
用C#实现字符串相似度算法(编辑距离算法 Levenshtein Distance)
在搞验证码识别的时候需要比较字符代码的相似度用到“编辑距离算法”,关于原理和C#实现做个记录。
据百度百科介绍:
编辑距离,又称Levenshtein距离(也叫做Edit Distance),是指两个字串之间,由一个转成另一个所需的最少编辑操作次数,如果它们的距离越大,说明它们越是不同。许可的编辑操作包括将一个字符替换成另一个字符,插入一个字符,删除一个字符。
例如将kitten一字转成sitting:
sitten (k→s)
sittin (e→i)
sitting (→g)
俄罗斯科学家Vladimir Levenshtein在1965年提出这个概念。因此也叫Levenshtein Distance。
例如
- 如果str1="ivan",str2="ivan",那么经过计算后等于 0。没有经过转换。相似度=1-0/Math.Max(str1.length,str2.length)=1
- 如果str1="ivan1",str2="ivan2",那么经过计算后等于1。str1的"1"转换"2",转换了一个字符,所以距离是1,相似度=1-1/Math.Max(str1.length,str2.length)=0.8
应用
DNA分析
拼字检查
语音辨识
抄袭侦测
补充内容:
感谢评论区刀是什么样的刀的热心分享,有兴趣的朋友可以参考一下stackoverflow的这篇博文:How to Strike a Match
整理了下stackoverflow的代码,代码如下:
1 /// <summary> 2 /// This class implements string comparison algorithm 3 /// based on character pair similarity 4 /// Source: http://www.catalysoft.com/articles/StrikeAMatch.html 5 /// </summary> 6 public class SimilarityTool 7 { 8 /// <summary> 9 /// Compares the two strings based on letter pair matches 10 /// </summary> 11 /// <param name="str1"></param> 12 /// <param name="str2"></param> 13 /// <returns>The percentage match from 0.0 to 1.0 where 1.0 is 100%</returns> 14 public double CompareStrings(string str1, string str2) 15 { 16 List<string> pairs1 = WordLetterPairs(str1.ToUpper()); 17 List<string> pairs2 = WordLetterPairs(str2.ToUpper()); 18 19 int intersection = 0; 20 int union = pairs1.Count + pairs2.Count; 21 22 for (int i = 0; i < pairs1.Count; i++) 23 { 24 for (int j = 0; j < pairs2.Count; j++) 25 { 26 if (pairs1[i] == pairs2[j]) 27 { 28 intersection++; 29 pairs2.RemoveAt(j);//Must remove the match to prevent "GGGG" from appearing to match "GG" with 100% success 30 31 break; 32 } 33 } 34 } 35 return (2.0 * intersection) / union; 36 } 37 38 /// <summary> 39 /// Gets all letter pairs for each 40 /// individual word in the string 41 /// </summary> 42 /// <param name="str"></param> 43 /// <returns></returns> 44 private List<string> WordLetterPairs(string str) 45 { 46 List<string> AllPairs = new List<string>(); 47 48 // Tokenize the string and put the tokens/words into an array 49 string[] Words = Regex.Split(str, @"\s"); 50 51 // For each word 52 for (int w = 0; w < Words.Length; w++) 53 { 54 if (!string.IsNullOrEmpty(Words[w])) 55 { 56 // Find the pairs of characters 57 String[] PairsInWord = LetterPairs(Words[w]); 58 59 for (int p = 0; p < PairsInWord.Length; p++) 60 { 61 AllPairs.Add(PairsInWord[p]); 62 } 63 } 64 } 65 return