

Hadoop学习笔记之四:HDFS客户端
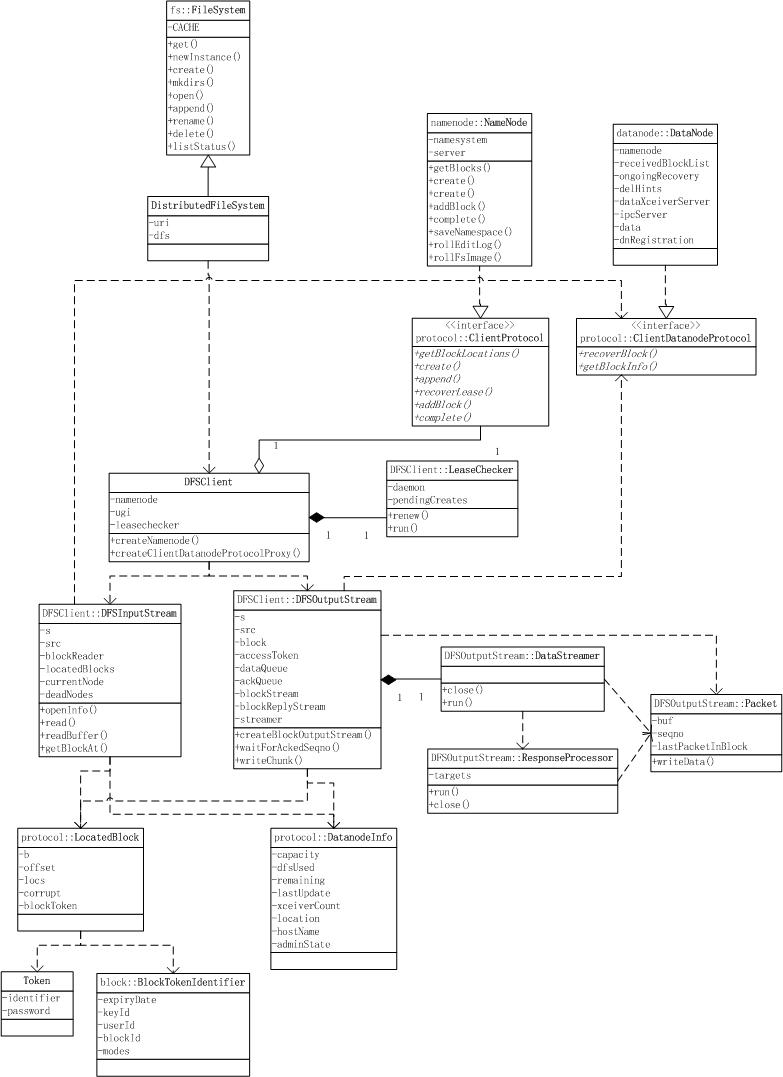
HDFS的客户端核心是DFSClient类,所有使用HDFS的客户端都会持有一个DFSClient对象,或通过持有一个DistributedFileSystem对象间接使用DFSClient;
DFSClient通过ClientProtocol向NameNode进行元数据请求;
当需要进行数据请求时,DFSClient会通过访问的类型(读、写)分别构造DFSInputStream、DFSOutputStream对象;这两个类通过ClientDatanodeProtocol与Datanode进行RPC通信,并通过DatanodeInfo、LocatedBlock对象访问某个Datanode上的某个Block;
写数据前,DFSClient生成相应的Lease信息,添加到LeaseChecker中,由LeaseChecker定期(LEASE_SOFTLIMIT_PERIOD / 2,默认半分钟)进行renew,保证写操作可持续进行;
写数据时,DFSOutputStream通过DataStreamer线程将数据pipeline到指定的多个Datanode上;DataStreamer以Packet为单位进行数据写请求,并通过ResponseProcessor线程处理对Datanode返回的相应Packet的响应;
HDFS写详解
block、packet与chunk
在DFSClient写HDFS的过程中,有三个需要搞清楚的单位:block、packet与chunk;
- block是最大的一个单位,它是最终存储于DataNode上的数据粒度,由dfs.block.size参数决定,默认是64M;注:这个参数由客户端配置决定;
- packet是中等的一个单位,它是数据由DFSClient流向DataNode的粒度,以dfs.write.packet.size参数为参考值,默认是64K;注:这个参数为参考值,是指真正在进行数据传输时,会以它为基准进行调整,调整的原因是一个packet有特定的结构,调整的目标是这个packet的大小刚好包含结构中的所有成员,同时也保证写到DataNode后当前block的大小不超过设定值;
- chunk是最小的一个单位,它是DFSClient到DataNode数据传输中进行数据校验的粒度,由io.bytes.per.checksum参数决定,默认是512B;注:事实上一个chunk还包含4B的校验值,因而chunk写入packet时是516B;数据与检验值的比值为128:1,所以对于一个128M的block会有一个1M的校验文件与之对应;
写过程中的三层buffer
写过程中会以chunk、packet及packet queue三个粒度做三层缓存;
