

Python之路【第十一篇】: 进程与线程
阅读目录
一. cpython并发编程之多进程
1.1 multiprocessing模块介绍
1.2 Process类的介绍
1.3 Process类的使用
1.4 进程间通信(IPC)方式一:队列
1.5 进程间通信(IPC)方式二:管道(了解部分)
1.6 进程间通信方式三:共享数据
1.7 进程同步(锁),信号量,事件...
1.8 进程池
二. python并发编程之多线程
2.1 threading模块
2.2 Python GIL(Global Interpreter Lock)
2.3 同步锁
2.4 死锁与递归锁
2.5 信号量Semahpore
2.6 事件Event
2.7 条件Condition(了解)
2.8 定时器Timer
2.9 线程queue
2.10 Python标准模块--concurrent.futures
三. 协程
四. 协程模块greenlet
五. gevent模块(单线程并发)
六. 综合应用
一. cpython并发编程之多进程
1.1 multiprocessing模块介绍
python中的多线程无法利用多核优势,如果想要充分地使用多核CPU的资源(os.cpu_count()查看),在python中大部分情况需要使用多进程。Python提供了非常好用的多进程包multiprocessing。
multiprocessing模块用来开启子进程,并在子进程中执行我们定制的任务(比如函数),该模块与多线程模块threading的编程接口类似。
multiprocessing模块的功能众多:支持子进程、通信和共享数据、执行不同形式的同步,提供了Process、Queue、Pipe、Lock等组件。
强调: 与线程不同,进程没有任何共享状态,进程修改的数据,改动仅限于该进程内。
1.2 Process类的介绍
创建进程的类:
Process([group [, target [, name [, args [, kwargs]]]]]),由该类实例化得到的对象,表示一个子进程中的任务(尚未启动) 强调: 1. 需要使用关键字的方式来指定参数 2. args指定的为传给target函数的位置参数,是一个元组形式,必须有逗号
参数介绍:
group参数未使用,值始终为None target表示调用对象,即子进程要执行的任务 args表示调用对象的位置参数元组,args=(1,2,'egon',) kwargs表示调用对象的字典,kwargs={'name':'egon','age':18} name为子进程的名称
方法介绍:
p.start():启动进程,并调用该子进程中的p.run()
p.run():进程启动时运行的方法,正是它去调用target指定的函数,我们自定义类的类中一定要实现该方法
p.terminate():强制终止进程p,不会进行任何清理操作,如果p创建了子进程,该子进程就成了僵尸进程,使用该方法需要特别小心这种情况。如果p还保存了一个锁那么也将不会被释放,进而导致死锁
p.is_alive():如果p仍然运行,返回True
p.join([timeout]):主线程等待p终止(强调:是主线程处于等的状态,而p是处于运行的状态)。timeout是可选的超时时间,需要强调的是,p.join只能join住start开启的进程,而不能join住run开启的进程
属性介绍:
p.daemon:默认值为False,如果设为True,代表p为后台运行的守护进程,当p的父进程终止时,p也随之终止,并且设定为True后,p不能创建自己的新进程,必须在p.start()之前设置
p.name:进程的名称
p.pid:进程的pid
p.exitcode:进程在运行时为None、如果为–N,表示被信号N结束(了解即可)
p.authkey:进程的身份验证键,默认是由os.urandom()随机生成的32字符的字符串。这个键的用途是为涉及网络连接的底层进程间通信提供安全性,这类连接只有在具有相同的身份验证键时才能成功(了解即可)
1.3 Process类的使用
1.创建并开启子进程的两种方式
注: 在windows中Process()必须放到# if __name__ == '__main__':下
Since Windows has no fork, the multiprocessing module starts a new Python process and imports the calling module.
If Process() gets called upon import, then this sets off an infinite succession of new processes (or until your machine runs out of resources).
This is the reason for hiding calls to Process() inside
if __name__ == "__main__"
since statements inside this if-statement will not get called upon import.
由于Windows没有fork,多处理模块启动一个新的Python进程并导入调用模块。
如果在导入时调用Process(),那么这将启动无限继承的新进程(或直到机器耗尽资源)。
这是隐藏对Process()内部调用的原理,使用if __name__ == “__main __”,这个if语句中的语句将不会在导入时被调用。


#! /usr/bin/env python # -*- coding: utf-8 -*- # __author__ = "shuke" # Date: 2017/6/26 0026 import time import random from multiprocessing import Process def talk(name): print("%s is say 'Hello'" % name) time.sleep(3) print("talking end") if __name__ == '__main__': p1=Process(target=talk,args=('Shuke',)) # args是元组的形式,必须加逗号 p2=Process(target=talk,args=('Tom',)) p3=Process(target=talk,args=('Eric',)) p4=Process(target=talk,args=('Lucy',)) p1.start() p2.start() p3.start() p4.start()
import time import random from multiprocessing import Process class Talk(Process): # 继承Process类 def __init__(self,name): super(Talk, self).__init__() # 继承父类__init__方法 self.name=name def run(self): # 必须实现一个run方法,规定 print("%s is say 'Hello'" % self.name) time.sleep(random.randint(1,3)) print("%s talking end"% self.name) if __name__ == '__main__': p1=Talk('Shuke') p2=Talk('Eric') p3=Talk('Tome') p4=Talk('Lucy') p1.start() # start方法会自动调用run方法运行 p2.start() p3.start() p4.start() print("主线程") ''' 执行结果: 主线程 Shuke is say 'Hello' Lucy is say 'Hello' Tome is say 'Hello' Eric is say 'Hello' Tome talking end Eric talking end Lucy talking end Shuke talking end '''
并发实现socket通信示例
from socket import * from multiprocessing import Process server = socket(AF_INET, SOCK_STREAM) server.setsockopt(SOL_SOCKET, SO_REUSEADDR, 1) server.bind(('127.0.0.1', 8081)) server.listen(5) def talk(conn, client_addr): while True: try: msg = conn.recv(1024) if not msg: break conn.send(msg.upper()) except Exception: break if __name__ == '__main__': # windows下start进程一定要写到这下面 while True: conn, addr = server.accept() p = Process(target=talk, args=(conn, addr)) p.start()
from socket import * client=socket(AF_INET,SOCK_STREAM) client.connect(('127.0.0.1',8081)) while True: msg=input('>>:').strip() if not msg:continue client.send(msg.encode('utf-8')) msg=client.recv(1024) print(msg.decode('utf-8'))
存在的问题:
每来一个客户端,都在服务端开启一个进程,如果并发来一个万个客户端,要开启一万个进程吗,你自己尝试着在你自己的机器上开启一万个,10万个进程试一试。
解决方法:进程池
2. Process对象的其他方法和属性
进程对象的其他方法一:terminate,is_alive
import time import random from multiprocessing import Process class Talk(Process): # 继承Process类 def __init__(self,name): super(Talk, self).__init__() # 继承父类__init__方法 self.name=name def run(self): # 必须实现一个run方法,规定 print("%s is say 'Hello'" % self.name) time.sleep(random.randint(1,3)) print("%s talking end"% self.name) if __name__ == '__main__': p1=Talk('Shuke') p1.start() # start方法会自动调用run方法运行 p1.terminate() # 关闭进程,不会立即关闭,所以is_alive立刻查看的结果可能还是存活 print(p1.is_alive())# True time.sleep(1) # 模拟CPU调度的延时 print("====分割线====") print(p1.is_alive())# False ''' 执行结果: True ====分割线==== False '''
进程对象的其他方法二:p1.daemon=True,p1.join
import time import random from multiprocessing import Process class Talk(Process): def __init__(self,name): super(Talk, self).__init__() self.name=name def run(self): print("%s is say 'Hello'" % self.name) time.sleep(random.randint(1,3)) print("%s talking end"% self.name) if __name__ == '__main__': p1=Talk('Shuke') p1.daemon = True # 一定要在p1.start()前设置,设置p1为守护进程,禁止p1创建子进程,并且父进程结束,p1跟着一起结束 p1.start() # start方法会自动调用run方法运行 p1.join(0.0001) # 等待p1停止,等0.0001秒就不再等了
剖析p1.join
from multiprocessing import Process import time import random def piao(name): print('%s is piaoing' %name) time.sleep(random.randint(1,3)) print('%s is piao end' %name) p1=Process(target=piao,args=('egon',)) p2=Process(target=piao,args=('alex',)) p3=Process(target=piao,args=('yuanhao',)) p4=Process(target=piao,args=('wupeiqi',)) p1.start() p2.start() p3.start() p4.start() p1.join() p2.join() p3.join() p4.join() print('主线程') #疑问:既然join是等待进程结束,那么我像下面这样写,进程不就又变成串行的了吗? #当然不是了 #注意:进程只要start就会在开始运行了,所以p1-p4.start()时,系统中已经有四个并发的进程了 #而我们p1.join()是在等p1结束,没错p1只要不结束主线程就会一直卡在原地,这也是问题的关键 #join是让主线程等,而p1-p4仍然是并发执行的,p1.join的时候,其余p2,p3,p4仍然在运行,等p1.join结束,可能p2,p3,p4早已经结束了,这样p2.join,p3.join.p4.join直接通过 # 所以4个join花费的总时间仍然是耗费时间最长的那个进程运行的时间 #上述启动进程与join进程可以简写为 p_l=[p1,p2,p3,p4] for p in p_l: p.start() for p in p_l: p.join()
进程对象的其他属性:name,pid
import time import random from multiprocessing import Process class Talk(Process): def __init__(self,name): # self.name=name # super().__init__() #Process的__init__方法会执行self.name=Piao-1, # #所以加到这里,会覆盖我们的self.name=name # 为我们开启的进程设置名字的做法 super().__init__() self.name=name def run(self): print("%s is say 'Hello'" % self.name) time.sleep(random.randint(1,3)) print("%s talking end"% self.name) if __name__ == '__main__': p1=Talk('Shuke') p1.start() # start方法会自动调用run方法运行 print("====") print(p1.pid) # 查看pid ''' 执行结果: ==== 20484 Shuke is say 'Hello' Shuke talking end '''
3. 进程同步(锁)
进程之间数据不共享,但是共享同一套文件系统,所以访问同一个文件,或同一个打印终端,是没有问题的
#多进程共享一个打印终端(用python2测试看两个进程同时往一个终端打印,出现打印到一行的错误) from multiprocessing import Process import time class Logger(Process): def __init__(self): super(Logger,self).__init__() def run(self): print(self.name) for i in range(1000000): l=Logger() l.start()
#多进程共享一套文件系统 from multiprocessing import Process import time,random def work(f,msg): f.write(msg) f.flush() f=open('a.txt','w') #在windows上无法把f当做参数传入,可以传入一个文件名,然后在work内用a+的方式打开文件,进行写入测试 for i in range(5): p=Process(target=work,args=(f,str(i))) p.start()
注: 既然可以用文件共享数据,那么进程间通信用文件作为数据传输介质就可以了啊,可以,但是有问题:
1.效率
2.需要自己加锁处理
需知:加锁的目的是为了保证多个进程修改同一块数据时,同一时间只能有一个修改,即串行的修改,没错,速度是慢了,牺牲了速度而保证了数据安全。
进程之间数据隔离,但是共享一套文件系统,因而可以通过文件来实现进程直接的通信,但问题是必须自己加锁处理。所以,就让我们用文件当做数据库,模拟抢票,(Lock互斥锁),见下文抢票示例。
学习了通过使用共享的文件的方式,实现进程直接的共享,即共享数据的方式,这种方式必须考虑周全同步、锁等问题。而且文件是操作系统提供的抽象,可以作为进程直接通信的介质,与mutiprocess模块无关。
但其实mutiprocessing模块为我们提供了基于消息的IPC通信机制:队列和管道。
IPC机制中的队列又是基于(管道+锁)实现的,可以让我们从复杂的锁问题中解脱出来,我们应该尽量避免使用共享数据,尽可能使用消息传递和队列,避免处理复杂的同步和锁问题,而且在进程数目增多时,往往可以获得更好的可扩展性。
1.4 进程间通信(IPC)方式一:队列
进程彼此之间互相隔离,要实现进程间通信,即IPC,multiprocessing模块支持两种形式:队列和管道,这两种方式都是使用消息传递的,广泛应用在分布式系统中。
Queue模块有三种队列及构造函数:
1. Python Queue模块的FIFO队列先进先出。 class Queue.Queue(maxsize)
2. LIFO类似于堆,即先进后出。 class Queue.LifoQueue(maxsize)
3. 还有一种是优先级队列级别越低越先出来。 class Queue.PriorityQueue(maxsize)
Queue类(创建队列)
Queue([maxsize]):创建共享的进程队列,Queue是多进程安全的队列,可以使用Queue实现多进程之间的数据传递,底层是以管道和锁的方式实现的。
参数介绍:
maxsize是队列中允许最大项数,省略则无大小限制。
方法介绍:
主要方法:
q.put方法用以插入数据到队列中,put方法还有两个可选参数:blocked和timeout。如果blocked为True(默认值),并且timeout为正值,该方法会阻塞timeout指定的时间,直到该队列有剩余的空间。如果超时,会抛出Queue.Full异常。如果blocked为False,但该Queue已满,会立即抛出Queue.Full异常。
q.get方法可以从队列读取并且删除一个元素。同样,get方法有两个可选参数:blocked和timeout。如果blocked为True(默认值),并且timeout为正值,那么在等待时间内没有取到任何元素,会抛出Queue.Empty异常。如果blocked为False,有两种情况存在,如果Queue有一个值可用,则立即返回该值,否则,如果队列为空,则立即抛出Queue.Empty异常.
q.get_nowait():同q.get(False)
q.put_nowait():同q.put(False)
q.empty():调用此方法时q为空则返回True,该结果不可靠,比如在返回True的过程中,如果队列中又加入了项目。
q.full():调用此方法时q已满则返回True,该结果不可靠,比如在返回True的过程中,如果队列中的项目被取走。
q.qsize():返回队列中目前项目的正确数量,结果也不可靠,理由同q.empty()和q.full()一样
q.task_done() 在完成一项工作之后,q.task_done() 函数向任务已经完成的队列发送一个信号
q.join() 实际上意味着等到队列为空,再执行别的操作
其他方法:
q.cancel_join_thread():不会在进程退出时自动连接后台线程。可以防止join_thread()方法阻塞
q.close():关闭队列,防止队列中加入更多数据。调用此方法,后台线程将继续写入那些已经入队列但尚未写入的数据,但将在此方法完成时马上关闭。如果q被垃圾收集,将调用此方法。关闭队列不会在队列使用者中产生任何类型的数据结束信号或异常。例如,如果某个使用者正在被阻塞在get()操作上,关闭生产者中的队列不会导致get()方法返回错误。
q.join_thread():连接队列的后台线程。此方法用于在调用q.close()方法之后,等待所有队列项被消耗。默认情况下,此方法由不是q的原始创建者的所有进程调用。调用q.cancel_join_thread方法可以禁止这种行为
应用:
''' multiprocessing 模块支持进程间通信的两种主要形式:管道和队列 都是基于消息传递实现的,都是队列接口 ''' from multiprocessing import Process,Queue import time q=Queue(5) q.put([1,2,3]) q.put(('a','b','c')) q.put(100) q.put("Hello World") q.put({'name':'shuke'}) # q.put('队列满了') # 如果队列元素满了,后续put进入队列的数据将会处于等待状态,直到队列的元素被消费,才可以加入 print(q.qsize()) # 5; 返回队列的大小 print(q.full()) # True print(q.get()) # [1, 2, 3] print(q.get()) # ('a', 'b', 'c') print(q.get()) # 100 print(q.get()) # Hello World print(q.get()) # {'name': 'shuke'} # print(q.get()) # 如果队列元素全部被消费完成,会一直卡住,直到队列中被放入新的元素 print(q.empty()) # True
生产者消费者模型
在并发编程中使用生产者和消费者模式能够解决绝大多数并发问题。该模式通过平衡生产线程和消费线程的工作能力来提高程序的整体处理数据的速度。
为什么要使用生产者和消费者模式
在线程世界里,生产者就是生产数据的线程,消费者就是消费数据的线程。在多线程开发当中,如果生产者处理速度很快,而消费者处理速度很慢,那么生产者就必须等待消费者处理完,才能继续生产数据。同样的道理,如果消费者的处理能力大于生产者,那么消费者就必须等待生产者。为了解决这个问题于是引入了生产者和消费者模式。
什么是生产者消费者模式
生产者消费者模式是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。
基于队列实现生产者消费者模型
from multiprocessing import Process,Queue import time import random def producer(seq,q,name): for item in seq: time.sleep(random.randint(1,3)) q.put(item) print("%s 生产者生产了: %s"%(name,item)) def consumer(q,name): while True: time.sleep(random.randint(1,3)) res=q.get() print("%s 消费者消费了: %s"%(name,res)) if __name__ == '__main__': q=Queue() seq=("苹果%s"% i for i in range(5)) p=Process(target=consumer,args=(q,'Tom')) # 以元组的方式传参 p.start() producer(seq,q,'shuke') print("=====主线程=====") ''' 执行结果: shuke 生产者生产了: 苹果0 Tom 消费者消费了: 苹果0 shuke 生产者生产了: 苹果1 Tom 消费者消费了: 苹果1 shuke 生产者生产了: 苹果2 shuke 生产者生产了: 苹果3 Tom 消费者消费了: 苹果2 shuke 生产者生产了: 苹果4 =====主线程===== Tom 消费者消费了: 苹果3 Tom 消费者消费了: 苹果4 '''
# 生产者发送结束标志给消费者 from multiprocessing import Process,Queue import time import random def producer(seq,q,name): for item in seq: time.sleep(random.randint(1,3)) q.put(item) print("%s 生产者生产了: %s"%(name,item)) def consumer(q,name): while True: time.sleep(random.randint(1,3)) res=q.get() if res is None:break print("%s 消费者消费了: %s"%(name,res)) if __name__ == '__main__': q=Queue() seq=("苹果%s"% i for i in range(5)) c=Process(target=consumer,args=(q,'Tom')) # 以元组的方式传参 c.start() producer(seq,q,'shuke') q.put(None) c.join() # 主线程等待直到c消费者进程运行结束再继续往下运行 print("=====主线程=====") ''' 执行结果: shuke 生产者生产了: 苹果0 Tom 消费者消费了: 苹果0 shuke 生产者生产了: 苹果1 Tom 消费者消费了: 苹果1 shuke 生产者生产了: 苹果2 Tom 消费者消费了: 苹果2 shuke 生产者生产了: 苹果3 Tom 消费者消费了: 苹果3 shuke 生产者生产了: 苹果4 Tom 消费者消费了: 苹果4 =====主线程===== '''
JoinableQueue类 (创建队列的另外一个类)
JoinableQueue([maxsize]):这就像是一个Queue对象,但队列允许项目的消费者通知生产者队列已经被成功处理,通知进程是使用共享的信号和条件变量来实现的。
参数介绍:
maxsize是队列中允许最大项数,省略则无大小限制。
方法介绍:
JoinableQueue的实例p除了与Queue对象相同的方法之外还具有:
- q.task_done(): 使用者使用此方法发出信号,表示q.get()的返回项目已经被处理。如果调用此方法的次数大于从队列中删除项目的数量,将引发ValueError异常。
- q.join(): 生产者调用此方法进行阻塞,直到队列中所有的项目均被处理。阻塞将持续到队列中的每个项目均调用q.task_done()方法为止。