AllPairs; 66 } 67 68 /// <summary> 69 /// Generates an array containing every 70 /// two consecutive letters in the input string 71 /// </summary> 72 /// <param name="str"></param> 73 /// <returns></returns> 74 private string[] LetterPairs(string str) 75 { 76 int numPairs = str.Length - 1; 77 78 string[] pairs = new string[numPairs]; 79 80 for (int i = 0; i < numPairs; i++) 81 { 82 pairs[i] = str.Substring(i, 2); 83 } 84 return pairs; 85 } 86 }
算法过程
- str1或str2的长度为0返回另一个字符串的长度。 if(str1.length==0) return str2.length; if(str2.length==0) return str1.length;
- 初始化(n+1)*(m+1)的矩阵d,并让第一行和列的值从0开始增长。
- 扫描两字符串(n*m级的),如果:str1[i] == str2[j],用temp记录它,为0。否则temp记为1。然后在矩阵d[i,j]赋于d[i-1,j]+1 、d[i,j-1]+1、d[i-1,j-1]+temp三者的最小值。
- 扫描完后,返回矩阵的最后一个值d[n][m]即是它们的距离。
计算相似度公式:1-它们的距离/两个字符串长度的最大值。
为了直观表现,我将两个字符串分别写到行和列中,实际计算中不需要。我们用字符串“ivan1”和“ivan2”举例来看看矩阵中值的状况:
1、第一行和第一列的值从0开始增长
| i | v | a | n | 1 | ||
| 0 | 1 | 2 | 3 | 4 | 5 | |
| i | 1 | |||||
| v | 2 | |||||
| a | 3 | |||||
| n | 4 | |||||
| 2 | 5 |
2、i列值的产生 Matrix[i - 1, j] + 1 ; Matrix[i, j - 1] + 1 ; Matrix[i - 1, j - 1] + t
| i | v | a | n | 1 | ||
| 0+t=0 | 1+1=2 | 2 | 3 | 4 | 5 | |
| i | 1+1=2 | 取三者最小值=0 | ||||
| v | 2 | 依次类推:1 | ||||
| a | 3 | 2 | ||||
| n | 4 | 3 | ||||
| 2 | 5 | 4 |
3、V列值的产生
| i | v | a | n | 1 | ||
| 0 | 1 | 2 | ||||
| i | 1 | 0 | 1 | |||
| v | 2 | 1 | 0 | |||
| a | 3 | 2 | 1 | |||
| n | 4 | 3 | 2 | |||
| 2 | 5 | 4 | 3 |
依次类推直到矩阵全部生成
| i | v | a | n | 1 | ||
| 0 | 1 | 2 | 3 | 4 | 5 | |
| i | 1 | 0 | 1 | 2 | 3 | 4 |
| v | 2 | 1 | 0 | 1 | 2 | 3 |
| a | 3 | 2 | 1 | 0 | 1 | 2 |
| n | 4 | 3 | 2 | 1 | 0 | 1 |
| 2 | 5 | 4 | 3 | 2 | 1 | 1 |
最后得到它们的距离=1
相似度:1-1/Math.Max(“ivan1”.length,“ivan2”.length) =0.8
算法用C#实现:
1 public class LevenshteinDistance 2 { 3 /// <summary> 4 /// 取最小的一位数 5 /// </summary> 6 /// <param name="first"></param> 7 /// <param name="second"></param> 8 /// <param name="third"></param> 9 /// <returns></returns> 10 private int LowerOfThree(int first, int second, int third) 11 { 12 int min = Math.Min(first, second); 13 return Math.Min(min, third); 14 } 15 16 private int Levenshtein_Distance(string str1, string str2) 17 { 18 int[,] Matrix; 19 int n = str1.Length; 20 int m = str2.Length; 21 22 int temp = 0; 23 char ch1; 24 char ch2; 25 int i = 0; 26 int j = 0; 27 if (n == 0) 28 { 29 return m; 30 } 31 if (m == 0) 32 { 33 34 return n; 35 } 36 Matrix = new int[n + 1, m + 1]; 37 38 for (i = 0; i <= n; i++) 39 { 40 //初始化第一列 41 Matrix[i, 0] = i; 42 } 43 44 for (j = 