SQL Server-聚焦EXISTS AND IN性能分析(十六)
前言
前面我们学习了NOT EXISTS和NOT IN的比较,当然少不了EXISTS和IN的比较,所以本节我们来学习EXISTS和IN的比较,简短的内容,深入的理解,Always to review the basics。
初步探讨EXISTS和IN
我们创建表Table1并且取出前面创建BigTable表中的六条数据并插入其中,同时有一条数据重复,如下:
CREATE TABLE Table1 (IntCol UNIQUEIDENTIFIER) Insert into Table1 (IntCol) Values ('b927ded5-c78b-4f53-80bf-f65a6ce86d87') Insert into Table1 (IntCol) Values ('1be326ec-4b62-4feb-8421-d9edf2df28c8') Insert into Table1 (IntCol) Values ('91c92337-24ba-4ebf-b2a3-14b987179ca6') Insert into Table1 (IntCol) Values ('c03168f8-c1c7-4903-a8ee-9b4d9c0b6b1f') Insert into Table1 (IntCol) Values ('c15ac08c-8d3d-4381-9c64-54854ddf15b7') Insert into Table1 (IntCol) Values ('c15ac08c-8d3d-4381-9c64-54854ddf15b7')
此时我们来进行IN查询
USE TSQL2012
GO
SELECT SomeColumn
FROM BigTable
WHERE SomeColumn IN (SELECT IntCol FROM dbo.Table1)

我们在之前讲过若是内部联接中此时会返回六条数据,因为内部联接着重强调的是JOIN后面的表,若右表有多条数据匹配上,此时则会返回多条数据,但是在IN查询中,此时只会返回五条数据,为何如此呢?
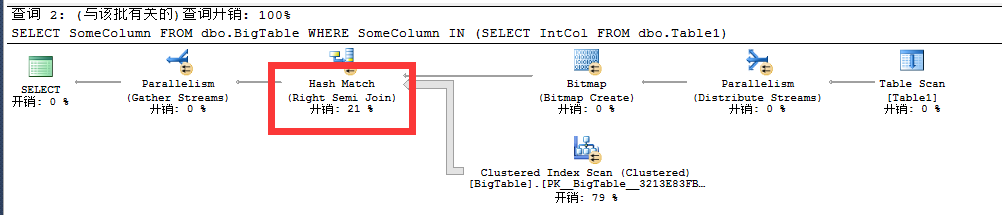
此时用IN查询时即使在子查询中有重复数据时也不会担心出问题,它会自动进行过滤处理,因为在上图中利用了Semi Join半联接中右半联接或左半联接,也就是说只返回重复的数据中的一条。那么在EXISTS中情况又是怎样呢?
SELECT SomeColumn
FROM dbo.BigTable
WHERE EXISTS (SELECT IntCol FROM dbo.Table1)
此时因为没有WHERE条件,此时会返回外部查询表中所有数据,为了和上述IN查询实现等同的结果,我们需要加上WHERE条件
USE TSQL2012
GO
SELECT SomeColumn
FROM dbo.BigTable AS bt
WHERE EXISTS (SELECT IntCol FROM dbo.Table1 AS t WHERE bt.SomeColumn = t.IntCol)
而EXISTS相对于IN来说当需要比较两个或两个以上条件时,EXISTS能更好的实现而IN就没那么容易了,比如如下
SELECT SomeColumn FROM dbo.BigTable AS bt WHERE EXISTS (SELECT IntCol FROM dbo.Table1 AS t WHERE bt.SomeColumn = t.IntCol AND bt.OtherCol = t.OtherCol)
好了,到了这里我们开始讲讲二者性能问题
进一步探讨EXISTS和IN
我们直接利用前面的表来进行查询
SELECT ID, SomeColumn FROM BigTable
WHERE SomeColumn IN (SELECT LookupColumn FROM SmallerTable)
SELECT ID, SomeColumn FROM BigTable
WHERE EXISTS (SELECT LookupColumn FROM SmallerTable WHERE SmallerTable.LookupColumn = BigTable.SomeColumn)