from multiprocessing import Process,JoinableQueue import time import random def producer(seq,q,name): for item in seq: q.put(item) print("%s 生产者生产了: %s"%(name,item)) q.join() # 生产者调用此方法进行阻塞 def consumer(q,name): while True: res=q.get() if res is None:break print("%s 消费者消费了: %s"%(name,res)) q.task_done() # 使用者使用此方法发出信号,表示q.get()的返回元素已经被消费处理。 if __name__ == '__main__': q=JoinableQueue() seq=("苹果%s"% i for i in range(5)) c=Process(target=consumer,args=(q,'Tom')) # 以元组的方式传参 c.daemon=True # 在start之前进行设置为守护进程,在主线程停止时c也停止,但是不用担心,producer内调用q.join保证了consumer已经处理完队列中的所有元素 c.start() producer(seq,q,'shuke') print("=====主线程=====") ''' 执行结果: shuke 生产者生产了: 苹果0 Tom 消费者消费了: 苹果0 shuke 生产者生产了: 苹果1 Tom 消费者消费了: 苹果1 shuke 生产者生产了: 苹果2 Tom 消费者消费了: 苹果2 shuke 生产者生产了: 苹果3 Tom 消费者消费了: 苹果3 shuke 生产者生产了: 苹果4 Tom 消费者消费了: 苹果4 =====主线程===== '''
from multiprocessing import Process,JoinableQueue import time import random def producer(seq,q,name): for item in seq: time.sleep(random.randint(1,3)) q.put(item) print("%s 生产者生产了: %s"%(name,item)) q.join() def consumer(q,name): while True: time.sleep(random.randint(1, 3)) res=q.get() if res is None:break print("%s 消费者消费了: %s"%(name,res)) q.task_done() if __name__ == '__main__': q=JoinableQueue() seq=("苹果%s"% i for i in range(5)) c1=Process(target=consumer,args=(q,'消费者1')) # 以元组的方式传参 c2=Process(target=consumer,args=(q,'消费者2')) c3=Process(target=consumer,args=(q,'消费者3')) c1.daemon=True # 在start之前进行设置为守护进程,在主线程停止时c也停止,但是不用担心,producer内调用q.join保证了consumer已经处理完队列中的所有元素 c2.daemon=True c3.daemon=True c1.start() c2.start() c3.start() producer(seq,q,'shuke') print("=====主线程=====") ''' 执行结果: shuke 生产者生产了: 苹果0 消费者3 消费者消费了: 苹果0 shuke 生产者生产了: 苹果1 消费者1 消费者消费了: 苹果1 shuke 生产者生产了: 苹果2 消费者2 消费者消费了: 苹果2 shuke 生产者生产了: 苹果3 消费者1 消费者消费了: 苹果3 shuke 生产者生产了: 苹果4 消费者3 消费者消费了: 苹果4 =====主线程===== '''
from multiprocessing import Process,JoinableQueue import time import random def producer(seq,q,name): for item in seq: # time.sleep(random.randint(1,3)) q.put(item) print("%s 生产者生产了: %s"%(name,item)) q.join() def consumer(q,name): while True: # time.sleep(random.randint(1, 3)) res=q.get() if res is None:break print("%s 消费者消费了: %s"%(name,res)) q.task_done() if __name__ == '__main__': q=JoinableQueue() seq=["苹果%s"% i for i in range(5)] c1=Process(target=consumer,args=(q,'消费者1')) # 以元组的方式传参 c2=Process(target=consumer,args=(q,'消费者2')) c3=Process(target=consumer,args=(q,'消费者3')) c1.daemon=True # 在start之前进行设置为守护进程,在主线程停止时c也停止,但是不用担心,producer内调用q.join保证了consumer已经处理完队列中的所有元素 c2.daemon=True c3.daemon=True c1.start() c2.start() c3.start() # producer(seq,q,'shuke') # 也可以是下面三行的形式,开启一个新的子进程当生产者,不用主线程当生产者 p=Process(target=producer,args=(seq,q,'shuke')) # 注意此处参数seq为列表 p.start() p.join() print("=====主线程=====") ''' 执行结果: shuke 生产者生产了: 苹果0 shuke 生产者生产了: 苹果1 消费者3 消费者消费了: 苹果0 shuke 生产者生产了: 苹果2 消费者2 消费者消费了: 苹果1 消费者3 消费者消费了: 苹果2 shuke 生产者生产了: 苹果3 消费者2 消费者消费了: 苹果3 shuke 生产者生产了: 苹果4 消费者3 消费者消费了: 苹果4 =====主线程===== '''
1.5 进程间通信(IPC)方式二:管道(了解部分)
管道也可以说是队列的另外一种形式,下面我们就开始介绍基于管道实现进程之间的消息传递
Pipe类(创建管道)
Pipe([duplex]): 在进程之间创建一条管道,并返回元组(conn1,conn2),其中conn1,conn2表示管道两端的连接对象,强调一点:必须在产生Process对象之前产生管道
参数介绍:
dumplex:默认管道是全双工的,如果将duplex射成False,conn1只能用于接收,conn2只能用于发送。
方法介绍:
主要方法:
- conn1.recv(): 接收conn2.send(obj)发送的对象。如果没有消息可接收,recv方法会一直阻塞。如果连接的另外一端已经关闭,那么recv方法会抛出EOFError。
- conn1.send(obj): 通过连接发送对象。obj是与序列化兼容的任意对象。
conn1.close():关闭连接。如果conn1被垃圾回收,将自动调用此方法。
conn1.fileno():返回连接使用的整数文件描述符。
conn1.poll([timeout]):如果连接上的数据可用,返回True。timeout指定等待的最长时限。如果省略此参数,方法将立即返回结果。如果将timeout射成None,操作将无限期地等待数据到达。
conn1.recv_bytes([maxlength]):接收c.send_bytes()方法发送的一条完整的字节消息。maxlength指定要接收的最大字节数。如果进入的消息,超过了这个最大值,将引发IOError异常,并且在连接上无法进行进一步读取。如果连接的另外一端已经关闭,再也不存在任何数据,将引发EOFError异常。
conn.send_bytes(buffer [, offset [, size]]):通过连接发送字节数据缓冲区,buffer是支持缓冲区接口的任意对象,offset是缓冲区中的字节偏移量,而size是要发送字节数。结果数据以单条消息的形式发出,然后调用c.recv_bytes()函数进行接收
conn1.recv_bytes_into(buffer [, offset]):接收一条完整的字节消息,并把它保存在buffer对象中,该对象支持可写入的缓冲区接口(即bytearray对象或类似的对象)。offset指定缓冲区中放置消息处的字节位移。返回值是收到的字节数。如果消息长度大于可用的缓冲区空间,将引发BufferTooShort异常。
基于管道实现进程间通信 (与队列的方式是类似的,队列就是管道加锁实现的)
from multiprocessing import Process,Pipe import time def consumer(p,name): left,right = p left.close() while True: try: fruit = right.recv() print("%s 收到水果: %s" % (name,fruit)) except EOFError: right.close() break def producer(seq,p): left,right = p right.close() for item in seq: left.send(item) else: left.close() if __name__ == '__main__': left,right = Pipe() c1=Process(target=consumer,args=((left,right),'Tom')) c1.start() seq=(i for i in range(5)) producer(seq,(left,right)) right.close() left.close() c1.join() print("===主线程===") ''' 执行结果: Tom 收到水果: 0 Tom 收到水果: 1 Tom 收到水果: 2 Tom 收到水果: 3 Tom 收到水果: 4 ===主线程=== '''
注: 生产者和消费者都没有使用管道的某个端点,就应该将其关闭,如在生产者中关闭管道的右端,在消费者中关闭管道的左端。如果忘记执行这些步骤,程序可能再消费者中的recv()操作上挂起。管道是由操作系统进行引用计数的,必须在所有进程中关闭管道后才能生产EOFError异常。因此在生产者中关闭管道不会有任何效果,除非消费者中也关闭了相同的管道端点。
from multiprocessing import Process,Pipe import time,os def adder(p,name): server,client=p client.close() while True: try: x,y=server.recv() except EOFError: server.close() break res=x+y server.send(res) print('server done') if __name__ == '__main__': server,client=Pipe() c1=Process(target=adder,args=((server,client),'c1')) c1.start() server.close() client.send((10,20)) print(client.recv()) client.close() c1.join() print('主进程')
注: send()和recv()方法使用pickle模块对对象进行序列化。
1.6 进程间通信方式三:共享数据
展望未来,基于消息传递的并发编程是大势所趋,即便是使用线程,推荐做法也是将程序设计为大量独立的线程集合通过消息队列交换数据。这样极大地减少了对使用锁定和其他同步手段的需求,还可以扩展到分布式系统中。
注: 进程间通信应该尽量避免使用本节所讲的共享数据的方式
进程间数据是独立的,可以借助于队列或管道实现通信,二者都是基于消息传递的,虽然进程间数据独立,但可以通过Manager实现数据共享,事实上Manager的功能远不止于此。
from multiprocessing import Process,Manager import os def foo(name,d,l): l.append(os.getpid()) d[name]=os.getpid() if __name__ == '__main__': with Manager() as manager: d=manager.dict({'name':'shuke'}) l=manager.list(['init',]) p_l=[] for i in range(5): p=Process(target=foo,args=('p%s' %i,d,l)) p.start() p_l.append(p) for p in p_l: p.join() #必须有join不然会报错 print(d) print(l) ''' 执行结果: {'p0': 62792, 'p4': 63472, 'name': 'shuke', 'p1': 60336, 'p3': 62704, 'p2': 63196} ['init', 60336, 62704, 62792, 63196, 63472] '''
1.7 进程同步(锁),信号量,事件...
