
Deep Learning学习(开篇)
2013-02-19 22:02 Jack King 阅读(28373) 评论(5) 收藏 举报Deep Learning(深度学习)最近火爆的不行,不论是以NIPS,ICML,CVPR这些top conference为代表的学术界,还是以Google,Microsoft,IBM为代表的工业界,都加入到了轰轰烈烈的深度学习行列中。在可以预见的相当长一段时间内,Deep Learning依然会持续这种热点状态。下面的工作和Deep Learning的内容很相关,希望能够比较深入详细的研究一下其相关的内容。后面会坚持记录下学习过程,既是对自己的鼓励,也希望能够和更多的朋友进行交流。
应该如何开头呢?这个话题千头万绪的,自己也没有仔细整理过,都是东拼西凑零零散散的东西。记得以前一个教育家说过,人类的学习过程应该遵循认知的过程,而不是理论的逻辑过程。大概是这个意思吧,具体记不清楚了,下面就从自己接触到了解Deep Learning的过程来说一下。
最初知道Deep Learning还是从Neural Network大本营 NIPS的Paper List上偶然看到的,是一篇关于Sparse Coding的文章。当时不懂的问题很多,只是知道这种non-linear变化是很NB的,后来再没有过多接触。后来是从新浪微博上一干大牛(@余凯_西二旗民工,@张栋_机器学习,@老师木,@邓侃等等)讨论中有一个比较入门的了解。前一段时间自己在做关于Transfer Learning和Metric Learning的东西,对Features Learning方面的有了一些认识,才对Deep Learning有一些体会。
我们知道在信号处理中,无论是图像还是语音,基本的处理流程是(以图像为例):
(1) 对原始输入进行预处理,如resize图像大小,去除噪音,背景差分等;
(2) 在预处理过程输出的数据上提取特征,进行features extraction及feature selection的操作,比如进行HOG计算,之后进行特征降维等;
(3) 在获得的features vectors(instances)之上,使用各种model进行学习,训练,最终完成具体任务,如Classification,Recognition等
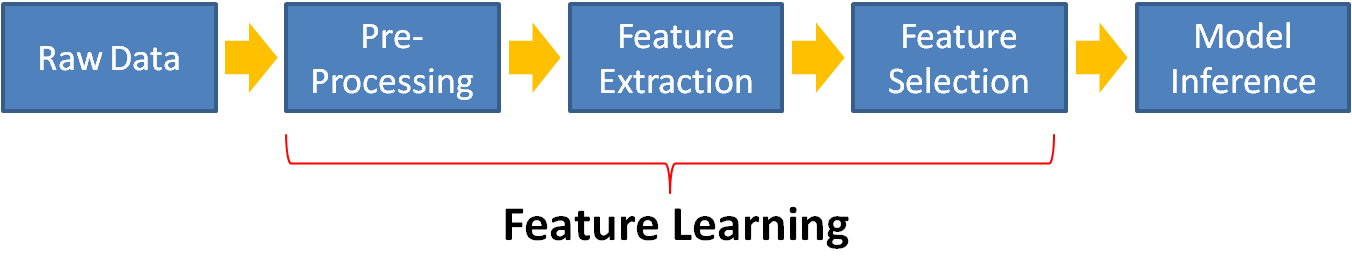
这里面通常把通常把(1)和(2)统称起来叫做Feature Learning。需要说明一下,在上图中,把(2)过程分成两个Feature Extraction和Feature Learning两个部分。很多文献中,把关于feature的linear transformation称为Feature Extraction,关于non-linear transformation称为Feature Selection。为了便于区分,这里将计算、提取特征称为Feature Extraction,将对特征(feature)的linear 和non-linear transformation 统称为Feature Selection。
从上面的这个流程图中,我们可以看出,后面的操作是建立在前面输出结果的基础之上的。这样越靠近前部的处理就愈加重要,不考虑“预处理”部分,Feature Extraction是其中最为重要的部分。有很多文献中都提及到,Feature Extraction决定了要解决问题的能力上限,而在其后流程中的模型\方法等只是为了更好的或更有效的接近这个上限。
我们知道,虽然研究设计features的工作很多,但是特别有效的feature还是很少,在眼前张口就来的可能就SIFT,HOG这么几种。这里要说明的是,我们不是否定关于设计feature的工作,而是说这部分工作是很难的,特别是具体到一个特殊领域工作中,这些Features是否依然适合解决我们的问题都是未知。并且在实际工作,这部分工作需要更多的人工操作参入其中,由于人的因素这一方面增加了feature的不确定性,另一方面使得工程投入十分昂贵。
众多牛人其实很早以前就意识到这个问题了,也进行了很多尝试,比如类似Metric Learning,Kernel Learning等,这些linear或是non-linear的transformation都希望可以获取更有效的feature representation。然而,就像我们前面谈论到的,这些方法还是已有的features基础之上的。根据features决定上限的理论,这个东西还不是我们最想要的东西。于是牛人也继续发展这个问题,既然这个问题还是不行,大家干脆直接从原始底层数据上学习feature吧(features learning/representation learning),于是乎传说中的Deep Learning在这种需求背景下横空出世了。
深度学习(Deep Learning)的概念大概是2006年左右由Geoffrey Hinton等人提出来的,主要通过神经网络(Neural Network, NN)来模拟人的大脑的学习过程,希望通过模仿人的大脑的多层抽象机制来实现对数据(画像、语音及文本等)的抽象表达,将features learning和classifier整合到了一个学习框架中,减少了人工/人为在设计features中的工作。“深度学习”里面的深度(Deep)指的就是神经网络多层结构。深度学习的基本思想就是,在一个n层的NN中,对每一层的输出(Output)与这一层的输入(Input)“相等”。这个地方“相等”有两个含义在里面:第一个是说Output和Input不是在绝对形式上的相等,而是在抽象意义上的相等,举个不太恰当的例子,比如说对“交通工具”这个概念上,Input是“可以驾驶的,四个轮子”,Output是“车”,这样虽然对两者的描述不一致,但是我们都可以理解为“交通工具”了;关于“相等”的另外一点指的是限制的约束的程度,比如说是不会造成歧义的完全“相等”还是有适当宽松条件的“相等”。 其实上面的最后一点中的这两个思想,也是对应了Deep Learning中两种方法:AutoEncoder和Sparse Coding,除去这两者外,还有一个很常用的方法就是Restrict Boltzmann Machine (RBM)。具体的细节问题,在这里面暂时不讨论,在后面学习的时候会单独讨论到这个问题。
