
A simple test
博士生课程报告
视觉信息检索技术
博 士 生:施 智 平
指导老师:史忠植 研究员
中国科学院计算技术研究所
2005年1月
目 录
第一部分 综述
第1章 基于内容的多媒体检索技术综述
基于内容的多媒体信息检索技术是数字图书馆的关键技术之一,是海量多媒体信息资源得以高效、充分地获取和利用的技术支持。它的成熟发展和在数字图书馆建设中的推广应用,将从根本上提升数字图书馆的信息检索能力和对用户的信息贡献力度。
1 关于基于内容的多媒体信息检索技术
对于数字图书馆环境下,以多媒体、超文本为主要存储形式的海量数字化信息资源,关键词已经难以足够形象和准确地描述多媒体信息所呈现的视觉或听觉感知,致使适用于文本信息资源的关键词检索方式显得相形见绌,而基于内容的多媒体信息检索技术在数字图书馆建设中逐渐显示出无比的优越性。
所谓基于内容的信息检索(content-based retrieval)是对文本、图像、音频、视频等媒体对象进行内容语义的分析和特征的提取,并基于这些特征进行相似性匹配的信息检索技术。它与传统数据库基于关键词的检索方式相比,具有如下特点:
1.1 突破了关键词检索基于文本特征的局限,直接从媒体内容中提取特征线索,使检索更加接近媒体对象。
1.2 提取特征的方法多种多样,例如,可以提取图像的形状特征、颜色特征、纹理特征,视频的动态特征,音频的音调特征等。
1.3 人机交互式检索。基于内容的检索系统通常采用参数调整方法、聚类分析方法、概率学习方法和神经网络方法等,通过人机交互的方式来捕捉和建立多媒体信息低层特征和高层语义之间的关联,即所谓相关反馈技术。其目的是在检索过程中根据用户的查询要求返回一组检索结果,用户可以对检索结果进行评价和标记,然后反馈给系统,系统根据这些反馈信息进行学习,再返回新的查询结果,从而使检索结果更接近用户的要求。
1.4 相似性匹配检索。基于内容的检索是按照一定的匹配算法将需求特征与特征库中的特征元数据(metadata)进行相似性匹配,满足一定相似性的一组初始结果按照相似度大小排列,提供给用户。这与关键词的精确匹配算法有明显不同。
1.5 逐步求精的检索过程。用户通过浏览初始结果,可以从中挑选相似结果,或者选择其中一个结果作为示例,进行特征的调整,并重新进行相似性匹配,经过多次循环后不断缩小查询范围,做到逐步求精,最终得到较为理想的查询结果。
综上所述,基于内容的多媒体信息检索技术的开发重点和技术优势主要包括以下两项:对多媒体信息内容特征的识别和描述技术、对特征的相似性匹配技术。可见,这种检索技术是一项涉及面很广的交叉学科的应用技术,需要利用图像处理、模式识别、计算机视觉、图像理解等领域的知识作为基础,还需从认知科学、人工智能、数据库管理系统、人机交互、信息检索等领域引入新的媒体数据表示和数据模型,从而设计出可靠、有效的检索算法、系统结构以及友好的人机界面。
2 基于内容的图像检索
基于内容的图像检索技术是通过分析图像的内容,提取其颜色、形状、纹理等可视特征,建立特征索引,存储于特征库中;在检索时,用户只需把自己对图像的模糊印象描述出来,就可以通过多次的近似匹配,在大容量图像库中查询到所需图像。
2.1 基于颜色特征的检索
颜色是描述一幅图像最简便而有效的特征,在基于颜色特征的检索算法中通常用颜色直方图来表示图像的颜色特征。直方图能较好地反映图像中各颜色的频率分布,横轴表示颜色等级,纵轴表示在一个颜色等级上,具有该颜色的像素在整幅图像中所占的比例。直方图可以对整幅图像进行最大匹配度检索;如果用户希望对图像中的部分颜色加以指定,可以采用基于图像分割的直方图检索方法,即将一幅图像划分为n×n个子图像,将对应位置的子图像颜色特征与数据库中的图像进行对比匹配。
2.2 基于纹理特征的检索
纹理是基于内容图像检索的一条主要线索,它包含了关于图像表面的结构安排和周围环境的关系。在70年代初期,Haralick等人提出了纹理特征的共生矩阵表示法。他首先根据像素间的方向和距离构造一个共生矩阵,然后从共生矩阵中抽取有意义的统计量作为纹理表示。Tamura等人则从视觉的心理学角度提出了纹理表示方法,表示的所有纹理性质都具有直观的视觉意义,这使得Tamura纹理表示在图像检索中非常具有吸引力,而且可以提供一个更友好的用户界面。进入90年代,小波变换理论被应用于纹理表示之中。
在基于图像纹理特征的实际检索中,一般采用示例查询(QuerybyExample)方式。用户给出一个所需图像的示例,系统会按照示例搜索与之相似的图像,用户在这些相似图像集合中确定检索目标。
2.3 基于形状特征的检索
形状是描述图像内容的本质特征,在实际检索中,形状特征的表达和匹配经常采用最为简便的方法,即用形状参数(shapefactor),如矩、面积、周长等定量测度来描述图像形状并进行匹配;也可以分割图像,进行边缘提取,得到目标的轮廓线,针对轮廓线进行形状特征检索。
2.4 基于知识的图像检索
基于知识的图像检索也是基于内容检索的重要方法之一。图像本身是一定数量的颜色像素点的集合,人类能够识别出像素点集合的含义是人类以自身的知识赋予图像意义的过程。基于知识的图像检索系统为用户提供知识库,针对一个图像需求,搜索引擎依次调入每一幅图像的内容描述,结合知识库中的相关知识,以图像需求为目标进行推理,如果需求目标得到满足,则确定这幅图像符合检索要求。
3 基于内容的视频检索
基于内容的视频信息检索是当前多媒体数据库发展的一个重要研究领域,它通过对非结构化的视频数据进行结构化分析和处理,采用视频分割技术,将连续的视频流划分为具有特定语义的视频片段——镜头,作为检索的基本单元,在此基础上进行代表帧(representativeframe)的提取和动态特征的提取,形成描述镜头的特征索引;依据镜头组织和特征索引,采用视频聚类等方法研究镜头之间的关系,把内容相近的镜头组合起来,逐步缩小检索范围,直至查询到所需的视频数据。这里,视频分割、代表帧和动态特征提取是基于内容的视频检索的关键技术。
3.1 基于代表帧的检索
代表帧是用于描述一个镜头的关键图像,它反映镜头的主要内容。代表帧的选取方法很多,比较经典的是帧平均法和直方图平均法,其特征的提取与一般静态图像一样,包括颜色特征、纹理特征和轮廓特征等。
视频被抽象为代表帧之后,视频检索就变成按照某种相似度来检索数据库中与需求相似的代表帧。目前常用的查询方式是示例查询,即根据用户提交的视频例子,在视频特征库的支持下,检索到相似的代表帧,用户就可以通过播放观看它代表的视频片段,并挑选相似的图像,选择这些图像中所有相近的代表帧,重新进行更精确的查询。
3.2 基于动态特征的检索
视频数据的动态特征是检索时用户所能给出的主要内容,例如,镜头的运动变化、运动目标的大小变化、视频目标的运动轨迹等。这些动态特征的提取与代表帧的提取不同,不能从静态图像中获得,必须对整个视频序列进行分析。
基于动态特征来搜索镜头是视频检索的进一步要求。检索时可以利用运动方向和幅度特征来检索运动的主体目标,还可以将动态特征与代表帧特征结合起来,检索出动态特征相似但静态特征不同的镜头。
3.3 视频浏览
视频浏览是视频数据库的重要组成部分,当用户对所要检索的目标不十分明确时,往往需要对视频数据进行快速浏览以便寻找感兴趣的内容,目的是排除次要内容,以较少的图像尽可能全面地表达出所需视频数据的主要内容特征。
4 基于内容的多媒体信息检索系统开发概况
4.1 QBIC系统
由IBMAlmaden研究中心开发,是基于内容的检索系统的典型代表。QBIC系统允许使用示例图像、用户构建的草图、选择的颜色和纹理模式、镜头和目标运动以及其他图形信息等,对大型图像和视频数据库进行查询。
4.2 Photobook系统
由MIT的媒体实验室于1994年开发研制。图像在存储时按人脸、形状或纹理特性自动分类,图像根据类别通过显著语义特征压缩编码。
4.3 CORE系统
这是新加坡国立大学开发的一个基于内容的检索系统。其显著的技术特色包括:多种特征提取方法、多种基于内容检索方法、使用自组织神经网络对复杂特征度量、建立基于内容索引的新方法以及对多媒体信息进行模糊检索的新技术。
4.4 VisualSEEK系统
由美国哥伦比亚大学图像和高级电视实验室开发。它实现了互联网上基于内容的图像/视频检索系统,提供了一套工具供人们在Web上检索图像和视频信息。
另外还有许多类似的系统,例如,加利福尼亚大学SantaBarbara分校的Netra、伊利诺依大学的Infomedia以及哥伦比亚大学的VideoQ等。
5 基于内容的多媒体检索技术的发展趋势
基于内容的多媒体信息检索技术与传统数据库技术、Web搜索引擎技术相结合,可以方便地实现海量多媒体信息资源的存储和管理,并可以检索HTML网页中丰富的多媒体信息。在可预见的将来,基于内容的多媒体检索技术将会在数字图书馆建设中得到广泛应用。
但随着多媒体内容的增多和存储技术的提高,目前的技术开发还远远不够,有待于进行更深层次的研究和探索。基于内容的多媒体检索技术的发展趋势主要集中在以下几方面:
5.1 综合的多特征检索技术
多媒体具有各种视觉和听觉特征以及其他时间和空间关系,对于同一种特征,也有不同的表示方法,例如,同样是颜色特征,可以有直方图特征、颜色距(Colormoments)、颜色集(Colorsets)、主颜色等多种特征表示法,它们从不同的角度表示媒体的特征。而如何有机地组织多种特征,并按照用户的查询要求合并各种特征的检索结果,将是一个值得研究的问题。
——综合还意味着采纳其他学科领域的成果,如传统的基于文本的信息检索技术、人工智能技术等。基于内容的检索系统并不排斥传统常规的检索途径,相反,要充分利用现有的文本检索功能,并集成到基于内容的检索系统中,向用户提供完备的检索能力。
5.2 高层概念和低层特征的关联
人们在日常生活中习惯使用的事物概念,例如,"楼房、汽车、海滩"等是用以表达具体含义的概念,在多媒体信息查询中也经常使用,而且属于多媒体数据的高层语义内容。目前,基于低层特征的检索技术已基本成熟,如果能够建立这些低层特征与高层语义概念的关联,将实现媒体语义的计算机自动抽取。针对多媒体信息检索系统而言,在响应时间和大容量数据库约束的前提下,可以采用语义模板、用户交互、机器学习、神经网络等方法,突破从低层特征获取高层语义的壁垒。
5.3 高维索引技术
对于大容量的多媒体数据库,在基于内容的检索过程中,特征矢量常常高达102量级,大大多于常规数据库的索引能力,因此,需要研究新的索引结构和算法,以支持快速检索。目前,一般采用先减少维数,再用适当的多维索引结构的方法。虽然过去已经取得了一些进展,例如,k-d树和R-树以及改进的索引树结构,但仍然需要研究和探索有效的高维索引方法,以支持多特征、异构特征、权重、主键特征方面的查询要求。
5.4 时序媒体的内容结构化
典型的时序媒体是视频和音频。它们是一种非结构化的连续媒体流数据,需要进行结构化分析和处理,才能进行特征的提取。目前镜头分割技术相对成熟,计算机可以基于镜头进行浏览。但是,对于一段镜头非常多的视频,浏览起来很不方便。另外,镜头并不是人们关心的语义单元,而是些零散的剪切单元。因此,目前的研究热点是结合多类特征(音频、视频、文本等)抽取视频的语义和叙事结构,在多个层次上组织视频内容。
5.5 用户查询接口
现代多媒体信息系统的一个重要特征就是信息获取过程的可交互性,用户在系统中是主动的。除了提供示例和描绘查询的基本接口之外,用户的查询接口应提供丰富的交互能力,使用户在主动的交互过程中表达对媒体语义的感知,调整查询参数及其组合,最终获得满意的查询结果。
第二部分 基于内容的图像检索技术
近年来,随着多媒体技术和计算机网络的飞速发展,全世界的数字图像的容量正以惊人的速度增长。无论是军用还是民用设备,每天都会产生容量相当于数千兆字节的图像。这些数字图像中包含了大量有用的信息。然而,由于这些图像是无序地分布在世界各地,图像中包含的信息无法被有效地访问和利用。这就要求有一种能够快速而且准确地查找访问图像的技术,也就是所谓的图像检索技术。自从20世纪70年代以来,在数据库系统和计算机视觉两大研究领域的共同推动下,图像检索技术已逐渐成为一个非常活跃的研究领域。数据库和计算机视觉两大领域是从不同的角度来研究图像检索技术的,前者基于文本的,而后者是基于视觉的。
基于文本的图像检索技术(text-based image retrieval)的历史可以追溯到20世纪70年代末期。当时流行的图像检索系统是将图像作为数据库中存储的一个对象,用关键字或自由文本对其进行描述。查询操作是基于该图像的文本描述进行精确匹配或概率匹配,有些系统的检索模型还是有词典支持的。另外,图像数据模型、多维索引、查询评价等技术都在这样一个框架之下发展起来。然而,完全基于文本的图像检索技术存在着严重的问题。首先,目前的计算机视觉和人工智能技术都无法自动对图像进行标注,而必须依赖于人工对图像做出标注。这项工作不但费时费力,而且手工的标注往往是不准确或不完整的,还不可避免地带有主观偏差。也就是说,不同的人对同一幅图像有不同的理解方法,这种主观理解的差异将导致图像检索中的失配错误。此外,图像中所包含的丰富的视觉特征(颜色或纹理等)往往无法用文本进行客观地描述的。
90年代初期,随着大规模数字图像库的出现,上述的问题变得越来越尖锐。为克服这些问题,基于内容的图像检索技术(content-based image retrieval)应运而生。区别于原有系统中对图像进行人工标注的做法,基于内容的检索技术自动提取每幅图像的视觉内容特征作为其索引,如色彩、纹理、形状等。此后几年中,这个研究领域中的许多技术发展起来,一大批研究性的或商用的图像检索系统被建立起来。这个领域的发展主要来归功于计算机视觉技术的进步,在文献[]中有对这一领域的详细介绍。
应该认识到,基于内容的图像检索系统具有与传统基于文本的检索系统完全不同的构架。首先,由于图像依赖其视觉特征而非文本描述进行索引,查询将根据图像视觉特征的相似度进行。用户通过选择具有代表性的一幅或多幅例子图像来构造查询,然后由系统查找与例子图像在视觉内容上比较相似的图像,按相似度大小排列返回给用户。这就是所谓的通过例子图像的检索(query by image example)。另外,基于内容的检索系统一般通过可视化界面和用户进行频繁的交互,以便于用户能够方便地构造查询、评估检索结果和改进检索结果。
基于内容图像检索的体系结构划分为两个子系统:特征抽取子系统和查询子系统,如图2-1所示。

Fig.2-1 Architecture of Content-Based Image Retrieval system
图2-1基于内容图像检索的体系结构
各个模块的主要功能如下:
1.预处理
包括图像格式的转换、尺寸的统一,图像的增强与去噪等功能,为图像的特征提取打下基础。
2.目标标识
目标标识为用户提供一种工具,以全自动或半自动(需要用户干预)的方式标识图像中用户感兴趣的区域或目标对象,以便针对目标进行特征提取并查询。当进行整体内容检索时,利用全局特征,这时不用目标标识功能。目标标识是可选的。
3.特征提取
对图像数据库进行特征提取,提取用户感兴趣的、适合检索要求的特征。特征提取可以是全局性的,即整幅图像,也可以是针对某个目标的,即图像中的子区域,如人脸等。
4. 数据库
生成的数据库由图像库、特征库和知识库组成。图像库为数字化的图像信息,特征库包含用户输入的特征和预处理自动提取的内容特征。知识库包含专门和通用知识,有利于查询优化和快速匹配,知识库中知识表达可以更换以适用各种不同的应用领域。
5.查询接口
友好的人机交互界面是一个成功检索系统不可缺少的条件,它可以大大提高检索的效率。在基于内容检索中,由于特征值为高维向量,不具有直观性,因此必须为其提供一个可视化的输入手段。可采用的方式有三种:操纵交互输入方式、模板选择输入方式和用户提交特征样板的输入方式。同时应支持多种特征的组合。另外,查询返回的结果需要浏览,应在用户界面提供浏览功能。
6.检索引擎
检索是利用特征之间的距离函数来进行相似性检索。模仿人的认知过程,近似得到数据库的认知排队,存在一些不同的相似性测度算法,检索引擎中包括一个较为有效可靠的相似性测度函数集。
7. 索引/过滤
检索引擎通过索引/过滤模块达到快速搜索的目的,从而可以应用到大型数据库中。过滤器作用于全部数据,过滤出的数据集合再用高维特征匹配来检索。索引用于低维特征,可以用R树来索引以加快检索。
在这一部分中,我们将主要讨论有关基于内容的图像检索方面的一些相关问题和方法。第2章中给出了一系列图像视觉特征的提取、表达和索引方法。第3章中讨论了图像相似度衡量方法和其它检索相关技术。在第4章中,我们介绍了图像检索中相关反馈的机制和途径。最后,第5章中总结了现有的一些图像检索系统,并对这一领域的未来方向作出展望。
第2章 图像特征的提取与表达
图像特征的提取与表达是基于内容的图像检索技术的基础。从广义上讲,图像的特征包括基于文本的特征(如关键字、注释等)和视觉特征(如色彩、纹理、形状、对象表面等)两类。由于基于文本的图像特征提取在数据库系统和信息检索等领域中已有深入的研究,本章中我们主要介绍图像视觉特征的提取和表达。
视觉特征又可分为通用的视觉特征和领域相关的视觉特征。前者用于描述所有图像共有的特征,与图像的具体类型或内容无关,主要包括色彩、纹理和形状;后者则建立在对所描述图像内容的某些先验知识(或假设)的基础上,与具体的应用紧密有关,例如人的面部特征或指纹特征等。由于领域相关的图像特征主要属于模式识别的研究范围,并涉及许多专业的领域知识,在此我们就不再详述,而只考虑通用的视觉特征。
对于某个特定的图像特征,通常又有多种不同的表达方法。由于人们主观认识上的千差万别,对于某个特征并不存在一个所谓的最佳的表达方式。事实上,图像特征的不同表达方式从各个不同的角度刻画了该特征的某些性质。在本章中,我们主要介绍那些由实践证明对图像检索比较有效的特征和相应的表达方法。本章的第1、2、3节中我们将分别介绍图像的颜色、纹理和形状特征,第4节中介绍包含有空间信息的图像特征,最后一节简述了多维索引技术和降低维度技术。
2.1 颜色特征的提取
颜色特征是在图像检索中应用最为广泛的视觉特征,主要原因在于颜色往往和图像中所包含的物体或场景十分相关。此外,与其他的视觉特征相比,颜色特征对图像本身的尺寸、方向、视角的依赖性较小,从而具有较高的鲁棒性。
面向图像检索的颜色特征的表达涉及到若干问题。首先,我们需要选择合适的颜色空间来描述颜色特征;其次,我们要采用一定的量化方法将颜色特征表达为向量的形式;最后,还要定义一种相似度(距离)标准用来衡量图像之间在颜色上的相似性。在本节中,我们将主要讨论前两个问题,并介绍颜色直方图、颜色矩、颜色集、颜色聚合向量以及颜色相关图等颜色特征的表示方法。
2.1.1 颜色直方图
颜色直方图是在许多图像检索系统中被广泛采用的颜色特征。它所描述的是不同色彩在整幅图像中所占的比例,而并不关心每种色彩所处的空间位置,即无法描述图像中的对象或物体。颜色直方图特别适于描述那些难以进行自动分割的图像。
当然,颜色直方图可以是基于不同的颜色空间和坐标系。最常用的颜色空间是RGB颜色空间,原因在于大部分的数字图像都是用这种颜色空间表达的。然而,RGB空间结构并不符合人们对颜色相似性的主观判断。因此,有人提出了基于HSV空间、Luv空间和Lab空间的颜色直方图,因为它们更接近于人们对颜色的主观认识。其中HSV空间是直方图最常用的颜色空间。它的三个分量分别代表色彩(Hue)、饱和度(Saturation)和值(Value)。从RGB空间到HSV空间的转化公式如下所示:
给定RGB颜色空间的值(r,g,b),r,g,bÎ[0,1,…,255],则转换到 HSV空间的(h,s,v)值计算如下:
设 定义
定义 为:
为:

则

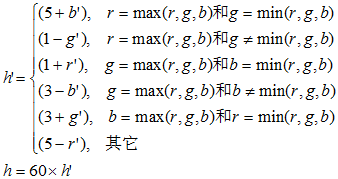
其中r, g, b∈ [0 … 1], h∈ [0 … 6], and s, v∈ [0 … 1]。从RGB空间到Luv空间和到Lab空间的转化可以在文献[1]中找到。
计算HSV空间中两种颜色的距离由多种不同的方法。例如在[2]中提出了如下的颜色距离计算公式:
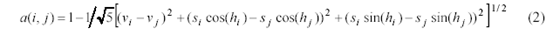 其中(hi, si, vi)和(hj, sj, vj) 分别代表两种HSV空间中的颜色。这种相似度量方法相当于一个圆柱形颜色空间中的欧拉距离,该空间中的颜色值表示为(scosh, ssinh, v)。在[3]中这样的圆柱空间被进一步变形称为圆锥性空间,其中的颜色表示为(svcosh, svsinh, v)。这些改变使v值较小的时候,降低了直方图对h和s分量的分辨能力。
其中(hi, si, vi)和(hj, sj, vj) 分别代表两种HSV空间中的颜色。这种相似度量方法相当于一个圆柱形颜色空间中的欧拉距离,该空间中的颜色值表示为(scosh, ssinh, v)。在[3]中这样的圆柱空间被进一步变形称为圆锥性空间,其中的颜色表示为(svcosh, svsinh, v)。这些改变使v值较小的时候,降低了直方图对h和s分量的分辨能力。
计算颜色直方图需要将颜色空间划分成若干个小的颜色区间,每个小区间成为直方图的一个bin。这个过程称为颜色量化(color quantization)。然后,通过计算颜色落在每个小区间内的像素数量可以得到颜色直方图。颜色量化有许多方法,例如向量量化、聚类方法或者神经网络方法。最为常用的做法是将颜色空间的各个分量(维度)均匀地进行划分。相比之下,聚类算法则会考虑到图像颜色特征在整个空间中的分布情况,从而避免出现某些bin中的像素数量非常稀疏的情况,使量化更为有效。另外,如果图像是RGB格式而直方图是HSV空间中的,我们可以预先建立从量化的RGB空间到量化的HSV空间之间的查找表(look-up table),从而加快直方图的计算过程。
上述的颜色量化方法会产生一定的问题。设想两幅图像的颜色直方图几乎相同,只是互相错开了一个bin,这时如果我们采用L1距离或者欧拉距离(见3.1.1节)计算两者的相似度,会得到很小的相似度值。为了克服这个缺陷,需要考虑到相似但不相同的颜色之间的相似度。一种方法是采用二次式距离[4](见3.1.3节)。另一种方法是对颜色直方图事先进行平滑过滤,即每个bin中的像素对于相邻的几个bin也有贡献。这样,相似但不相同颜色之间的相似度对直方图的相似度也有所贡献。
选择合适的颜色小区间(即直方图的bin)数目和颜色量化方法与具体应用的性能和效率要求有关。一般来说,颜色小区间的数目越多,直方图对颜色的分辨能力就越强。然而,bin的数目很大的颜色直方图不但会增加计算负担,也不利于在大型图像库中建立索引。而且对于某些应用来说,使用非常精细的颜色空间划分方法不一定能够提高检索效果,特别是对于不能容忍对相关图像错漏的那些应用。另一种有效减少直方图bin的数目的办法是只选用那些数值最大(即像素数目最多)的bin来构造图像特征,因为这些表示主要颜色的bin能够表达图像中大部分像素的颜色。实验证明这种方法并不会降低颜色直方图的检索效果。事实上,由于忽略了那些数值较小的bin,颜色直方图对噪声的敏感程度降低了,有时会使检索效果更好。两种采用主要颜色构造直方图的方法可以在文献[5,6]中找到。
2.1.2 颜色矩
另一种非常简单而有效的颜色特征使由Stricker 和Orengo所提出的颜色矩(color moments) [7]。这种方法的数学基础在于图像中任何的颜色分布均可以用它的矩来表示。此外,由于颜色分布信息主要集中在低阶矩中,因此仅采用颜色的一阶矩(mean)、二阶矩(variance)和三阶矩(skewness)就足以表达图像的颜色分布。与颜色直方图相比,该方法的另一个好处在于无需对特征进行向量化。颜色的三个低次矩在数学上表达为:

其中pij是图像中第j个像素的第i个颜色分量。因此,图像的颜色矩一共只需要9个分量(3个颜色分量,每个分量上3个低阶矩),与其他的颜色特征相比是非常简洁的。在实际应用中为避免低次矩较弱的分辨能力,颜色矩常和其它特征结合使用,而且一般在使用其它特征前起到过滤缩小范围(narrow down)的作用。
2.1.3 颜色集
为支持大规模图像库中的快速查找,Smith和Chang提出了用颜色集(color sets)作为对颜色直方图的一种近似[8]。他们首先将RGB颜色空间转化成视觉均衡的颜色空间(如HSV空间),并将颜色空间量化成若干个bin。然后,他们用色彩自动分割技术将图像分为若干区域,每个区域用量化颜色空间的某个颜色分量来索引,从而将图像表达一个二进制的颜色索引集。在图像匹配中,比较不同图像颜色集之间的距离和色彩区域的空间关系(包括区域的分离、包含、交等,每种对应于不同得评分)。因为颜色集表达为二进制的特征向量,可以构造二分查找树来加快检索速度,这对于大规模的图像集合十分有利。
2.1.4 颜色聚合向量
针对颜色直方图和颜色矩无法表达图像色彩的空间位置的缺点,Pass[9]提出了图像的颜色聚合向量(color coherence vector)。它是颜色直方图的一种演变,其核心思想是将属于直方图每一个bin的像素进行分为两部分:如果该bin内的某些像素所占据的连续区域的面积大于给定的阈值,则该区域内的像素作为聚合像素,否则作为非聚合像素。假设αi与βi分别代表直方图的第i个bin中聚合像素和非聚合像素的数量,图像的颜色聚合向量可以表达为<(α1, β1), (α2, β2), …, (αN, βN)>。而<α1 + β1, α2 + β2, …, αN +βN > 就是该图像的颜色直方图。由于包含了颜色分布的空间信息,颜色聚合向量相比颜色直方图可以达到更好的检索效果。
2.1.5 颜色相关图
颜色相关图(color correlogram)是图像颜色分布的另一种表达方式[16]。这种特征不但刻画了某一种颜色的像素数量占整个图像的比例,还反映了不同颜色对之间的空间相关性。实验表明,颜色相关图比颜色直方图和颜色聚合向量具有更高的检索效率,特别是查询空间关系一致的图像。
假设I表示整张图像的全部像素,i) 则表示颜色为c(i)的所有像素。颜色相关图可以表达为:

其中i, j ∈ {1, 2, …, N},k∈ {1, 2, …, d},| p1 – p2 | 表示像素p1和p2之间的距离。颜色相关图可以看作是一张用颜色对<i, j>索引的表,其中<i, j>的第k个分量表示颜色为c(i)的像素和颜色为c(j)的像素之间的距离小于k的概率。如果考虑到任何颜色之间的相关性,颜色相关图会变得非常复杂和庞大(空间复杂度为O(N2d))。一种简化的变种是颜色自动相关图(color auto-correlogram),它仅仅考察具有相同颜色的像素间的空间关系,因此空间复杂度降到O(Nd)。
2.2 纹理特征的提取
纹理特征是一种不依赖于颜色或亮度的反映图像中同质现象的视觉特征[12]。它是所有物体表面共有的内在特性,例如云彩、树木、砖、织物等都有各自的纹理特征。纹理特征包含了物体表面结构组织排列的重要信息以及它们与周围环境的联系[13]。正因为如此,纹理特征在基于内容的图像检索中得到了广泛的应用,用户可以通过提交包含有某种纹理的图像来查找含有相似纹理的其他图像。
由于纹理特征对模式识别和计算机视觉等领域的重要意义,对纹理的分析研究在过去的三十年中取得了重大的成果。在本节中,我们将着重介绍那些在基于内容的图像检索中所常用的那些纹理特征,主要有Tamura纹理特征、自回归纹理模型、方向性特征、小波变换和共生矩阵等形式。
2.2.1 Tamura纹理特征
基于人类对纹理的视觉感知的心理学的研究,Tamura等人提出了纹理特征的表达[14]。Tamura纹理特征的六个分量对应于心理学角度上纹理特征的六种属性,分别是粗糙度(coarseness)、对比度(contrast)、方向度(directionality)、线像度(linelikeness)、规整度(regularity)和粗略度(roughness)。其中,前三个分量对于图像检索尤其重要[e.g,15]。接下来我们就着重讨论粗糙度、对比度和方向度这三种特征的定义和数学表达。
粗糙度。粗糙度的计算可以分为以下几个步骤进行。首先,计算图像中大小为2k × 2k个像素的活动窗口中像素的平均强度值,即有