模拟抢票(Lock-->互斥锁)
# 文件db的内容为:{"count":1} # 注意一定要用双引号,不然json无法识别 from multiprocessing import Process,Lock import json import time import random import os def work(filename,lock): #买票 # lock.acquire() with lock: # with语法下面的代码块执行完毕会自动释放锁 with open(filename,encoding='utf-8') as f: dic=json.loads(f.read()) # print('剩余票数: %s' % dic['count']) if dic['count'] > 0: dic['count']-=1 time.sleep(random.randint(1,3)) #模拟网络延迟 with open(filename,'w',encoding='utf-8') as f: f.write(json.dumps(dic)) print('%s 购票成功' %os.getpid()) else: print('%s 购票失败' %os.getpid()) # lock.release() if __name__ == '__main__': lock=Lock() p_l=[] for i in range(5): p=Process(target=work,args=('db',lock)) p_l.append(p) p.start() for p in p_l: p.join() print('主线程') ''' 执行结果: 63448 购票成功 13676 购票失败 61668 购票失败 63544 购票失败 17816 购票失败 主线程 '''
#互斥锁 同时只允许一个线程更改数据,而Semaphore是同时允许一定数量的线程更改数据 ,比如厕所有3个坑,那最多只允许3个人上厕所,后面的人只能等里面有人出来了才能再进去,如果指定信号量为3,那么来一个人获得一把锁,计数加1,当计数等于3时,后面的人均需要等待。一旦释放,就有人可以获得一把锁 #信号量与进程池的概念很像,但是要区分开,信号量涉及到加锁的概念 from multiprocessing import Process,Semaphore import time,random def go_wc(sem,user): sem.acquire() print('%s 占到一个茅坑' %user) time.sleep(random.randint(0,3)) #模拟每个人拉屎速度不一样,0代表有的人蹲下就起来了 sem.release() if __name__ == '__main__': sem=Semaphore(5) p_l=[] for i in range(13): p=Process(target=go_wc,args=(sem,'user%s' %i,)) p.start() p_l.append(p) for i in p_l: i.join() print('============》')
# python线程的事件用于主线程控制其他线程的执行,事件主要提供了三个方法 set、wait、clear。 # 事件处理的机制:全局定义了一个“Flag”,如果“Flag”值为 False,那么当程序执行 event.wait 方法时就会阻塞,如果“Flag”值为True,那么event.wait 方法时便不再阻塞。 clear:将“Flag”设置为False set:将“Flag”设置为True #_*_coding:utf-8_*_ #!/usr/bin/env python from multiprocessing import Process,Event import time,random def car(e,n): while True: if not e.is_set(): #Flase print('\033[31m红灯亮\033[0m,car%s等着' %n) e.wait() print('\033[32m车%s 看见绿灯亮了\033[0m' %n) time.sleep(random.randint(3,6)) if not e.is_set(): continue print('走你,car', n) break def police_car(e,n): while True: if not e.is_set(): print('\033[31m红灯亮\033[0m,car%s等着' % n) e.wait(1) print('灯的是%s,警车走了,car %s' %(e.is_set(),n)) break def traffic_lights(e,inverval): while True: time.sleep(inverval) if e.is_set(): e.clear() #e.is_set() ---->False else: e.set() if __name__ == '__main__': e=Event() # for i in range(10): # p=Process(target=car,args=(e,i,)) # p.start() for i in range(5): p = Process(target=police_car, args=(e, i,)) p.start() t=Process(target=traffic_lights,args=(e,10)) t.start() print('============》')
1.8 进程池 星级: *****
什么时候使用进程池?
开多进程的目的是为了并发,如果有多核,通常有几个核就开几个进程,进程开启过多,效率反而会下降(开启进程是需要占用系统资源的,而且开启多余核数目的进程也无法做到并行),但很明显需要并发执行的任务要远大于核数,这时我们就可以通过维护一个进程池来控制进程数目,比如httpd的进程模式,规定最小进程数和最大进程数...
当被操作对象数目不大时,可以直接利用multiprocessing中的Process动态成生多个进程,十几个还好,但如果是上百个,上千个目标,手动的去限制进程数量却又太过繁琐,此时可以发挥进程池的功效。
对于远程过程调用的高级应用程序而言,应该使用进程池,Pool可以提供指定数量的进程,供用户调用,当有新的请求提交到pool中时,如果池还没有满,那么就会创建一个新的进程用来执行该请求;但如果池中的进程数已经达到规定最大值,那么该请求就会等待,直到池中有进程结束,就重用进程池中的进程。
注: 在利用Python进行系统管理的时候,特别是同时操作多个文件目录,或者远程控制多台主机,并行操作可以节约大量的时间。
Pool类(创建进程池)
Pool([numprocess [,initializer [, initargs]]]):创建进程池
参数介绍:
numprocess:要创建的进程数,如果省略,将默认使用cpu_count()的值
initializer:是每个工作进程启动时要执行的可调用对象,默认为None
initargs:是要传给initializer的参数组
方法介绍:
主要方法:
p.apply(func [, args [, kwargs]]):在一个池工作进程中执行func(*args,**kwargs),然后返回结果。需要强调的是:此操作并不会在所有池工作进程中并执行func函数。如果要通过不同参数并发地执行func函数,必须从不同线程调用p.apply()函数或者使用p.apply_async() p.apply_async(func [, args [, kwargs]]):在一个池工作进程中执行func(*args,**kwargs),然后返回结果。此方法的结果是AsyncResult类的实例,callback是可调用对象,接收输入参数。当func的结果变为可用时,将理解传递给callback。callback禁止执行任何阻塞操作,否则将接收其他异步操作中的结果。 p.close():关闭进程池,防止进一步操作。如果所有操作持续挂起,它们将在工作进程终止前完成 p.terminate():立即终止所有工作进程,同时不执行任何清理或结束任何挂起工作。如果p被垃圾回收,将自动调用此函数 P.jion():等待所有工作进程退出。此方法只能在close()或teminate()之后调用
方法apply_async()和map_async()的返回值是AsyncResul的实例obj。实例具有以下方法
obj.get():返回结果,如果有必要则等待结果到达。timeout是可选的。如果在指定时间内还没有到达,将引发一场。如果远程操作中引发了异常,它将在调用此方法时再次被引发。
obj.ready():如果调用完成,返回True
obj.successful():如果调用完成且没有引发异常,返回True,如果在结果就绪之前调用此方法,引发异常
obj.wait([timeout]):等待结果变为可用。
应用
from multiprocessing import Pool import time def work(n): print('开工啦...') time.sleep(3) return n**2 if __name__ == '__main__': q=Pool() #异步apply_async用法:如果使用异步提交的任务,主进程需要使用jion,等待进程池内任务都处理完,然后可以用get收集结果,否则,主进程结束,进程池可能还没来得及执行,也就跟着一起结束了 res=q.apply_async(work,args=(2,)) q.close() q.join() #join在close之后调用 print(res.get()) #同步apply用法:主进程一直等apply提交的任务结束后才继续执行后续代码 # res=q.apply(work,args=(2,)) # print(res)
使用进程池维护固定数目的进程
''' Pool内的进程数默认是cpu核数,假设为4(查看方法os.cpu_count()) 开启6个客户端,会发现2个客户端处于等待状态 在每个进程内查看pid,会发现pid使用为4个,即多个客户端公用4个进程 ''' from socket import * from multiprocessing import Pool import os server = socket(AF_INET, SOCK_STREAM) server.setsockopt(SOL_SOCKET, SO_REUSEADDR, 1) server.bind(('127.0.0.1', 8081)) server.listen(5) def talk(conn, client_addr): print("进程PID: %s"%(os.getpid())) while True: try: msg = conn.recv(1024) if not msg: break conn.send(msg.upper()) except Exception: break if __name__ == '__main__': # windows下start进程一定要写到这下面 p = Pool() # 默认使用CPU的核数 while True: conn,client_addr=server.accept() p.apply_async(talk,args=(conn,client_addr)) # p.apply(talk,args=(conn,client_addr)) # #同步的话,则同一时间只有一个客户端能访问
from socket import * client=socket(AF_INET,SOCK_STREAM) client.connect(('127.0.0.1',8081)) while True: msg=input('>>:').strip() if not msg:continue client.send(msg.encode('utf-8')) msg=client.recv(1024) print(msg.decode('utf-8'))
from socket import * client=socket(AF_INET,SOCK_STREAM) client.connect(('127.0.0.1',8081)) while True: msg=input('>>:').strip() if not msg:continue client.send(msg.encode('utf-8')) msg=client.recv(1024) print(msg.decode('utf-8'))
回调函数(callback) 星级: *****
1. 不需要回调函数的场景
如果在主进程中等待进程池中所有任务都执行完毕后,再统一处理结果,则无需回调函数。
from multiprocessing import Pool import time,random,os def work(n): time.sleep(1) return n**2 if __name__ == '__main__': p=Pool() res_l=[] for i in range(10): res=p.apply_async(work,args=(i,)) res_l.append(res) p.close() p.join() #等待进程池中所有进程执行完毕 nums=[] for res in res_l: nums.append(res.get()) #拿到所有结果 print(nums) #主进程拿到所有的处理结果,可以在主进程中进行统一进行处理
2. 回调函数的应用场景
进程池中任何一个任务一旦处理完了,就立即告知主进程:我好了额,你可以处理我的结果了。主进程则调用一个函数去处理该结果,该函数即回调函数。
我们可以把耗时间(阻塞)的任务放到进程池中,然后指定回调函数(主进程负责执行),这样主进程在执行回调函数时就省去了I/O的过程,直接拿到的是任务的结果。
from multiprocessing import Pool import time,random,os def get_page(url): print('(进程 %s) 正在下载页面 %s' %(os.getpid(),url)) time.sleep(random.randint(1,3)) return url #用url充当下载后的结果 def parse_page(page_content): print('<进程 %s> 正在解析页面: %s' %(os.getpid(),page_content)) time.sleep(1) return '{%s 回调函数处理结果:%s}' %(os.getpid(),page_content) if __name__ == '__main__': urls=[ 'http://maoyan.com/board/1', 'http://maoyan.com/board/2', 'http://maoyan.com/board/3', 'http://maoyan.com/board/4', 'http://maoyan.com/board/5', 'http://maoyan.com/board/7', ] # 要创建进程池中的进程数,如果省略,将默认使用cpu_count()的值 p=Pool() res_l=[] #异步的方式提交任务,然后把任务的结果交给callback处理 #注意:会专门开启一个进程来处理callback指定的任务(单独的一个进程,而且只有一个) for url in urls: res=p.apply_async(get_page,args=(url,),callback=parse_page) res_l.append(res) #异步提交完任务后,主进程先关闭p(必须先关闭),然后再用p.join()等待所有任务结束(包括callback) p.close() p.join() print('{主进程 %s}' %os.getpid()) #收集结果,发现收集的是get_page的结果 #所以需要注意了: #1. 当我们想要在将get_page的结果传给parse_page处理,那么就不需要i.get(),通过指定callback,就可以将i.get()的结果传给callback执行的任务 #2. 当我们想要在主进程中处理get_page的结果,那就需要使用i.get()获取后,再进一步处理 for i in res_l: #本例中,下面这两步是多余的 callback_res=i.get() print(callback_res) ''' 打印结果: (进程 52346) 正在下载页面 http://maoyan.com/board/1 (进程 52347) 正在下载页面 http://maoyan.com/board/2 (进程 52348) 正在下载页面 http://maoyan.com/board/3 (进程 52349) 正在下载页面 http://maoyan.com/board/4 (进程 52348) 正在下载页面 http://maoyan.com/board/5 <进程 52345> 正在解析页面: http://maoyan.com/board/3 (进程 52346) 正在下载页面 http://maoyan.com/board/7 <进程 52345> 正在解析页面: http://maoyan.com/board/1 <进程 52345> 正在解析页面: http://maoyan.com/board/2 <进程 52345> 正在解析页面: http://maoyan.com/board/4 <进程 52345> 正在解析页面: http://maoyan.com/board/5 <进程 52345> 正在解析页面: http://maoyan.com/board/7 {主进程 52345} http://maoyan.com/board/1 http://maoyan.com/board/2 http://maoyan.com/board/3 http://maoyan.com/board/4 http://maoyan.com/board/5 http://maoyan.com/board/7 '''
from multiprocessing import Pool import time,random import requests import re def get_page(url,pattern): response=requests.get(url) if response.status_code == 200: return (response.text,pattern) def parse_page(info): page_content,pattern=info res=re.findall(pattern,page_content) for item in res: dic={ 'index':item[0], 'title':item[1], 'actor':item[2].strip()[3:], 'time':item[3][5:], 'score':item[4]+item[5] } print(dic) if __name__ == '__main__': pattern1=re.compile(r'<dd>.*?board-index.*?>(\d+)<.*?title="(.*?)".*?star.*?>(.*?)<.*?releasetime.*?>(.*?)<.*?integer.*?>(.*?)<.*?fraction.*?>(.*?)<',re.S) url_dic={ 'http://maoyan.com/board/7':pattern1, } p=Pool() res_l=[] for url,pattern in url_dic.items(): res=p.apply_async(get_page,args=(url,pattern),callback=parse_page) res_l.append(res) for i in res_l: i.get() # res=requests.get('http://maoyan.com/board/7') # print(re.findall(pattern,res.text)) ''' 执行结果: {'actor': '阿米尔·汗,萨卡诗·泰瓦,法缇玛·萨那·纱卡', 'index': '1', 'score': '9.8', 'title': '摔跤吧!爸爸', 'time': '2017-05-05'} {'actor': '李微漪,亦风', 'index': '2', 'score': '9.3', 'title': '重返·狼群', 'time': '2017-06-16'} {'actor': '高强,于月仙,李玉峰', 'index': '3', 'score': '9.2', 'title': '忠爱无言', 'time': '2017-06-09'} {'actor': '杨培,尼玛扎堆,斯朗卓嘎', 'index': '4', 'score': '9.1', 'title': '冈仁波齐', 'time': '2017-06-20'} {'actor': '约翰尼·德普,哈维尔·巴登,布兰顿·思怀兹', 'index': '5', 'score': '8.9', 'title': '加勒比海盗5:死无对证', 'time': '2017-05-26'} {'actor': '戴夫·帕特尔,鲁妮·玛拉,大卫·文翰', 'index': '6', 'score': '8.8', 'title': '雄狮', 'time': '2017-06-22'} {'actor': '蔡卓妍,周柏豪,钟欣潼', 'index': '7', 'score': '8.6', 'title': '原谅他77次', 'time': '2017-06-23'} {'actor': '水田山葵,山新,大原惠美', 'index': '8', 'score': '8.6', 'title': '哆啦A梦:大雄的南极冰冰凉大冒险', 'time': '2017-05-30'} {'actor': '盖尔·加朵,克里斯·派恩,罗宾·怀特', 'index': '9', 'score': '8.6', 'title': '神奇女侠', 'time': '2017-06-02'} {'actor': '范楚绒,洪海天,谢元真', 'index': '10', 'score': '8.5', 'title': '潜艇总动员之时光宝盒', 'time': '2015-05-29'} '''
apply_async(非阻塞)和apply(阻塞)的区别示例:
使用进程池(非阻塞,apply_async)
from multiprocessing import Process,Pool import time def func(msg): print( "msg:", msg) # time.sleep(1) return 'Bye Bye!' if __name__ == "__main__": processes=4 # 进程池的进程总数 pool = Pool(processes) # 实例化 res_l=[] for i in range(5): msg = "hello 同学%s" % str(i) res=pool.apply_async(func, args=(msg,)) # 维持执行的进程总数为processes,当一个进程执行完毕后会添加新的进程进去 res_l.append(res) print("============= 我是分割线 =================") pool.close() # 关闭进程池,防止进一步操作。如果所有操作持续挂起,它们将在工作进程终止前完成 pool.join() # 调用join之前,先调用close函数,否则会出错。执行完close后不会有新的进程加入到pool进程池,join函数等待所有子进程结束 print("Sub-process(es) done.") for i in res_l: print(res.get()) ''' 执行结果: ============= 我是分割线 ================= msg: hello 同学0 msg: hello 同学1 msg: hello 同学2 msg: hello 同学3 msg: hello 同学4 Sub-process(es) done. Bye Bye! Bye Bye! Bye Bye! Bye Bye! Bye Bye! '''
使用进程池(阻塞,apply)
from multiprocessing import Process,Pool import time def func(msg): print( "msg:", msg) # time.sleep(1) return 'Bye Bye!' if __name__ == "__main__": processes=4 # 进程池的进程总数 pool = Pool(processes) # 实例化 res_l=[] for i in range(5): msg = "hello 同学%s" % str(i) res=pool.apply(func, args=(msg,)) # 维持执行的进程总数为processes,当一个进程执行完毕后会添加新的进程进去 res_l.append(res) # 同步执行,即执行完一个拿到结果,再去执行另外一个 print("============= 我是分割线 =================") pool.close() # 关闭进程池,防止进一步操作。如果所有操作持续挂起,它们将在工作进程终止前完成 pool.join() # 调用join之前,先调用close函数,否则会出错。执行完close后不会有新的进程加入到pool进程池,join函数等待所有子进程结束 print("Sub-process(es) done.") print(res_l) for i in res_l: # apply是同步的,所以直接得到结果,没有get()方法 print(res) ''' 执行结果: msg: hello 同学0 msg: hello 同学1 msg: hello 同学2 msg: hello 同学3 msg: hello 同学4 ============= 我是分割线 ================= Sub-process(es) done. ['Bye Bye!', 'Bye Bye!', 'Bye Bye!', 'Bye Bye!', 'Bye Bye!'] Bye Bye! Bye Bye! Bye Bye! Bye Bye! Bye Bye! '''
#coding: utf-8 import multiprocessing import os, time, random def Lee(): print("\nRun task Lee-%s" %(os.getpid())) #os.getpid()获取当前的进程的ID start = time.time() time.sleep(random.random() * 10) #random.random()随机生成0-1之间的小数 end = time.time() print('Task Lee, runs %0.2f seconds.' %(end - start)) def Marlon(): print("\nRun task Marlon-%s" %(os.getpid())) start = time.time() time.sleep(random.random() * 40) end=time.time() print('Task Marlon runs %0.2f seconds.' %(end - start)) def Allen(): print("\nRun task Allen-%s" %(os.getpid())) start = time.time() time.sleep(random.random() * 30) end = time.time() print('Task Allen runs %0.2f seconds.' %(end - start)) def Frank(): print("\nRun task Frank-%s" %(os.getpid())) start = time.time() time.sleep(random.random() * 20) end = time.time() print('Task Frank runs %0.2f seconds.' %(end - start)) def Egon(): print("\nRun task Egon-%s" %(os.getpid())) start = time.time() time.sleep(random.random() * 20) end = time.time() print('Task Egon runs %0.2f seconds.' %(end - start)) def Lily(): print("\nRun task Lily-%s" %(os.getpid())) start = time.time() time.sleep(random.random() * 20) end = time.time() print('Task Lily runs %0.2f seconds.' %(end - start)) if __name__=='__main__': function_list= [Lee, Marlon, Allen, Frank, Egon, Lily] print("parent process %s" %(os.getpid())) pool=multiprocessing.Pool(4) for func in function_list: pool.apply_async(func) #Pool执行函数,apply执行函数,当有一个进程执行完毕后,会添加一个新的进程到pool中 print('Waiting for all subprocesses done...') pool.close() pool.join() #调用join之前,一定要先调用close() 函数,否则会出错, close()执行后不会有新的进程加入到pool,join函数等待素有子进程结束 print('All subprocesses done.') 多个进程池