Deep Learning技术已经有些年头了(2006),真正震撼大家的可能是两件事。一个是在2012年的ImageNet画像识别大赛上,Geoffrey Hinton带领学生利用Deep Learning取得了极好的成绩(2012,85%;2011,74%;2010,72%)。另外一件事是Microsoft通过与Geoffrey Hinton合作,利用Deep Learning在语音识别系统中取得了巨大的成功。无论研究人员还是工程师,在这两件事上除去惊喜外,更看到了巨大的经济利益。从2012年Google透漏出来的技术路线图,我们也可以看到,Google下一阶段的技术重点也放到了Deep Learning(另一个是Knowledge Graph)。邓侃在他的文章中说:“借助于 Deep Learning 算法,人类终于找到了如何处理‘抽象概念’这个亘古难题的方法。”,“Deep Learning 引爆的这场革命,不仅学术意义巨大,而且离钱很近,实在太近了。如果把相关技术难题比喻成一座山,那么翻过这座山,山后就是特大露天金矿。技术难题解决以后,剩下的事情,就是动用资本和商业的强力手段,跑马圈地了。”也就是因为这些原因,让大家极度兴奋。
虽然Deep Learning看起来很完美,但是我们也得认识到这东西也是有不足的。比如老师木认为这个东西只是大家新炒作起来的技术,本质上与其他的Machine Learning的方法没有区别,Deep Learning可以做到的,其他方法也是可以做到的。所以学习的时候也不要迷信DL,要有一个清醒的认识。
还有一些关于Deep Learning的一些趣闻,主要是关于Geoffrey Hinton。这位老先生可以说是Deep Learning的开山鼻祖了。Hinton老先生很是了不起,是NN的终极Fans,专注NN四十年之久,即是大家都不看好NN的时候,老先生对NN也是不离不弃。余凯的在中科院计算所的talk里,也聊过关于SVM和NN之间一些“恩怨”,听着也很是有趣。觉得这些大师之间有时候也是很有趣的,参考文献中有一些关于些故事的,感兴趣的可以看一看。不管怎么说,对于这些事情我们这些小人物就是听一个乐子吧,最应该学习的是大师们的优点,踏踏实实的做好自己的研究和工作。
下面的学习计算从两方面走,一个是从理论上仔细学习一下相关方法,多读一些文献,看看其他人是都是从哪些方面入手的,这个还要看一些文章再做决定,这个主要是从[1]中给出的reading list入手了,主要集中在关于Computer Vision的部分。
另一个是从应用上走,主要是研究一些Deep Learning工具的使用(主要是Theano),实现一些示例。在这个过程中有不理解的地方在做适当的调整、学习。主要是按照[9]中给出的路线走:先了解一下Theano basic tutorial,然后按照[1]中的Getting StartedGuide学习。
之后呢尝试几个算法,关于Supervise Learning的
(1) Logistic Regression - using Theano for something simple
(2)Multilayer perceptron - introduction to layers
(3) Deep Convolutional Network - a simplified version of LeNet5
Unsupervise Learning的
(1) Auto Encoders, Denoising Autoencoders - description of autoencoders
(2)Stacked Denoising Auto-Encoders - easy steps into unsupervised pre-training for deep nets
(3) Restricted Boltzmann Machines - single layer generative RBM model
(4) Deep Belief Networks - unsupervised generative pre-training of stacked RBMs followed by supervised fine-tuning
下面给出一些参考文献:
[1] Website: http://deeplearning.net/
[2] Introduction to Deep Learning: http://en.wikipedia.org/wiki/Deep_learning
[3] Bengio’s Survey: http://www.iro.umontreal.ca/~bengioy/papers/ftml_book.pdf
[4] Standord Deep Learning tutorial: http://ufldl.stanford.edu/wiki/index.php/UFLDL_Tutorial
[5] cvpr 2012 tutorial:http://cs.nyu.edu/~fergus/tutorials/deep_learning_cvpr12/tutorial_p2_nnets_ranzato_short.pdf, from LR, NN, CNN to Sparse Encoder
[6] 李航博士: http://blog.sina.com.cn/s/blog_7ad48fee0100vz2f.html
[7] 八卦: http://www.cnblogs.com/nicejs/archive/2012/12/07/2807766.html
[8] 邓亚峰: http://blog.sina.com.cn/s/blog_6ae183910101dw2z.html
[9] elevencity : http://elevencitys.com/?p=1854
[10] 邓侃:http://blog.sina.com.cn/s/blog_46d0a3930101fswl.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号