
第1次作业
要求0:作业要求地址【https://edu.cnblogs.com/campus/nenu/2016CS/homework/2110】
要求1:git仓库地址【https://git.coding.net/Jingr98/wf.git】
要求2:
1.PSP阶段表格
|
SP2.1 |
任务内容 |
计划共完成需要的时间(min) |
实际完成需要的时间(min) |
|
Planning |
计划 |
40 |
50 |
|
Estimate |
估计这个任务需要多少时间,并规划大致工作步骤 |
40 |
50 |
|
Development |
开发 |
810 |
1030 |
|
Analysis |
需求分析 (包括学习新技术) |
90 |
130 |
|
Design Spec |
生成设计文档 |
40 |
40 |
|
Design Review |
设计复审 (和同事审核设计文档) |
0 |
0 |
|
Coding Standard |
代码规范 (为目前的开发制定合适的规范) |
0 |
40 |
|
Design |
具体设计 |
90 |
90 |
|
Coding |
具体编码 |
480 |
600 |
|
Code Review |
代码复审 |
40 |
50 |
|
Test |
测试(自我测试,修改代码,提交修改) |
70 |
80 |
|
Reporting |
报告 |
180 |
210 |
|
Test Report |
测试报告 |
100 |
120 |
|
Size Measurement |
计算工作量 |
40 |
40 |
|
Postmortem & Process Improvement Plan |
事后总结, 提出过程改进计划 |
40 |
50 |
|
功能模块 |
具体阶段 |
预计时间(min) |
实际时间(min) |
|
功能1 |
具体设计 具体编码 测试完善 |
20 130 20 |
30 200 25 |
|
功能2 |
具体设计 具体编码 测试完善 |
30 140 20 |
15 150 25 |
|
功能3 |
具体设计 具体编码 测试完善 |
40 210 30
|
45 250 30 |
2.分析预估耗时和实际耗时的差距原因:
(1)在分析预估耗时时,没有过多考虑编程中的细节问题。编程过程中不断有新的问题出现。
(2)对Java语言掌握不够熟练,编程中学习的时间较长
(3)最主要的原因就是一开始审题不清,没有考虑到输出样例格式的问题。导致项目将要完工时又要整改很多地方,浪费了好多时间。
要求3:
1.解题思路描述
(1)看到题目后,我想了一下这个程序大致有三个步骤:读取文本、统计单词、(排序)输出。有了这个框架后,我从最简单的功能1尝试编写,在获取到文本内容需要对字符串进行分割时我遇到了一些问题(因为不是很熟悉正则表达式),所以查阅了相关教程,自己尝试写了一下可以达到预期效果,但是需要两次正则表达式的运用(一是对字符串按空格和非字母数字符号进行分割得到字符串数组,二是对得到的字符串数组通过字母开头规则过滤掉那些非法单词),自我感觉这里编写的不是太好。实现了功能1后我开始看功能2,发现只要得到文件夹下的文件名数组,排序后返回指定文件路径后就可以参照功能1的实现。功能3的话只要在前者的基础上传入参数-n,对list进行排序后根据-n输出结果。
(2)最初编写时我是把功能1和功能2写在了一起,即用一个count()函数实现两个功能。功能1直接调用count()就可以实现词频统计,功能2则需要先调用readDir()和setpath()方法得到指定文件路径,然后再调用count()就可以了。功能3则是用count( int n )实现。但是后来我仔细看了题目后发现,两者的输出样例是不一样的!发现了这个问题后,我本来想写两个输出结果的方法分别对应上述两种情况,但是尝试了一下报了很多错误,就不敢大改了,只能选择把两种情况完全分开处理,于是就有了现在的 countFile()和countDir()分别对应功能1和功能2,countNum()对应功能3。这样虽然解决了样例输出的问题,但是代码重复量真的很大。
2.代码介绍
(1)困难点:功能1主要是对字符串的处理(正则表达式的运用),如何得到合法单词;功能2主要是获取某文件夹下的所有文件名,并按照文件名排序后返回指定文件,其余就参照功能1的实现;功能3主要是对词频进行排序,并按照参数进行输出。其实我感觉这三个功能分开来写不是很难,对我来说,最困难的就是如何减少代码的重复。三个功能明显有重复的部分,应该把哪些部分拎出来写成公共的方法,是我应该继续思考的!