- 首先,当数据流入DFSOutputStream时,DFSOutputStream内会有一个chunk大小的buf,当数据写满这个buf(或遇到强制flush),会计算checksum值,然后填塞进packet;
- 当一个chunk填塞进入packet后,仍然不会立即发送,而是累积到一个packet填满后,将这个packet放入dataqueue队列;
- 进入dataqueue队列的packet会被另一线程按序取出发送到datanode;(注:生产者消费者模型,阻塞生产者的条件是dataqueue与ackqueue之和超过一个block的packet上限)
用图表示如下: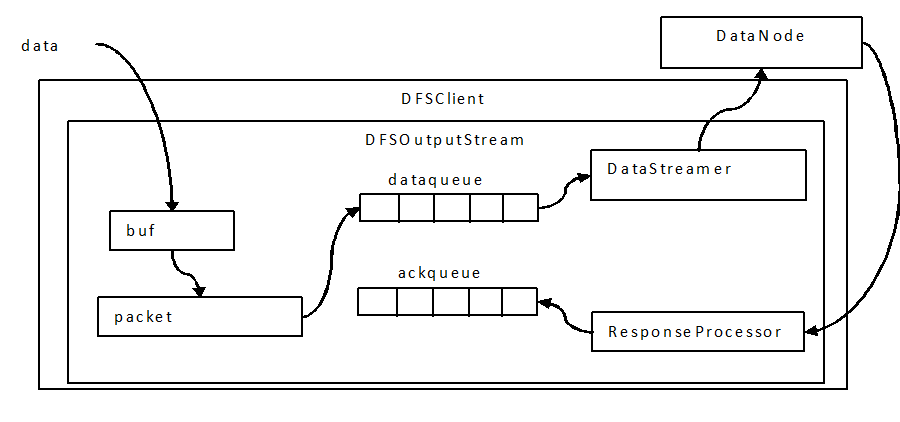
文件的可见性
写一个新文件时,文件元数据在NameNode上以一个临时的INode结构(INodeFileUnderConstruction)存储,这种文件是不可见的,即进行list操作不会被显示。
如果开始写入数据,即产生了block,则这个文件也不能被其它客户端创建。但这是一种临时状态,如果当前创建这个文件的客户端出现异常,该文件迟早会离开不可见状态,该名字空间不会被浪费。
在以下几种情况下,文件会变得可见:
- 文件创建完成,关闭文件;
- 文件写完了一个block;这时虽然文件可见,但数据仅可见已经完成的block;
- 客户端异常关闭,1小时(见Lease(租约)的“租约释放”部分)后该文件可见;或在1分钟后,虽然该文件仍不可见,但可以进行追加数据;此后文件的可见性由新的客户端行为决定;
注:未关闭、已经写入数据但未完成一个block的文件,在原客户端异常关闭后的1分钟内处于不可见不可写状态;
数据可见性与sync
DFSOutputStream提供sync接口,然而其无法做到通常sync需要达到的数据可见性要求,即语义不同,为此,hadoop 0.23以后该接口改名为hflush。
在写数据过程中,上层的写请求数据不断进入三层缓存;如果这时上层请求了一个sync操作,则当前缓存内的所有数据会要求立即向下flush,这个意思是:
- buf中的数据立即完结成一个chunk,填塞到当前正在写的packet中;
- 当前的packet立即进入dataqueue队列,等待被发送;
每个packet都有一个递增的序列号,sync请求会阻塞等待直到ackqueue中包含了该序列号,即该packet得到了应答才会返回;如果当前正在写的block还没有被NameNode记录过(在edits中),则请求返回前还会要求NameNode将该block进行记录。
因为没有要求DataNode做任何的数据刷新操作,因而不保证数据可见;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号