找到一个实例供客户端连接,负责使三个实例的负载基本平衡,负责在客户端与实例的连接断开之后重连,也可以负责读写分离(在机器性能不同的情况下可以做这样的优化)等等,使用这个中间层之后,把这三个实例的架构在客户端方面是透明的,客户端只需要指定这个集群的数据源地址,连接到中间层即可,中间层会负责客户端与服务器实例连接的传递工作。
这里其实最核心的问题是,在三个实例之间,因为它们的关系是对等的,multi-master架构的,那么在同时写入的时候,如何保证整个集群数据的一致性,完整性与正确性。
在通常mysql的使用过程中,也不难实现一种multi-master架构,但是一般需要上层应用来配合,比如先要约定每个表必须要有自增列,并且如果是2个节点的情况下,一个节点只能写偶数的值,而另一个节点只能写奇数的值,同时2个节点之间互相做复制,因为2个节点写入的东西不同,所以复制不会冲突,在这种约定之下,可以基本实现多master的架构,也可以保证数据的完整性与一致性。但这种方式使用起来还是有限制,同时不具有扩展性,不是真正意义上的集群。
而通过使用Galera,它在里面通过判断键值的冲突方式实现了真正意义上的multi-master,下面就这个问题展开深入解析它的实现方式。
Percona Xtradb Cluster的实现方式基本上是在Percona MySQL Server的基础上将一个开源包Galera加入进来,实现了数据的同步。
Galera提供了很多接口,下面是几个最重要的接口:
1. 连接到指定集群名字的集群中,相当于是一个新的节点加入到一个已经存在的集群或者建立一个新的集群
wsrep_status_t (*connect) (wsrep_t* wsrep,
const char * cluster_name,
const char * cluster_url,
const char * state_donor,
wsrep_bool_t bootstrap);
2. 下面这个接口的作用是,在这个函数里面一直接收其它节点广播出来的数据,并且调用复制APPLY函数执行复制操作。这个函数只要返回,说明执行出错或者发生其它问题,只要正常这个函数一直阻塞在这里(具体应该不是阻塞,而是一直在recv函数中执行操作),而里面一直在调用某几个回调函数,回调函数会在初始化的时候指定。
wsrep_status_t (*recv)(wsrep_t* wsrep, void* recv_ctx);
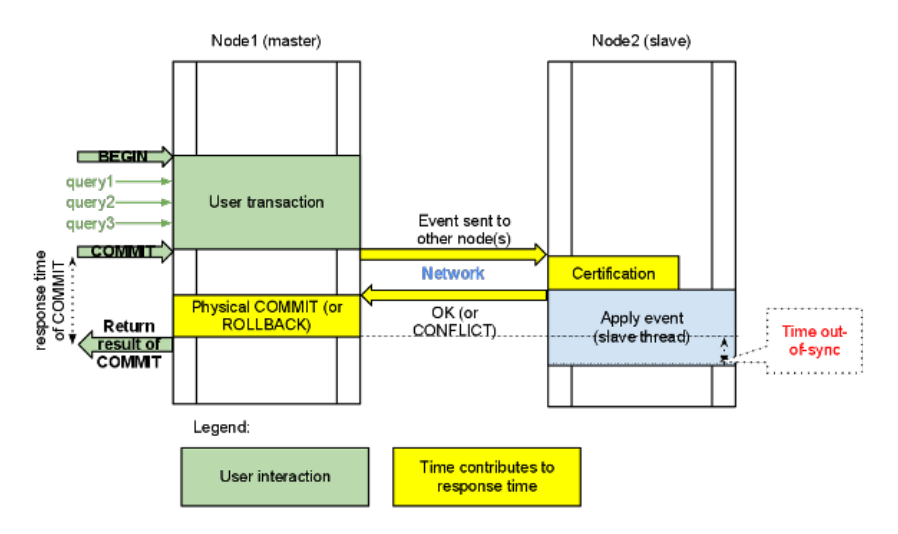
3. 下面这个接口的作用是在数据库事务提交时,会使用2阶段提交方式,在ha_trans_commit中,首先会针对每一个存储引擎执行一个ht->prepare函数,而对于Galera,在内部实现也是当作一个内嵌的存储引擎使用的,所以它执行的是wsrep_prepare,这个函数的功能是将在执行过程中产生的binlog通过下面会介绍到的接口append_data传到其它节点上面去(或者没有传过去,只是将这些数据对象存储在本地,等待提交操作),然后再通过下面这个接口pre_commit去与其它节点的Galera通讯检查有没有冲突,这个过程也就是在介绍Galera的文章中说到的certification阶段。下面表示出了这个验证过程。
wsrep_status_t (*pre_commit)(wsrep_t* wsrep,
wsrep_conn_id_t conn_id,
wsrep_ws_handle_t* ws_handle,
uint32_t flags,
wsrep_trx_meta_t* meta);
4. 下面这个接口的作用是,在由于某种原因导致在复制的过程中,其它节点已经成功验证,并没有冲突,但本节点自己出错了,则此时会通过这个接口模拟复制的过程在本节点将这个事务复制APPLY。
wsrep_status_t (*replay_trx)(wsrep_t* wsrep,
wsrep_ws_handle_t* ws_handle,
void* trx_ctx);
5. 下面这个接口是很重要的,在Galera中解决了一个关键问题是不同对等节点同时做写操作时,如果保证它们之间的冲突的问题。
wsrep_status_t (*append_key)(wsrep_t* wsrep,
wsrep_ws_handle_t* ws_handle,
const wsrep_key_t* keys,
size_t count,
enum wsrep_key_type type,
wsrep_bool_t copy);