(2)代码片段
简单介绍一下我的代码,总体上用Java写了两个类:wf类(包含各种功能方法)和wfTest类(分情况对wf类里的方法进行调用,用来测试)。
1) isLegal()函数:判断是否为合法单词
1 public boolean isLegal(String word) {
2 String regex="^[a-zA-Z][a-zA-Z0-9]*$";
3 Pattern p = Pattern.compile(regex);
4 Matcher m =p.matcher(word);
5 if(m.matches()) {
6 return true;
7 }else {
8 return false;
9 }
10 }
2) readDir()函数:获取文件夹下所有文件的文件名,对数组进行排序并返回第一个元素
1 public String readDir(String filepath){
2 File file = new File(filepath);
3 String[] filelist = file.list();
4 String[] namelist = new String [filelist.length];
5 for(int i=0;i<filelist.length;i++) {
6 File readfile = new File(filepath+"\\"+filelist[i]);
7 namelist[i]=readfile.getName();
8 }
9 List<String> list = (List<String>)Arrays.asList(namelist);
10 Collections.sort(list);
11 String[] paths = list.toArray(new String[0]);
12
13 return paths[0];
14 }
3) countFile()函数:当输入格式为【wf -c 文件名 】时调用,并输出结果
1 public void countFile() {
2 try {
3 FileInputStream inputStream = new FileInputStream(new File(path));
4 BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(inputStream));
5 //将文件内容存入words中
6 while((lineword=bufferedReader.readLine())!=null) {
7 words+=lineword+"\n";
8 }
9 //全部转换成小写,达到不区分大小写的目的
10 String str=words.toString().toLowerCase();
11 //分割字符串并存入数组
12 String[] word = str.split("[^a-zA-Z0-9]|\\ ");
13 int num =0;
14 Map<String,Integer> myMap = new TreeMap<String,Integer>();
15 //遍历数组将其存入Map<String,Integer>中
16 for(int i=0;i<word.length;i++) {
17 //首先判断是否为合法单词,合法则存入map中
18 if(isLegal(word[i])) {
19 if(myMap.containsKey(word[i])) {
20 num = myMap.get(word[i]);
21 myMap.put(word[i], num+1);
22 }
23 else {
24 myMap.put(word[i], 1);
25 }
26 }
27 }
28 //将map.entrySet()转换成list
29 List<Map.Entry<String, Integer>> list =new ArrayList<Map.Entry<String,Integer>>(myMap.entrySet());
30 //输出结果
31 System.out.println("total"+" "+list.size()+"\n");
32 // for(int i=0;i<list.size();i++) {
33 // Map.Entry<String, Integer> e =list.get(i);
34 // System.out.println(e.getKey()+" "+e.getValue());
35 // }
36 for(int i=0;i<word.length;i++) {
37 if(myMap.containsKey(word[i])) {
38 System.out.printf("%-14s%d\n",word[i],myMap.get(word[i]));
39 myMap.remove(word[i]);
40 }
41 }
42 bufferedReader.close();
43 }catch(FileNotFoundException e) {
44 e.printStackTrace();
45 }catch(IOException e) {
46 e.printStackTrace();
47 }
48 }
4) countDir()函数:当输入格式为【wf -f 文件路径 】时调用,并输出结果。(和countFile函数基本一致,只是输出格式上有些不同)


1 public void countDir() {
2 try {
3 FileInputStream inputStream = new FileInputStream(new File(path));