其中k = 0, 1, …, 5 而g(i, j)是位于(i, j)的像素强度值。然后,对于每个像素,分别计算它在水平和垂直方向上互不重叠的窗口之间的平均强度差。

其中对于每个像素,能使E 值达到最大(无论方向)的k 值用来设置最佳尺寸Sbest(x,y)=2k。最后,粗糙度可以通过计算整幅图像中Sbest的平均值来得到,表达为

粗糙度特征的另一种该进形式是采用直方图来描述Sbest的分布,而不是像上述方法一样简单地计算Sbest的平均值。这种改进后的粗糙度特征能够表达具有多种不同纹理特征的图像或区域,因此对图像检索更为有利。
对比度。对比度是通过对像素强度分布情况的统计得到的。确切地说,它是通过α4 =μ4/σ4来定义的,其中μ4 是四次矩而σ2 是方差。对比度是通过如下公式衡量的:

该值给出了整个图像或区域中对比度的全局度量。
方向度。方向度的计算需要首先计算每个像素处的梯度向量。该向量的模和方向分别定义为

其中.H 和.V 分别是通过图像卷积下列两个3x3操作符所得的水平和垂直方向上的变化量。

当所有像素的梯度向量都被计算出来后,一个直方图HD被构造用来表达θ 值。该直方图首先对θ 的值域范围进行离散化,然后统计了每个bin中相应的|.G|大于给定阈值的像素数量。这个直方图对于具有明显方向性的图像会表现出峰值,对于无明显方向的图像则表现得比较平坦。最后,图像总体的方向性可以通过计算直方图中峰值的尖锐程度获得,表示如下:

上式中的p代表直方图中的峰值,np为直方图中所有的峰值。对于某个峰值p,Wp 代表该峰值所包含的所有的bin,而φp 是具有最高值的bin。
2.2.2 自回归纹理模型
最近二十年中有大量的研究集中在应用随机场模型表达纹理特征,这方面Markov随机场(MRF)模型取得了很大的成功。自回归纹理模型(simultaneous auto-regressive,或SAR)就是MRF模型的一种应用实例。
在SAR模型中,每个像素的强度被描述成随机变量,可以通过与其相邻的像素来描述。如果s代表某个像素,则其强度值g(s)可以表达为它的相邻像素强度值的线性叠加与噪音项ε (s)的和,如下所示:

其中μ 是基准偏差,由整幅图像的平均强度值所决定,D表示了s的相邻像素集。θ(r) 是一系列模型参数,用来表示不同相邻位置上的像素的权值。ε(s) 是均值为0而方差为σ2 的高斯随机变量。通过上式可以用回归法计算参数θ 和标准方差σ 的值,它们反映了图像的各种纹理特征。例如较高的σ 表示图像具有很高的精细度,或较低的粗糙度。又比如,如果s正上方和正下方的θ很高,表明图像具有垂直的方向性。最小误差法(least square error)和极大似然估计(maximum likelihood estimation)可以用来计算模型中的参数。此外,SAR的一种变种称为旋转无关的自回归纹理特征(rotation-invariant SAR或RISAR),具有与图像的旋转无关的特点。
定义合适的SAR模型需要确定相邻像素集合的范围。然而,固定大小的相邻像素集合范围无法很好地表达各种纹理特征。为此,有人提出过多维度的自回归纹理模型(multi-resolution SAR或MRSAR)[16],能够在多个不同的相邻像素集合范围下计算纹理特征。文献[17,18]中给出了MRSAR纹理特征和其他纹理特征对于图像检索的性能对比。实验结果表明MRSAR纹理特征能够较好地识别出图像中各种纹理特征。
2.2.3 小波变换
小波变换(wavelet transform)也是一种常用的纹理分析和分类方法[19,20]。小波变换指的是将信号分解为一系列的基本函数ψmn(x)。这些基本函数都是通过对母函数ψ(x)的变形得到,如下所示:

其中m和n是整数。这样,信号f (x) 可以被表达为:

二维小波变换的计算需要进行递归地过滤和采样。在每个层次上,二维的信号被分解为四个子波段,根据频率特征分别称为LL、LH、HL和HH。有两种类型的小波变换可以用于纹理分析,其中是金字塔结构的小波变换(pyramid-structured wavelet transform 或PWT)和树桩结构的小波变换(tree-structured wavelet transform或TWT)。PWT 递归地分解LL波段。但是对于那些主要信息包含在中频段范围内的纹理特征,仅仅分解低频的LL波段是不够的。因此,TWT被提出来克服上述的问题。TWT区别于PWT的主要之处在于它除了递归分解LL波段之外,还会分解其它的LH、HL和HH等波段。
小波变换表示的纹理特征可以用每个波段的每个分解层次上能量分布的均值和标准方差。例如
三层的分解,PWT表达为3x4x2的特征向量。TWT的特征向量取决于每个子波段是分解方式。一般来说,由PWT所得的特征是由TWT所得特征的一个子集。此外,根据在文献[21]中所作的性能对比,不同的小波变换在对纹理分析方面没有很显著的差别。
2.2.4 其它纹理特征
除了上述的Tamura特征、SAR模型和小波变换等纹理特征之外,还有许多其它的纹理特征。早在70年代,Haralick等研究人员就提出了用共生矩阵(co-occurrence matrix)表示纹理特征的方法[13]。该方法对从数学角度研究了图像纹理中灰度级的空间依赖关系。它首先建立一个基于象素之间方向性和距离的共生矩阵,然后从矩阵中提取有意义的统计量作为纹理特征。许多其他研究人员沿着这个方向提出了扩展的方案。例如Gotlieb和Kreyszig研究了[13]中提出的统计特征,在实验中得出能量、相关性、惯量和熵是最有效的特征[22]。
Gabor过滤法[23]能够最大程度地减少空间和频率的不确定性,同时还能够检测出图像中不同方向和角度上的边缘和线条。[24,25]中提到了很多方法根据过滤输出结果来描述图像特征。
此外,小波变换也常常与其它技术结合以获得更好的效果,例如Gross 等人用小波变换与KL展开式和Kohonen多处理机系统来进行纹理分析[26]。Thyagarajan等[27]用小波变换和共生矩阵来进行纹理分析,结合了统计和变换两者的优点。
2.3 形状特征的提取
物体和区域的形状是图像表达和图像检索中的另一重要的特征。但不同于颜色或纹理等底层特征,形状特征的表达必须以对图像中物体或区域的划分为基础。由于当前的技术无法做到准确而鲁棒的自动图像分割,图像检索中的形状特征只能用于某些特殊应用,在这些应用中图像包含的物体或区域可以直接获得。另一方面,由于人们对物体形状的变换、旋转和缩放主观上不太敏感,合适的形状特征必须满足对变换、旋转和缩放无关,这对形状相似度的计算也带来了难度。
通常来说,形状特征有两种表示方法,一种是轮廓特征的,一种是区域特征的。前者只用到物体的外边界,而后者则关系到整个形状区域。这两类形状特征的最典型方法分别是傅立叶描述符和形状无关矩。我们在下文中将详细介绍这两种方法,同时还简单介绍了其它的形状特征。
2.3.1 傅立叶形状描述符
傅立叶形状描述符(Fourier shape descriptors)的基本思想是用物体边界的傅立叶变换作为其形状描述。假设一个二维物体的轮廓是由一系列坐标为(xs, ys)的像素组成,其中0 ≤ s ≤ N-1,而N是轮廓上像素的总数。从这些边界点的坐标中可以推导出三种形状表达,分别是曲率函数(curvature function)、质心距离(centroid distance)和复坐标函数(complex coordinates function)。.
轮廓线上某一点的曲率定义为轮廓切向角度相对于弧长的变化率。曲率函数K(s) 可以表示为:

其中θ(s) 是轮廓线的切向角度,定义为:

质心距离定义为从物体边界点到物体中心(xc, yc)的距离,如下所示:

复坐标函数是用复数所表示的像素坐标:

对这种复坐标函数的傅立叶变换会产生一系列复数系数。这些系数在频率上表示了物体形状,其中低频分量表示形状的宏观属性,高频分量表达了形状的细节特征。形状描述符可以从这些变换参数中得出。为了保持旋转无关性,我们仅仅保留了参数的大小信息,而省去了相位信息。缩放的无关性是通过将参数的大小除以DC分量(或第一个非零参数)的大小来保证的。请注意变换无关性是基于轮廓的形状表示所固有的特点。
对于曲率函数和质心距离函数,我们只考虑正频率的坐标轴,因为这时函数的傅立叶变换是对称的,即有|F-i| = |Fi|。基于曲率函数的形状描述符表示为

其中Fi表示傅立叶变换参数的第i个分量。类似的,由质心距离所导出的形状描述符为

对于复坐标函数,正频率分量和负频率分量被同时采用。由于DC参数与形状的所处的位置有关而被省区。因此,第一个非零的频率分量被用来对其它变换参数进行标准化。复坐标函数所导出的形状描述符为

为保证数据库中所有物体的形状特征都有相同的长度,在实施傅立叶变换之前需要将所有边界点的数目统一为M。例如, M可以取为2n = 64,这样就可以采用快速傅立叶变换来提高算法效率。
2.3.2 形状无关矩
形状无关矩(Moment Invariants)是基于区域的物体形状表示方法。假设R是用二值图像表示的物体,则R形状的第p+q阶中心矩为:

其中(xc, yc)是物体的中心。为获得缩放无关的性质,可以对该中心矩进行标准化操作[1]:

基于这些矩,Hu [28]提出了一系列分别具有变换、旋转和缩放无关性的7个矩:

除了上述的七种无关矩以外,还有许多计算形状无关矩的方法。在文献[29]中,Yang和Albregtsen在Green定理的基础上提出了在二值图像中快速计算矩的方法。由于许多有效的不变量都是从反复的实验中得到的,Kapur等开发了一系列算法用来系统地寻找特定的几何不变性[30]。Gross 和Latecki还开发出了一种方法,能够在图像数字化的过程中保持物体边缘的定性微分几何[30]。另外,文献[31]还提到了一种代数曲线和不变量的框架,用来在混杂的场景中表示复杂物体。它用多项式拟合来表示局部几何信息,用几何不变量进行对象的匹配和识别。
2.3.3 基于内角的形状特征
在文献[32]中提出了一种基于内角的形状特征表达方法。与傅立叶描述符一样,我们首先将物体近似的表达成多边形的形式。多边形内角的对形状的表达和识别非常重要,可以表达为

显然,基于内角的形状描述与形状所在位置、旋转和大小无关,因此它非常适于图像检索系统。
以下是一系列从内角导出的形状特征定义:
顶点数:多边形的顶点数目越多,形状就越复杂。把具有不同顶点数目的两个形状当作很不相似的两个形状是有一定的合理性的。
内角平均值:多边形所有内角的平均值从一定程度上反映了多边形的形状属性。例如三角形的内角平均值为60度,与矩形的内角平均值90度之间有较大差别。
内角标准方差:多边形内角的标准方差为

其中a是内角的平均值。该标准方差δ是多边形的总体描述。多边形越规则,δ值越小。因此,它可以用来分辨正多边形和不规则多边形。
内角直方图(Intra-angle histogram):首先将0°-360°的角度范围等分成k个区间,作为直方图的k个bin,然后统计每个角度区间中的内角数目。内角直方图反映了内角的总体分布。