6. 下面这个接口的作用上面已经提到过了,它是用来将同步数据传递到其它节点上保证所有节点的一致性,这个接口与上面的接口是对应的,相当于是key-value模式,这个是value,上面的是key,基本的作用是,key用来保证每个节点并发写入时不会冲突(当然冲突时会直接报错回滚),value用来保证每个节点的数据都是一致的,而对于mysql的实现方式而言,value完全就是binlog。
wsrep_status_t (*append_data)(wsrep_t* wsrep,
wsrep_ws_handle_t* ws_handle,
const struct wsrep_buf* data,
size_t count,
enum wsrep_data_type type,
wsrep_bool_t copy);
7. 下面这个接口的作用是初始化一个Galera对象,一个实例对应一个这样的对象,在起动服务器的时候初始化,将所有需要的参数,环境变量包括:集群姓名、实例地址,更重要的是,因为Galera拿到的是binlog,它是不知道如何复制数据的,所以这里必须要指定一个接口来做binlog的复制,初始化时告诉Galera,复制数据的接口为wsrep_apply_cb,那么这个接口接收到的数据就是binlog,它来解析并APPLY这些binlog,到这里时,Galera已经根据这个binlog对应的key做了冲突判断,并且验证通过的。还有一些类似的接口也要在这里指定,后面再做介绍。
wsrep_status_t (*init) (wsrep_t* wsrep,
const struct wsrep_init_args* args);
上面这几个接口是最基本的操作接口,这是Galera对外提供的接口。那么现在已经知道这些接口的情况下,就整个mysql工作流程到Galera包的调用说明一下一个PXC事务的工作方式。
首先在mysqld启动的时候,执行函数wsrep_init_startup,这个函数的功能是初始化整个mysql的Galera系统,它主要实现下面一些功能:
- 在这个函数中首先做的是wsrep_init,这里初始化很多变量,从变量wsrep_provider中找到对应的Galera动态链接包,找到它的接口(包括上面介绍的7个),最主要的是下面结构的初始化:
struct wsrep_init_args wsrep_args;
struct wsrep_gtid const state_id = { local_uuid, local_seqno };
wsrep_args.data_dir = wsrep_data_home_dir;
wsrep_args.node_name = (wsrep_node_name) ? wsrep_node_name : "";
wsrep_args.node_address = node_addr;
wsrep_args.node_incoming = inc_addr;
wsrep_args.options = (wsrep_provider_options) ? wsrep_provider_options : "";
wsrep_args.proto_ver = wsrep_max_protocol_version;
wsrep_args.state_id = &state_id;
wsrep_args.logger_cb = wsrep_log_cb;
wsrep_args.view_handler_cb = wsrep_view_handler_cb;
wsrep_args.apply_cb = wsrep_apply_cb;
wsrep_args.commit_cb = wsrep_commit_cb;
wsrep_args.unordered_cb = wsrep_unordered_cb;
wsrep_args.sst_donate_cb = wsrep_sst_donate_cb;
wsrep_args.synced_cb = wsrep_synced_cb;
rcode = wsrep->init(wsrep, &wsrep_args);
这个结构是Galera节点信息初始化的入口,在最后它会通过wsrep->init(wsrep, &wsrep_args);将当前wsrep初始化,这个wsrep就是当前实例的Galera的全局对象。
wsrep_args.data_dir表示的是当前数据库的目录,对应变量wsrep_data_home_dir