4 BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(inputStream));
5 //将文件内容存入words中
6 while((lineword=bufferedReader.readLine())!=null) {
7 words+=lineword;
8 }
9 //全部转换成小写,达到不区分大小写的目的
10 String str=words.toString().toLowerCase();
11 //分割字符串并存入数组
12 String[] word = str.split("[^a-zA-Z0-9]|\\ ");
13 int num =0;
14 Map<String,Integer> myMap = new TreeMap<String,Integer>();
15 //遍历数组将其存入Map<String,Integer>中
16 for(int i=0;i<word.length;i++) {
17 //首先判断是否为合法单词
18 if(isLegal(word[i])) {
19 if(myMap.containsKey(word[i])) {
20 num = myMap.get(word[i]);
21 myMap.put(word[i], num+1);
22 }
23 else {
24 myMap.put(word[i], 1);
25 }
26 }
27 }
28 //将map.entrySet()转换成list
29 List<Map.Entry<String, Integer>> list =new ArrayList<Map.Entry<String,Integer>>(myMap.entrySet());
30 //输出结果
31 System.out.println("total"+" "+list.size()+" words");
32 for(int i=0;i<list.size();i++) {
33 Map.Entry<String, Integer> e =list.get(i);
34 System.out.println(e.getKey()+" "+e.getValue());
35 }
36 bufferedReader.close();
37 }catch(FileNotFoundException e) {
38 e.printStackTrace();
39 }catch(IOException e) {
40 e.printStackTrace();
41 }
42 }
5) countNum()函数:当输入格式为【wf -f 文件路径 -n 数量】或者【wf -c 文件名 -n 数量】或者【wf -n 数量 -c 文件名】或者【wf -n 数量 -f 文件路径】时调用,并输出结果
1 public void countNum(int n) {
2 try {
3 FileInputStream inputStream = new FileInputStream(new File(path));
4 BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(inputStream));
5 //将文件内容存入words中
6 while((lineword=bufferedReader.readLine())!=null) {
7 words+=lineword+"\n";
8 }
9 //全部转换成小写,达到不区分大小写的目的
10 String str=words.toString().toLowerCase();
11 //分割字符串并存入数组
12 String[] word = str.split("[^a-zA-Z0-9]|\\ ");
13 int num =0;
14 Map<String,Integer> myMap = new TreeMap<String,Integer>();
15 //遍历数组将其存入Map<String,Integer>中
16 for(int i=0;i<word.length;i++) {
17 //首先判断是否为合法单词
18 if(isLegal(word[i])) {
19 if(myMap.containsKey(word[i])) {
20 num = myMap.get(word[i]);
21 myMap.put(word[i], num+1);
22 }
23 else {
24 myMap.put(word[i], 1);
25 }
26 }
27 }
28 //将map.entrySet()转换成list
29 List<Map.Entry<String, Integer>> list =new ArrayList<Map.Entry<String,Integer>>(myMap.entrySet());
30 //通过比较器实现排序
31 Collections.sort(list,new Comparator<Map.Entry<String, Integer>>(){
32 public int compare(Entry<String,Integer> e1,Entry<String,Integer> e2) {
33 return e2.getValue().compareTo(e1.getValue());
34 }
35 });
36 //输出结果
37 System.out.println("Total words is "+list.size());
38 System.out.println("----------");