0; j <= m; j++) 45 { 46 //初始化第一行 47 Matrix[0, j] = j; 48 } 49 50 for (i = 1; i <= n; i++) 51 { 52 ch1 = str1[i - 1]; 53 for (j = 1; j <= m; j++) 54 { 55 ch2 = str2[j - 1]; 56 if (ch1.Equals(ch2)) 57 { 58 temp = 0; 59 } 60 else 61 { 62 temp = 1; 63 } 64 Matrix[i, j] = LowerOfThree(Matrix[i - 1, j] + 1, Matrix[i, j - 1] + 1, Matrix[i - 1, j - 1] + temp); 65 } 66 } 67 for (i = 0; i <= n; i++) 68 { 69 for (j = 0; j <= m; j++) 70 { 71 Console.Write(" {0} ", Matrix[i, j]); 72 } 73 Console.WriteLine(""); 74 } 75 76 return Matrix[n, m]; 77 } 78 79 /// <summary> 80 /// 计算字符串相似度 81 /// </summary> 82 /// <param name="str1"></param> 83 /// <param name="str2"></param> 84 /// <returns></returns> 85 public decimal LevenshteinDistancePercent(string str1, string str2) 86 { 87 //int maxLenth = str1.Length > str2.Length ? str1.Length : str2.Length; 88 int val = Levenshtein_Distance(str1, str2); 89 return 1 - (decimal)val / Math.Max(str1.Length, str2.Length); 90 } 91 }
调用:
1 static void Main(string[] args) 2 { 3 string str1 = "ivan1"; 4 string str2 = "ivan2"; 5 Console.WriteLine("字符串1 {0}", str1); 6 7 Console.WriteLine("字符串2 {0}", str2); 8 9 Console.WriteLine("相似度 {0} %", new LevenshteinDistance().LevenshteinDistancePercent(str1, str2) * 100); 10 Console.ReadLine(); 11 }
结果:
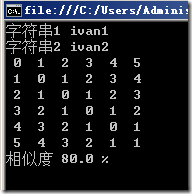
拓展与补充:
小规模的字符串近似搜索,需求类似于搜索引擎中输入关键字,出现类似的结果列表。
来源:.Net.NewLife。
需求:假设在某系统存储了许多地址,例如:“北京市海淀区中关村大街1号海龙大厦”。用户输入“北京 海龙大厦”即可查询到这条结果。另外还需要有容错设计,例如输入“广西 京岛风景区”能够搜索到"广西壮族自治区京岛风景名胜区"。最终的需求是:可以根据用户输入,匹配若干条近似结果共用户选择。
目的:避免用户输入类似地址导致数据出现重复项。例如,已经存在“北京市中关村”,就不应该再允许存在“北京中关村”。
举例:



此类技术在搜索引擎中早已广泛使用,例如“查询预测”功能。
要实现此算法,首先需要明确“字符串近似”的概念。
计算字符串相似度通常使用的是动态规划(DP)算法。
常用的算法是 Levenshtein Distance。用这个算法可以直接计算出两个字符串的“编辑距离”。所谓编辑距离,是指一个字符串,每次只能通过插入一个字符、删除一个字符或者修改一个字符的方法,变成另外一个字符串的最少操作次数。这就引出了第一种方法:计算两个字符串之间的编辑距离。稍加思考之后发现,不能用输入的关键字直接与句子做匹配。你必须从句子中选取合适的长度后再做匹配。把结果按照距离升序排序。
1 using System; 2 using System.Collections.Generic; 3 using System.Linq; 4 using System.Text; 5 6 namespace BestString 7 { 8 public static class SearchHelper 9 { 10 public static string[] Search(string param, string[] datas) 11 { 12 if (string.IsNullOrWhiteSpace(param)) 13 return new string[0]; 14 15 string[] words = param.Split(new char[] { ' ', ' ' }, StringSplitOptions.RemoveEmptyEntries); 16 17 foreach (string word in words) 18 { 19 int maxDist = (word.Length - 1) / 2; 20 21 var q = from str in datas 22 where word.Length <= str.Length 23 && Enumerable.Range(0, maxDist + 1) 24 .Any(dist => 25 { 26 return Enumerable.Range(0, Math.Max(str.Length - word.Length - dist + 1, 0)) 27 .Any(f => 28 { 29 return Distance(word, str.Substring(f, word.Length + dist)) <= maxDist; 30 }); 31 }) 32 orderby str 33 select str; 34 datas = q.ToArray(); 35 } 36 37 return datas; 38 } 39 40 static int Distance(string str1, string str2) 41 { 42 int n = str1.Length; 43 int m = str2.Length; 44 int[,] C = new int[n + 1, m + 1]; 45 int i, j, x, y, z; 46 for (i = 0; i <= n; i++) 47 C[i, 0] = i; 48 for (i = 1; i <= m; i++) 49 C[0, i] = i; 50 for (i = 0; i < n; i++) 51 for (j = 0; j < m; j++) 52 { 53 x = C[i, j + 1] + 1; 54 y = C[i + 1, j] + 1; 55 if (str1[i] == str2[j]) 56 z = C[i, j]; 57 else 58 z = C[i, j] + 1; 59 C[i + 1, j + 1] = Math.Min(Math.Min(x, y), z); 60 } 61 return C[n, m]; 62 } 63 } 64 }
分析这个方法后发现,每次对一个句子进行相关度比较的时候,都要把把句子从头到尾扫描一次,每次扫描还需要以最大误差作长度控制。这样一来,对每个句子的计算次数大大增加。达到了二次方的规模(忽略距离计算时间)。
所以我们需要更高效的计算策略。在纸上写出一个句子,再写出几个关键字。一个一个涂画之后,偶然发现另一种字符串相关的算法完全可以适用。那就是 Longest common subsequence(LCS,最长公共字串)。为什么这个算法可以用来计算两个字符串的相关度?先看一个例子:
关键字:少年时代的神话播下了浪漫注意
句子:就是少年时代大量神话传说在其心田里播下了浪漫主义这颗难以磨灭的种子
这里用了两个关键字进行搜索。可以看出来两个关键字都有部分匹配了句子中的若干部分。这样可以单独为两个关键字计算 LCS,LCS之和就是简单的相关度。看到这里,你若是已经理解了核心思想,已经可以实现出基本框架了。但是,请看下面这个例子:
关键字:东土大唐,唐三藏
句子:我本是东土大唐钦差御弟唐三藏大徒弟孙悟空行者
看出来问题了吗?下面还是使用同样的关键字和句子。
关键字:东土大(唐唐)三藏
句子: 我本是东土大唐钦差御弟唐三藏大徒弟孙悟空行者
举这个例子为了说明,在进行 LCS 计算的过程中,得到的结果并不能保证就是我们期望的结果。为了①保证所匹配的结果中不存在交集,并且②在句子中的匹配结果尽可能的短,需要采取两个补救措施。(为什么需要满足这样的条件,读者自行思考)
第一:可以在单次计算 LCS 之后,用贪心策略向前(向后)找到最先能够完成匹配的位置,再用相同的策略向后(向前)扫描。这样可以满足第二个条件找到句子中最短的匹配。如果你对 LCS 算法有深入了解,完全可以在计算 LCS 的过程中找到最短匹配的结束位置,然后只需要进行一次向前扫描就可以完成。这样节约了一次扫描过程。
第二:增加一个标记数组,记录句子中的字符是否被匹配过。
最后标记数组中标记过的位置就是匹配结果。
相信你看到这里一定非常头晕,下面用一个例子解释:(句子)
关键字: ABCD
句子: XAYABZCBXCDDYZ
句子分解: X Y Z X YZ
A B C D
A B C D
你可能会匹配成 AYABZCBXCDD,AYABZCBXCD,ABZCBXCDD,ABZCBXCD。我们实际需要的只是ABZCBXCD。
使用LCS匹配之后,得到的很可能是 XAYABZCBXCDDYZ;
用贪心策略向前处理后,得到结果为 XAYABZCBXCDDYZ;
用贪心策略向后处理后,得到结果为 XAYABZCBXCDDYZ。
这样处理的目的是为了避免得到较长的匹配结果(类似正则表达式的贪婪、懒惰模式)。
以上只是描述了怎么计算两个字符串的相似程度。除此之外还需要:①剔除相似度较低的结果;②对结果进行排序。
剔除相似度较低的结果,这里设定了一个阈值:差错比例不能超过匹配结果长度的一半。
对结果进行排序,不能够直接使用相似度进行排序。因为相似度并没有考虑到句子的长度。按照使用习惯,通常会把匹配度高,并且句子长度短的放在前面。这就得到了排序因子:(不匹配度+0.5)/句子长度。
最后得到我们最终的搜索方法
