
机器学习基础——模型参数评估与选择
当看过一些简单的机器学习算法或者模型后,对于具体问题该如何评估不同模型对具体问题的效果选择最优模型呢。
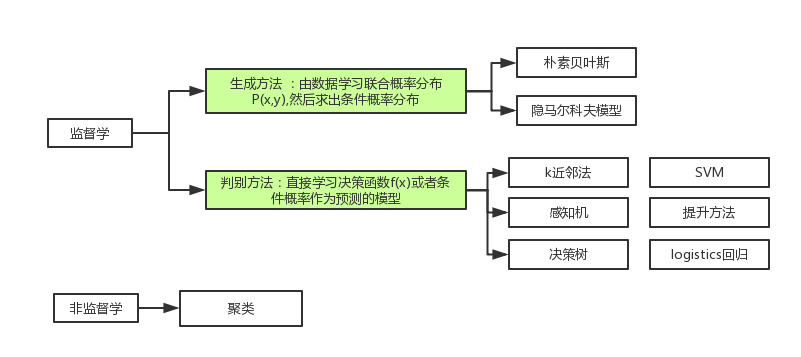
机器学习分类
1. 经验误差、泛化误差
假如m个样本中有a个样本分类错误
错误率:E = a / m;
精度: 1 - E
训练误差: 又叫经验误差,是指算法/模型在训练样本上的误差
泛化误差:算法/模型在新样本上的误差
显然我们希望得到泛化误差小的机器学习算法。
2.欠拟合、 过拟合
欠拟合:欠拟合是指讯息能力低下,本来一些有的特征没有学习到。
解决方法:欠拟合一般比较容易克服,例如在决策树学习中扩展分支在神经网络学习中增加学习轮数就可以。
过拟合:模型把训练样本学的“太好”,很可能把训练样本自身的一些特点当做了所有潜在样本都会具有的一般性质,这样就会导致泛化能力下降。
解决方法: 很难克服或者彻底避免。
下面这张图对欠拟合/过拟合解析的十分到位:

3. 样本采集
3. 1 留出法
直接将数据集D划分成两个互斥的集合,其中一个作为训练集S,另一个作为测试集T 即: D = S ∪ T , S ∩ T = ∅ . 在S上训练出模型后用T来评估其测试误差,作为泛化误差的评估。
需要注意的训练/测试集的划分要尽可能的保持数据分布的一致性,避免因数据划分过程引入额外的偏差而对最终结果产生影响。 如果从采样的角度看数据集划分过程,则保留类别比例的采样方式通常称为分层采样。
单层留出法得到的评估结果往往不够稳定可靠,在使用留出法时,一般采用若干次随机划分、重复进行试验评估后取平均值为留出法结果。
缺点: 若训练集S包含绝大多数样本则训练出的模型可能更接近与用D训练处的模型,但由于T比较小,评估结果可能不够稳定准确。 若令测试机包含多一些样本,则训练集S与D差别更大,被评估的模型与用D训练出的模型相比可能有较大差别,从而降低了评估结果的保真性。 常见的做法是将 2/3 ~ 4/5 的样本用于训练,剩余样本用于测试。
3.2 交叉验证法

3.3 自助法
留出法和交叉验证法都有一个缺点: 需要保留一部分样本用于测试,因此实际评估的模型所使用的训练集比D小,这必然会引入一些因训练样本规模不同而导致的估计偏差。
自助法: 给定包含m个样的数据集D,我们对它进行采样产生数据集D_:每次随机从D中挑选一个样本,将其拷贝到D_中,然后将该样本放回到D中,下次采样时同样可以被采到。
明显D中有一部分样本会多次出现,而另一部分样本不出现。于是估计样本在m次采样中始终不被采到的概率:
![]()
即通过自助采样,初始数据集D中约有0.368的样本没有出现在D_中。 我们可以将D\D_用作测试集,这样实际评估的模型与期望评估的模型都是用m个训练样本。
4 . 性能度量——查准率、查全率
对于二分类问题进行如下统计:

查准率:
P = TP / (TP + FP)
查全率:
R = TP / (TP + FN)
以预测癌症为例,正例为癌症,反例不是癌症。 查准率表示预测为癌症实际发生癌症的概率,而查全率是指预测为癌症的覆盖率(部分预测为反例但实际情况确实正例)。
其它机器学习算法:
监督学习——随机梯度下降算法(sgd)和批梯度下降算法(bgd)
参考:
周志华 《机器学习》
《推荐系统实战》

