

词法分析中的“贪心算法”(读《C陷阱与缺陷》)
1、一些专业名词的定义
符号:关键字+标志符+运算符
词法分析器:编译器中负责将程序分解为一个一个符号的部分,一般称为词法分析器。
符号之间的空白(空格符、制表符、换行符)被忽略。
因此代码1和代码2是等效的
代码1: 1 if(x > y) big = x
代码2:
1 i 2 f 3 ( 4 x 5 > 6 y 7 ) 8 b 9 i 10 g 11 = 12 x
C语言中某些符号:
例1:/ 、*、=
特点:只有一个字符长。称为单字符符号
例2: /* 、==、以及标识符,包括了多个字符,称为多字符符号
简单的来说词法分析中的“贪心算法”就是,当C编译器读取了一个字符,他会继续读取连续最大范围内与它组成符号的其他字符。如果不能组成符,则停止。
规则:每个符号尽可能包含多的字符,编译器从左至右一个字符一个字符读入,如果该字符可能组成一个符号,那么再读入下一个字符,再判断已经读入的两个字符组成的字符串是否可能是一个字符的组成部分,如果可能,继续读入下一个字符,重复上述循环且判断,直到读入的字符组成的字符串已不再可能组成一个有意义的的符号。
需要注意的是:除了字符串和字符常量,符号的中间不能嵌有空白(空白符、制表符、换行符),例如 == 和 = = 是两个符号
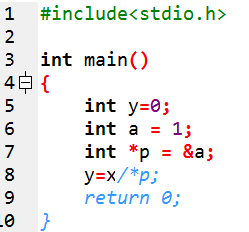
代码3: 1 y=x/*p
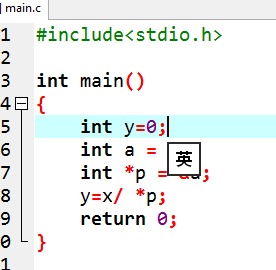
代码4: 1 y=x/ *p
代码3则表示 /* 后面的全被注释,直到匹配到右注释符号 */
代码4则表示 y 等于 x除以 p所指向内存的值
代码3实例图:
代码4实例图:
我们实际中,应该尽量减少这种操作。或者选用优先级的 () 来规避这种准二义性。你让机器纠结了,机器就会纠结死你。
题目1:a+++++b
题目2:为什么n-->0的含义是n-- > 0,而不是n- ->0
解答1:a++为第一个符号,然后++组成第二个符号,第一个后置++有匹配项a,而a++是个左值用于匹配第二个++
解答2:n--为第一个符号,然后>为单独符号 。