我们以上图中内角θ=的计算为例介绍内角的计算方法。设a、b、c三点的中心为p,则有abc∠

其中o为原点。如p在多边形内部,则θ小于180°,否则θ大于180°。当θ≤180°时,

当θ>180°时,

2.3.4 其它形状特征
近年来在形状表示和匹配方面的工作,包括有限元法(Finite Element Method或FEM)、旋转函数(Turning Function)、和小波描述符(Wavelet Descriptor)等方法。FEM [33]定义了一个稳定性矩阵来描述物体上的每一个点与其它点之间的联系。这个稳定性矩阵的特征向量被称作特征空间的模合基。所有的形状都首先映射到这个特征空间,再在特征值的基础上计算形状相似性。类似于傅立叶描述符的思路,Arkin等提出了旋转函数用来比较凹面或凸面多边形的相似性[34]。在文献[35]中,Chuang和Kuo用小波变换来描述物体形状。它几乎包含了符合我们要求的所有性质,如不变性、单一性、稳定性和空间位置等。在众多的形状匹配算法中,Chamfer匹配方法吸引了不少研究者的兴趣。Barrow等首先提出了Chamfer比较法[36],该方法能够以线性的时间复杂度比较两个的形状块集合。为加快匹配的速度,Borgerfos提出了分层Chamfer匹配算法[37],这种匹配算法可以在不同的精确层次上进行,从粗糙到精确。另外,IBM所开发的QBIC图像检索系统[38]采用曲率、离心率和主轴方向等参数作为形状特征。
除了二维形状表示法外,还有许多用于三维形状表达的方法。在[39]中,Wallance和Wintz提出了傅立叶描述符的标准化方法,它包含了所有形状信息,而且计算效率很高。他们还利用了傅立叶描述符的良好插补能力,有效地表示了三维空间中的形状。在文献[40]中,Wallance 和Mitchell提出了兼顾结构和统计方法的局部形状分析法来表达三维形状特征。Taubin提出了用一套代数无关矩来同时表示二维空间的形状特征和三维空间的形状特征[41],大大减少了形状匹配的计算量。
尽管计算上述的形状特征并不复杂,但发明一种符合人们主观判断的形状相似性度量算法还是一个有待解决的难题。同时,要在图像检索中充分使用形状特征,还必须有鲁棒的图像自动分割的通用算法。最近的研究工作中,有人提出了适于处理大规模图片库的图像自动分割算法[42]。
2.4 图像的空间关系特征
上述的颜色、纹理和形状等多种特征反映的都是图像的整体特征,而无法体现图像中所包含的对象或物体。事实上,图像中对象所在的位置和对象之间的空间关系同样是图像检索中非常重要的特征。打个比方,蓝色的天空和蔚蓝的海洋的在颜色直方图上是非常接近而难以辨别。但如果我们指明是"处于图像上半部分的蓝色区域",则一般来说就可以区分天空和海洋。由此可见,包含空间关系的图像特征对检索有很大帮助。
空间关系特征可以分为两类:一类方法首先对图像进行自动分割,划分出其中所含的对象或颜色区域,然后根据这些区域对图像索引;另一类方法则简单地将图像均匀划分若干规则子块,对每个图像子块提取特征建立索引。下面我们分别介绍这两类方法。
2.4.1 基于图像分割的方法
这类方法中的图像空间关系特征主要包括二维符号串,空间四叉树和符号图像。匹兹堡大学的Chang提出了用二维符号串(2D-String)[43]的方法,其基本思想是将图像沿x轴和y轴方向进行投影,然后按2D子串匹配进行图像空间关系的检索。该方法比较简单,但缺点在于仅利用对象质心不足以表达对象的空间位置关系,而且描述的空间关系太简单,实际的空间关系要复杂得多。符号图像[44](symbolic image)方法是基于图像中全部有意义的对象已经被预先分割出来的假设,将每个对象用质心坐标和一个符号名字代表,从而构成整幅图像的索引。这些方法都假设所有对象都可以通过一定的特征被精确地识别出来,因而只需要关注如何匹配对象的空间关系即可。然而,对象并非总是由某些确定的特征构成的。此外,除了少数特殊应用外,图像自动分割对大多数应用来说是相当困难的。下面我们介绍一些常用的图像分割算法。
在[45]中,Lybanon等用基于形态学动作进行自动图像分割。他们用各种类型的图像来测试算法效果,包括光学天文图、红外线的海洋图和磁力图等。这种模拟方法在处理以上科技图像有良好的效果,但处理一般图像的效果还有待进一步证实。Li[46]等提出了基于的模糊熵的分割算法。这种方法是以这样的事实为前提的,即熵的局部最大值对应于图像上各个区域之间的不确定性。它对于那些直方图上没有明显起伏的图像是非常有效的。
所有以上提到的算法都是自动的,其主要优点是可以从大量的图像中提取边界而不占用用户的时间和精力。然而,如果通用领域内没有经过预处理的图像,这种自动的分割技术效果就不太好。通常,算法所划分的仅仅是区域而不是对象。如果想在图像检索中获得高层语义上的对象(实体),就需要人工的辅助。Samadani和Han[47]提出计算机辅助下的边界提取法,将用户手工输入和计算机图像边界生成算法结合起来。Daneels等[48]提出了一种有关有效轮廓的更完善的方法。该方法首先在用户出入的基础上,用贪婪法获得快速初始收敛,然后再动态地改进边框轮廓。Rui等[49]提出了基于色彩、纹理空间中的聚类算法。首先由用户指出图像上感兴趣的区域,再用这个算法将该区域聚合成有意义的对象。
2.4.2 基于图像子块的方法
为了避免准确的图像自动分割的困难,同时又要提供一些有关图像区域空间关系的基本信息,一种折衷的方法是将图像预先等分成若干子块(可能是重叠的),然后分别提取每个子块的各种特征。在检索中,我们首先根据特征计算图像的相应子块之间的相似度,然后通过加权计算总的相似度。类似的方法还有四叉树方法,即将整个图看成四叉树的结构,每一个分支都拥有的直方图来描述颜色特征。此方法可以支持对象空间关系的检索方法,例如"找出草地上是蓝色天空的图片"的查询可以通过把图像分割成上下两个子块,在每个子块中匹配相应的特征来实现。
虽然这类方法从概念上来说非常简单,但这种普通规则的分块并不能精确的给出局部色彩的信息,而且计算和存储的代价都比较昂贵。因此,在这类方法在实际中应用较少,从而给基于对象空间关系的图像检索带来了困难。
2.5 多维图像特征的索引
为了使基于内容的图像检索技术能够扩展到应用于大规模的图像库,我们必须采用有效的多维索引技术。存在的难题有两个方面:
1) 高维数:通常情况下,图像特征向量的维数的数量级是102。
2) 非欧拉的相似度度量:由于欧拉度量方法可能无法有效地模仿人类对视觉内容的所有感知,我们经常需要采用其它的相似性度量方法,例如直方图的交、余弦、相关性等非欧拉的相似度衡量方法。
要解决上述这些问题,可行的途径是首先采用维数缩减技术降低特征向量的维数,然后使用适当的多维索引技术(通常能够支持非欧拉的相似度衡量方法)。
2.5.1 维数缩减技术
虽然图像特征向量的维数非常高,但内在必需的维数并不高[50,51]。因此我们在使用任何索引技术以前,最好首先进行维数缩减。常用的两种缩减方法是Karhunen-Loeve变换(KLT)和按列聚类。
KL变换和它的变种在面部识别、特征图像、信息分析和主成分分析(Principal Component Analysis)等领域内的应用已经得到了深入的研究。Ng和Sedighian [52]曾采用特征图像的方法来实现维数缩减,Faloutsos 和Lin在[53]中提出了用于维数缩减的KLT快速逼近算法。研究结果表明,大多数的实数集合(视觉特征向量)可以大量的缩减维数,并且对检索效果不会产生明显的影响。Chandrasekaran [54]等开发了低秩奇异值分解(Singular Value Decomposition)更新算法,它能够被高效而稳定地应用KL变换。由于图像检索系统是一个的动态系统,不断会有新的图像加入到系统中,索引结构也需要相应地进行动态更新。奇异值分解算法就提供了这样一种动态更新索引结构的工具。
除了KL变换,聚类是另一种实现维数缩减的有力工具。聚类技术被广泛地应用于模式识别、语音分析、信息检索等领域。通常的聚类方法是将相似的对象(如模式、信号和文档等)聚合在一起,以实现识别或分组等功能,即所谓的按行聚类。同样,聚类也可以按列进行,从而缩减特征空间的维数[55]。实验表明这种方法非常简单有效。
值得一提的是,盲目的缩减维数是非常危险的,因为如果维数被缩减到必要的维数以下,图像特征的信息就有可能丢失。为了避免盲目的维数缩减,事后的验证阶段是十分必要的。在众多的验证方法中,Fisher判别式[11]可以提供有效的监督。
2.5.2 多维索引技术
尽管经过了维数缩减,图像特征向量的维度仍然较高,因此我们需要选择一个合适的多维索引算法来为特征向量建立索引。有三个研究领域对多维索引技术做出过贡献,它们分别是计算几何、数据库管理系统和模式识别。现在较流行的多维索引技术包括Bucketing成组算法、k-d树、优先级k-d树、四叉树、K-D-B树、HB树、R树以及它的变种R+ 树和R*树等等。除了以上几种方法,在模式识别领域有广泛应用的聚类和神经网络技术也是可能的索引技术。
多维索引技术的历史可以追溯到20世纪70年代中期。就在那个时候,诸如Cell算法、四叉树和k-d树等各种索引技术纷纷问世,但它们的效果都不尽人意。在GIS和CAD系统对空间索引技术的需求推动下,Guttman于1984年提出了R树索引结构[56]。在他的工作的基础上,许多R树的变种被开发出来,例如Sellis等提出了R+树[58],Greene也提出了他的R树的变种[57]。在1990年,Beckman和Kriegel提出了最佳动态R树的变种—R*树[59]。然而,即便是R*树也无法处理维数高于20的情况。
文献[51,52]中给出了对各种索引算法的综述和对比。其中White和Jain [51]的研究目标是提供通用的或者领域相关的索引算法。受到k-d树和R树的启发,他们提出了VAM k-d树和VAMSplit R树。实验表明VAMSplit R树具有最优的算法效率,但失去了R树所具有的动态特点。在[52]中,Ng和Sedighian提出了一种用于图像检索的三阶段检索技术,即维数缩减、现有索引算法的评估和选择、对所选索引算法的优化。
考虑到几乎所有的树状结构索引技术都是为传统的数据库查询(点查询和范围查询)所设计,而并非为了图像检索所设计,因此有必要探讨能够符合图像检索要求和特点的新的索引结构。Tagare在[60]中研究了这样的技术,他提出了一种树结构的调整方法,能够通过删减妨碍相似度查询效率的树节点来优化树结构。
上述的方法仅仅讨论了如何对图像检索中的高维数据进行索引,而没有涉及到非欧拉的相似度度量问题。图像检索中的许多相似度计算方法都不是基于欧拉距离的,比如颜色直方图的求交。在这个方面上有两种很有希望的技术,分别是聚类技术和神经网络。Charikar等提出了适用于动态信息检索增加的聚类技术[61]。这种技术具有动态的结构,能够处理高维数据,同时支持非欧拉的相似度度量。在[62]中,Rui和Chakrabarti等在速度、精确性和对非欧拉相似度度量的支持等方面进一步扩展了这种技术。
在[63]中,Zhang和Zhong提出了用自组织(Self-Organization Map,或SOM)神经网构造树状索引结构的方法。SOM的好处在于具有无人监督的记忆能力、动态聚类功能和支持任意的相似度度量。通过在纹理集上进行的实验表明,SOM是一种很有希望的索引技术。
第3章 相似度量方法
3.1 视觉特征的相似度模型
在基于文本的检索方法采用的是文本的精确匹配,而基于内容的图像检索则通过计算查询(例子图像)和候选图像之间在视觉特征上的相似度匹配进行。因此,定义一个合适的视觉特征相似度度量方法对检索的效果有很大的影响。由于上一章中的视觉特征大都可以表示成向量的形式,常用的相似度方法都是向量空间模型(vector space model),即将视觉特征看作是向量空间中的点,通过计算两个点之间的接近程度来衡量图像特征间的相似度。
3.1.1 L1距离和L2距离
如果图像特征的各分量之间是正交无关的,而且各维度的重要程度相同,两个特征向量A和B之间距离可以用L1距离或者L2距离(也称为欧拉距离)来度量。其中L1距离可以表示为:

其中N是特征向量的维数。类似地,L2距离可以表示为:

3.1.2 直方图相交
上述两种距离度量方法常用来计算颜色直方图之间的距离。度量直方图距离的另一种方法是直方图相交(histogram intersection)。假设I和Q是两个含有N个bin的颜色直方图,则它们之间的相交距离表示为:

直方图的相交是指两个直方图在每个bin中共有的像素数量。有时,该值还可以通过除以其中一个直方图中所有的像素数量来实现标准化,从而使其值属于[0,1]的值域范围。

3.1.3 二次式距离
对于基于颜色直方图的图像检索来说,二次式(quadratic form)距离已被证明比使用欧拉距离或是直方图相交距离更为有效。原因在于这种距离考虑到了不同颜色之间存在的相似度。两个颜色直方图I和Q之间的二次式距离可以表示为:

这种方法通过引入颜色相似性矩阵A,使其能够考虑到相似但不相同的颜色间的相似性因素。
其中A = [ajj],aij表示直方图中下标为i和j的两个颜色bin之间的相似度。颜色相似性矩阵A可以通过对色彩心理学的研究中获得[64]。与此等价的另一种做法是先对颜色直方图进行求闭包操作,使每个颜色bin的值都受到来自它相邻颜色bin的影响。这样,颜色直方图本身就包含了不同颜色之间的相似性因素,因此可以直接地使用欧拉距离或直方图相交距离。这种对直方图预处理的方法的好处在于在检索过程中计算相似度的代价较小。
3.1.4 马氏距离
如果特征向量的各个分量间具有相关性或者具有不同的权重,可以采用马氏距离(Mahalanobis distance)来计算特征之间的相似度。马氏距离的数学表达为:

其中C是特征向量的协方差矩阵。该距离标准常用来计算SAR特征的相似度。
当特征向量的各分量间没有相关性,马氏距离还可以进一步简化,因为这时只需要计算每个分量的方差ci。简化后的马氏距离如下所示:

对某个图像特征选择一种合适的相似度衡量方法是获取满意的检索效率的重要保证。然而,更为重要和困难的是确定不同特征之间或是同一特征的不同分量之间的权重。
3.1.5 非几何的相似度方法
上述的各种方法都是基于向量空间模型的,采用几何距离作为相似度度量。这样的距离函数通常要满足距离公理的自相似性、最小性、对称性和三角不等性等条件。然而,早在1950年,Attneave[65]用几何距离对一组四边形的感知相似性进行了实验,发现距离度量方法和人对相似性的感知判断之间存在一定差距。Tversky值出相似性的最小性原理在一些识别中并不一定成立。同时,对于相似对称性原则,在一定情况下存在着方向性[66]。对相似三角不等性也同样存在着一些争议。
1977年,Tversky提出了著名的特征对比模型(contrast model)[67]。与几何距离不同,该模型不把每个实体看作特征空间中的一个点,而将每个实体用一个特征集来表示。设两个实体a和b,它们对应的特征集分别为A和B,则两个特征间应当满足匹配性、单调性和独立性假设。基于这样的假设,Tversky提出了对比模型定理:对于满足上述的3个假设的度量函数s,一定存在一个相似度度量函数S和一个非负函数f,以及两个常量α,β>0,对于实体a,b,c,d和它们的特征集A,B,C,D,有如下公式:

f是一个反映特征显著性的函数,衡量指定特征对相似度的贡献。当α≠β时,相似函数是不对称的。Tversky的理论扬弃了几何模型下相似度度量的优缺点,提出了一个广泛的理论衡量方法。这个方法的缺点是还不够实用,只适合那些特征明显的对象,而且对于f函数的表示形式并不是唯一的,在具体的应用环境中还需要进一步的明确。
3.2 图像特征的性能评价
通过上面的章节可知,基于内容的图像检索中采用多种不同的图像特征和相似度算法。对于某个特定的图像库,我们需要选择一种或多种最有效的图像特征和相似度算法。这需要对不同条件下的检索效果进行全面地评价,比较不同方法的优劣,找出最好的方法。
对检索效果的评价在于检索结果的正确与否,主要使用的是查准率(precision)和查全率(recall)两个指标。查准率的含义是在一次查询过程中,系统返回的查询结果中的相关图像的数目占所有返回图像数目的比例;查全率则指系统返回的查询结果中的相关图像的数目占图像库中所有相关图像数目(包括返回的和没有返回的)的比例。用户在评价查询结果时,可以预先确定某些图像作为查询的相关图像,然后根据系统返回的结果来计算查准率和查全率。这两个指标的值越高说明检索方法的效果越好。
Ma和Zhang对一些常用的颜色特征和纹理特征的检索效率进行了全面的对比。他们的实验是基于Corel照片库和Brodatz图片集[68]中的20,000幅彩色图像进行的。这些图像在内容上有很大的差异,因此可以保证实验的客观公正。为简化起见,所有的图像特征都是从整幅图像中提取的,而没有将图像划分为区域来分别提取特征。检索性能是在一定返回结果数量的前提下通过查全率来衡量的。下面是他们详细的实验结果。
3.2.1 颜色特征的比较
他们的实验中对比了四种基本的颜色特征,它们分别是颜色直方图、颜色矩、颜色聚合向量和颜色相关图。
颜色直方图:实验对比了不同颜色空间中的颜色直方图对检索效果的影响。这些颜色空间包括Luv空间、Lab空间和HSV空间和它的两个变形(HSV圆柱形和HSV圆锥形空间)。没有进行RGB颜色空间的实验是因为它不适于度量颜色之间的主观相似度。实验结果表明HSV空间和HSV圆柱形空间能够提供最优的检索效果。
颜色矩:和颜色直方图的实验结果相反,对于颜色矩来说采用Luv和Lab颜色空间比用HSV颜色空间的效果更好。同时,使用三个低次矩的平均效果好于只使用两个低次矩(均值和标准方差)的情况。但是,有时候使用第三阶矩可能使特征对图像中的场景变化过于敏感,因此有时反而会降低检索效率。另外,实验表明颜色矩的维数尽管远远低于颜色直方图,而检索效果却很接近。
颜色聚合向量:由于颜色聚合向量是从颜色直方图演变而来,因此不难理解它在HSV颜色空间中的应用效果最优。因为颜色聚合向量包含了空间相关信息,从理论上来说它应该比颜色直方图的检索效果更好。然而,实验结果表明颜色聚合向量只对那些颜色或纹理比较统一的图像有更好的效果,对一般的图像而言没有优势。同时,对于颜色聚合向量和颜色直方图来说,用L1距离比使用L2距离的效果更好。
颜色相关图:实验主要观察了颜色直方图和其他颜色特征相比对检索效果的影响。结果表明,颜色相关图能够提供最佳的检索效果,但它的计算也最为复杂。
3.2.2 纹理特征的比较
这一节中将给出2.2节中描述的各种纹理特征的性能对比。基于Corel图片库的实验表明,这些纹理特征的性能从最好到最差分别是多维自回归纹理特征(MRSAR)、Gabor特征、TWT小波变换、PWT小波变换、改进的Tamura特征、粗糙度直方图、方向性直方图和传统Tamura特征。注意,所谓改进的Tamura特征是指用直方图代替单个数值来表示传统Tamura特征中的粗糙度指标。实验结果证明,这个改进大幅度提高了Tamura纹理特征的效果。另外,所谓粗糙度直方图和方向性直方图都是改进后的Tamura特征的分量。
除了使用Corel图片外,实验中也采用了Brodatz纹理库来测试纹理特征的性能。这个纹理库常常被用以纹理分析和分类算法的测试,因此是用来评价纹理特征很好的一个测试集。目前这个库中有116幅图片,每一幅被等分成16张互不重叠的小图,则总共有1856张小图。来自于同一幅原图的小图被认为是互相相关的,则每张用于检索的小图都有15张相关图像。基于Brodatz的实验结果和前面基本一致,但Gabor特征的性能提高到MRSAR特征的水平。另外,传统Tamura特征的性能也优于粗糙度和方向性直方图的水平,这说明它比较适于描述像Brodatz这类图片纹理比较均匀一致的图像集。
第二部分参考文献
1. A. K. Jain, Fundamentals of Digital Image Processing, Englewood Cliffs, Prentice Hall, 1989.
2. J. R. Smith and S. F. Chang, "VisualSEEk: a fully automated content-based image query system," ACM Multimedia 96, Boston, MA, Nov. 1996.
3. S. Belongie, et al., "Recognition of images in large databases using a learning framework," Technical Report 97-939, U.C. Berkeley CS Division, 1997
4. M. Ioka, "A method of defining the similarity of image on the basis of color information," Technical Report RT-0030, IBM Research, November 1989.
5. M. J. Swain and D. H. Ballard, "Color indexing," International Journal of Computer Vision, Vol. 7, No. 1, pp.11-32, 1991.
6. Y. Gong, H. J. Zhang and T. C. Chua, "An image database system with content capturing and fast image indexing abilities", Proc. IEEE International Conference on Multimedia Computing and Systems, Boston, 14-19 May 1994, pp.121-130.
7. M. Stricker and M. Orengo, "Similarity of color images," SPIE Storage and Retrieval for Image and Video Databases III, vol. 2185, pp.381-392, Feb. 1995.
8. John R. Smith and Shih-Fu Chang. Tools and techniques for color image retrieval. In Proc. of SPIE: Storage and Retrieval for Image and Video Database.vol 2670, 1995.
9. G. Pass and R. Zabih, "Histogram refinement for content-based image retrieval," IEEE Workshop on Applications of Computer Vision, pp. 96-102, 1996.
10. J. Huang, et al., "Image indexing using color correlogram," IEEE Int. Conf. on Computer Vision and Pattern Recognition, pp. 762-768, Puerto Rico, June 1997.
11. John. R. Smith and Shih-Fu Chang. Transform features for texture classification and discrimination in large image databases. In Proc.IEEE Int. Conf. on Image Proc. 1995.
12. John R. Smith and Shih-Fu Chang. Automated binary texture feature sets for image retrieval. In Proc. IEEE Int. Conf. Acoust., Speech, and Signal Proc., May 1996.
13. Robert M. Haralick, K. Shanmugam, and Its'hak Dinstein. Texture features for image classification. IEEE Trans. On Sys, Man, and Cyb, SMC-3(6):610-621, 1973.
14. H. Tamura, S. Mori, and T. Yamawaki, "Texture features corresponding to visual perception," IEEE Trans. On Systems, Man, and Cybernetics, vol. Smc-8, no. 6, June 1978.
15. Niblack, et al., "The QBIC project: querying images by content using color, texture, and shape," Proc. of SPIE, Storage and Retrieval for Image and Video Databases, Vol. 1908, February 1993, San Jose, pp. 173-187.
16. J. Mao and A. K. Jain, "Texture classification and segmentation using multiresolution simultaneous autoregressive models," Pattern Recognition, Vol. 25, No. 2, pp. 173-188, 1992.
17. R. W. Picard, T. Kabir, and F. Liu, "Real-time recognition with the entire Brodatz texture database," Proc. IEEE Int. Conf. on Computer Vision and Pattern Recognition, pp. 638-639, New York, June 1993.
18. B. S. Manjunath and W. Y. Ma, "Texture features for browsing and retrieval of image data," IEEE Trans. on Pattern Analysis and Machine Intelligence, vol. 18, No. 8, pp. 837-842, Aug. 1996.
19. T. Chang and C. C. Jay Kuo, "Texture analysis and classification with tree-structured wavelet transform," IEEE Trans. On Image Processing, vol. 2, no. 4, pp. 429-441, October 1993.
20. A. Laine and J. Fan, "Texture classification by wavelet packet signatures," IEEE Trans. Pattern Analysis and Machine Intelligence, vol. 15, no. 11, pp. 1186-1191, Nov. 1993.
21. W. Y. Ma and B. S. Manjunath, "A comparison of wavelet features for texture annotation," Proc. of IEEE Int. Conf. on Image Processing, vol. II, pp. 256-259, Washington D.C., Oct. 1995.
22. Calvin C. Gotlieb and Herbert E. Kreyszig. Texture descriptors based on co-occurrence matrices. Comput. Vis., Graphics, and Image Proc., 51:70-86, 1990.
23. J. G. Daugman, "Complete discrete 2D Gabor transforms by neural networks for image analysis and compression," IEEE Trans. ASSP, vol. 36, pp. 1169-1179, July 1998.
24. A. C. Bovic, M. Clark, and W. S. Geisler, "Multichannel texture analysis using localized spatial filters," IEEE Trans. Pattern Analysis and Machine Intelligence, vol. 12, pp. 55-73, January 1990.
25. A. K. Jain and F. Farroknia, "Unsupervised texture segmentation using Gabor filters," Pattern Recognition, 24(12), pp. 1167-1186, 1991.
26. M. H. Gross, R. Koch, Li. Lippert, and A. Dreger. Multiscale image texture analysis in wavelet spaces. In Proc. IEEE Int. Conf. on Image Proc., 1994.
27. K. S. Thyagarajan, Tom Nguyen, and Charles Persons. A maximum likelihood approach to texture classification using wavelet transform. In Proc. IEEE Int. Conf. on Image Proc., 1994.
28. M. K. Hu, "Visual pattern recognition by moment invariants," in J. K. Aggarwal, R. O. Duda, and A. Rosenfeld, Computer Methods in Image analysis, IEEE computer Society, Los Angeles, CA, 1977.
29. L. Yang and F. Algregtsen, "Fast computation of invariant geimetric moments: A new method giving correct results," Proc. IEEE Int. Conf. On Image Processing, 1994.
30. Deepak Kapur, Y. N. Lakshman, and Tushar Saxena. Computing invariants using elimination methods. In Proc. IEEE Int. Conf. on Image roc., 1995.
31. David Copper and Zhibin Lei. On representation and invariant recognition of complex objects based on patches and parts. In Spinger Lecture Notes in Computer Science series, 3D Object Representation for Computer Vision. M. Hebert, J. Ponce, T. Boult, A. Gross, Eds., New York,: Springer, 1995, pp. 139-153.
32. Yueting Zhuang, "Intelligent multimedia information analysis and retrieval with applications to visual design", Ph.D thesis, Zhejiang University, 1998. (庄越挺, "智能多媒体信息分析与检索的研究", 博士论文, 浙江大学, 1998.)
33. A. Pentland and R. W. Picard, and S. Sclaroff. Photobook: Comtent-based manipulation of image databases. Int. J. Comput. Vis., 18(3):233-254, 1996.
34. Esther M. Arkin, L. Chew, D. Huttenlocher, K. Kedem, and J. Mitchell. An efficienly computable metric for comparing polygonal shapes. IEEE Trans. Patt. Recog. And Mach. Intell., 13(3), March 1991.
35. Gene C. H. Chuang and C. C. Jay Kuo. Wavelet descriptor of planar curves: Theory and applications. IEEE Trans. Image Proc., 5(1): 56-70, Jan 1996.
36. H. G. Barrow. Parametric correspondence and chamfer matching: Two new techniques for image matching. In Proc. 5th Int. Joint Conf. Artificial Intelligence, 1997.
37. Gunilla Borgefors. Hierarchical chamfer matching: A parametric edge matching algorithm. IEEE Trans. Patt. Recog. And Mach. Intell, 10(6): 849-865, 1988.
38. ACM. Proc. int. conf. on multimedia. 1993-1997.
39. I. Wallace and O. Mitchell. Three-dimensional aircraft recognition algorithm using normalized Fourier descriptors. Comput. Vis., Graphics, and Image Proc., 13:99-126, 1980.
40. I. Wallace and P. Wintz. An efficient three-dimensional shape analysis using local shape descriptors. IEEE Trans. Patt. Recog. And Mach. Intell., PAMI-3(3):310-323, MAY 1981.
41. G. Taubin. Recognition and positioning of rigid objects using algebraic moment invariants. In Proc. SPIE Vol. 1570 Geometric Methods in Computer Vision, 1991.
42. W. Y. Ma and B. S. Manjunath, "Edge flow: a framework of boundary detection and image segmentation," IEEE Int. Conf. on Computer Vision and Pattern Recognition, pp. 744-749, Puerto Rico, June 1997.
43. S.-K. Chang, Q. Y. Shi, and C. Y. Yan, "Iconic indexing by 2-D strings," IEEE Trans. Pattern Anal. Machine Intell., 9(3), pp. 413-428, May 1987.
44. V. N. Gudivada and V. V. Raghavan, "Design and evaluation of algorithms for image retrieval by spatial similarity," ACM Trans. on Information Systems, vol. 13, no. 2, pp. 115-144, April 1995.
45. M. Lybanon, S. Lea, and S. Himes. Segmentation of diverse image types using opening and closing. In Proc. IEEE Int. Conf. on Image Proc. 1994.
46. X. Q. Li, Z. W. Zhao, H. D. Cheng, C. M. Huang, and R. W. Harris. A fuzzy logic approach to image segmentation. In Proc. IEEE Int. Conf. on Image Proc. 1994.
47. Ramin Samadani and Cecilia Han. Computer-assisted extraction of boundaries from images. In Proc. SPIE Storage and Retrieval for Image and Video Databases, 1993.
48. Dirk Daneels, D. Campenhout, Wayne Niblack, Will Equitz, Ron Barber, Erwin Bellon, and Freddy Fierens. Interactive outlining: An improved approach using active contours. In Proc. SPIE Storage and Retrieval for Image and Video Databases, 1993.
49. Yong Rui, Alfred C. She, and Thomas S. Huang. Automated shape segmentation using attraction-based grouping in spatial-color-texture space. In Proc. IEEE Int. Conf. on Image Proc., 1996.
50. D. White and R. Jain. Algorithm and strategies for similarity retrieval. In TR VCL-96-101. University of California, San Diego, 1996.
51. D. White and R. Jain. Similarity indexing: Algorithms and performance. In Proc. SPIE Storage and Retrieval for Image and Video Database, 1996.
52. R. Ng and A. Sedighian. Evaluating multi-dimensional indexing structures for images transformed by principal component analysis. In Proc. SPIE Storage and Retrieval for Image and Video Database, 1996.
53. C. Faloutsos and King-Ip (David) Lin. Fastmap: A fast algorithm for indexing, data-mining and visualization of traditional and multimedia datasets. In Proc. Of SIGMOD, pages 163-179, 1995.
54. S. Chandrasekaran, B. S. Manjunath, Y. F. Wang, J. Winkeler, and H. Zhang. An eigenspace update algorithm for image analysis. Comput. Vis., Graphics, and Image Proc. 1997.
55. G. Salton and M. J. McGill. Introduction to Modern Information Retrieval. McGraw-Hill Book Company, New York, 1982.
56. A. Guttman. R-tree: a dynamic index structure for spatial searching. In Proc. ACM SIGMOD, 1984.
57. D. Greene. An implementation and performance analysis of spatial data access. In Proc. ACM SIGMOD, 1989.
58. T. Sellis, N. Roussopoulos, and C. Faloutsos. The R+ tree: A dynamic index for multi-dimensional objects. In Proc. 12th VLDB, 1987.
59. N. Beckmann, H. P. Kriegel, R. Schenier, and B. Seeger. The R*-tree: an efficient and robust access method for points and rectangles. In Proc. ACM SIGMOD, 1990.
60. Hemant Tagare. Increasing retrieval efficiency by index tree adaption. In Proc. of IEEE Workshop on Content-based Access of Image and Video Libraries, in conjunction with IEEE CVPR '97, 1997.
61. Moses Charikar, Chandra Chekur, Tomas Feder, and Rajeev Motwani. Incremental clustering and dynamic information retrieval. In Proc. of the 29th Annual ACM Symposium on Theory of Computing, pages 626-635, 1997.
62. Yong Rui, Kaushik Chakrabarti, Sharad Mehrotra, Yunxin Zhao, and Thomas S. Huang. Dynamic clustering for optimal retrieval in high dimensional multimedia databases. In TR-MARS-10-97, 1997.
63. HongJiang Zhang and Di Zhong. A scheme for visual feature based image retrieval. In Proc. SPIE Storage and Retrieval for Image and Video Database, 1995.
64. H. J. Zhang and D. Zhong, "A Scheme for visual feature-based image indexing," Proc. of SPIE conf. on Storage and Retrieval for Image and Video Databases III, pp. 36-46, San Jose, Feb. 1995.
65. Santini S, Jain R. Similarity measures. http://www-cse.ucsd.edu/users/ssantini.
66. D. R. Xu. Research on the imagery generation in Design. Ph.D dissertation, Zhejiang University, Hangzhou, 1995.
67. Tversky A. Feature of similarity. Psychological Review, 1977, 84 (4): 327~352.
68. P. Brodatz, "Textures: A photographic album for artists & designers," Dover, NY, 1966.
第三部分 基于内容的视频检索技术
第4章 视频分割
视频分割是自动视频内容分析的首要内容,也是其核心基础技术。视频分割结果的好坏将直接影响到后续分析步骤(如摄像机运动分析、视频内容组织等)的准确性。在开展对视频分割技术研究的过程中,我们建立了一个视频分割系统,它由MPEG视频流索引生成模块、视频帧数据提取和DC图像提取模块、视频特征提取模块以及镜头分割模块组成,如图4-1所示。

