
中文事件抽取关键技术研究(谭红叶 博士毕业论文)
中文事件抽取关键技术研究(谭红叶 博士毕业论文)
事件抽取的定义
ACE2005 将该项任务定义为:识别特定类型的事件,并进行相关信息的确定和抽取,主要的相关信息包括:事件的类型和子类型、事件论元角色等。根据这个定义,可将事件抽取的任务分成两大核心子任务:(1)事件的检测和类型识别;(2)事件论元角色的抽取。除此以外,由于绝大部分的论元角色都是实体,因此实体的识别也是事件抽取的一项基本任务。
信息抽取的定义
Andrew McCallum所提出的定义具有普遍意义。他将信息抽取定义为(A.McCallum. Information Extraction: Distilling Structured Data from Unstructured Text. ACM Queue 2005, 2005: 49~57):
从无结构或松散结构的文本中对数据库的字段进行填充并形成记录。涉及到这样几个子任务:①切分处理(Segmentation):主要是识别可以填充数据库字段的文本片段的起始位置。②分类(Classification):主要是 确 定 文 本 片 段 要 填 充 的 数 据 库 字 段 是 什 么 , 通 常 Segmentation 和Classification在系统中同时进行。
目前信息抽取的局限性
信息抽取系统仍然存在一些局限:1.精度不高;2.不可移植;3.组件不确定没控制
信息抽取的主要方法
主要方法:
1基于知识工程的方法,由语言学家与领域专家通过观察一些相关的文档集,根据抽取任务手工编写一定的规则来进行相关信息的抽取。(90年代)对格式化文本容易
2.统计和机器学习
2.1基于规则(决策树规则)局限性:模式表达能力有限;难获取复杂句或跨句的模式
2.2基于统计的方法:运用大量简单特征,共同使用多种细致特征。HMM, CRF, MEMM,NB。
2.3多种机器学习混合的方法。
信息抽取发展
优秀的团队:
Cymfony公司、Bhasha公司、Linguamatics公司、Revsolutions公司,纽约大学、加利福尼亚大学、尤他州大学、华盛顿大学等。在英国、德国、意大利、爱尔兰等国家也有机构在进行相关研究。
优秀的系统:
AutoSlog、CRYSTAL、PROTEUS、WIEN 、 Softmealy 、 Stalker 、 Whisk 、 SRV 、RAPIER
精度文本格式
非常规律:(数据库、数据库生成的网页)几乎完美的性能
有规律可循的:(新闻等)95%
不规律的:
关系抽取一般精度为60%
研究趋势的分析
在未来一段时间,研究关注的焦点应该是借助机器学习的方法,使系统只需最少的人工干预就能轻易地适用于新的领域和新的数据格式并能够快速地处理大规模、不受格式和领域限制的文档集合。
(1)简单训练和半监督学习。
(2)交互式抽取。
(3)不确定性估计和多个假设的管理。
事件抽取的核心任务
事件 mention 的识别、事件属性的确定和论元角色的识别。
事件的属性信息:(类型、子类型【重要】)、模态、倾向性、普遍性、时态。
论元角色:实体、数值、时间。
事件抽取的主要方法
1.基于多种机器学习的混合方法(多个子任务)
2.半监督和无监督的学习方法
实体识别方法
(1)基于规则的方法。在早期的名实体识别系统中,大多采用这种方法,具体有:决策树方法,基于转换的方法,文法方法。
(2)基于几何空间判别的方法。具体包括:支持向量机方法,Fisher判别分析,神经网络方法。 (我比较感兴趣)
(3)基于概率统计的方法。是名实体识别的主流方法和技术。具体有:Bayes 判别方法,N-gram 模型,HMM 模型,ME 模型,MEMM 模型和CRF 模型。
半监督学习的主要方法
自训练(Self-training),协作训练(Co-training),直推式(Transductive)SVM和基于图的方法(Graph-based methods)等等。
自训练(self-training/self-teaching/boostrapping)
它的主要思想是:首先利用少量的已标注数据或初始种子集合训练一个初始分类器,然后用初始分类器对未标注数据进行分类,并将可信度最大的数据加入到已标注数据中。接着在不断扩大的已标注数据集上,重复上述过程直到得到一个较为精确的分类器。
局限性:(1)初始种子不同,分类器的性能不同,分类器收敛的速度也不同。(2)Bootstrapping 过程中出现的分类错误会在自我训练过程中被逐渐放大,并导致该过程失败。因此,初始种子的选择和新标注实例的评价和选择是该算法的关键。(以前我做无监督的时候,没有意识到这是一种比较成熟的方法吧,看来看的东西太少)
种子选择:实例种子或者模式种子。
评价函数:最简单的是计数或概率。
模式
信息抽取中的模式是指可以传递特定领域中关系和事件信息的语言表达式。
信息抽取中,模式由多个项(Item)或槽(Slot)组成,其中包括:抽取项、触发项和约束项。抽取项又称为目标项,约束项有时称为约束条件,主要用来在文本中确定目标项的相关信息,以确保抽取的信息准确。约束条件主要包含句法约束与语义约束。触发项用来触发一个模式在文本片段的匹配。
(找三种模式,抽取到的内容扔到分类器中对么?)