wsrep_args.node_name表示的是当前实例的名字,对应变量wsrep_node_name,一般默认会被设置为机器名
wsrep_args.node_address表示当前节点的地址,对应变量wsrep_node_address,可以不设置,如果不设置的话,系统会自己找到ip。
wsrep_args.node_incoming表示可以接收连接请求的节点,对应状态变量wsrep_incoming_addresses
wsrep_args.state_id表示一个节点的UUID,对应状态变量wsrep_cluster_state_uuid
再下面的是几个回调函数的初始化,需要回调函数的原因有:
- mysql与galera是分层的,上层可以调用galera的接口来复制数据库的,但是对于galera,它是不知道如何提交一个事务,如何判断写入结果集是不是冲突,也不知道如何做sst,更不知道如何解析binlog来做复制。所以上层必须要向galera下层说明如何去解析,如何去执行等。
- 框架的一般实现方式,这属于废话。
下面分别介绍每个回调函数的功能:
- wsrep_log_cb:用来做日志的,因为galera产生一些日志后,需要告诉mysql,转换为mysql的日志,所以它需要这个接口告诉mysql,让mysql记录底层产生的日志。
- wsrep_view_handler_cb:这是Galera启动之后,第一个需要执行的回调函数,在新节点的Galera加入到并且已经连接到集群中时,新node会拿自己的local_state_uuid和集群的cluster_state_uuid对比,如果这两者有区别时,就需要做sst或者ist,此时这个回调函数所做的工作是,根据不同的同步方式,准备不同的同步命令:
- 对于mysqldump,这里只需要将数据接收地址及执行方式告诉集群即可。因为对于这种的实现方式是,doner直接在远程连接新加入的mysql实例,将它自己的所有数据dump出来直接用mysql执行了,所以新加入的节点不需要做任何操作,因为doner在导入的时候,如果新节点已经启动完成,也是可以做操作的。
- 对于rsync,这里需要做的是告诉集群同步方式及执行命令,因为这与mysqldump不同,对于rsync与xtrabackup,它们用到的同步方式分别是脚本wsrep_sst_rsync,wsrep_sst_xtrabackup,这2个脚本都放在安装目录的bin下面,在这里会把相应的命令生成出来,对于rsync,类似是这样的命令:
wsrep_sst_rsync --role 'joiner' --address '192.168.236.231' --auth 'pxc_sst:txsimIj3eSb8fttz' --datadir '/home/q/zhufeng.wang/pxcdata2/' --defaults-file '/home/q/zhufeng.wang/pxcdata2/my.cnf' --parent '11048',
在这个命令中,--role指明当前节点是joiner还是doner,因为在脚本中会做不同处理,--address表示向什么地址同步,--auth是在配置文件中指定的权限信息,--datadir表示当前新加入的库的数据目录,--defaults-file表示新加入节点的配置文件,--parent表示加入者的进程id号。
这里生成的命令的作用是,以joiner的角色执行脚本wsrep_sst_rsync,从脚本中可以看到,它会给mysql返回一个“ready 192.168.236.231:4444/rsync_sst”的字符串,地址和ip表示的是加入节点上面用来传数据的RSYNC(具体说应该是NC)的地址和端口,4444是脚本中已经写好的值,如果这个端口已经在用了,则会失败。而后面的rsync_sst是用来检查是不是已经有人在做了,如果文件rsync_sst.pid已经存在,则说明正在执行,此时执行会失败。如果正常的话则会创建另一个文件rsync_sst.conf,这是一个配置文件,用来让加入节点做rsync操作的,里面指定了path,read only,timeout等信息。
上面的问题解释清楚之后,脚本需要执行的就是等待donor给它传数据了,它会被阻塞,直到数据成功传送完成。
此时加入节点已经将信息“执行方式+192.168.236.231:4444/rsync_sst“传给了Galera,Galera在得到这个信息,并且等到选择一个合适的donor出来之后,这个donor会给端口4444传数据。脚本等待并且接收数据完成之后,就说明恢复完成了,因为rsync是直接复制文件的。那么此时脚本会返回一个UUID:seqno信息给加入节点,加入节点在这之前一直处于等待状态,如果收到这些信息之后说明恢复完成,则继续启动数据库。 - 对于xtrabackup,前面信息都是一样的,只是用到的脚本不同,脚本是wsrep_sst_xtrabackup,也同样会先执行一个参数角色为joiner的脚本wsrep_sst_xtrabackup,这个部分也会给加入节点返回一个字符串信息:ready 192.168.236.231:4444/xtrabackup_sst,返回之后,脚本就在等待NC将所有donor备份的数据传过来直到完成。还是同样地,Galera得到192.168.236.231:4444/xtrabackup_sst信息之后,集群会选择一个donor出来给这个地址发送备份数据。等待传送完成之后,脚本会继续执行,此时执行的就是xtrabackup的数据恢复操作,恢复完成之后,脚本会给加入节点输出UUID:seqno信息,而此时加入节点一直在等待的,如果发现脚本给它这些信息之后,说明已经做完sst,那么加入完成,数据库正常继续启动。
- wsrep_apply_cb:这个函数其实很容易明白,从名字即可看出是apply,因为在Galera层,上面已经讲过了,它是不知道binlog是什么东西的,它只知道key是什么东西,同时它判断是不是冲突也就是根据key来实现的,根本不会用到binlog,那么在Galera中,如果已经判断到一个节点上面的一个事务操作没有出现冲突,那Galera怎么知道如何去做复制呢?让其它节点也产生同样的修改呢?那么这个函数就是告诉Galera怎么去做复制,在下层,如果判断出不冲突,则Galera直接执行这个回调函数即可,因为这个函数处理的直接就是binlog的恢复操作。它拿到的数据就是一个完成的binlog数据。
- wsrep_commit_cb:同样的道理,对于Galera,也是有事务的,它在完成一个操作之后,如果本地执行成功,则需要执行提交,如果失败了,则要回滚,那么Galera也还是不知道如何去提交,或者回滚,或者回滚提交需要做什么事情,那么这里也是要告诉Galera这些东西。
- wsrep_unordered_cb:什么都不做
- wsrep_sst_donate_cb:这个回调函数很重要,从名字看出,它是用来提供donate的,确实是的,在上面wsrep_view_handler_cb中介绍的做SST的时候已经介绍了一点这方面的信息,那这个函数是什么时候用呢?
它是在wsrep_view_handler_cb函数告诉加入节点的地址端口及执行方式之后,这个是告诉pxc集群了,那么集群会选择一个合适的节点去做donor,那么选择出来之后,它怎么知道如何去做?那么这里就是要告诉它如何去做,把数据发送到哪里等等,因为wsrep_view_handler_cb告诉集群的信息只是一个地址、端口及执行方式,是一个字符串而已,那么wsrep_sst_donate_cb拿到的东西就是这个信息,而此时加入节点正处于等待donor传数据给它的状态,应该是阻塞的。
那么这个回调函数做的是什么呢?首先它会根据传给它的执行方式判断是如何去做,现在有几种情况:- 对于mysqldump方式,这里做的事情是执行下面的命令: "wsrep_sst_mysqldump "
WSREP_SST_OPT_USER " '%s' "WSREP_SST_OPT_PSWD " '%s' "WSREP_SST_OPT_HOST " '%s' "WSREP_SST_OPT_PORT " '%s' "WSREP_SST_OPT_LPORT " '%u' "WSREP_SST_OPT_SOCKET " '%s' "WSREP_SST_OPT_DATA " '%s' "WSREP_SST_OPT_GTID " '%s:%lld'"很明显,它现在执行的是脚本 wsrep_sst_mysqldump ,后面是它的参数,其实里面用到的就是mysqldump命令,脚本中主要的操作是mysqldump $AUTH -S$WSREP_SST_OPT_SOCKET --add-drop-database --add-drop-table --skip-add-locks --create-options --disable-keys --extended-insert --skip-lock-tables --quick --set-charset --skip-comments --flush-privileges --all-databases可以看出它是将全库导出的,导出之后直接在远程将导出的sql文件通过mysql命令直接执行了,简单说就是远程执行了一堆的sql语句,将所有的信息复制到(远程执行sql)新加入节点中。而这也正是mysqldump不像其它2种执行方式一样在新加入节点还需要做些操作,包括恢复,等待等操作,mysqldump方式在新加入节点也是不需要等待