图4-1:视频分割系统的结构图
本章的组织如下:首先在第一节介绍了MPEG标准中的关键技术和视频流结构;在第二节中讨论了本系统中所实现的快速DC图像提取算法;第三节、第四节阐述了系统中实现的视频分割算法,并对它们的实验结果进行分析。
4.1 MPEG-2中的关键技术以及视频码流结构
MPEG2中用到的关键压缩编码技术有三个:DCT、帧间预测编码和Huffman编码。DCT大大减小了每帧图像数据的空间冗余度,运动补偿大大减小了图像数据序列的时间冗余度,而Huffman编码则在信息表示方面减小了整体的数据冗余度。这几种技术的综合运用,使MPEG2的适应性更强,压缩率更高。
离散余弦变换(DCT)
在数字图像处理技术中,常见的变换编码有DFT变换、DCT变换以及KL变换。其中,KL变换的数据压缩能力是最优的,但KL变换计算复杂,没有快速算法,特征向量不易求取,实现起来困难。和它相比,DCT变换的在数据压缩性能接近KL 变换,且象DFT变换一样,有快速算法,因此,在MPEG2压缩标准中,选用了DCT变换。下面给出DCT变换的公式:

这里x, y 表示图像空间中的坐标,u, v表示变换域中的坐标
一般的,在MPEG2标准中的每个图像都分割成8×8的块(N=8),对每个这样的块都进行DCT变换。变换后得到64个DCT系数,其左上角的系数为直流系数(DC),它的值为该块的平均值的8倍:

其余63个系数称为交流系数(AC)。然后,对DCT系数进行量化,由于DCT变换后能量都集中在8×8样值块的左上部分,量化后样值块的右下部分有很多零值,采用Zig-Zag扫描方法,使零系数连续的长度比较长,在此基础上作游程编码(Run-Length Coding)将有很高的效率。不可避免的是,对DCT系数量化取整会带来图像精度的降低,但在DCT域中受到影响的主要是高频系数,而人眼对图像中的高频分量并不敏感,因此恢复出的图像仍有很好的效果[34]。在MPEG2码流中,除了Zig-Zag扫描,还引入了交替扫描方式,如图4-2所示。

图4-2 MPEG2中DCT系数的扫描方式
帧间预测编码
帧间预测编码利用参考帧来估计当前帧,为了使预测误差e(y,x,t)尽可能的小,从而达到减小码率的目的采用运动处理的方法进行预测。运动处理有二个过程。第一个过程是对运动物体的位移作出估计,即是要对运动物体从参考帧到当前帧位移的方向和像素作出估计,也就是要求出运动矢量,这过程叫做运动估计 (Motion Estimation)。第二个过程是指按照运动矢量,将参考帧作位移,求出对当前帧的估计,也就是求出f'(y,x,t),这个过程也称为运动补偿(Motion Compensation)。图4-3 给出了运动处理的全过程。
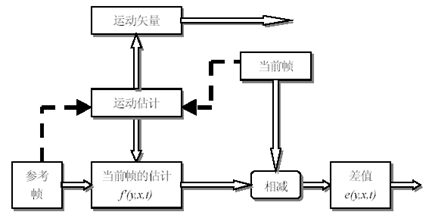
图4-3 运动处理原理图
运动估计的原理: 当前帧和参考帧的匹配搜索产生运动矢量,用这个运动矢量将参考帧位移,求得当前帧的估计f'(y,x,t),这个估计值和当前帧的差值e(y,x,t)经量化后被送到接收机,同时送去的有运动矢量。
在MPEG2标准中采用如图4-4所示的以块为基础的运动估计。先将图像分为M×N小块,运动估计按每块计算,并假定在同一块中的像素具有同样的位移。在接收端用运动补偿误差和运动信息来重建图像。在块匹配算法(BMA)中,假定每帧最大位移为W个像素,那么当前块的像素就应在上一帧的N+2W的窗口内搜索相应的匹配块。

图4-4 以块为基础的运动估计
运动估计的最终目的是要利用其结果做运动补偿,以获得尽可能小的预测误差。在编码器端利用求得的运动矢量(在解码器端是依据收到的运动矢量)将存储器中前一帧的重建图像中相应的块按这个运动矢量作位移,这就是运动补偿的过程。运动补偿性能的好坏与所采取的运动估计方法有关,而且与所处理的图像序列的特点关系也很大。
Huffman编码
Huffman编码属于信息熵编码,信息熵编码源于Shannon 40年代末在贝尔实验室的工作。信息熵编码的思路是用不定长的码字进行编码。码字分配的原则是出现概率大的分配短的码字、出现概率小的分配长的码字。信息熵编码目前已经派生出多种基于统计的编码方法。现在较常用的信息熵编码包括Huffman编码、算术编码、替代编码和游程编码。其中Huffman编码是通用的无失真数据压缩方法。
Huffman编码的特点是特别适用于所有信源符号的出现概率都是1/2的整数次幂的情况。算法如下:
按照出现的概率(频度)排列所有的信源符号
递归的将两个当前最小概率的符号组合在一起形成一个新的复合符号,最终构成一个二叉树;
用从根到叶的二叉树路径的边标号(0/1)表达叶子,得到每一个信源符号的Huffman码,构成编码表;
根据编码表对给定的符号序列进行编码。
二叉树路径的边标号的习惯一般是概率大的边标0,概率小的边标1。
MPEG2视频码流结构
MPEG2采用了分层的体系结构来组织编码数据。最高层为系统层,该层主要包含重要的同步信息、实践信息及其它相关数据。在系统层下是视频层和音频层。MPEG2标准中的视频层数据大致可以分为六层结构,可看作用一定语法结构限定的等级体系,其中各语法结构又包含一个或更多的从属结构,如图4-5所示。

图4-5 MPEG2 视频数据流层次
这六层数据从高到低的顺序依次为图像序列(Sequence)、图像组(GOP)、图像(Picture)、宏块条(Slice)、宏块(Macroblock)、块(Block)。
4.2提取DC图像
由公式(4-3)可知,一个8*8的小块经过DCT变换之后其最左上角的直流系数(DC)为原来块的平均值的8倍,由一帧图像中所有块的DC系数除以8得到的数组成的图像为原来图像缩小8*8倍后产生的图像,这样的图像我们称为DC图像,如图4-6所示。虽然它的精度相比原来的图像已大大降低,但我们仍能看出图像中的大概内容,对这样的DC图像序列进行处理将会大大的降低空间复杂度和时间复杂度。但是为了降低视频数据中的时间冗余度,对原始的图像数据序列进行了帧间预测编码,这样有些图像必须进行反DCT变换和运动补偿才能恢复数据。而我们知道,这两部操作是十分费时的,基于此,Princeton大学的Boon-Lock Yeo和Bede Liu提出了一个提取近似DC图像的快速算法[35]。

图4-6:一帧图像(352*288)和它的DC图像(44*36)(New1)
MPEG码流中有三种编码帧类型,分别为I帧、P帧、B帧。I帧称为内部编码帧(Intra-coded frames, I-frames),它的编码由该帧的图像本身的内容决定;P帧称为前向预测编码帧(Predictively-coded frames, P-frames),它的编码以位于它之前的I帧或P帧为参考帧,仅传送图像中内容变化部分的差值信息,重放时,根据它的参考帧和编码时保留的信息(如:运动矢量、预测误差等数据)重构该编码帧;B帧称为双向预测内插编码帧(Bi-directional predictive frames, B-frames),它是根据该帧前面的I帧或P帧和后面的I帧或P帧来获得运动误差估计的。
从上可以看出I帧的DC图像可以从视频码流中不经反DCT变换和运动补偿得到,但对于P帧和B帧,必须使用运动信息才能得到DC图像,如图4-7所示,
其中Pref为当前块在参考帧中的参考块(它可以不和该帧中的块对齐),从图中可以看出,Pref为块P1、P2、P3、P4中的一部分组成的块,由于DCT变换的线性特性,它的DC系数可表示为: 
其中(DCT(Pi))mn为小块经过DCT变换之后的在(mn)位置上的分量,Si1、 Si2
用于将块Pi在Pref中的部分移到参考块Pref中相应的位置,Si1为如下两种形式的矩阵:

Si2为如下两种形式的矩阵:

具体使用哪种形式由所需执行的位移操作决定。如图4-8所示。

图4-7:参考块(Pref)、运动矢量和当前块

图4-8:移动子块到参考块中的相应位置
如果按公式(4-4)来计算DC系数,需进行256次乘法,这样与完全解码得到DC系数所花费的时间相近,因而,我们采用了一种近似的替代方法[35],如公式(4-5)所示:

这样只要得到参考块所覆盖的四个块的DC系数和当前块的运动矢量就可以得到该块的近似DC系数。
早期的视频分割大多采用的是基于静态图像内容的分割技术,随着MPEG标准的广泛使用,为了降低解码所需要的时间同时利用编码中有用信息(例如运动矢量),产生了直接在压缩域进行视频数据分割的技术。
4.3基于压缩域的视频分割
4.3.1切变检测
大家知道,虽然使用相邻两帧图像的像素差来检测cut的方法计算复杂度较低(比颜色直方图还低),但由于该方法对摄像机运动或物体运动比较敏感,其检测效率并不十分理想,一般更倾向于颜色直方图,它不仅计算简单,而且对运动引起的图像变化不敏感。当我们使用DC图像时,由于DC图像可以看成是全
图的平滑图像,使用相邻两帧DC图像的直方图差来检测cut效果要相对更好一些。相邻两帧DC图像(l、1+l)的直方图差计算如公式(4-6)所示:

在选取阈值进行判断时,由于镜头变换属于时域上的局部行为,使用全局阈值会降低算法的鲁棒性,此处我们使用一个滑动窗口来测试当前帧l左右各帧图像的范围内DC图像直方图差的变化情况,当如下两个条件成立时,我们认为帧和帧之间存在一个cut:

另外,在一些视频中存在着闪光(flash)现象(特别是在新闻节目中大量出现),它表现为光的突然增强,一般持续1-3帧的时间,也满足以上的两个条件。为此,增加第三个判断条件:

4.3.2渐变检测
由于渐变要通过多帧才能完成,一般跨越6-25帧,所以对它的检测自然也要通过考察多帧的特征变化情况得到。它一般分为淡入淡出(fade in & fade out)、溶解(dissolve)和划入划出(wipe in & wipe out)三种主要情况。其中淡入淡出中最显著的特征为出现单色帧且图像内容的淡化,划入划出在图像中的表现也比较突出。对于溶解,由于其在变换的整个过程中无论是从时域上或是从空域上均不能将两段视频片断分开(两个视频片断相互融合在一起),造成了分割的困难,在4.4小节我们将对它的检测方法进行描述。下面先介绍淡入淡出和划入划出的检测算法。
fade检测算法:

其中第四步用于消除闪光现象对检测造成的影响(此时由于光太强可能会引起图像变成单色图像)。
wipe检测算法:
wipe的表现为变换过程中的图像拥有两段视频相应帧中的一部分内容以及一条内容分界线,而且该分界线在图像序列中移动趋势固定。大部分wipe检测算法都是围绕这条内容分界线展开的。由于该分界线的形状(它可以是直线,也可以是曲线)以及它在图像序列中的移动趋势变化多端,很难建立合适的分界线模型来进行检测,我们实现了基于分界线移动趋势的算法:


第五章 视频数据的浏览和检索技术
目前,基于内容的视频数据检索主要分为两个方向,一是着重于恢复视频数据的语义结构信息,称为非线性浏览技术,它使用户能够更有条理地浏览视频节目,如视频点播应用等。另一类是着重于视频数据的特征提取和检索机制,让用户能够快速有效地从大型数据库中找到所关心的片段,如数字视频图书馆等。
5.1 视频非线性浏览












视频非线性浏览是指将线性的视频流按照不同的情节、场景和镜头组织成一个有条理的结构,使用户可以根据自己的需要选择想要浏览的部分。视频非线性系统的主要技术有,视频时间轴切割、关键帧提取和高层语义结构恢复。
图 1. 视频非线性浏览系统
视频数据通常由一系列连续拍摄的镜头剪辑衔接而成,无论是视频非线性浏览还是视频特征的提取,它们所操作的基本对象都是单个镜头剪辑,因此视频数据检索的首要任务是将不同的镜头剪辑互相分开,即视频的时间轴切割。在视频编辑技术中,将不同镜头衔接起来的方式有切变、淡入、淡出、迭化等等,目前的镜头切割算法对于切变检测已经毫无问题,对于渐变检测也取得了较好的效果[1]。
关键帧技术是将视频序列中每个镜头的最有代表性的帧提取出来, 从而对整个视频数据进行压缩。最简单的算法是间隔固定的时间抽取一帧作为代表帧,然而这样有可能遗漏持续时间较短的镜头,[2,3]采用对每一个镜头提出一个关键帧的方法,但一个关键帧无法表示较长镜头的内容,[2]利用视频数据在特征空间上的相关性作为抽取关键帧的依据,当沿时间轴的相关性减小到一定程度时,就提取新的关键帧。其他的技术包括把多帧图像根据背景或者主要对象进行拼接,用以代表更多的视频内容。
视频非线性浏览需要从视频数据中恢复出高层语义信息,通常来说这是比较困难的目前的技术只能在一些特定的领域恢复语义信息,现今研究最多的是电视新闻的结构分析,由于电视新闻的时间和空间结构比较固定,对于结构较为复杂的电影片段,要想恢复情节或故事级的结构,目前的技术还很难实现。
5.2 视频数据的检索
视频数据的检索系统框图如所示,根据检索的方式不同,视频数据检索大致可以分为两类:草图检索和示例检索, 两者都是从基于内容的图像检索方式中扩展过来的。















