



上回我们介绍了两种有穷自动机模型——确定性有穷自动机DFA和非确定性有穷自动机,以及从正则表达式经过NFA最终转化为DFA的算法。有些同学表示还是难以理解NFA到底怎么转化为DFA。所以本篇开头时我想再多举一个例子,看看NFA转化为DFA之后到底是什么样。首先我们看下面的NFA,它是从一组词法分析所用的正则表达式转换而来的。这个NFA合并了IF、ID、NUM、error这四个单词的NFA。因此,它的四个接受状态分别代表遇到了四种不同的单词。

用上一篇学到的方法,我们需要求出一个DFA,它的每个状态都是NFA状态集合的一个子集。首先我们要定义任何状态的ε-闭包,之所以叫ε-闭包,是因为它对ε转换而言是封闭的,也就是说ε-闭包内任何状态,经过ε转换之后,都还是闭包内的一个状态。接下来,从初始状态ε-闭包开始,我们要计算输入任何一种字符后,NFA所能转换到的下一个状态集合。这一步的公式是:

其中那个U型的符号,表示:对NFA状态集合d中的任何状态s,求出s在遇到符号c之后所能达到的所有状态组成的集合,再把所有这种集合求并集。最后,再对这个集合求出ε-闭包。我很难找出一种更简单的描述方式,简而言之就是要计算出NFA状态集合d,在输入符号c之后,所能达到的一切状态的新集合。而这个集合,就会变成DFA的一个状态,这个状态是从d,沿着一条标有c的边达到的。我们首先求出初始状态的ε-闭包作为DFA的初始状态,然后,我们要反复从当前已知的NFA状态集合出发,计算输入任意字符后所能达到的新状态集合,直到不能再找出新的NFA状态集合为止。这一段算法的确是有一点考验思考能力的,所以建议大家画几个简单的NFA,照着上一篇中的公式比划一下,多思考思考,一定可以理解的。下面我贴出上边NFA转换而成的DFA,让大家对NFA转成的DFA有个感性的认识:

大家可以看出,转换而成的DFA每一个状态都是由若干个原NFA状态组成的集合。而任何状态集合,其中只要有一个是NFA的接受状态,我们就将它作为DFA的接受状态。注意,有些状态中可能包含不止一个NFA接受状态。比如上图接受IF的状态是NFA的状态集合{3,6,7,8},其中3号是NFA中接受IF的状态,而8号则是NFA中接受ID的的状态。那么为什么我们选择让DFA状态接受IF而不是ID呢,因为IF是关键字,ID是标识符,我们必须让IF的优先级高于ID,不然就无法在词法分析的时候解析出if关键字。也就是说,在设计词法分析其的时候我们要让所有的保留关键字优先级高于ID,这一点就是在DFA接受状态的选取上体现出来的。
一旦完成了NFA->DFA的转换,DFA状态就没有必要保留原来NFA状态集合的信息了,我们完全可以把DFA进一步抽象为一个表,其中表的一行就是DFA的一个状态,而每一列就是一个字符。这是上一篇我们引入的第一个DFA:
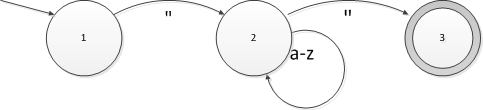
将这个DFA写成状态转换表的形式,就成了这样:
| a | b | c | d | e | f | g | h | i | j | k | l | m | n | o | p | q | r | s | t | u | v | w | x | y | z | " | |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 |
| 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 3 |
| 3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
这个表可能跟大家想象当中有一点点不一样,我们来观察一下:首先这个表比DFA状态图中多一个状态0,而且这个状态上,无论输入什么字符都转到状态0上。我们称这个状态为停机状态。在实践当中,我们一律使用状态0作为停机状态。停机状态的含义就是,一旦状态机到达这个状态就“死”了,它再也不能离开这个状态。等一下我们再看为什么需要这个停机状态,先来看看状态1。在这个状态上,当输入字符是"(引号)的时候,就会转换到状态2,这跟上面的DFA状态图一致;而如果输入字符是a-z之类的,全部都转到状态0,也就是停机状态。这意味着在状态1,接受这些(a-z)字符是未定义的,会导致DFA死掉。接下来是状态2,这个状态应该和大家的预期是一样的,a-z的字符输入,会回到状态2,而输入引号则会转到状态3。最后是状态3,因为状态3没有发出任何边,所以状态3上任何输入字符都会导致停机。最后我们回过头来考虑为什么需要停机状态,因为我们需要它来判断是否检测到了一个单词。用DFA状态转换表进行词法分析的步骤是:
- 一开始,让DFA处于状态1(而不是0,切记!)。
- 输入字符串的一个字符,并且检查表中对应于这个字符的下一个状态。
- 转换到下一个状态。同时,如果这个状态不是0,用另一个变量记住这个状态。
- 不断输入字符串进行状态转换,直到当前状态为0(停机状态)。
- 检查另外一个变量记住的上一个状态,如果上一个状态是接受状态,报报告成功扫描一个单词;如果不是接受状态,报告词法错误。
- 如果要继续解析,需要将DFA的状态恢复到1(而不是0),再重新开始。
也就是说,我们总要等到DFA运行到停机状态,也就是死了之后才判断是否成功扫锚到一个单词,这是因为我们想要词法分析器进行最长匹配。比如我们解析C#代码:string1 = null; 这句代码中的string1是一个标识符,代表一个变量。如果词法扫描器刚刚扫描到string,就报告发现了“关键字string”,那这里逻辑就不对了。而如果等到DFA状态抓换到停机状态时再判断,就能判断到最长可能的的单词。比如,当词法分析器分析到了string时,它仍然没有停机,于是就输入了下一个字符"1",这时词法分析的状态就从接受“关键字string”的状态转换到接受“标识符”的状态;然后词法分析器发现下一个字符是空格,而空格接在string1后面并不是任何合法的单词,所以它就会转到停机状态。最后我们判断停机前最后一个状态是接受“标识符”的状态,于是报告成功扫描标识符string1。这样就实现了最长匹配的目的。
在VBF.Compilers.Scanners库中,我采用的是一个二维数组来存储的DFA状态转换表。其中有一个FiniteAutomationEngine.cs中包含了储存DFA转换表,以及进行状态转换操作的任务。最后Scanner类实现了真正的词法分析逻辑。大家如果对上述语言描述的算法有兴趣,可以直接去看这两个类的实现。
接下来我们要考虑一个非常实际的问题。如果词法分析器要支持Unicode字符集(UTF-16)上字符串的解析,那么DFA转换表会非常大。实际上,如果要支持中文的注释、字符串或者标识符,DFA转换表会有4万列以上,最多可以有65536列。这样只要一个状态就会占掉sizeof(int) x 65536= 256KB的内存。像C#这样的语言,DFA可能会多至几百个状态。即使是我们要做的C#超小子集miniSharp,也有140个状态。这样光DFA状态转换表就要占35MB内存。虽然现在计算机动辄就有8G内存,但是CPU的二级或三级缓存通常只有几MB,如果不能将DFA转换表全部放进二级缓存的话,效率必然大大受到影响。我们观察一下上面列出的DFA状态转换表,会发现从a-z这些字符的列都是完全一样的,它们全都在状态1转到状态0;在状态2转换到状态2;在状态3转到状态0。我们称这样转换表的列完全相同的字符称作同一个等价类。如果我们的DFA状态转换表不用字符作为列,而是使用等价类的话,就能大大缩小状态转换表的体积。然后,我们只要用一个字符->等价类的映射表,就能用O(1)的时间复杂度,将任意字符映射到它的等价类。比如,在应用等价类之后,上面展示的DFA可以变成:
等价类表:
| a | b | c | d | e | f | g | h | i | j | k | l | m | n | o | p | q | r | s | t | u | v | w | x | y | z | " | |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
转换表:
| 0 | 1 | |
| 0 | 0 | 0 |
| 1 | 0 | 2 |
| 2 | 2 | 3 |
| 3 | 0 | 0 |
这样一来,只需要有一个一行的等价类表。而因为最多也就只有65536个等价类(每种字符一个等价类),所以这个等价类表可以声明成ushort[65536],它只会占128K内存。经过压缩之后,miniSharp语言的等价类一共只有57个。所以140个状态只需要不到32KB的内存即可装下,现在它可以完全装载到CPU的二级缓存中了,完美达成目标!
