


JS 正则表达式深入
1.零宽断言
断言指正则表达式可以指明在指定的内容前面或后面会出现满足规则的内容
零宽指的是断言只是匹配的表达式,不占据宽度,也不会出现在返回的匹配结果中
"<span class="read-count">阅读数:641</span>" 找出该字符串中的阅读量
(1)正向先行断言
语法: (?=pattern)
作用: 匹配pattern前面的内容,不返回本身
^\\d+(?=</span>)
(2)正向后行断言
语法:(?<=pattern)
作用: 匹配pattern后面的内容,不返回本身
^(?<=<span class="read-count">阅读数:)\\d+
(3)负向先行断言
我爱祖国,我是祖国的花朵
语法:(?!pattern)
作用:匹配非pattern前面的内容,不返回本身
匹配非花朵前的祖国
祖国(?!的花朵)
(4)负向后行断言
语法: (?<pattern)
作用: 匹配非pattern后面的内容,不返回本身
2.捕获和非捕获
捕获:匹配表达式,
捕获组:匹配子表达式的内容,把匹配结果保存到内存中中数字编号或显示命名的组里,以深度优先进行编号,之后可以通过序号或名称来使用这些匹配结果。

(2)命名编号捕获组
也就是自定义分组编号名称
语法:(?<name>exp)
上述区号可以这样写:
(?<quhao>\0\d{2})-(?<haoma>\d{8})
有如下分组:

(3)非捕获组
语法:(?:exp)
用来标识那些不需要捕获的分组
(?:\0\d{2})-(\d{8})
第一个表达式不需要捕获

3.反向引用
捕获会返回一个捕获组,这个分组是保存在内存中,不仅可以在正则表达式外部通过程序进行引用,也可以在正则表达式内部进行引用,这种引用方式就是反向引用。
按照捕获组命名规则:反向引用可分为:
1.数字编号反向引用 \k 或者 \number
2.命名编号反向引用 \k 或者 \'name'
捕获组的作用主要是用来查找一些重复的内容或做替换指定字符
比如要查找一串字母"aabbbbgbddesddfiid"里成对的字母
首先得匹配到上一个字母,然后保存下来,再判断下一个字母是否和上一个相等,这里可以用捕获保存
用捕获组作为搜索条件 (\\w)\\1
\1指数字命名
替换:假如想要把字符串中abc换成a
String test = "abcbbabcbcgbddesddfiid";
String reg="(a)(b)c";
System.out.println(test.replaceAll(reg, "$1"));;
4.贪婪和非贪婪
贪婪匹配:就是匹配尽可能多的字符,每次不匹配了舍弃最右边字符继续匹配
非贪婪匹配(懒惰匹配):尽可能少匹配,懒惰量词是在贪婪量词后加个?号

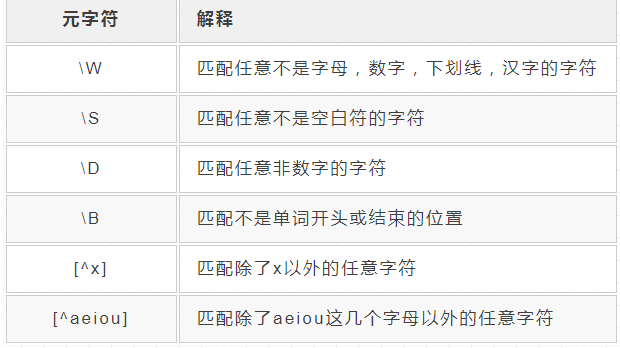
5.反义字符


 浙公网安备 33010602011771号
浙公网安备 33010602011771号