模式的不同主要表现在以下几个方面:
(1)抽取粒度不同。有的模式可以直接抽取出准确的目标项,而有的模式抽取的是包含目标项的句法成分。
(2)约束强度不同。如果模式的约束条件越多,使用的语义约束越多,则其约束强度越强。随着约束强度的增加,模式的严格性增加,可以确保抽取的目标项的准确性,但模式的表达能力或覆盖能力会下降。
(3)抽取效率不同。有的模式一次可以抽取多个目标项,而有的模式一次只能抽取一个目标项。类似前者的模式称作多槽(Multi-slot)抽取模式,而后者称为单槽(Single-slot)抽取模式。如模式示例 1 为一个单槽抽取模式。如果采用这种模式,系统需要为每一个目标项生成对应的模式。
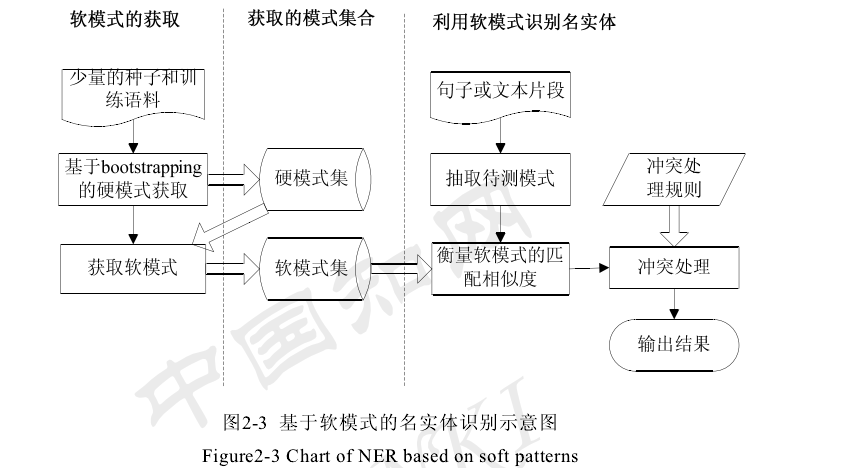
Bootstraping方法
(1)手工建立初始种子集Sseed,候选模式集Pcand = null, 可用模式集Paccepted= null。
(2)抽取模式,加入到建立候选模式集Pcand。根据种子集Sseed,在训练语料中抽取窗口大小为L的上下文模式加入到候选模式集Pcand。
(3)选择模式加入到可用模式集Paccepted。利用一定的评价函数Fpattern计算候选模式集Pcnd中每个模式的分数,并按照分数对模式排序。 满足一定条件的模式加入可用模式集Paccepted中。
(4)利用可用模式集Paccepted识别相关名实体,构成候选实例集合Icand。
(5)判断迭代是否终止。如果候选实例集合稳定即不再有新的实体名被识别,或满足一定的迭代次数,或可用模式集达到一定的规模,则循环终止;否则执行(6)。
(6)根据可信实例,确定新种子。首先Sseed= null,然后利用一定的评价函数Finstance计算候选实例集Icand中每个实例的分数,并按照分数对实例排序。满足一定条件的实例为可信实例,并且加入到种子集Sseed。
(7)返回步骤(2)开始继续循环。
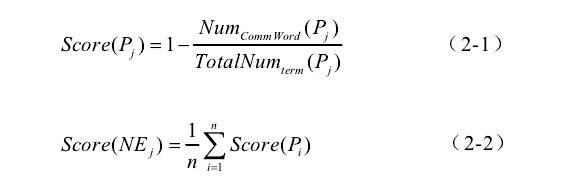
公式(2-1)是对模式的评价。其中, NumCommWord(Pj)为模式Pj抽取的普通词个数,普通词指被词典收录的词。 TotalNumterm (Pj)为模式Pj抽取出的目标项的总个数。这个公式通过模式可以抽取出的普通词与所有抽取项个数的比例对模式进行评分。该公式表明:如果一个模式抽取出的普通词越多,则这个模式对目标项的指示性越弱,即这个模式识别目标项的准确率越低。
公式(2-2)是对实例的评价。其中, Pi为本次迭代中抽取出实体NEj的任一模式,n为本次迭代中抽取出实体NEj的所有模式的总数。该公式通过可以抽取出该实例的模式的可靠程度来评价实例的可靠性。
模式泛化
一般通过放宽模式的约束条件来实现,如:缩短模式长度、利用词性或语义标记代替词形信息等等。
硬模式(Hard pattern)和硬匹配(Hard match):若模式的形式固定,且在模式匹配时需要精确匹配,则称此模式为硬模式,相应的精确匹配称为硬匹配。如:2.3 部分抽取出的模式集合就属于硬模式集合。 (正则表达式吧?)
