原生爬虫(爬取熊猫直播人气主播排名)
此代码未采用任何反爬虫策略
'''' This is a module ''' import re from urllib import request # 断点调试 class Spider(): ''' This is a class ''' # 私有方法 # 匹配所有字符 [\s\S]*? 非贪婪 url='https://www.panda.tv/all?pdt=1.27.psbar-menu.0.1oj9bbkfjbh' root_pattern = '<div class="video-info">([\w\W]*?)</div>' name_pattern = '</i>([\w\W]*?)</span>' number_pattern = '<span class="video-number">([\w\W]*?)</span>' def __fetch_content(self): # This is a HTTP request r = request.urlopen(Spider.url) # 字节码 htmls = r.read() htmls = str(htmls,encoding='utf-8') return htmls def __analysis(self, htmls): root_html = re.findall(Spider.root_pattern, htmls) anchors = [] for html in root_html: name = re.findall(Spider.name_pattern, html) number = re.findall(Spider.number_pattern, html) anchor = {'name':name,'number':number} anchors.append(anchor) # print(root_html[0]) # print(anchors[0]) # print(anchors) return anchors def __refine(self, anchors): # 匿名函数lambda l = lambda anchor: {'name':anchor['name'][0].strip(),'number':anchor['number'][0]} # r = map(l, anchors) # print(r) return map(l,anchors) def __sort(self, anchors): # 默认增序 anchors = sorted(anchors, key = self.__sort_seed, reverse=True) return anchors def __sort_seed(self, anchor): r = re.findall('\d*', anchor['number']) number = float(r[0]) if '万' in anchor['number']: number *= 10000 return number def __show(self, anchors): for rank in range(0, len(anchors)): print('rank'+str(rank+1)+':'+anchors[rank]['name']+' '+anchors[rank]['number']) def go(self): htmls = self.__fetch_content() # self.__analysis(htmls) anchors = self.__analysis(htmls) # anchors = self.__refine(anchors) anchors = list(self.__refine(anchors)) # print(anchors) # anchors = list(self.__refine(anchors)) anchors = self.__sort(anchors) self.__show(anchors) # print(anchors) spider = Spider() spider.go()
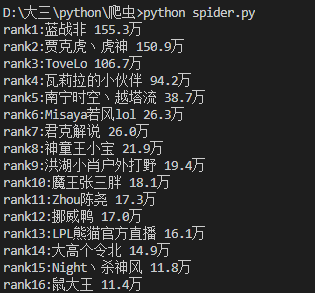
运行该.py文件,终端显示部分结果如下: