

[Java] Map / HashMap - 源代码学习笔记
Map
1. 用于关联 key 和 value 的对象,其中 key 与 key 之间不能重复。
2. 是一个接口,用来代替 Java 早期版本中的 Dictionary 抽象类。
3. 提供三种不同的视图用于观察内部数据,key 的 Set 视图、value 的 Collection 视图,key-value 关联对象的 Set 视图。
4. 有些实现会保证元素的顺序,例如 TreeMap。有些则不会保证,例如 HashMap
5. 如果 key 是可变对象,需要小心处理
6. key 值指向 Map 自身是不被允许,但是,value 值指向 Map 自身是被运行的。
7. 从 Java 8 开始,对 Map 接口引入了许多 Default 方法。目的是为了支持 Java 8 新引入的函数式编程,同时,又不打破既有的继承 Map 接口的代码。此处不展开讨论。
HashMap
1. 一个基于 hash table 的 Map 接口实现。
2. 允许 null 作为 key 或者 value
3. 不保证元素的顺序
4. 提供常量时间内能完成的操作,包括 get,put 操作
5. 有两个内置参数会影响 HashMap 的性能:initial capacity 和 loadfactor
6. 迭代过程,采用 fail-fast 机制。详情可参看 ArrayList fail-fast 。
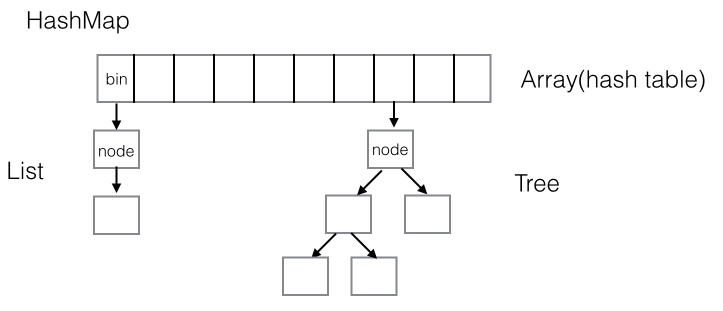
7. 一个 hash 值对于一个箱子( bin )。当多个不同元素的 hash 值相同时,他们归属于同一个箱子。
HashMap 采用树结构来处理大量的 hash 值冲突的情况。树是指红黑树。
8. tableSizeFor(int) 返回一个大于参数的最小 2 的幂次方的值。例如 tableSizeFor(3) 返回 4, tableSizeFor(5) 返回 8。
9. remove(Object) 删除 Object 为 key 的记录,并返回关联的 value 值。如果无法找到需要删除的元素则返回 null 。 注意,返回 null 有两种情况,一种是无法找到元素,另一种是 Object 关联 value 本身就是 null。
10. removeNode(int hash, Object key, Object value, boolean matchValue, boolean movable) 是具体实现删除算法的方法,被 remove(Object) 调用。算法思路如下:
a. 根据 hash 找到对应的箱子
b. 在箱子中找到需要删除的对象。根据箱子内元素的存储结构的不同(列表或者树),采用不同的搜索方式。
c. 找到待删除对象后,根据不同的存储结构,调用采用不同的节点删除策略。
HashMap 的数据结构关系的简单示意图,如下。
11. keySet(),values() 和 entrySet() 分别返回 key, value, entry 的视图。由于仅仅内部数据的一个视图,视图和 HashMap 用的是同一份数据。所以,在视图上对元素进行的修改,同样会反映到 HashMap 中,反之亦然。
12. 基础的迭代器是 HashIterator。其他三个集成器:KeyIterator, ValueIterator, EntryIterator,均继承自 HashIterator 的迭代器。
13. afterNodeAccess, afterNodeInsertion, afterNodeRemoval 是应用于 linkedHashMap 的后期处理,在 HashMap 中不处理。
Jdk 版本: jdk1.8.0_31.jdk

 浙公网安备 33010602011771号
浙公网安备 33010602011771号