

一、python介绍
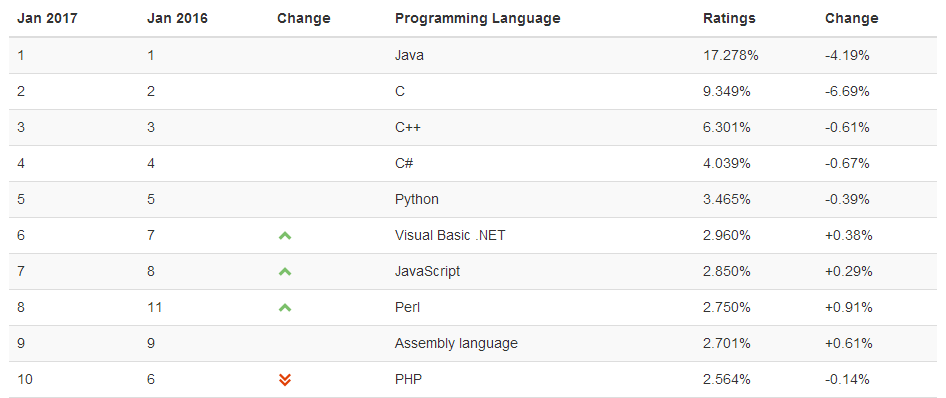
上图中排名前五的语言中,C、C++、C#都是编译型语言,python与java则都是解释型语言,那么什么是编译型语言,什么是解释型语言?
编译型语言:程序在执行之前需要一个专门的编译过程,把程序编译成为机器语言的文件,运行时不需要重新翻译,直接使用编译的结果就行了。
优点是只需要编译一次,运行时不需要编译,所以程序执行效率高,缺点相对就很明显,跨平台性差,要针对不同平台生成不同的执行文件。
解释型语言:程序不需要编译,程序在运行时才翻译成机器语言,每执行一次都要翻译一次。
优点是有良好的平台兼容性,直接修改代码后快速部署就可以直接运行,缺点是由于每次运行都需要编译一次,性能上相对编译型语言自然就会差一些。
二、python的优缺点
python的优点:
1、简单:Python是一种代表简单主义思想的语言。阅读一个良好的Python程序就感觉像是在读英语一样。它使你能够专注于解决问题而不是去搞明白语言本身。
2、易学:Python极其容易上手,因为Python有极其简单的说明文档。
3、速度快:Python 的底层是用 C 语言写的,很多标准库和第三方库也都是用 C 写的,运行速度非常快。
4、免费、开源:Python是FLOSS(自由/开放源码软件)之一。使用者可以自由地发布这个软件的拷贝、阅读它的源代码、对它做改动、把它的一部分用于新的自由软件中。FLOSS是基于一个团体分享知识的概念。
5、高层语言:用Python语言编写程序的时候无需考虑诸如如何管理你的程序使用的内存一类的底层细节。
6、可移植性:由于它的开源本质,Python已经被移植在许多平台上(经过改动使它能够工作在不同平台上)。
7、解释性:一个用编译性语言比如C或C++写的程序可以从源文件(即C或C++语言)转换到一个你的计算机使用的语言(二进制代码,即0和1)。这个过程通过编译器和不同的标记、选项完成。
8、面向对象:Python既支持面向过程的编程也支持面向对象的编程。
9、可扩展性:如果需要一段关键代码运行得更快或者希望某些算法不公开,可以部分程序用C或C++编写,然后在Python程序中使用它们。
10、可嵌入性:可以把Python嵌入C/C++程序,从而向程序用户提供脚本功能。
11、规范的代码:Python采用强制缩进的方式使得代码具有较好可读性。而Python语言写的程序不需要编译成二进制代码。
python的缺点:
1、单行语句和命令行输出问题:很多时候不能将程序连写成一行,如import sys;for i in sys.path:print i。而perl和awk就无此限制,可以较为方便的在shell下完成简单程序,不需要如Python一样,必须将程序写入一个.py文件。
2、运行速度慢:这里是指与C和C++相比。
3、代码无法加密。
三、python2.7 or python3.x
其实对于python的版本选择,由于以前工作的时候做的工作都是和python2.7打交道所以一直使用的是python2.7;选择3.x的原因主要有几点,首先2.7版本于2020年将停止更新服务,再者3.x的兼容性、编码等原因。
四、安装python
windows下安装python
下载安装包:
https://www.python.org/downloads/
安装:
默认安装路径:
C:\PYTHON35
配置环境变量:
1. 右键计算机;
2. 属性;
3. 高级系统设置;
4. 高级;
5. 环境变量;
6. 在第二个框中找到Path双击;
7. 将python安装目录追加到值中,用;分隔。
五、Hello World!
新建一个hello.py 文件,并输入:
print("Hello World")
在命令行中执行命令:
python hello.py
即可看到系统返回:
E:\>python hello.py
Hello World!
六、变量
1、变量的作用:
变量是只不过保留的内存位置用来存储值。这意味着,当创建一个变量,那么它在内存中保留一些空间。
根据一个变量的数据类型,解释器分配内存,并决定如何可以被存储在所保留的内存中。因此,通过分配不同的数据类型的变量,你可以存储整数,小数或字符在这些变量中。
2、变量赋值:
Python的变量不必显式地声明保留的存储器空间。当分配一个值给一个变量的声明将自动发生。等号(=)来赋值给变量。
操作数=操作符的左边是变量,操作数=操作符的右侧的名称在变量中存储的值。例如:
counter = 100 miles = 1000.0 name = "John"
3、命名规则:
变量名只能是字母、数字或者下划线的任意组合,并且首字母不能是数字,同时也不可以使用以下关键字声明变量:
['and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'exec', 'finally', 'for', 'from', 'global', 'if', 'import','in', 'is', 'lambda', 'not', 'or', 'pass', 'print', 'raise', 'return', 'try', 'while', 'with', 'yield']
七、编码格式
1. ASCII
ASCII(American Standard Code for Information Interchange),是一种单字节的编码。计算机世界里一开始只有英文,而单字节可以表示256个不同的字符,可以表示所有的英文字符和许多的控制 符号。不过ASCII只用到了其中的一半(\x80以下),这也是MBCS得以实现的基础。
2. MBCS
然而计算机世界里很快就有了其他语言,单字节的ASCII已无法满足需求。后来每个语言就制定了一套自己的编码,由于单字节能表示的字符太少,而且同时也需要与ASCII编码保持兼容,所以这些编码纷纷使用了多字节来表示字符,如GBxxx、BIGxxx等等,他们的规则是,如果第一个字节是\x80以下,则仍然表示ASCII字符;而如果是\x80以上,则跟下一个字节一起(共两个字节)表示一个字符,然后跳过下一个字节,继续往下判断。
这里,IBM发明了一个叫Code Page的概念,将这些编码都收入囊中并分配页码,GBK是第936页,也就是CP936。所以,也可以使用CP936表示GBK。
MBCS(Multi-Byte Character Set)是这些编码的统称。目前为止大家都是用了双字节,所以有时候也叫做DBCS(Double-Byte Character Set)。必须明确的是,MBCS并不是某一种特定的编码,Windows里根据你设定的区域不同,MBCS指代不同的编码,而Linux里无法使用 MBCS作为编码。在Windows中你看不到MBCS这几个字符,因为微软为了更加洋气,使用了ANSI来吓唬人,记事本的另存为对话框里编码ANSI就是MBCS。同时,在简体中文Windows默认的区域设定里,指代GBK。
3. Unicode
后来,有人开始觉得太多编码导致世界变得过于复杂了,让人脑袋疼,于是大家坐在一起拍脑袋想出来一个方法:所有语言的字符都用同一种字符集来表示,这就是Unicode。
最初的Unicode标准UCS-2使用两个字节表示一个字符,所以你常常可以听到Unicode使用两个字节表示一个字符的说法。但过了不久有人觉得256*256太少了,还是不够用,于是出现了UCS-4标准,它使用4个字节表示一个字符,不过我们用的最多的仍然是UCS-2。
UCS(Unicode Character Set)还仅仅是字符对应码位的一张表而已,比如"汉"这个字的码位是6C49。字符具体如何传输和储存则是由UTF(UCS Transformation Format)来负责。
一开始这事很简单,直接使用UCS的码位来保存,这就是UTF-16,比如,"汉"直接使用\x6C\x49保存(UTF-16-BE),或是倒过来使用\x49\x6C保存(UTF-16-LE)。但用着用着美国人觉得自己吃了大亏,以前英文字母只需要一个字节就能保存了,现在大锅饭一吃变成了两个字节,空间消耗大了一倍……于是UTF-8横空出世。
UTF-8是一种很别扭的编码,具体表现在他是变长的,并且兼容ASCII,ASCII字符使用1字节表示。然而这里省了的必定是从别的地方抠出来 的,你肯定也听说过UTF-8里中文字符使用3个字节来保存吧?4个字节保存的字符更是在泪奔……(具体UCS-2是怎么变成UTF-8的请自行搜索)
另外值得一提的是BOM(Byte Order Mark)。我们在储存文件时,文件使用的编码并没有保存,打开时则需要我们记住原先保存时使用的编码并使用这个编码打开,这样一来就产生了许多麻烦。 (你可能想说记事本打开文件时并没有让选编码?不妨先打开记事本再使用文件 -> 打开看看)而UTF则引入了BOM来表示自身编码,如果一开始读入的几个字节是其中之一,则代表接下来要读取的文字使用的编码是相应的编码:
BOM_UTF8 '\xef\xbb\xbf' BOM_UTF16_LE '\xff\xfe' BOM_UTF16_BE '\xfe\xff'
并不是所有的编辑器都会写入BOM,但即使没有BOM,Unicode还是可以读取的,只是像MBCS的编码一样,需要另行指定具体的编码,否则解码将会失败。
八、数据类型:
1、数字
int(整型):