图 2. 视频数据库检索系统
草图检索时用户通过检索系统提供的工具构成一幅草图, 然后提交给检索引擎找出最匹配的图象, 相对来说, 草图检索比较适合于简单的图象的检索, 对于视频数据, 或者结构比较复杂的图象, 难以用草图表示构成相应的查询清楚. VideoQ中实现了一个基于草图的查询界面,用户可以指定所要查询物体的形状、大小、颜色以及运动轨迹等等。
示例检索是指用户提交一段图像或视频数据,要求找出与该段视频内容相类似的剪辑,由于提交视频的复杂性,处理查询时必须对示例做较多的处理(分割、特征提取等),虽然让提交视频可以使查询的描述能力大大增强,但同时出现用户如何给出初始示例的问题,因此基于示例的检索系统通常与视频浏览系统联系在一起,用户先通过浏览找到比较接近的目标,然后启动检索引擎搜索所有的相似结果。
5.3 运动信息---视频数据的重要内容
视频所包含的数据量远远超过其他媒体, 因此视频数据一直是多媒体处理和检索中最难解决的问题。然而一段视频数据不同于一系列的任意图片沿时间轴简单的堆叠, 组成视频的图象在时间轴上有很强的相关性, 充分利用这种相关性, 可以更好地对视频数据进行压缩或检索, 而另一方面, 视频图象在时间轴上的差异又包含着一种重要的信息, 需要在压缩和检索时加以重视。
针对视频数据中有大量的时间冗余, 可以采用抽取关键帧的方法, 得到关键帧以后, 可以在前面提到的图象的基于内容的检索技术对关键帧进行检索。基于关键帧的方法将视频的检索问题转化为图象的检索问题, 使原先的图象检索的理论和方法可以方便地应用于视频检索中,具有很强的实际意义。然而关键帧技术是用一幅静态的图象来代表一段视频, 它所能表达的信息通常为"是什么"、"有些什么",它无法表示"干什么"这类的动态信息, 如果用户关心的是某一个动作或一个过程, 对于关键帧的检索往往很难满足这种要求, 视频数据中包含了丰富的运动信息, 如何利用视频数据的这些运动信息来为视频检索服务, 是一个值得重要研究的问题。
事实上关键帧和运动信息从两个不同的方面描述了视频数据的内容,而且两者在一定条件下可以互相转化,这一点我们可以来看一个比方:
视频数据灰度数据可以用一个沿着x、y和时间轴的三维函数f(x,y,t)来描述,为了表述的方便我们只看图像中某一点沿时间轴的变化,它可以用f(t)来描述,为了用有限的存储空间来表述这个函数我们可以采用空间采样的方法,用f(t)在一系列时间点上的样点值来近似表示这个函数,其他时间点的值可以通过其临近的样点值的插值来得到,如图3所示,
关键帧提取方法采用的就是这种思想,然而高等数学的泰勒展开法告诉我们一个函数的在某一点附近的值还可以通过这个函数在这一点的多阶导数值来确定,即
















(a)关键帧方法下 f(t) 的表示

(b) 泰勒展开法下f(t)的表示
图 3. 视频数据的两种表示方法
图像序列的运动矢量实际上就可以比作是灰度图像的一阶导数,从这点可以看出采用关键帧方法和采用运动信息的方法具有对于描述视频数据具有类似的效果,为了更好地表示运动信息,可以提取更多的关键帧来实现,然而这样必然造成数据量过大,从另一方面来说,单纯地靠某一时间点的多阶导数也无法恢复在时间轴上距离较远点的信息,因此运动信息还是需要以一定的关键帧作为基础,两者互相结合,可以使对于视频数据的描写更加完善、更加经济。本论文工作所集中的目标就是如何利用视频数据中的运动信息进行基于内容的检索。
5.4 运动信息的提取
基于运动的视频数据检索技术首先需要将运动信息从视频数据中提取出来,从视频序列中提取的运动信息称为光流,它是对物体在3维场景中的运动造成的在2维图像平面上投影的变化的一种估计,光流估计在计算机视觉和视频压缩中有着重要的作用。在所有的从视频序列中计算光流的方法中,基于窗口匹配的相关性技术是最直观且被广泛应用的方法,MPEG视频压缩标准采用的就是这种块匹配方法,Andrea Giachetti在他的《计算图像运动的匹配技术》一文中对多种块匹配技术作了比较,块匹配技术的基本假设是每个块的灰度模式在连续的帧中几乎保持不变,且局部的纹理包含了足以互相区分的信息,这样可以通过在一定大小的窗口中搜索出唯一匹配的灰度块来得到图像序列的光流。基于相关性的光流分析对于噪声的敏感程度要比基于微分的方法小,基于微分的方法在帧间运动比较大时会有重叠问题,通常在图像纹理不相关时,基于块匹配的算法具有较好的效果。块匹配算法的最大的不足是计算的复杂性, 计算一个帧的光流场需要进行N^2次匹配搜索, 如果搜索限定在距离原块为M的范围之内, 总的时间复杂度为N^2*(2M+1)^2, 这样大的计算量即使在高性能的计算机上也要有相当长的时间。 已经提出了许多方法来提高块匹配算法这方面的性能,主要有
- 窗口亚采样
实验表明匹配块的大小在15个像素以上时才能够达到比较好的效果, 然而实验结果同时表明在计算匹配时不需要将块中所有的像素都进行计算, 可以对于匹配块进行亚采样, 只要对所有亚采样点进行相关计算即可, 如果原先匹配块的大小为NxN, 亚采样间隔为s, 则亚采样后的时间复杂度为 。
。
- 快速搜索算法
可以用快速的搜索算法来搜索最大匹配块。Ancona和Poggio在中提出了 一种将2维全搜索变成两个1维搜索的方法, 这种方法同时独立的搜索水平方向和垂直方向的匹配块, 这种算法将复杂度从 降低到
降低到 。除此之外还可以采用变步长逐步求精的方法[25], 如果步长呈2的指数次方减小, 则最终的时间复杂度为
。除此之外还可以采用变步长逐步求精的方法[25], 如果步长呈2的指数次方减小, 则最终的时间复杂度为 。
。
- 采用查找表
由于计算两个块的匹配程度的算法是由一系列差的平方相加而成, 因此可以将中间的所有可能结果做成查找表, 每次重复时就可不必重新计算, 只要查找表中的值即可, 当然这会占用很大的存储空间, 但这样换取了时间上的高效率。
5.5 运动信息的应用
对于非压缩的视频原始数据, 可以通过以上的方法计算出光流图, 对于MPEG压缩的视频数据, 它的运动矢量就是一个光流图,基于运动信息的视频检索就是在这些光流数据上进行处理, 根据运动分析的不同层次, 运动信息可以被应用于以下几个方面:
1. 利用全局运动信息进行视频分类和检索
整个视频序列的光流图直接可以作为一种描述视频的特征。Fernado和Canagarajah在[2]提出了一种利用MPEG视频流中的运动矢量进行视频时域的分割, 包括对于镜头突变和镜头渐变的检测。在镜头突变时, MPEG码流的运动矢量将会呈现相当大的随机性, 通过计算整个帧的运动矢量的均值和方差, 就可以判断出是否存在突变。对于由于镜头运动引起的渐变, 如扫视、聚焦等, 文献[28]计算两个测试量---运动矢量的平均幅度和平均角度来判断, 实验表明全局运动特征在镜头突变检测中与基于颜色直方图的突变检测具有相同的性能, 在渐变检测, 特别是摄像机运动检测方面, 运动特征理所当然具有更好的效果。
Sahouria在[2]利用主元素分析法(PCA)对全局运动矢量进行分析, 主元素分析发可以将运动信息组成的特征空间进行降维, 可以使用较低维的特征矢量来描述视频片段的运动内容, 基于这种方法, 他提出了一种对视频片段进行分类的方法, 首先将全局运动信息投影在一个公共的基空间上, 然后取空间中最主要的两维在时间轴上的变化作为分类的依据, 将不同类的体育比赛片段进行分类, 实验系统对于棒球, 冰球, 排球等片段的获得了较好的区分能力。
全局运动信息的缺点是摄像机运动信息在其中占主导地位, 造成的干扰相当严重,单独作为检索依据的意义不大。
2. 基于运动信息的对象分割
人类的认知通常是通过分类, 合并, 将信息组织成以对象为单位的语义层次的概念, 因此, 为了让检索系统能够更好地与人类的认知过程相吻合, 以基于对象的方式组织视频建索系统, 是最有效的方式。
图象和视频基于对象的分割一直是基于内容的图象分析的首要前提, 在基于内容的视频检索中, 如果检索的特征是相对于不同的对象而不只是整个帧的特征, 那么基于这种特征的检索将更加灵活, 而且可能更加符合用户高层次的抽象要求。在视频数据中的对象分割比图象中更加容易, 因为, 视频数据增加了时间轴的信息, 具有连续运动的区域通常属于同一个对象, 而利用其他的图象特征如颜色和纹理等却没有这种性质, 运动信息被应用于对象分割已经有很长的时间了, 特别是MPEG4基于对象的视频编码的兴起使基于运动信息的分割有了更大的发展[2]。
应用于MPEG-4中的对象操作功能需要将对象分割成对观察者来说有意义的区域, 一些专门针对VOP提取的语义级分割算法最近被提了出来:

图 4. 视频对象的分割[25]
Neri将自动对象分割看作是一个从静态的背景中提取运动物体的问题。在初始化阶段, 可能的前景区域通过对于一组帧间差异的高阶统计测试来得到, 帧间差异可以是由物体运动或高斯噪声产生的, 对于摄像机运动造成的背景运动, 需要事先作出估计和补偿, 对于所有的差异帧, 计算它们的零延迟四阶矩, 由于零延迟四阶矩对于高斯噪声的抑制效果很好, 将这些矩取一定的域值就可以得到一对于运动物体和重现区域的分割图, 为了区别重现区域, 在运动分析阶段, 计算所有被标记为运动区域的点的位移, 位移通过块匹配来计算, 如果像素的位移为零, 则它被看作是重现的背景。最后,利用数学形态学的方法将不连续的区域合并, 去除分割图中对象中的小孔, 最终分割出的前景物体稍微大了一些, 因为整个边界是完全用运动信息来确定的, 没有用到颜色或边缘特征, 在这种方法应用之后, 可以增加一个后处理过程, 利用空间边缘特性来改善边界位置。
Mech和Wollborn提出了一种从估计的变化检测模板生成视频对象面的方法, 开始时, 先通过在两个连续的帧之间取一个全局的域值来生成变化检测模板(Change detection mask CDM), 然后通过用局部的自适应门限来对该CDM进行反复的松弛, 以保证空间的连续性。 通过采用一定的记忆性, 即如果一个像素在前L中属于一个CMD, 则该像素被标记为变化的, 这种方法可以增加时域的稳定性。接下来的简化阶段包括一个形态学的封闭过程, 去除较小的区域以得到最终的CDM, 对象模板是从CDM中去除重现的背景, 并利用灰度边界来改善边界的位置。 这种方法被选为MPEG-4的测试方法的一个部分, 其中增加了镜头检测, 基于8运动参数的全局运动估计和补偿, 而且记忆长度L也是自适应的。
以上两种方法都是基于时域信息的, 而Choi等人提出了一种空间形态学的分割技术。 它开始是也采用全局的运动估计和补偿, 全局精细运动参数从块匹配算法得到的, 实际的分割先对每一帧作形态学的开启, 闭合的简化处理, 形态化后的亮度和色度图象取取域值后作为分水岭算法的输入来检测对象边界的位置, 为了避免过度分割, 小于门限的区域将同它的邻域合并, 最后对每一个区域进行前景/背景判断, 生成视频对象面。 如果一个区域有超过半数的像素被标记在变化检测模板中, 它就被判别为前景。为了保证时域的连续性, 分割的结果必须与前一帧作一致性处理, 那些在前一帧中有大部分像素属于前景的区域也被合并入前景。这样可以做到对象的跟踪, 即使它停止了运动。相比较而言,前两种方法将会在几个静止帧后丢失跟踪目标, 依帧分组的大小和记忆长度而定。
以上三种算法都是从原始视频图象中直接提取运动对象, 对于一些压缩域的视频数据, 其编码本身就带有运动信息, 运动分割可以直接利用这些信息, 这样可以提高检索系统提取运动特征的效率,节省计算时间。 但是, 由于压缩域的运动矢量通常是针对编码而言的, 不能很好地反映实际物体的运动,Khanh Duc Vo等人提出了一种提高运动矢量正确性的MPEG运动矢量估计方法,通过计算运动矢量的可靠性参数, 将宏块分成三类, 正常, 平整, 和边缘, 然后用一个宏块整合阶段将相邻的同类宏块合并成各个区域, 最后分别对各个区域作运动估计, 每个区域使用同样的运动矢量, 这样就避免了没有纹理的区域永远被分配为零运动矢量, 由这种方法改进的MPEG编码器的输出运动矢量更好地反应了视频中不同对象的运动信息, 有利进行基于对象的视频分析。
3. 基于对象的运动信息检索
简单地只使用底层的运动矢量图来检索视频数据, 所得的检索结果难以符合人们的要求, 为了提供更自然的检索结果, 运动信息也必须以面向对象的方式组织。
[A Del Bimbo]采用了一种时间-空间域逻辑式的方法来描述视频对象的各种关系和简单的事件, 然而所有的时-空关系都是用手工标注的,[F Goshani]中定义了一系列代数算子来对视频时空特性建模, 然而这项技术没有考虑到多个对象的相互关系处理。
Columbia大学的开发的VideoQ系统是比较成功的实现了基于运动的内容描述[25],VideoQ实际上是一个完整的基于对象的视频数据检索系统, 它实现的功能有:
- 自动视频对象分割和跟踪
- 基于颜色、纹理、形状、和运动特征的检索
- 多对象联合检索
- 时间和空间受限的检索
- 互联网上的交互查询和浏览
- 压缩域的视频处理