二. python并发编程之多线程
2.1 threading模块
multiprocess模块的接口完全模仿了threading模块的接口,二者在使用层面,有很大的相似性,因而不再详细介绍。
2.1.1开启线程的两种方式(同Process)
# 方法一 from threading import Thread import time def sayhi(name): time.sleep(2) print('%s say hello!'% name) if __name__ == '__main__': t = Thread(target=sayhi,args=('shuke',)) t.start() print("=====我是分割线=====") print("主线程")
# 方法二 from threading import Thread import time class Sayhi(Thread): def __init__(self,name): super().__init__() self.name=name def run(self): time.sleep(2) print("%s say hello!"%self.name) if __name__ == '__main__': t=Sayhi('shuke') t.start() print("=====我是分割线=====") print("主线程")
2.1.2 子线程与子进程的区别
线程与进程的执行速度对比
1. 根据输出结果对比
# 线程方式 from threading import Thread def work(): print("Hello python!") if __name__ == '__main__': t = Thread(target=work) t.start() print('主线程/主进程') ''' 执行结果: Hello python! 主线程/主进程 '''
# 进程方式 from multiprocessing import Process def work(): print("Hello python!") if __name__ == '__main__': t = Process(target=work) t.start() print('主线程/主进程') ''' 执行结果: 主线程/主进程 Hello python! '''
2. 根据pid来进行对比
# 线程方式 # 在主进程下开启多个线程,每个线程都跟主进程的pid一样 from threading import Thread import os def work(): print("Pid: %s" % os.getpid()) if __name__ == '__main__': t1 = Thread(target=work) t2 = Thread(target=work) t3 = Thread(target=work) t1.start() t2.start() t3.start() print("主线程/主进程pid: %s" % os.getpid()) ''' 执行结果: Pid: 65652 Pid: 65652 Pid: 65652 主线程/主进程pid: 65652 '''
# 进程方式 # 开多个进程,每个进程都有不同的pid from multiprocessing import Process import os def work(): print("Pid: %s" % os.getpid()) if __name__ == '__main__': t1 = Process(target=work) t2 = Process(target=work) t3 = Process(target=work) t1.start() t2.start() t3.start() print('主线程/主进程pid: %s' % os.getpid()) ''' 主线程/主进程pid: 20484 Pid: 5800 Pid: 67076 Pid: 62244 '''
2.1.3 小小的练习
#_*_coding:utf-8_*_ #!/usr/bin/env python import multiprocessing import threading import socket s=socket.socket(socket.AF_INET,socket.SOCK_STREAM) s.bind(('127.0.0.1',8080)) s.listen(5) def action(conn): while True: data=conn.recv(1024) print(data) conn.send(data.upper()) if __name__ == '__main__': while True: conn,addr=s.accept() p=threading.Thread(target=action,args=(conn,)) p.start() 多线程并发的socket服务端
#_*_coding:utf-8_*_ #!/usr/bin/env python import socket s=socket.socket(socket.AF_INET,socket.SOCK_STREAM) s.connect(('127.0.0.1',8080)) while True: msg=input('>>: ').strip() if not msg:continue s.send(msg.encode('utf-8')) data=s.recv(1024) print(data) 客户端
from threading import Thread msg_l=[] format_l=[] def talk(): while True: msg=input('>>: ').strip() if not msg:continue msg_l.append(msg) def format_msg(): while True: if msg_l: res=msg_l.pop() format_l.append(res.upper()) def save(): while True: if format_l: with open('db.txt','a',encoding='utf-8') as f: res=format_l.pop() f.write('%s\n' %res) if __name__ == '__main__': t1=Thread(target=talk) t2=Thread(target=format_msg) t3=Thread(target=save) t1.start() t2.start() t3.start()
2.1.4 线程的join与setdaemon
from threading import Thread import time def work(name): time.sleep(2) print("%s say hello" % name) if __name__ == '__main__': t = Thread(target=work,args=('shuke',)) t.setDaemon(True) t.start() t.join() print("主线程") print(t.is_alive()) ''' 执行结果: shuke say hello 主线程 False '''
2.1.5 线程的其他方法补充
Thread实例对象的方法
- isAlive(): 返回线程是否活动的。
- getName(): 返回线程名。
- setName(): 设置线程名。
threading模块提供的一些方法
- threading.currentThread(): 返回当前的线程变量。
- threading.enumerate(): 返回一个包含正在运行的线程的list。正在运行指线程启动后、结束前,不包括启动前和终止后的线程。
- threading.activeCount(): 返回正在运行的线程数量,与len(threading.enumerate())有相同的结果。
from threading import Thread import threading import time def work(): time.sleep(2) print(threading.current_thread().getName()) # 在主进程下开启线程 if __name__ == '__main__': t = Thread(target=work) t.start() print(threading.current_thread().getName()) print(threading.current_thread()) # 主线程 print(threading.enumerate()) # 连同主线程在内有两个运行的线程 print(threading.active_count()) print("主线程/主进程") ''' 执行结果: MainThread <_MainThread(MainThread, started 67280)> [<_MainThread(MainThread, started 67280)>, <Thread(Thread-1, started 64808)>] 2 主线程/主进程 Thread-1 '''
2.1.6 线程池
参考文章: http://www.cnblogs.com/tracylining/p/3471594.html
2.2 Python GIL(Global Interpreter Lock)
''' 定义: In CPython, the global interpreter lock, or GIL, is a mutex that prevents multiple native threads from executing Python bytecodes at once. This lock is necessary mainly because CPython’s memory management is not thread-safe. (However, since the GIL exists, other features have grown to depend on the guarantees that it enforces.) ''' 结论: 在Cpython解释器中,同一个进程下开启的多线程,同一时刻只能有一个线程执行,无法利用多核优势
这篇文章透彻的剖析了GIL对python多线程的影响,强烈推荐看浏览:http://www.dabeaz.com/python/UnderstandingGIL.pdf
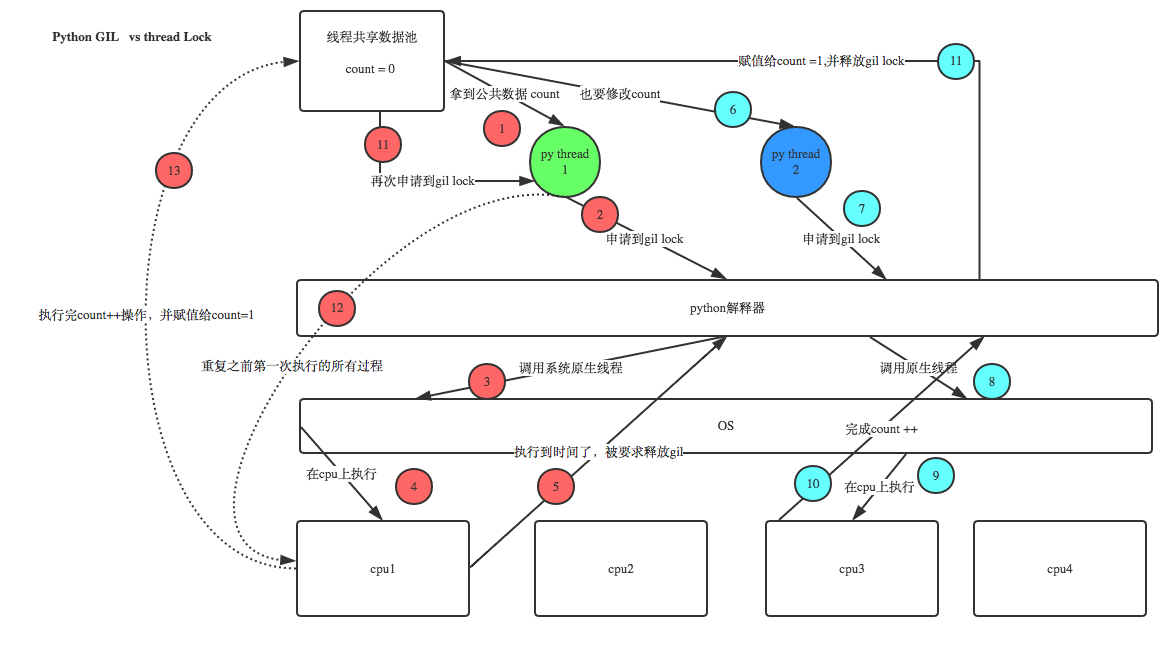
需求:
我们有四个任务需要处理,处理方式肯定是要玩出并发的效果,解决方案可以是:
方案一:开启四个进程
方案二:一个进程下,开启四个线程
单核情况下,分析结果:
如果四个任务是计算密集型,没有多核来并行计算,方案一徒增了创建进程的开销,方案二胜
如果四个任务是I/O密集型,方案一创建进程的开销大,且进程的切换速度远不如线程,方案二胜
多核情况下,分析结果:
如果四个任务是计算密集型,多核意味着并行计算,在python中一个进程中同一时刻只有一个线程执行用不上多核,方案一胜
如果四个任务是I/O密集型,再多的核也解决不了I/O问题,方案二胜
#计算密集型 from threading import Thread from multiprocessing import Process import os import time def work(): res=0 for i in range(1000000): res+=i if __name__ == '__main__': t_l=[] start_time=time.time() # for i in range(300): #串行 # work() for i in range(300): t=Thread(target=work) #在我的机器上,4核cpu,多线程大概15秒 # t=Process(target=work) #在我的机器上,4核cpu,多进程大概10秒 t_l.append(t) t.start() for i in t_l: i.join() stop_time=time.time() print('run time is %s' %(stop_time-start_time)) print('主线程')
#I/O密集型 from threading import Thread from multiprocessing import Process import time import os def work(): time.sleep(2) #模拟I/O操作,可以打开一个文件来测试I/O,与sleep是一个效果 print(os.getpid()) if __name__ == '__main__': t_l=[] start_time=time.time() for i in range(1000): t=Thread(target=work) #耗时大概为2秒 # t=Process(target=work) #耗时大概为25秒,创建进程的开销远高于线程,而且对于I/O密集型,多cpu根本不管用 t_l.append(t) t.start() for t in t_l: t.join() stop_time=time.time() print('run time is %s' %(stop_time-start_time))
应用:
多线程用于IO密集型,如socket,爬虫,web
多进程用于计算密集型,如金融分析
2.3 同步锁
import time import threading num = 100 #设定一个共享变量 # R=threading.Lock() def addNum(): global num #在每个线程中都获取这个全局变量 #num-=1 # R.acquire() temp=num time.sleep(0.1) num =temp-1 # 对此公共变量进行-1操作 # R.release() thread_list = [] for i in range(100): t = threading.Thread(target=addNum) t.start() thread_list.append(t) for t in thread_list: #等待所有线程执行完毕 t.join() print('Result: ', num)
锁通常被用来实现对共享资源的同步访问。为每一个共享资源创建一个Lock对象,当你需要访问该资源时,调用acquire方法来获取锁对象(如果其它线程已经获得了该锁,则当前线程需等待其被释放),待资源访问完后,再调用release方法释放锁,如下所示:
import threading R=threading.Lock() R.acquire() ''' 对公共数据的操作 ''' R.release()
GIL VS Lock
Python已经有一个GIL来保证同一时间只能有一个线程来执行了,为什么这里还需要lock?