软模式(Soft pattern)和软匹配(Soft match):若模式的形式比较灵活,且在模式匹配时不需要进行精确匹配,则称此模式为软模式,相应的匹配称为软匹配。 软模式的形式为:
<Token-L,i, W-L,i>…<Token-1,1, W-1,1>INTEREST_CLASS<Token+1,1, W+1,1> …<Token+L,i W+L,i>
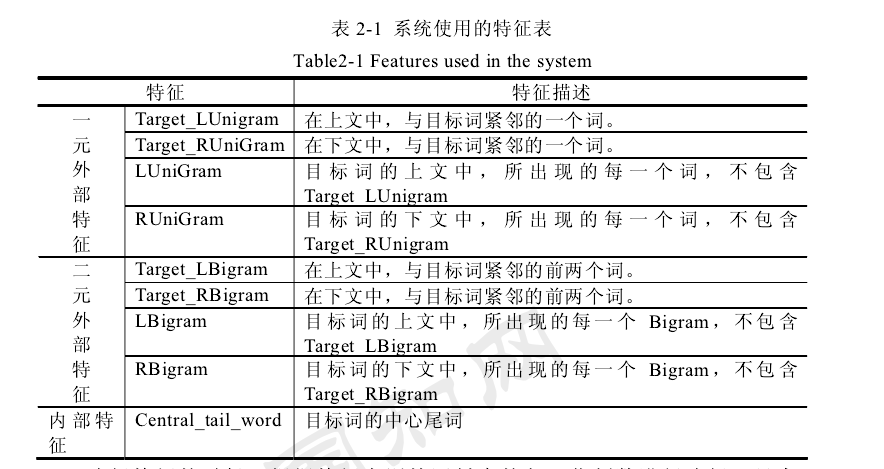
其中,Token-L,i表示第L个槽中可能出现的任何信息,如:词形、词性和语义类别等信息,W-L,i是权重,表示Token-L,i的重要性程度。
与硬模式类似,软模式也由多个槽组成。而且Token-L,i的信息与硬模式类似。
软模式和硬模式的主要不同表现在:
(1)每个槽都包含权重信息WL,i来表示TokenL,i的重要性程度。一般来说根据需要不同,WL,i的定义不同,可以是概率、相似度以及错误率等等。
(2)硬模式中的每个槽在软模式被扩展成一个词兜(Bag of words, BOW)。即,每个槽可能出现多个词语,每个词语的权重不同。
(3)模式匹配不同。硬模式要求进行硬匹配,所有的槽信息必须精确匹配。软模式由于包含权重信息,可以通过相似度计算或概率计算实现软匹配,即模糊匹配。
WL,I = P(Tokenl,i)=Num(Tokenl,i)/TotalNum(Token_in_slotl)
其 中 ,Num(Tokenl,i)是在槽slotl中出现的次数,TotalNum(Token_in_slotl)是槽slotl中出现的所有Token的次数。这些参数可以通过硬模式集合得到。
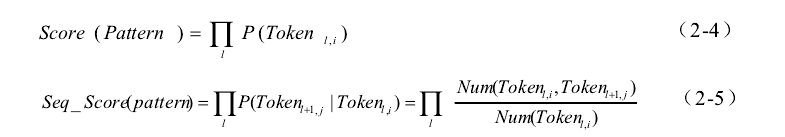
2-4计算uni-gram联合概率;2-5计算bi-gram联合概率
软模式:
冲突仲裁
(1) 联合概率大者优先。如果候选实体A的联合概率“远大于”候选实体B的联合概率,则候选实体A为最终识别结果。具体使用公式(2-4)计算联合概率时,对概率值取其对数的相反数。如果二者之差大于2就被认为是“远大于”。
(2) 联合概率与二元共现概率之和大者优先。如果不满足规则(1),则分别计算候选实体A与B的序列概率与联合概率之和,取和大者为最终识别结果。
(3) 实体长度大者优先。如果不能满足规则(1)和规则(2),则将长度大者作为最终识别结果。
把软模式转化为向量特征
冲突仲裁
(1) 相似度大者优先。如果候选实体A的相似度大于大于候选实体B的相似度,则候选实体A为最终识别结果。
(2) 实体长度大者优先。如果不能满足规则(1),则将长度大者作为最终识别结果。
利用cos作为相似度的指标
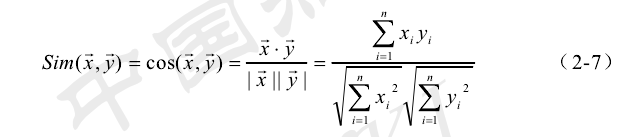
数据不均衡的问题
由于ACE语料存在着规模小、类别分布不均衡现象(Data imbalance),因此,所提出的事件检测与分类方法应该能够克服类别分布不平衡的问题。有很多人尝试去解决数据偏斜问题。有人提出通过一定的策略减少反例数量,来获取更平衡的数据(Z.H. Zheng, X.Y. Wu, R. Srihari. Feature Selection for Text Categorization on Imbalanced Data. SIGKDD Explorations, 2004, 6(1):80-89;)有人提出将问题转化为不受类别分布影响的分类问题来进行分类(苏金树,张博锋,徐昕,基于机器学习的文本分类技术研究进展,软件学报,2006, 17(9):1848-1859);也有人认为在不平衡数据上特征选择比分类算法更为重要(G. Forman. a Pitfall and Solution in Multi-Class Feature Selection for Text Classification. Proceedings of the 21st International Conference on Machine Learning (ICML2004), Banff, Canada, Morgan Kaufmann Publishers, 2004(9):38-46)。这里尝试通过好的特征选择策略来克服数据的不平衡问题,完成事件的检测和分类。