在VBF.Compilers类库中,为了NFA-> DFA算法的高效,甚至在NFA时就计算了等价类表。当然在NFA阶段计算得没有DFA阶段这样精确,所以在转换成DFA之后会再次计算等价类表。这种所谓的双重压缩法,把处理大量Unicode字符集NFA转换所需要的数小时时间减小到了几百毫秒。
接下来,我们就来简单了解一下VBF.Compilers.Scanners库的用法。首先,要写自己的词法分析器,需要引用VBF.Compilers.Common.dll库和
VBF.Compilers.Scanners.dll。其中Common库包含一个储存编译错误的类,和一个重要的类:SourceReader。这个类可以将任何TextReader作为输入,而且还支持在读取的过程中统计当前源代码的行、列。因此词法分析器就依赖于这个类来进行源代码输入。要定义一个词法分析器,需要一个最基础的类——Lexicon类。这个类相当于一个字典,它会保存所有单词的定义,同时在内部进行正则表达式到DFA的转换等工作。下面的代码演示了Lexicon类的用法:
using RE = VBF.Compilers.Scanners.RegularExpression;… Lexicon lexicon = new Lexicon(); LexerState lexer = lexicon.DefaultLexer; Token IF = lexer.DefineToken(RE.Literal("if")); Token ELSE = lexer.DefineToken(RE.Literal("else")); Token ID = lexer.DefineToken(RE.Range('a', 'z').Concat( (RE.Range('a', 'z') | RE.Range('0', '9')).Many())); Token NUM = lexer.DefineToken(RE.Range('0', '9').Many1()); Token WHITESPACE = lexer.DefineToken(RE.Symbol(' ').Many()); ScannerInfo info = lexicon.CreateScannerInfo(); |
我们来逐行解读一下这些代码。首先Lexicon类直接用new就可以创建出来,无需任何参数。接下来是这样代码:
LexerState lexer = lexicon.DefaultLexer;
这行代码调用了lexicon的DefaultLexer属性,返回了一个LexerState对象,它代表一个词法分析器的整体状态。后面我们就要用这个对象来定义单词的正则表达式。默认情况下,DefaultLexer是唯一的LexerState,而且不用创建新的LexerState对象。但是假如我们需要让某些词素在不同环境下展示为不同的类型,就可以定义新的LexerState。比如说“get”这个词素通常应该是一个标识符,而在定义属性的上下文环境下,它就变成了一个关键字。LexerState允许派生子状态来支持这种场景。但目前我们先暂考虑只有DefaultLexer的情况。
在拿到DefaultLexer之后即可使用DefineToken方法定义单词。DefineToken接受一个RegularExpression对象作为参数。RegularExpression类(在代码中简写为RE)的静态方法可以表示正则表达式的基本运算和几种常用的扩展运算。下面的表列出了RegularExpression常见用法:
| RegularExpression类的用法 | 例子 | 表示的正则表达式 |
| | 运算符 Union方法 |
x | y x.Union(y) |
x|y |
| >> 运算符 Concat方法 |
x >> y x.Concat(y) |
xy |
| Many方法 | x.Many() | x* |
| Many1方法 | x.Many1() | x+ |
| Optional方法 | x.Optional() | x? |
| Range静态方法 | RE.Range('0', '9') | [0-9] |
| CharSet静态方法 | RE.CharSet("abc") | [abc] (并运算) |
| Literal静态方法 | RE.Literal("abc") | abc (连接运算) |
| Repeat方法 | x.Repeat(5) | xxxxx |
| CharsOf静态方法 | RE.CharsOf(c => c == 'a') | [a] (根据lambda表达式创建一组字符的并运算集合) |