- 对于rsync方式,执行的命令是:wsrep_sst_rsync "
WSREP_SST_OPT_ROLE " 'donor' "WSREP_SST_OPT_ADDR " '%s' "WSREP_SST_OPT_AUTH " '%s' "WSREP_SST_OPT_SOCKET " '%s' "WSREP_SST_OPT_DATA " '%s' "WSREP_SST_OPT_CONF " '%s' "WSREP_SST_OPT_GTID " '%s:%lld'"可以看出,它执行的还是脚本wsrep_sst_rsync ,不过现在的角色是donor,在脚本中,它就是把库下面所有的有用的文件都一起用rsync传给加入节点的NC,这又与上面说的接起来了,这边传数据,那么收数据,这边完成之后,那么收数据完成了,则SST也就做完了。
- 对于Xtrabackup方式,执行的命令是一样的,只是用到的脚本是wsrep_sst_xtrabackup,道理与上面完全相同,这边做备份,那么接收数据,等各自完成之后,也就完成了SST。
- 对于mysqldump方式,这里做的事情是执行下面的命令: "wsrep_sst_mysqldump "
- wsrep_synced_cb:这个回调函数的作用是,在mysql启动的时候,会有一些状态不一致的情况,那么当状态不一致的时候,系统会将当前的状态设置为不可用,也就是wsrep_ready这个状态变量为OFF,那么为了保证数据的一致性,或者由于复制启动的时候会影响到数据的一致性,那么在这个状态的时候,从库的复制线程会等待这个状态变为ON的时候才会继续执行,否则一直等待,那么这个回调函数做的事情就是告诉新加入节点或者donor节点,现在的同步已经完成了,状态已经是一致的了,可以继续做下面的操作了。所以此时复制会继续开始。
自从上次说了wsrep_init_startup之后,感觉已经过了很久了,中间大概都有5000个字了。。。
那么现在还接着wsrep_init_startup继续说:
在执行了上面所说的wsrep_init之后,接下来要做的事情是:
执行函数wsrep_start_replication,这个所做的事情是调用第一个接口connect,这个函数的功能已经说过了,就是加入集群,算是报个到吧。
接着再做创建一个线程wsrep_rollback_process,专门做回滚操作。
接着再做wsrep_create_appliers,专门做APPLY操作,这里创建的线程是wsrep_replication_process,可以有多个,这个会根据变量wsrep_slave_threads(其实只创建wsrep_slave_threads-1个线程,后面会说到原因)来创建的,这个就是真正的所谓“多线程复制”。
在这个线程中,用到了接口wsrep->recv(wsrep, ( void *)thd);
对于函数recv,从来不返回,除非是出错了,这里面的逻辑下面简单说一下:
还是从上面做SST开始吧:
在做SST前,其实只是创建一个线程,如果设置的线程数大于1,则做上面已经说了,会创建wsrep_slave_threads-1个线程,这原因是:
SST这前,只创建一个,是为了让单独一个线程去处理SST的工作。
上面已经说过了,在新加入节点将地址信息发送给集群之后,集群会选择一个donor出来
而创建的那一个单独的线程wsrep_replication_process会阻塞在wsrep->recv里面,因为选择出来的donor发现它是新加入的节点,所以它会直接在里面调用回调函数wsrep_sst_donate_cb,它的参数就是集群给它的“方式+192.168.236.231:4444/rsync_sst”类似的东西,所以这就回到了上面对回调函数wsrep_sst_donate_cb的说明了,它先做备份,然后再将数据复制到新加入节点中。
在做完SST之后,然后把剩下的线程创建起来(如果配置的wsrep_slave_threads大于1的话)。
再接着上面的wsrep_init_startup函数说:
此时调用最后一个wsrep_sst_wait,很明显,是等待SST完成,前面已经说过了,新节点一直在等,直到已经做完SST,然后再继续启动数据库。