在32位机器上,整数的位数为32位,取值的范围为-2**31 ~2**31-1,即-2147483648~2147483648
在64位机器上,整数的位数为64位,取值的范围为-2**63~2**63-1,即-9223372036854775808~9223372036854775807
long(长整型):
和C语言不通,python的长整数没有指定位宽,即:Python没有限制长整数数值的大小,但实际上由于机器内存有限,我们使用的长整数数值不可能无限大。
在Python2.2开始,如果整数发生溢出,Python会自动将整数数据转换为长整数,所以如今在长整数数字后面不加字母L也不会导致严重后果。
float(浮点型):
浮点数用于处理实数,也就是带有小数的数字,占用8个字节(64位),其中52位表示低,11位表示指数,剩下的一位表示符号。
complex(复数):
复数是由实数部分和虚数部分组成,一般形式为x+yj,其中x是复数的实数部分,y是复数的虚数部分,这里的x和y都是实数。
2、布尔值
真或假 True False
3、字符串
Python中最常用的数据类型,可以使用引号('或“)来创建字符串。
var1 = 'Hello World' var2 = "Python"
下面介绍一下字符串常用的几个功能:
(1)移除空白
strip()方法可以移除字符串中头尾指定的字符,当括号中为空的时候默认为空格,如下所示:
>>> s = ' abc'
>>> s.strip()
'abc'
也可以在括号中指定一个值,如下所示:
>>> str = "0000000this is string example....wow!!!0000000";
>>> str.strip('0')
'this is string example....wow!!!'
(2)分割
split()方法通过制定分隔符,对字符串进行切片,如果参数num有置顶值,则只分隔num个字符串
split()的语法:
str.split(str="", num=string.count(str)).
实例:
>>> str = "Line1-abcdef \nLine2-abc \nLine4-abcd"
>>>
>>> str.split()
['Line1-abcdef', 'Line2-abc', 'Line4-abcd']
>>>
>>> str.split(' ',1)
['Line1-abcdef', '\nLine2-abc \nLine4-abcd']
(3)长度
len()可以输出字符串的长度
>>> str = "Line1-abcdef \nLine2-abc \nLine4-abcd"
>>> len(str)
35
(4)索引
索引获取特定偏移的元素:
字符串中第一个元素的偏移为0,字符串中最后一个元素的偏移为-1,str[0]获取第一个元素,str[-2]获取倒数第二个元素。
>>> str='abcd' >>> str[0] 'a'
>>> str[-1]
'd'
>>> str[-2]
'c'
(5)切片
通常上边界不包括在提取字符串内,如果没有指定值,则分片的边界默认为0和序列的长度
str[1:3]获取从偏移为1的字符一直到偏移为3的字符串,不包括偏移为3的字符串 “tr”
str[1:] 获取从偏移为1的字符一直到字符串的最后一个字符(包括最后一个字符) “tring”
str[:3] 获取从偏移为0的字符一直到偏移为3的字符串,不包括偏移为3的字符串 “str”
str[:-1] 获取从偏移为0的字符一直到最后一个字符(不包括最后一个字符串) “strin”
str[:] 获取字符串从开始到结尾的所有元素 “string”
str[-3:-1] 获取偏移为-3到偏移为-1的字符,不包括偏移为-1的字符 “in”
str[-1:-3]和str[2:0] 获取的为空字符,系统不提示错误 “”
分片的时候还可以增加一个步长,str[::2] 输出的结果为 “srn”
(6)格式化输出
1. 打印字符串
>>> print ("His name is %s"%("Aviad"))
His name is Aviad
2.打印整数
>>> print ("He is %d years old"%(25))
He is 25 years old
3.打印浮点数
>>> print ("His height is %f m"%(1.83))
His height is 1.830000 m
4.打印浮点数(指定保留小数点位数)
>>> print ("His height is %.2f m"%(1.83))
His height is 1.83 m
5.指定占位符宽度
>>> print ("Name:%10s Age:%8d Height:%8.2f"%("Aviad",25,1.83))
Name: Aviad Age: 25 Height: 1.83
6.指定占位符宽度(左对齐)
>>> print ("Name:%-10s Age:%-8d Height:%-8.2f"%("Aviad",25,1.83))
Name:Aviad Age:25 Height:1.83
7.指定占位符(只能用0当占位符?)
>>> print ("Name:%-10s Age:%08d Height:%08.2f"%("Aviad",25,1.83))
Name:Aviad Age:00000025 Height:00001.83
8.科学计数法
>>> format(0.0015,'.2e') '1.50e-03'