| Symbol静态方法 | RE.Symbol('a') | a |
大家可以看上面的代码,结合这个表来学习RegularExpression的各种用法。注意,定义Token的先后顺序决定了各个单词的优先级,排在前面的更加优先。为了确保保留关键字的优先级,所有关键字必须在标识符ID之前定义。在所有的单词都定义完毕之后,我们调用Lexicon的CreateScannerInfo方法来得到一个ScannerInfo对象。这个对象就包含了已经转换好的DFA和各种词法分析器运转所需要的参数。下一步,我们就可以用ScannerInfo对象创建出Scanner对象,请看下面的代码:
Scanner scanner = new Scanner(info); string source = "asdf04a 1107 else"; StringReader sr = new StringReader(source); scanner.SetSource(new SourceReader(sr)); scanner.SetSkipTokens(WHITESPACE.Index); Lexeme l1 = scanner.Read(); Console.WriteLine(l1.TokenIndex); //等于ID.Index Console.WriteLine(l1.Value); //等于 asdf04a Lexeme l2 = scanner.Read(); Console.WriteLine(l2.TokenIndex); //等于NUM.Index Console.WriteLine(l2.Value); //等于 1107 Lexeme l3 = scanner.Read(); Console.WriteLine(l3.TokenIndex); //等于ELSE.Index Console.WriteLine(l3.Value); //等于 else Lexeme l4 = scanner.Read(); Console.WriteLine(l4.TokenIndex); //等于info.EndOfStreamTokenIndex Console.WriteLine(l4.Value); //等于 null |
创建Scanner对象时,需要传入上一步生成的ScannerInfo对象,接下来可以指定输入的源代码。这里我们用StringReader来读取一段字符串源代码。注意Scanner的SetSkipTokens方法,可以设定词法扫描器自动跳过的单词。比如我们不希望词法分析器返回空白字符的词素,就设定跳过WHITESPACE单词。在操作Scanner类的时候,所有与Token相关的操作都是通过Token.Index(一个整数)来完成的,因为Scanner内部仅仅保存了Token在Lexicon内部的索引值,这样可以减小内存使用并且提高效率。
一切准备就绪之后就可以调用scanner.Read()方法来进行词法分析了!每次调用scanner.Read()会返回下一个词素(Lexeme对象),从Lexeme的属性中我们可以拿到该词素对应的单词类型(仍然是以Token.Index整数形式),词素的字符串表示(Value属性)以及词素在源代码中位置等丰富的信息。当扫描到文件或字符串尾部时,scanner.Read()会返回一个特殊的词素表示End Of Stream。这个特殊词素的TokenIndex可以从ScannerInfo对象查询到(每个ScannerInfo的EndOfStreamTokenIndex会不一样)。大家可以试着运行一下上述代码,并且修改自己的词法定义或源代码,来观察Scanner类的各种行为。另外VBF.Compilers.Scanner库还提供了两种具有特殊能力的Scanner——分别是PeekableScanner和ForkableScanner,未来的篇章中我们会用到它们的特殊能力。
到本篇为止,我们已经完整地讨论了词法分析所需的各种技术和VBF的实现。下一篇我们将讨论miniSharp语言的词法定义,并真正实现miniSharp的词法分析器。届时大家可以学到怎么创建支持中文的标识符和注释的正则表达式。敬请期待!
此外别忘了关注我的VBF项目:https://github.com/Ninputer/VBF 和我的微博:http://weibo.com/ninputer 多谢大家支持!
 posted on
posted on

 浙公网安备 33010602011771号
浙公网安备 33010602011771号