图5. VideoQ系统基于运动的草图查询[25]
在VideoQ系统中, 运动是一种关键的对象属性, 用户可以指定一个对象的运动轨迹, 大致的运动时间, 不同对象的出现顺序和消亡顺序, 物体尺度大小的变化和摄像机运动操作。对于一个长为 N 帧的图象, 视频对象的运动信息被存储在一个N-1维的向量中, 每个向量表示连续帧之间经过全局运动补偿后的平均中心位移, 这些位移信息在加上视频的时间采样率, 就可以知道物体的运动速度和存在时间。 在运动轨迹的匹配上, VideoQ采用两种匹配方法, 一种是空域的匹配算法, 即将运动轨迹投影到二维的平面上, 形成一个有序的轮廓, 然后通过计算轮廓的匹配情况来得到匹配度, 这是一种时间尺度无关的匹配方法, 另一种是时-空域结合的算法, 这种方法直接计算运动轨迹矢量之间的欧氏距离, 保留了对象运动的时间特性。
虽然VideoQ提供了对于物体运动轨迹的检索, 然而它缺少沿时间轴的归一化特性, 而且没有有效的空域检索机制来处理空间的相对位移和尺度不变性, []提出了基于运动的视频检索的模型,对时间不变性和空间位移和尺度不变性作了详细的讨论, 然而, 该系统所提出的方法仍然是基于对象整体的轨迹, 对于旋转和物体的变形运动, 如人的动作, 很难通过运动轨迹来描述, 需要对于运动物体有更进一步的描述。
5.6视频片断分类方法
视频分类就是根据视频表现内容的不同,将它们划分到事先预定义的分类中。它是许多视频应用的基础,比如视频数据库、数字图书馆、视频点播等。最早的视频分类是由人工进行的,由观看者根据他们的主观认识对视频进行描述,然后基于这些描述对视频进行分类,和传统的基于关键字的数据库技术很相似。它与观众的主观认识密切相连,受人为影响大,因而不够精确。为了客观反映视频的视觉内容,人们提出了基于视频内容的分类方法(CBVC, Content-Based VideoClassification)。
为了有效利用视频信息的时间特性,本文拟采用隐马尔可夫模型HMM对各种视频建模,从而来对视频进行分类。
首先,经过镜头分割和关键帧提取,视频表示为关键帧序列。同时提取关键帧的图像特征和运动特征。视频特征表现为关键帧特征序列。
不同类型的视频,应该有不同的特征序列,对各种类型视频分别训练HMM模型。
对一段视频,提取其特征序列,计算其对应各种模型的概率,取最大概率模型分类。
HMM的定义如下:
- 一个隐含的状态集合S={S1,S2,…,SN},在时间t的状态表示为qt∈S。
- 初始状态概率矢量,П={πi},πi=[q1=Si],1≤i≤N
- 状态转移概率矩阵,A={aij}, aij =P[qt=Sj| qt-1=Si], 1≤i,j≤N,
0≤aij≤1,
- 观察值概率,B={bj(Ot)},其中bj(Oi)=P[Ot=vk | qt=Sj],1≤j≤N,
V={v1,v2,…,vM}是观察值集合。
一个HMM可以表示为: λ=(A,B, П)。
HMM应用于视频分类中我们作如下设定:
- 隐含的状态集合S={S1,S2,…,SN},对应典型的关键帧集合。
- 初始状态概率矢量,П={πi},πi用相应状态镜头持续时间来表示。
- 状态转移概率矩阵,A={aij}, aij 表示关键帧的时间关系。
- 观察值概率,B={bj(Ot)},其中bj(Ot)表示当前帧与隐含状态帧的匹配程度。
通过训练得到HMM后,分类问题成为给定HMM模型λ,求在模型λ条件之下,观察值序列O1O2 …Or的概率,P(O1O2 …Or|λ)。可以通过前向算法计算。
第六章总结
多媒体信息由于其友好的表示形式和丰富的内容而一直为人们所关注,随着数字化技术、计算机技术以及网络技术的发展和广泛使用,为基于内容的检索技术的发展提供了舞台并使之具有现实意义。本章将对本文的主要研究内容作一个总结,并论述基于内容的图像检索、视频检索中目前依然存在的问题。
在近几年的发展中,为了解决在基于内容的检索系统中所提取的低层视觉特征和用户理解内容的语义概念之间的差异,从信息检索领域将相关反馈技术引入到基于内容的检索系统中。作为一种十分有效的人机交互手段,相关反馈取得了一定的成功,尤其是在图像检索系统中更是深入展开了对相关反馈技术应用的研究我们发现就目前的计算机视觉发展状况而言,很难对图像所包含的图像信息和用户所需要的图像信息进行准确的描述,需要对图像作一些基于语义表示,常用的方法有自动文本标注和与之相对应的结合视觉特征和语义网络的检索模型[6]。
对于视频来说,由于其信息内容的非结构化特性,需要在进行检索之前对其内容进行结构化处理,其中视频分割是自动视频内容结构化的首要内容,视频分割结果的好坏将直接影响到后续的分析步骤的准确性。同时视频内容具有实时性,相邻图像间的相关性很强,从而整个视频流中的信息有较大的冗余,也需要对内容相似的图像进行聚类,改用一种较为简洁的表示方式来代表该类内容,这一点也常用视频分割——镜头分割的方法将内容相似的一段和其它内容分割开来。在本文的第四章中我们对各种类型镜头变换的检测算法展开讨论,为了降低视频解码所需要的时间同时利用编码中有用信息,我们对基于压缩域的分割技术进行了研究,实现了基于DC图像的cut、fade和wipe类型的检测算法,实验结果表明该检测算法在对cut和fade的检测上取得了令人满意的结果,而且计算复杂度较低,但对wipe的检测还有待改进。
对于基于内容的图像检索,由于很难对图像所包含的信息和用户所需要的图像信息进行准确的描述,有必要对图像作一些基于语义表示,将自动文本标注和加入到系统中来,并建立结合视觉特征和语义网络的检索模型。另外,考虑到用户信息的重要性,深入探讨图像检索系统的接口技术,建立更为有效的人机交互工具。
对于基于内容的视频检索,由于视频中包含的丰富信息,既有高层的语义信息,又有底层的图像帧的视觉信息,还有时间、空间发展的情节信息。所以与图像检索系统相比,视频检索系统在定义和实现上均有很大的难度。目前视频检索系统的主要研究工作集中在视频内容的结构化(如特征提取、视频分割、关键帧提取、视频摘要等)方面,而在检索模型的建立上还存在着一些尚未解决的难点。我们下一步在继续完善视频分割技术的基础上,主要研究视频检索中检索模型如何建立,包括如何对视频的内容进行组织、对视频段内容的描述、视频段内容之间的比较以及如何将相关反馈技术融合到视频检索中来等。
第三部分参考文献
- M.J. Swain, D.H. Ballard, Color Indexing, Int. J. Computer Vision 7 (1) (1991) 11–32.
- J. Hafner, H.S. Sawhney, W. Equitz, M. Flickner, W. Niblack, Efficient color histogram indexing for quadratic form distance func-tion, IEEE Trans. Pattern Analysis and Machine Intelligence 17 (7) (1995) 729–736.
- M. Stricker, M. Orengo, Similarity of color images, Proc. SPIE: Storage and Retrieval for Image and Video Databases III 2420 (February) (1995) 381–392.
- A. Vellaikal, C.-C.J. Kuo, Content-based retrieval of color and multi-spectral images using joint spatial-spectral indexing, Proc. SPIE: Digital Image Storage and Archiving Systems 2606 (October) (1995) 232–243.
- M. Tuceryan, A.K. Jain, Texture analysis, in: C.H. Chen et al. (Eds.), Handbook of Pattern Recognition and Computer Vision, World Scientific, 1993, pp. 235–276.
- R.W. Picard, F. Liu, A new wold ordering for image similarity, Proc. International Conference on Acoustics Speech and Signal Processing V (April) (1994) 129–132.
- M. Flickner, H. Sawhney, W. Niblack, J. Ashley, Q. Huang, B. Dom, M. Gorkani, J. Hafner, D. Lee, D. Petkovic, D. Steele, P. Yanker, Query by image and video content: the QBIC system, IEEE Computer September (1995) 23–32.
- H. Zhang, D. Zhong, A scheme for visual feature based image index-ing, Proc. SPIE: Storage and Retrieval for Image and Video Databases III 2420 (February) (1995) 36–46.
- D. Tegolo, Shape analysis for image retrieval, Proc. SPIE: Storage and Retrieval for Image and Video Databases II 2185 (February) (1994) 59–69.
- J.P. Eakins, K. Shields, J. Boardman, ARTISAN—a shape retrieval system based on boundary family indexing, Proc. SPIE: Storage and Retrieval for Image and Video Databases IV 2670 (February) (1996) 17–28.
- S.-K. Chang, Q.-Y. Shi, C.-W. Yan, Iconic indexing by 2-D strings, IEEE Transactions Pattern Analysis and Machine Intelligence 9 (3 (May)) (1987) 413–428.
- E. Jungert, Extended symbolic projection as a knowledge structure.for image database systems, 4th BPRA Conference on Pattern Recognition, March 1988, pp. 343–351.
- S.K. Chang, C.M. Lee, C.R. Dow, Two dimensional string matching algorithm for conceptual pictorial queries, Proc. SPIE: Image Storage and Retrieval Systems 1662 (February) (1992) 47–58.
- S.-Y. Lee, F.-J. Hsu, Spatial reasoning and similarity retrieval of images using 2-D C-string knowledge representation, Pattern Recognition 25 (3) (1992) 305–318. Storage and Retrieval for Image and Video Databases V 3022 (February) (1997) 380–389.
- Aslandogan YA. Yu CT., Techniques and systems for image and video retrieval, IEEE Transactions on Knowledge & Data Engineering, vol.11, no.1, Jan.-Feb.1999, pp.56-63
- F. Arman, R. Depommier, A. Hsu, and M. Y. Chiu, Content-based browsing of video sequences, ACM Multimedia, Aug. 1994, 77–103.
- S. W. Smoliar and H. J. Zhang, Content-Based Video Indexing and Re-trieval, IEEE Multimedia, Summer 1994, 62–72.
- Yannis S. Avrithis,¤ Anastasios D. Doulamis, Nikolaos D. Doulamis, and Stefanos D. Kollias, A Stochastic Framework for Optimal Key Frame Extraction from MPEG Video Databases, Computer Vision and Image Understanding Vol. 75, Nos. 1/2, July/August, pp. 3–24, 1999
- M. Irani and P. Anandan, Video indexing based on mosaic representation, Proceedings of the IEEE, Vol. 86, No. 5, pp. 805–921, May 1998.
- B. L. Yeo and B. Liu, Rapid scene analysis on compressed videos, IEEE Trans. Circuits Systems Video Technol. 5, 1995, 533–544.
- Y. Ariki and Y.Saito, "Extraction of TV news articles based on scene cut detection using DCT clustering." In IEEE Int. Conf. Image Processing, Lausanne, Switzerland, 1996, pp, 847-850
- A. Hanjalic, R. Lagendijk, and J. Blemond, "Template-based detection of anchorperson shots in news programs." In IEEE Int. Conf. Image Processing, Chicago II, 1998, pp 148-152
- C. Low, Q. Tian, and H. Zhang, "An automatic news video parsing, indexing, and browsing system," in Proc. ACM Multimedia Conf., Boston, MA, 1996
- H. Zhang, Y. Gong, S. Smoliar, and S. Tan, "Automatic parsing of news," in Proc. Int. Conf.Multimedia Computing and Systems, Boston, MA, May 1994
- Shih-Fu Chang, Member, IEEE, William Chen, Horace J. Meng, Hari Sundaram, and Di Zhong, A Fully Automated Content-Based Video SearchEngine Supporting Spatiotemporal Queries, IEEE Transactions on Circuits and Systems for Video Technology, Vol. 8, No. 5, Sept 1998, pp 602-615
- A. Giachetti, Matching techniques to compute image motion, Image and Vision Computing 18 (2000) 247–260
- A. Giachetti, V. Torre, Refinement of optical flow estimation and detection of motion edges, Proc. ECCV'96, Cambridge, UK, April 1996.
- J.L. Barron, D.J. Fleet, S.S. Beauchemin, Performance of optical flow techniques Int, Int. J. Comput. Vision 12 (1) (1994) 43–77.
- W.A.C. Fernando, C.N. Canagarajah, D.R.Bull, Video Segmentation and Classification for Content Based Storage and Retrieval Using Motion Vectors, SPIE 99 pp 687-698.
- Emile Sahouria, Avideh Zakhor, Content Analysis of Video Using Principal Components, IEEE Transactions on Circuits and Systems for Video Technology, Vol 9, No. 8, Dec 1999
- Thomas Meier, King N. Ngan, Automatic Segmentation of Moving Objects for Video Object Plane Generation, IEEE Transactions on Circuits and Systems for Video Technology, VOL. 8, NO. 5, SEPTEMBER 1998
- A. Neri, S. Colonnese, G. Russo, and P. Talone, "Automatic moving object and background separation," Signal Processing, vol. 66, no. 2, pp. 219–232, 1998.
- R. Mech and M. Wollborn, "A noise robust method for segmentation of moving objects in video sequences," in IEEE Int. Conf. Acoust., Speech, Signal Processing, ICASSP'97, Munich, Germany, Apr. 1997, vol. 4, pp. 2657–2660.
- J. G. Choi, M. Kim, M. H. Lee, C. Ahn, S. Colonnese, U. Mascia, G. Russo, P. Talone, R. Mech, and M. Wollborn, "Combined algorithm of ETRI, FUB and UH on core experiment N2 for automatic seg-mentation algorithm of moving objects," in ISO/IEC JTC1/SC29/WG11 MPEG97/m2383, Stockholm, Sweden, July 1997.
- Khanh Duc Vo, Isao NISHIHARA, Toshiyuki YOSHIDA, Yoshinori SAKAI, Precise Estimation of Motion Vectors and its Application to MPEG Video Retrieval, ICIP 99
- T.Yoshida and Y. Sakai, "Reliability Metric of Motion Vectors and its Application to Motion Estimation," Proc. VCIP'95, pp. 799–809, 1995.
- A. Del Bimbo, E. Vicario, and D. Zingoni, "Symbolic description and visual querying of image sequences using spatio-temporal logic," IEEE Trans. Knowl. Data Eng., Vol. 7, pp. 609-622, Aug. 1995
- Y. F. Day, S. Dagtas, M. Iino, A. Khokhar, and A. Ghafoor, "Object-oriented conceptual model of video data," in Proc.11th Int. Conf. Data Engineering, Taipai, Taiwan, R.O.C., Mar. 1995, pp, 401-408
- F. Golshani and N. Dimitrova, "Retrieval and delivery of information in multimedia database systems," Inform. Softw. Technol., vol. 36, pp. 235-242, May 1994.
- Serhan Dagtas, Wasfi Al-Khatib, Arif Ghafoor, Rangasami L.Kashyap, Models for Motion-Based Video Indexing and Retrieval, IEEE Trans. Image Processing, Vol. 9. No.1, Jan 2000