1 using System; 2 using System.Collections.Generic; 3 using System.Linq; 4 using System.Text; 5 using System.Diagnostics; 6 7 namespace BestString 8 { 9 public static class SearchHelper 10 { 11 public static string[] Search(string param, string[] items) 12 { 13 if (string.IsNullOrWhiteSpace(param) || items == null || items.Length == 0) 14 return new string[0]; 15 16 string[] words = param 17 .Split(new char[] { ' ', '\u3000' }, StringSplitOptions.RemoveEmptyEntries) 18 .OrderBy(s => s.Length) 19 .ToArray(); 20 21 var q = from sentence in items.AsParallel() 22 let MLL = Mul_LnCS_Length(sentence, words) 23 where MLL >= 0 24 orderby (MLL + 0.5) / sentence.Length, sentence 25 select sentence; 26 27 return q.ToArray(); 28 } 29 30 //static int[,] C = new int[100, 100]; 31 32 /// <summary> 33 /// 34 /// </summary> 35 /// <param name="sentence"></param> 36 /// <param name="words">多个关键字。长度必须大于0,必须按照字符串长度升序排列。</param> 37 /// <returns></returns> 38 static int Mul_LnCS_Length(string sentence, string[] words) 39 { 40 int sLength = sentence.Length; 41 int result = sLength; 42 bool[] flags = new bool[sLength]; 43 int[,] C = new int[sLength + 1, words[words.Length - 1].Length + 1]; 44 //int[,] C = new int[sLength + 1, words.Select(s => s.Length).Max() + 1]; 45 foreach (string word in words) 46 { 47 int wLength = word.Length; 48 int first = 0, last = 0; 49 int i = 0, j = 0, LCS_L; 50 //foreach 速度会有所提升,还可以加剪枝 51 for (i = 0; i < sLength; i++) 52 for (j = 0; j < wLength; j++) 53 if (sentence[i] == word[j]) 54 { 55 C[i + 1, j + 1] = C[i, j] + 1; 56 if (first < C[i, j]) 57 { 58 last = i; 59 first = C[i, j]; 60 } 61 } 62 else 63 C[i + 1, j + 1] = Math.Max(C[i, j + 1], C[i + 1, j]); 64 65 LCS_L = C[i, j]; 66 if (LCS_L <= wLength >> 1) 67 return -1; 68 69 while (i > 0 && j > 0) 70 { 71 if (C[i - 1, j - 1] + 1 == C[i, j]) 72 { 73 i--; 74 j--; 75 if (!flags[i]) 76 { 77 flags[i] = true; 78 result--; 79 } 80 first = i; 81 } 82 else if (C[i - 1, j] == C[i, j]) 83 i--; 84 else// if (C[i, j - 1] == C[i, j]) 85 j--; 86 } 87 88 if (LCS_L <= (last - first + 1) >> 1) 89 return -1; 90 } 91 92 return result; 93 } 94 } 95 }
对于此类问题,要想得到更快速的实现,必须要用到分词+索引的方案。在此不做探讨。
作 者:Angel_Kitty
出 处:https://www.cnblogs.com/ECJTUACM-873284962/
关于作者:阿里云ACE,目前主要研究方向是Web安全漏洞以及反序列化。如有问题或建议,请多多赐教!
版权声明:本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接。
特此声明:所有评论和私信都会在第一时间回复。也欢迎园子的大大们指正错误,共同进步。或者直接私信我
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是作者坚持原创和持续写作的最大动力!
欢迎大家关注我的微信公众号IT老实人(IThonest),如果您觉得文章对您有很大的帮助,您可以考虑赏博主一杯咖啡以资鼓励,您的肯定将是我最大的动力。thx.

我的公众号是IT老实人(IThonest),一个有故事的公众号,欢迎大家来这里讨论,共同进步,不断学习才能不断进步。扫下面的二维码或者收藏下面的二维码关注吧(长按下面的二维码图片、并选择识别图中的二维码),个人QQ和微信的二维码也已给出,扫描下面👇的二维码一起来讨论吧!!!

欢迎大家关注我的Github,一些文章的备份和平常做的一些项目会存放在这里。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号