句子的表示
自然语言处理中文本表示模型主要有:布尔模型、向量空间模型、潜在语义模型、概率模型和N元语法(N-gram)模型。
如果特征项是词,则一个文本对应的向量又称作词兜(bag of words, BOW)。有很多研究表明比 BOW 复杂的数据表示形式(如:将短语作为特征项)并不能有效提升分类器的性能。因此 BOW 已经成为 NLP 中文本表示的一个标准方法。
特征选择
在实际问题中,特征空间(Feature space)的维数(Dimensionality)一般都非常大,特征维数过高不仅影响分类器的速度,而且会带来过拟和(Overfitting)问题,同时特征空间中并不是每个特征都对分类有明显的作用。因此,通过有效的方法来降低特征空间的维数显得尤为重要。主要的降维方法有特征选择(Feature selection)和特征抽取(Feature extraction)两类方法。特征选择指从原始的特征集中通过一定的方法选择特征构成新的特征子集。特征抽取是指从原始特征集中采用一定的策略生成新的特征构成新的特征集。本文采用基于特征选择的方法降低特征维数,改进分类器的性能。
特征选择方法分成封装器(Wrapper)模式和过滤器(Filter)模式两种。Wrapper方法在特征选择上表现最佳。常见的用于文本领域问题的比较著名的特征过滤方法有:文档频率(Document frequency, DF)、信息增益(Information gain,IG)、 (Chi-square)统计量,互信息(Mutual information, MI)、相关系数(Correlation coefficient,CC)、Odds Raito(OR)等策略。
全局特征选择(Global feature selection, GFS)指对所有的类别都使用通用的特征选择过程,并且在识别过程中共享一个特征集合。局部特征选择(Local feature selection, LFS)是指特征选择针对每一个类别进行,不同的类别使用不同的特征集合,因此特征选择的方法可以不同。
正特征(Positive feature, PF)对样例属于某个类别有很强的预测能力,即包含该特征的样例很大程度上属于某个类别;负特征(Negative feature, NF)可以很好地预测样例与某一个类别不相关,即包含该特征的样例很大程度上不属于某个类别。
英语的词法分析、短语分析、句法分析准确率
英文的词法分析、短语分析和句法分析的准确率分别为99%、92%和90%。S. B. Zhao, R. Grishman. Extracting Relations with Integrated Information Using Kernel Methods. Proceedings of the 43rd Annual Meeting of Association of Computational Linguistics(ACL2005), Ann Arbor, 2005: 419-426
扩展特征
(1)词林特征。91 梅家驹. 同义词词林. 上海辞书出版社, 1996 哈 工 大 信 息 检 索 实 验 室 . 同 义 词 词 林 扩 展 版 ( 电 子 版 . 2006 ,http://ir.hit.edu.cn/)
(2)知网 特征。该特 征主要指当前词在Hownet中定义的义元(SemUnit)解释,旨在利用知网(Hownet)中提供的义元解释来覆盖意相近的词。具体使用时,为每个义元指定一个编码从而得到每个词的义元解释代码。董振东, 董强. HowNet2005. http://www.keenage.com. 2005
posted on 2014-09-04 21:24 Dream_Fish 阅读(5352) 评论(0) 编辑 收藏 举报