39 for(int i=0;i<n;i++) {
40 Map.Entry<String, Integer> e =list.get(i);
41 System.out.printf("%-14s%d\n",e.getKey(),e.getValue());
42 }
43 bufferedReader.close();
44 }catch(FileNotFoundException e) {
45 e.printStackTrace();
46 }catch(IOException e) {
47 e.printStackTrace();
48 }
49 }
6)setpath()函数:创建对象时若没有传入路径,则给变量path赋值
public void setpath(String path) { this.path=path; }
7)最后,在wfTest类里,我通过 if else 语句对控制台输入的字符串分情况讨论,调用相应的方法
1 package wf;
2 import java.util.*;
3
4 public class wfTest{
5 public static void main(String[] args) {
6 Scanner input = new Scanner(System.in);
7 String str = "";
8 str = input.nextLine();
9 String[] splt = str.split(" ");
10 String path;
11 int num=splt.length;
12 if(num==3) {
13
14 if(splt[1].equals("-c")) {
15 path=splt[2];
16 wf test = new wf(path);
17 test.countFile();
18 }else if(splt[1].equals("-f")){
19
20 wf test = new wf();
21 path=test.readDir(splt[2]);
22 // System.out.println(splt[2]);
23 test.setpath(splt[2]+"\\"+path);
24 test.countDir();
25 }else {
26 System.out.println("输入格式有错误");
27 }
28
29 }else if(num==5) {
30 if(splt[1].equals("-f")&&splt[3].equals("-n")) {
31 wf test = new wf();
32 path=test.readDir(splt[2]);
33 test.setpath(splt[2]+"\\"+path);
34 test.countNum(Integer.parseInt(splt[4]));
35 }else if(splt[1].equals("-c")&&splt[3].equals("-n")) {
36 path=splt[2];
37 wf test = new wf(path);
38 test.countNum(Integer.parseInt(splt[4]));
39 }else if(splt[1].equals("-n")&&splt[3].equals("-c")) {
40 path=splt[4];
41 wf test = new wf(path);
42 test.countNum(Integer.parseInt(splt[2]));
43 }else if(splt[1].equals("-n")&&splt[3].equals("-f")) {
44 wf test = new wf();
45 path=test.readDir(splt[4]);
46 test.setpath(splt[4]+"\\"+path);
47 test.countNum(Integer.parseInt(splt[2]));
48 }else {
49 System.out.println("输入格式有错误");
50 }
51 }else {
52 System.out.println("输入格式有错误");
53 }
54
55 input.close();
56 }
57 }
8)运行结果展示:
此截图是在eclipse平台上运行的效果,但是项目里已经生成 wf.exe 执行文件,可以在控制台进行测试(这是我第一次用jar包通过exe4j生成可执行文件,因为在exe4j上忘记选择生成控制台程序(默认是gui程序),所以在这里纠结了好久,真的是。。。为了避免大家犯同样的错误,在此诚挚地推荐一篇相关博客:https://blog.csdn.net/u011752272/article/details/80697198)
作业输出样例:
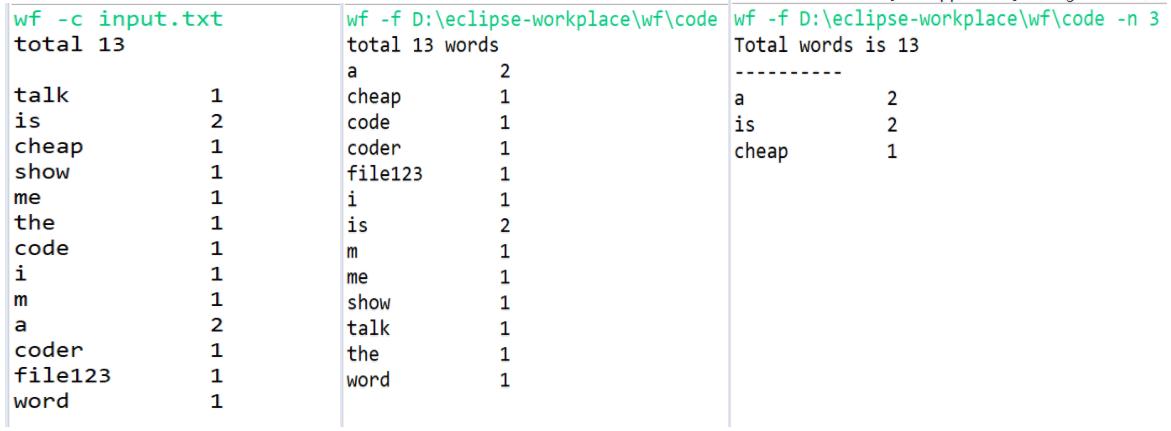
测试输出样例:

3.个人感想
通过此次项目的经历,我觉得代码的规范性很重要。这次作业我相当于写了两个版本,最终的代码是在初期代码的基础上改了很多,这个改代码的时间真的快赶上我写出程序的时间了。一开始自己没想着如何整体对项目结构进行设计,就一步步按照自己的想法写完了,但是回过头去改的时候,发现结构有些乱,改的时候需要兼顾很多东西,真的不太好。这让我想到了《构建之法》第四章所讲的有关代码规范的重要性,现在看自己编写的代码都别扭与复杂,更别说在合作的过程中他人看自己的代码的感受了。希望自己可以通过此次作业,在这方面有所改进。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号