达成共识:锁的目的是为了保护共享的数据,同一时间只能有一个线程来修改共享的数据
得出结论:保护不同的数据就应该加不同的锁。
最后,问题就很明朗了,GIL 与Lock是两把锁,保护的数据不一样,前者是解释器级别的(当然保护的就是解释器级别的数据,比如垃圾回收的数据),后者是保护用户自己开发的应用程序的数据,很明显GIL不负责这件事,只能用户自定义加锁处理,即Lock。GIL是解释器级别的锁,LOCK是应用程序级别(用户级别)的锁。
详解:
因为Python解释器会自动定期进行内存回收,可以理解为python解释器里有一个独立的线程,每过一段时间它起wake up做一次全局轮询看看哪些内存数据是可以被清空的,此时自己的程序 里的线程和 py解释器自己的线程是并发运行的,假设线程删除了一个变量,py解释器的垃圾回收线程在清空这个变量的过程中的clearing时刻,可能一个其它线程正好又重新给这个还没来及得清空的内存空间赋值了,结果就有可能新赋值的数据被删除了,为了解决类似的问题,python解释器简单粗暴的加了锁,即当一个线程运行时,其它人都不能动,这样就解决了上述的问题, 这可以说是Python早期版本的遗留问题。
2.4 死锁与递归锁
from threading import Thread,Lock import time mutexA=Lock() mutexB=Lock() class MyThread(Thread): def run(self): self.func1() self.func2() def func1(self): mutexA.acquire() print('\033[41m%s 拿到A锁\033[0m' %self.name) mutexB.acquire() print('\033[42m%s 拿到B锁\033[0m' %self.name) mutexB.release() mutexA.release() def func2(self): mutexB.acquire() print('\033[43m%s 拿到B锁\033[0m' %self.name) time.sleep(2) mutexA.acquire() print('\033[44m%s 拿到A锁\033[0m' %self.name) mutexA.release() mutexB.release() if __name__ == '__main__': for i in range(10): t=MyThread() t.start() ''' Thread-1 拿到A锁 Thread-1 拿到B锁 Thread-1 拿到B锁 Thread-2 拿到A锁 然后就卡住,死锁了 '''
解决方法,递归锁,在Python中为了支持在同一线程中多次请求同一资源,python提供了可重入锁RLock。
这个RLock内部维护着一个Lock和一个counter变量,counter记录了acquire的次数,从而使得资源可以被多次require。直到一个线程所有的acquire都被release,其他的线程才能获得资源。上面的例子如果使用RLock代替Lock,则不会发生死锁:
mutexA=mutexB=threading.RLock() #一个线程拿到锁,counter加1,该线程内又碰到加锁的情况,则counter继续加1,这期间所有其他线程都只能等待,等待该线程释放所有锁,即counter递减到0为止
2.5 信号量Semahpore
Semaphore管理一个内置的计数器,
每当调用acquire()时内置计数器-1;
调用release() 时内置计数器+1;
计数器不能小于0;当计数器为0时,acquire()将阻塞线程直到其他线程调用release()。
import threading import time semaphore = threading.Semaphore(5) # 设置为5,表示同一时刻可以通过5个线程进行操作 def func(): if semaphore.acquire(): print (threading.currentThread().getName() + ' get semaphore') time.sleep(2) semaphore.release() for i in range(20): t1 = threading.Thread(target=func) t1.start()
与进程池是完全不同的概念,进程池Pool(4),最大只能产生4个进程,而且从始至终同一时刻只有四个进程存在,不会产生新的,而信号量是产生一堆线程/进程,同一时刻可以通过5个线程/进程进行数据操作。
2.6 事件Event
线程的一个关键特性是每个线程都是独立运行且状态不可预测。如果程序中的其 他线程需要通过判断某个线程的状态来确定自己下一步的操作,这时线程同步问题就 会变得非常棘手。为了解决这些问题,我们需要使用threading库中的Event对象。 对象包含一个可由线程设置的信号标志,它允许线程等待某些事件的发生。在 初始情况下,Event对象中的信号标志被设置为假。如果有线程等待一个Event对象, 而这个Event对象的标志为假,那么这个线程将会被一直阻塞直至该标志为真。一个线程如果将一个Event对象的信号标志设置为真,它将唤醒所有等待这个Event对象的线程。如果一个线程等待一个已经被设置为真的Event对象,那么它将忽略这个事件, 继续执行。(可以结合实际生活中的红绿灯进行理解)
event.isSet(): #返回event的状态值; event.wait(): #如果 event.isSet()==False将阻塞线程; event.set(): #设置event的状态值为True,所有阻塞池的线程激活进入就绪状态, 等待操作系统调度; event.clear(): #恢复event的状态值为False。
import threading import time import logging logging.basicConfig(level=logging.DEBUG, format='(%(threadName)-10s) %(message)s',) def worker(event): logging.debug('Waiting for redis ready...') event.wait() logging.debug('redis ready, and connect to redis server and do some work [%s]', time.ctime()) time.sleep(1) def main(): readis_ready = threading.Event() t1 = threading.Thread(target=worker, args=(readis_ready,), name='t1') t1.start() t2 = threading.Thread(target=worker, args=(readis_ready,), name='t2') t2.start() logging.debug('first of all, check redis server, make sure it is OK, and then trigger the redis ready event') time.sleep(3) # simulate the check progress readis_ready.set() if __name__=="__main__": main() 不了解redis可以参考mysql的例子(一样的道理)
from threading import Thread,Event import threading import time,random def conn_mysql(): print('\033[41m%s 等待连接mysql。。。\033[0m' %threading.current_thread().getName()) event.wait() print('\033[41mMysql初始化成功,%s开始连接。。。\033[0m' %threading.current_thread().getName()) def check_mysql(): print('\033[43m正在检查mysql。。。\033[0m') time.sleep(random.randint(1,3)) event.set() time.sleep(random.randint(1,3)) if __name__ == '__main__': event=Event() t1=Thread(target=conn_mysql) #等待连接mysql t2=Thread(target=conn_mysql) #等待连接myqsl t3=Thread(target=check_mysql) #检查mysql t1.start() t2.start() t3.start() ''' 执行结果: Thread-1 等待连接mysql。。。 Thread-2 等待连接mysql。。。 正在检查mysql。。。 Mysql初始化成功,Thread-1开始连接。。。 Mysql初始化成功,Thread-2开始连接。。。 '''
def conn_mysql(): count=0 while not e.is_set(): print('%s 第 <%s> 次尝试' %(threading.current_thread().getName(),count)) count+=1 e.wait(0.5) print('%s ready to conn mysql' %threading.current_thread().getName()) time.sleep(1)
from threading import Thread,Event import threading import time,random def conn_mysql(): while not event.is_set(): print('\033[42m%s 等待连接mysql。。。\033[0m' %threading.current_thread().getName()) event.wait(0.1) print('\033[42mMysql初始化成功,%s开始连接。。。\033[0m' %threading.current_thread().getName()) def check_mysql(): print('\033[41m正在检查mysql。。。\033[0m') time.sleep(random.randint(1,3)) event.set() time.sleep(random.randint(1,3)) if __name__ == '__main__': event=Event() t1=Thread(target=conn_mysql) t2=Thread(target=conn_mysql) t3=Thread(target=check_mysql) t1.start() t2.start() t3.start() 修订上述mysql版本
这样,我们就可以在等待Redis服务启动的同时,看到工作线程里正在等待的情况。
应用: 连接池
2.7 条件Condition(了解)
使得线程等待,只有满足某条件时,才释放n个线程
import threading def run(n): con.acquire() con.wait() print("run the thread: %s" %n) con.release() if __name__ == '__main__': con = threading.Condition() for i in range(10): t = threading.Thread(target=run, args=(i,)) t.start() while True: inp = input('>>>') if inp == 'q': break con.acquire() con.notify(int(inp)) con.release()
def condition_func(): ret = False inp = input('>>>') if inp == '1': ret = True return ret def run(n): con.acquire() con.wait_for(condition_func) print("run the thread: %s" %n) con.release() if __name__ == '__main__': con = threading.Condition() for i in range(10): t = threading.Thread(target=run, args=(i,)) t.start()
2.8 定时器Timer
定时器,指定n秒后执行某操作
from threading import Timer def hello(): print("hello, world") t = Timer(1, hello) t.start() # after 1 seconds, "hello, world" will be printed
2.9 线程queue
queue队列 :使用import queue,用法与进程Queue一样
queue is especially useful in threaded programming when information must be exchanged safely between multiple threads.
1. class queue.Queue(maxsize=0) #先进先出
import queue q=queue.Queue() q.put('first') q.put('second') q.put('third') print(q.get()) print(q.get()) print(q.get()) ''' 结果(先进先出): first second third '''
2. class queue.LifoQueue(maxsize=0) #last in fisrt out
import queue q=queue.LifoQueue() q.put('first') q.put('second') q.put('third') print(q.get()) print(q.get()) print(q.get()) ''' 结果(后进先出): third second first '''
3. class queue.PriorityQueue(maxsize=0) #存储数据时可设置优先级的队列
import queue q=queue.PriorityQueue() #put进入一个元组,元组的第一个元素是优先级(通常是数字,也可以是非数字之间的比较),数字越小优先级越高 q.put((20,'a')) q.put((10,'b')) q.put((30,'c')) print(q.get()) print(q.get()) print(q.get()) ''' 结果(数字越小优先级越高,优先级高的优先出队): (10, 'b') (20, 'a') (30, 'c') '''
2.10 Python标准模块--concurrent.futures
concurrent.futures模块是在Python3.2中添加的。根据Python的官方文档,concurrent.futures模块提供给开发者一个执行异步调用的高级接口。concurrent.futures基本上就是在Python的threading和multiprocessing模块之上构建的抽象层,更易于使用。尽管这个抽象层简化了这些模块的使用,但是也降低了很多灵活性,所以如果你需要处理一些定制化的任务,concurrent.futures或许并不适合你。
concurrent.futures包括抽象类Executor,它并不能直接被使用,所以你需要使用它的两个子类:ThreadPoolExecutor或者ProcessPoolExecutor。正如你所猜的,这两个子类分别对应着Python的threading和multiprocessing接口。这两个子类都提供了池,你可以将线程或者进程放入其中。
https://docs.python.org/dev/library/concurrent.futures.html
三. 协程
协程:是单线程下的并发,又称微线程,纤程。英文名Coroutine。一句话说明什么是线程:协程是一种用户态的轻量级线程,即协程是由用户程序自己控制调度的。
需要强调的是:
- python的线程属于内核级别的,即由操作系统控制调度(如单线程一旦遇到io就被迫交出cpu执行权限,切换其他线程运行)
- 单线程内开启协程,一旦遇到io,从应用程序级别(而非操作系统)控制切换
对比操作系统控制线程的切换,用户在单线程内控制协程的切换,优点如下:
- 协程的切换开销更小,属于程序级别的切换,操作系统完全感知不到,因而更加轻量级
- 单线程内就可以实现并发的效果,最大限度地利用cpu
要实现协程,关键在于用户程序自己控制程序切换,切换之前必须由用户程序自己保存协程上一次调用时的状态,如此,每次重新调用时,能够从上次的位置继续执行
(详细的:协程拥有自己的寄存器上下文和栈。协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈)
为此,我们之前已经学习过一种在单线程下可以保存程序运行状态的方法,即yield,我们来简单复习一下:
- yiled可以保存状态,yield的状态保存与操作系统的保存线程状态很像,但是yield是代码级别控制的,更轻量级
- send可以把一个函数的结果传给另外一个函数,以此实现单线程内程序之间的切换
#不用yield:每次函数调用,都需要重复开辟内存空间,即重复创建名称空间,因而开销很大 import time def consumer(item): # print('拿到包子%s' %item) x=11111111111 x1=12111111111 x3=13111111111 x4=14111111111 y=22222222222 z=33333333333 pass def producer(target,seq): for item in seq: target(item) # 每次调用函数,会临时产生名称空间,调用结束则释放,循环100000000次,则重复这么多次的创建和释放,开销非常大 start_time=time.time() producer(consumer,range(100000000)) stop_time=time.time() print('run time is:%s' %(stop_time-start_time)) # 13.474999904632568 #使用yield:无需重复开辟内存空间,即重复创建名称空间,因而开销小 import time def init(func): def wrapper(*args,**kwargs): g=func(*args,**kwargs) next(g) return g return wrapper @init def consumer(): x=11111111111 x1=12111111111 x3=13111111111 x4=14111111111 y=22222222222 z=33333333333 while True: item=yield # print('拿到包子%s' %item) pass def producer(target,seq): for item in seq: target.send(item) #无需重新创建名称空间,从上一次暂停的位置继续,相比上例,开销小 start_time=time.time() producer(consumer(),range(100000000)) stop_time=time.time() print('run time is:%s' %(stop_time-start_time)) # 10.674000024795532
协程的定义(满足1,2,3就可称为协程):
- 必须在只有一个单线程里实现并发
- 修改共享数据不需加锁
- 用户程序里自己保存多个控制流的上下文栈
- 附加:一个协程遇到IO操作自动切换到其它协程(如何实现检测IO,yield、greenlet都无法实现,就用到了gevent模块(select机制)
缺点:
协程的本质是单线程下,无法利用多核,可以是一个程序开启多个进程,每个进程内开启多个线程,每个线程内开启协程。
协程指的是单个线程,因而一旦协程出现阻塞,将会阻塞整个线程。
四. 协程模块greenlet
greenlet是一个用C实现的协程模块,相比与python自带的yield,它可以使你在任意函数之间随意切换,而不需把这个函数先声明为generator。
from greenlet import greenlet def test1(): print('test1,first') gr2.switch() print('test1,sencod') gr2.switch() def test2(): print('test2,first') gr1.switch() print('test2,sencod') gr1=greenlet(test1) gr2=greenlet(test2) gr1.switch() ''' 执行结果: test1,first test2,first test1,sencod test2,sencod '''
from greenlet import greenlet def eat(name): print('%s eat fruit apple' %name) gr2.switch('shuke') print('%s eat fruit banana' %name) gr2.switch() def play_phone(name): print('%s play basketbal' %name) gr1.switch() print('%s play football' %name) gr1=greenlet(eat) gr2=greenlet(play_phone) gr1.switch(name='jack') #可以在第一次switch时传入参数,以后都不需要 ''' 执行结果: jack eat fruit apple shuke play basketbal jack eat fruit banana shuke play football '''
单纯的切换(在没有io的情况下或者没有重复开辟内存空间的操作),反而会降低程序的执行速度。
#顺序执行 import time def f1(): res=0 for i in range(10000000): res+=i def f2(): res=0 for i in range(10000000): res*=i start_time=time.time() f1() f2() stop_time=time.time() print('run time is: %s' %(stop_time-start_time)) #1.7395639419555664 #切换 from greenlet import greenlet import time def f1(): res=0 for i in range(10000000): res+=i gr2.switch() def f2(): res=0 for i in range(10000000): res*=i gr1.switch() gr1=greenlet(f1) gr2=greenlet(f2) start_time=time.time() gr1.switch() stop_time=time.time() print('run time is: %s' %(stop_time-start_time)) #7.789067983627319
greenlet只是提供了一种比generator更加便捷的切换方式,仍然是没有解决遇到IO自动切换的问题。
五. gevent模块(单线程并发)
Gevent 是一个第三方库,可以轻松通过gevent实现并发同步或异步编程,在gevent中用到的主要模式是Greenlet, 它是以C扩展模块形式接入Python的轻量级协程。 Greenlet全部运行在主程序操作系统进程的内部,但它们被协作式地调度。
g1=gevent.spawn()创建一个协程对象g1,spawn括号内第一个参数是函数名,如eat,后面可以有多个参数,可以是位置实参或关键字实参,都是传给函数eat的。
遇到IO阻塞时会自动切换任务
import gevent def eat(): print('eat food 1') gevent.sleep(2) # 等饭来 print('eat food 2') def play_phone(): print('play phone 1') gevent.sleep(1) # 网卡了 print('play phone 2') # gevent.spawn(eat) # gevent.spawn(play_phone) # print('主') # 直接结束 # 因而也需要join方法,进程或线程的jion方法只能join一个,而gevent的join方法可以join多个 g1=gevent.spawn(eat) g2=gevent.spawn(play_phone) gevent.joinall([g1,g2]) print('主') ''' 执行结果: eat food 1 play phone 1 play phone 2 eat food 2 主 '''
注: 上例中gevent.sleep(2)模拟的是gevent可以识别的io阻塞,而time.sleep(2)或其他的阻塞,gevent是不能直接识别的,此时就需要进行打补丁,将阻塞设置为gevent可以识别的IO阻塞。
通常的写法为,在文件的开头,如下
from gevent import monkey;monkey.patch_all() import gevent import time
from gevent import monkey;monkey.patch_all() import gevent import time def eat(): print('eat food 1') time.sleep(2) print('eat food 2') def play_phone(): print('play phone 1') time.sleep(1) print('play phone 2') g1=gevent.spawn(eat) g2=gevent.spawn(play_phone) gevent.joinall([g1,g2]) print('主')
同步与异步
概念:
同步和异步的概念对于很多人来说是一个模糊的概念,是一种似乎只能意会不能言传的东西。其实我们的生活中存在着很多同步异步的例子。比如:你叫我去吃饭,我听到了就立刻和你去吃饭,如果我们有听到,你就会一直叫我,直到我听见和你一起去吃饭,这个过程叫同步;异步过程指你叫我去吃饭,然后你就去吃饭了,而不管我是否和你一起去吃饭。而我得到消息后可能立即就走,也可能过段时间再走。如果我请你吃饭,就是同步,如果你请我吃饭就用异步,这样你比较省钱。哈哈哈。。。
import gevent def task(pid): """ Some non-deterministic task """ gevent.sleep(0.5) print('Task %s done' % pid) def synchronous(): for i in range(1, 10): task(i) def asynchronous(): threads = [gevent.spawn(task, i) for i in range(10)] gevent.joinall(threads) print('Synchronous:') synchronous() # 同步 print('Asynchronous:') asynchronous() # 异步
上面程序的重要部分是将task函数封装到Greenlet内部线程的gevent.spawn。 初始化的greenlet列表存放在数组threads中,此列表被传给gevent.joinall 函数,后者阻塞当前流程,并执行所有给定的greenlet。执行流程只会在 所有greenlet执行完后才会继续向下走。
#gevent线程的一些用法 g1=gevent.spawn(func,1,,2,3,x=4,y=5) g2=gevent.spawn(func2) g1.join() #等待g1结束 g2.join() #等待g2结束 #或者上述两步合作一步:gevent.joinall([g1,g2]) g1.value#拿到func1的返回值
from gevent import monkey;monkey.patch_all() import gevent import requests import time def get_page(url): print('GET: %s' %url) response=requests.get(url) if response.status_code == 200: print('%d bytes received from %s' %(len(response.text),url)) start_time=time.time() gevent.joinall([ gevent.spawn(get_page,'https://www.python.org/'), gevent.spawn(get_page,'https://www.yahoo.com/'), gevent.spawn(get_page,'https://github.com/'), ]) stop_time=time.time() print('run time is %s' %(stop_time-start_time)) 协程应用:爬虫
通过gevent实现单线程下的socket并发(from gevent import monkey;monkey.patch_all()一定要放到导入socket模块之前,否则gevent无法识别socket的阻塞)
from gevent import monkey;monkey.patch_all() from socket import * import gevent #如果不想用money.patch_all()打补丁,可以用gevent自带的socket # from gevent import socket # s=socket.socket() def server(server_ip,port): s=socket(AF_INET,SOCK_STREAM) s.setsockopt(SOL_SOCKET,SO_REUSEADDR,1) s.bind((server_ip,port)) s.listen(5) while True: conn,addr=s.accept() gevent.spawn(talk,conn,addr) def talk(conn,addr): try: while True: res=conn.recv(1024) print('client %s:%s msg: %s' %(addr[0],addr[1],res)) conn.send(res.upper()) except Exception as e: print(e) finally: conn.close() if __name__ == '__main__': server('127.0.0.1',8080)
#_*_coding:utf-8_*_ __author__ = 'Linhaifeng' from socket import * client=socket(AF_INET,SOCK_STREAM) client.connect(('127.0.0.1',8080)) while True: msg=input('>>: ').strip() if not msg:continue client.send(msg.encode('utf-8')) msg=client.recv(1024) print(msg.decode('utf-8'))
from threading import Thread from socket import * import threading def client(server_ip,port): c=socket(AF_INET,SOCK_STREAM) c.connect((server_ip,port)) count=0 while True: c.send(('%s say hello %s' %(threading.current_thread().getName(),count)).encode('utf-8')) msg=c.recv(1024) print(msg.decode('utf-8')) count+=1 if __name__ == '__main__': for i in range(500): t=Thread(target=client,args=('127.0.0.1',8080)) t.start()
六. 综合应用
简单主机批量管理工具
需求:
- 主机分组
- 主机信息配置文件用configparser解析
- 可批量执行命令、发送文件,结果实时返回,执行格式如下
- batch_run -h h1,h2,h3 -g web_clusters,db_servers -cmd "df -h"
- batch_scp -h h1,h2,h3 -g web_clusters,db_servers -action put -local test.py -remote /tmp/
- 主机用户名密码、端口可以不同
- 执行远程命令使用paramiko模块
- 批量命令需使用multiprocessing并发