到此为止,谈到的都是Galera的启动过程及SST的东西,下面就正常执行过程讲述一下,可以大概的了解它的原理。
首先客户端选择一个集群中的服务器连接上去之后,此时其实与连接一个单点是完全相同的。
在执行一个sql的时候,在非pxc的情况下,执行的最终调用的函数是mysql_parse,而对于pxc来说,它调用的是wsrep_mysql_parse,对于它们的区别,后面再讲。
首先,将一个操作可以分为几个阶段:
- 语句分析:对于这个阶段,执行的都是本地操作,不会涉及到集群的操作,所以和普通的mysql执行分析操作没有区别。
- 本地执行:对于第2阶段,这里会做一个很重要的操作,那就是在插入、更新、删除记录时会调用一个wsrep_append_keys函数,它的作用就是将当前被修改的记录的关键字(其实就是当前表的关键字在这行记录中对应的列的值,如果没有关键字,则就是rowid,因为pxc只支持innodb)提取出来,再按照Galera接口需要要的格式组装起来,然后再通过Galera的接口append_key(上面已经详细介绍过了)传给集群。
对于不同操作,其实KEY的最终数据是不同的,如果是插入,KEY当然只有新记录的键值,对于更新,包括了旧数据及新数据的键值,对于删除,则只有老数据的键值。同时如果键值具有多个列,则它们的组合方式是以列优先,其次才是新旧值,也就是说,对于更新记录,它的顺序应该是下面这样的:
旧键第一个值 新键第一个值 旧键第二个值 新键第二个值 ...... ...... 旧键第n个值 新键第n个值 当然对于插入行,只是简单的下面的格式:新键第一个值 新键第二个值 ...... 新键第n个值 还是上面说的,galera完全是靠这些KEY来判断是不是已经和其它客户端的操作造成了冲突的。 - 事务提交:在这个阶段,首先会做一个两阶段提交的wsrep_prepare,这里面会执行一个核心操作,对应的函数是wsrep_run_wsrep_commit,在这个函数中做了2个重要的操作,首先将这个事务产生的binlog通过接口append_data传给集群,这部分data是与上面的key对应的,组成了key-value结构,key是用来判断是不是冲突的,value是用来复制的,它是完完整整的binlog,在做复制的时候其它节点直接拿来做apply。另一件事就是调用接口pre_commit,这在上面已经说过了,其实就里请求集群对当前key-value进行验证,如果验证通过,则地本继续执行提交,将数据固化,而如果验证失败,则回滚即可。
那么现在连接服务器的工作流程已经介绍完,但是对于其它的节点而言,因为集群已经验证通过,本地服务器已经提交完成,那么其它节点在验证通过之后,会在recv接口中继续执行,调用前面说到的wsrep_apply_cb回调函数,那么此时它拿到的就是上面事务提交时的binlog数据,直接做apply就好了。
上面提到,在pxc中用到的执行函数为wsrep_mysql_parse,而在普通的mysql中用到的是mysql_parse,这2个的区别是什么呢?首先wsrep_mysql_parse调用了mysql_parse,只是在它之后,还做了另外一些操作,下面就这个操作做一个描述:
这里存在一种情况,在当前执行节点的某一个事务在执行pre_commit操作并等待的过程中,此时有另一个事务,这个事务有可能是来自其它节点的复制事务(在本地表现为复制线程),它的优先级比当前事务高,并且正好这2个事务在某一个数据行上面是冲突的,那么此时就会将当前事务杀死(实际上是调用了一次abort_pre_commit函数,这个函数也是Galera的一个接口,上面没有做过介绍),而正在此时,pre_commit已经在其它节点上面完成验证,并且其它节点都已经复制完成,在这种情况下,pre_commit函数会返回一个错误码WSREP_BF_ABORT,表示其它节点复制完成,当前事务被杀死,那么此时当前连接会一直返回到wsrep_mysql_parse中,也就是跳出mysql_parse(因为上面的操作其实都在这个函数中,只是wsrep_mysql_parse将mysql_parse包了一层),执行后面的操作,这里的操作是在将刚才被杀死的事务重新做一遍,以slave模式做一遍,像复制一样,具体对应的函数为wsrep_replay_transaction。
关于区别,仅此而已。
PXC的DDL实现说明
下面再详细说一下关于在PXC中的DDL实现方式,这里面可能存在一些问题:
pxc对于DDL,就不那么严谨了,所有的DDL都是通过简单的对象封锁实现的,这里又用到了Galera的另外2个接口,之前没有介绍到的,分别是:
wsrep_status_t (*to_execute_start)(wsrep_t* wsrep,
wsrep_conn_id_t conn_id,
const wsrep_key_t* keys,
size_t keys_num,
const struct wsrep_buf* action,
size_t count,
wsrep_trx_meta_t* meta);
及
wsrep_status_t (*to_execute_end)(wsrep_t* wsrep, wsrep_conn_id_t conn_id);
to_execute_start是用来上锁的,主要的参数就是keys,里面的信息就是数据库名及表名等对象名,如果是对库操作,则只有库名,参数action表示的是当前执行的DDL的语句级的binlog,那么这个是用来复制的,在其它节点直接执行这个binlog就好了。
to_execute_end是解锁的,等中间的操作完成之后,就会调用这个接口。
在锁定区间内,因为这是Galera的接口,所以相当于在整个集群中对操作对象做了锁定。
在锁定之后,执行的DDL操作只是本地的,与集群的是没有任何关系的,因为此时其实已经通过一开始的to_execute_start函数已经在其它节点上面将这个操作已经完成了。
关于这一点,很容易测试出来
构造一个2个节点的集群,第一个节点先设置wsrep_on为0,使得它的任何操作不做同步;
现在创建一个表,这个表是本地的,不会复制到另一个节点上面去。
此时将wsrep_on设置为1
然后再执行一次这个创建表的语句
此时发现,本地的执行报错了,然后再观察一下另一个节点,竟然神奇的出现了?
其实这是一种不一致的状态。
上面的测试,如果第二次创建的表名是相同的,但是结构不同,这就导致2个节点的结构不同,而创建成功了。
上面的测试是说到了另一个节点某一个表不存在的情况,本地是存在的。
现在如果反过来说,本地是不存在的,而另一个节点已经存在,那么按照上面执行的逻辑可以知道,通过to_execute_start,另一个节点的复制肯定是不能成功的,因为已经存在了,这点只会在log文件中写一个错误日志表现出来,而没有采取任何其它措施,那个节点还是正常的。而本地节点则正常的创建这个表,问题还是一样的。
其实上面关于ddl的问题官方的wiki上面已经说清楚了,请参照:
具体这个问题为:
Q: How DDLs are handled by Galera?
Q&A
- 如果出现不一致,节点如何被集群踢出
构造下面一种场景:
正常运行的2个节点的集群,分别命名为A和B,现在先在A上面创建一个表
A:create table t (sno int primary key);
B:然后发现B已经同步了这个表
A:设置A节点,让它的修改不再同步到其它节点,这是一种手动构造不一致的方式
set wsrep_on=0;
然后在A上面插入一条记录,那么这个记录就不会被复制到B上面
A:insert into t values(1);
此时查看A已经有一条1的记录,而B上面还是空表,说明是正常的。
现在在B的节点上面插入一条同样的记录,因为上面的wsrep_on只是设置了不从A同步数据到B,而此时B还是可以同步数据到A的,那么在B上执行同样的插入语句:
B:insert into t values(1);
此时A挂了……
分析:这个挂是在recv接口中发生的,因为复制是在这个里面发生的,通过调用回调函数wsrep_apply_cb实现,而此时A节点的t表已经有一条记录了,B节点再做的时候,这里复制会执行失败,导致wsrep_apply_cb接口执行时会报错,然后recv知道报错之后,就直接将自己这个进程退出了,这样就造成了节点被中踢出的现象(其实是自己不想干了)。不过这种表现上是优雅的,因为自己在离开前已经办好了一切离开的手续了,属于正常退出。
到现在为止,所有的关于pxc实现方式已经基本搞清楚,其它问题均是mysql本身的问题
总结:pxc架构上面可谓是实现了真正的集群,最主要的特点是多主的,并且基本没有延时,这样就解决了mysql主从复制的很多问题,但其中还是存在一些问题的,比如2个节点容易出现脑裂现象,这必须要通过另一个工具去做一个监控及评判,而官方推荐最好是搞三个节点,但可能会造成一定程度的空间及机器的浪费,但在实际使用时可以适当的在一个实例上面多放置几个库,来提高使用效率。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号