
python入门之jieba库的使用
对于一段英文,如果希望提取其中的的单词,只需要使用字符串处理的split()方法即可,例如“China is a great country”。


然而对于中文文本,中文单词之间缺少分隔符,这是中文及类似语言独有的“分词问题”。
jieba(“结巴”)是python中一个重要的第三方中文分词函数库。jieba库是第三方库,不是python安装包自带的,因此,需要通过pip指令安装。
Windows 下使用命令安装:在联网状态下,在命令行下输入 pip install jieba 进行安装,安装完成后会提示安装成功 。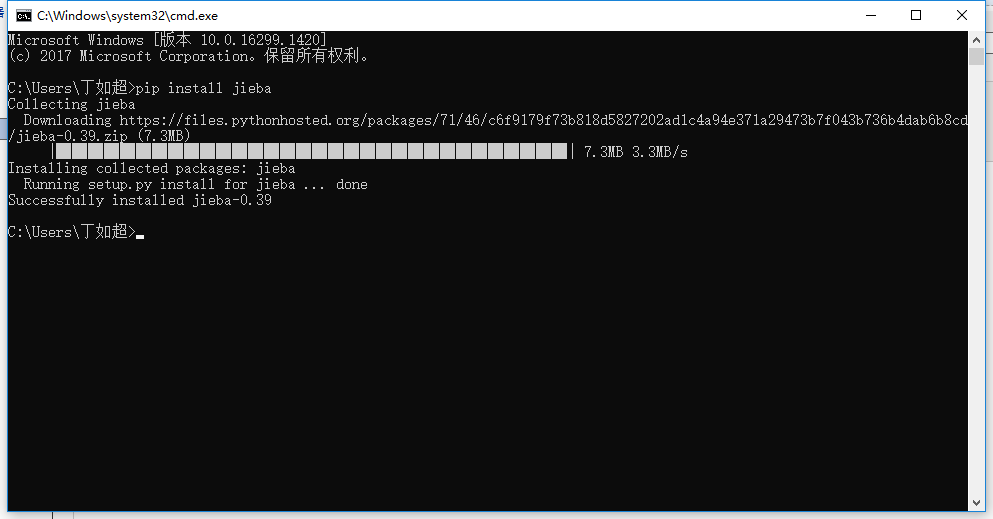
- jieba分词的三种模式
精确模式、全模式、搜索引擎模式
- 精确模式:把文本精确的切分开,不存在冗余单词
- 全模式:把文本中所有可能的词语都扫描出来,有冗余
- 搜索引擎模式:在精确模式基础上,对长词再次切分
- jieba库常用函数
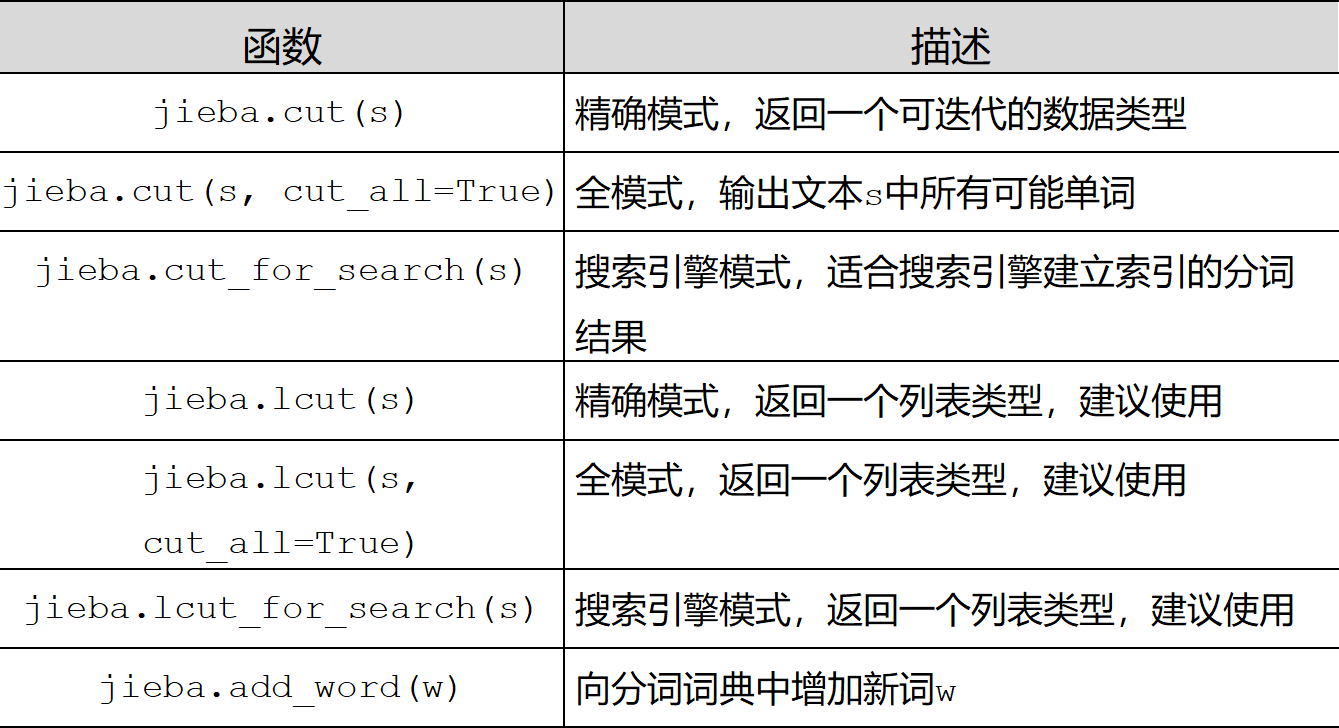
- 举例如下
jieba._lcut("中华人民共和国是一个伟大的国家")
jieba._lcut("中华人民共和国是一个伟大的国家",cut_all=True)
jieba._lcut_for_search("中华人民共和国是一个伟大的国家")
运行结果:


