
The implementation of Lua 5.0 阅读笔记(二)
6 线程和协程
读完这篇文章我才意识到python的协程到底缺了什么,这个就是coroutine和semi-coroutine的区别了。区别就是,semi-coroutine只能返回(yield)到调用者所在位置,不能将控制权交到任意其他协程上去。具有这个特征的,都是semi-coroutine。
Lua实现协程的时候,充分利用了其C栈和Lua栈。进行协程调用的时候,解释器会在C栈上会进行一次递归调用,然后协程自身的栈在新建立的Lua栈里消长。当一个协程结束的时候,解释器会退出,返回调用者(即上一个解释器)。注意,这里是一个协程对应C栈上的一帧。与之相反,参考经典的CPython实现,每一次python的函数调用都会产生一层新的C栈,因此,python的函数调用受C堆栈大小的限制。Stackless Python之所以声名大噪,就是因为解决了这个问题,只有tasklet才会在C栈上产生新的栈帧。
作者还提到,这里实现协程的时候,比较棘手的地方是嵌套调用时如何处理外部的局部变量,因为存在协程时,很可能会出现一个函数引用的局部变量存在于另一个协程栈中。而这个问题,因为Lua的upvalue而被完美解决了。
7 Lua的虚拟机
Lua5.0之前的版本,使用的都是基于栈的虚拟机,直到5.0才转为基于寄存器的虚拟机,Lua是第一门大规模使用寄存器虚拟机的工业级语言。
不过要注意的是,不是说基于寄存器的虚拟机就不需要使用栈,Lua5依然有使用栈。栈上会分配栈帧用来存放寄存器,局部变量也都在寄存器中。基于寄存器的意思是,对于Lua函数的参数传递,不再需要繁琐的入栈和出栈操作了。作者顺带讨论了一下寄存器虚拟机的两个性能问题,包括生成的虚拟机代码大小以及指令解码的开销。和Java的jvm做了对比,结果是难分伯仲之间,寄存器机器会稍胜一筹。
Lua的一条指令是32位,指令的布局可以参考下图:
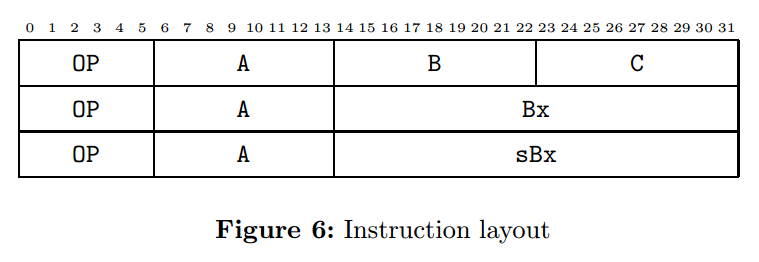
指令是三地址码的格式,A是存放结果的寄存器,B和C就是操作数。由于指令长度的限制,如果想在一个指令里完成一个跳转语句,跳转的范围就会受到限制。因此,Lua将条件语句变成一个test语句和紧接着的jump语句来解决(跟汇编很像^_^)。
这节里还提到寄存器窗口,不过没看懂。维基了一下,寄存器窗口是指实际寄存器数目会比可用寄存器数目要多,不同的函数调用,他们看到的同名寄存器可以是不同的寄存器。比如func1使用了AX和BX,func2也同样使用AX和BX,不过实际上寄存器有4个,func1递归调用func2的时候,func2使用的AX和BX是func1以外的两个。
posted on 2013-07-17 18:14 lifehacker 阅读(833) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号