二者都是利用默认的聚集索引扫描和哈希匹配中的右半联接且开销一致。接下来我们再来在二者查询列上创建索引
CREATE INDEX idx_BigTable_SomeColumn
ON BigTable (SomeColumn)
CREATE INDEX idx_SmallerTable_LookupColumn
ON SmallerTable (LookupColumn)
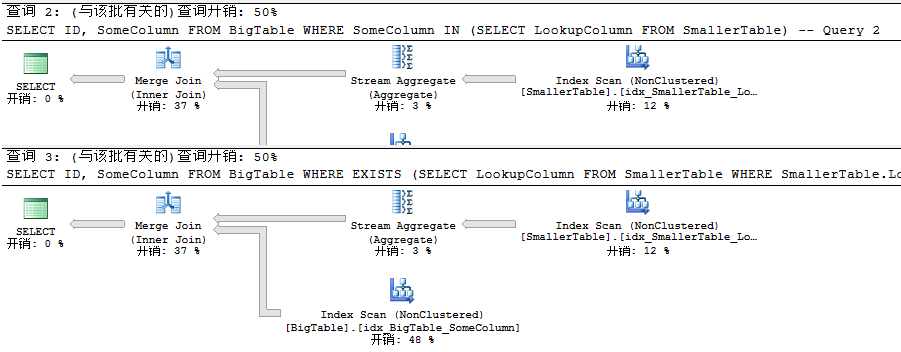
此时只是创建了索引后查询效率改善了,而且查询计划较之前只是哈希匹配中的左半联接替换成了合并联接中的内部联接,同时增加了流聚合。二者在开销上仍是一致的。在我所看其他教程中印象中一直都在说利用EXISTS代替IN,其EXISTS查询性能高于IN,而且事实却是开销一致,难道是100万数据太小,还是场景不够,还是语句不够复杂么。都在说看使用场景,那么到底是在什么场景下EXISTS比IN性能好呢,对此有更深入了解的你们,希望在评论中得到最实际的回答。而我认为觉得用EXISTS的话,只是EXISTS比IN更加灵活而已,而且不会出现意外的结果。下面我们继续往下看。
深入探讨EXISTS和IN
我们接下来看看用IN会出现什么意外的情况,我们首先创建测试表,并插入数据如下:
USE TSQL2012 GO CREATE TABLE table1 (id INT, title VARCHAR(20), someIntCol INT) GO CREATE TABLE table12 (id INT, t1Id INT, someData VARCHAR(20)) GO
插入测试数据
INSERT INTO table1 SELECT 1, 'title 1', 5 UNION ALL SELECT 2, 'title 2', 5 UNION ALL SELECT 3, 'title 3', 5 UNION ALL SELECT 4, 'title 4', 5 UNION ALL SELECT null, 'title 5', 5 UNION ALL SELECT null, 'title 6', 5 INSERT INTO table12 SELECT 1, 1, 'data 1' UNION ALL SELECT 2, 1, 'data 2' UNION ALL SELECT 3, 2, 'data 3' UNION ALL SELECT 4, 3, 'data 4' UNION ALL SELECT 5, 3, 'data 5' UNION ALL SELECT 6, 3, 'data 6' UNION ALL SELECT 7, 4, 'data 7' UNION ALL SELECT 8, null, 'data 8' UNION ALL SELECT 9, 6, 'data 9' UNION ALL SELECT 10, 6, 'data 10' UNION ALL SELECT 11, 8, 'data 11'
table1和table2中的数据分别如下:

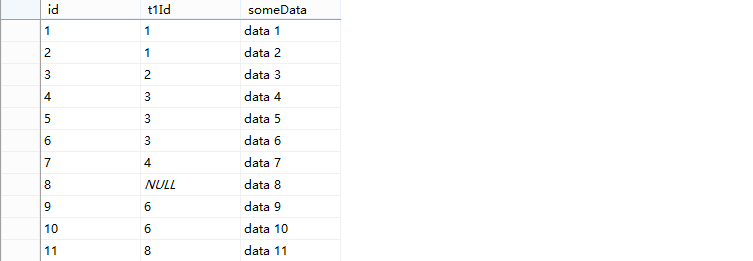
探讨一(IN查询导致错误结果)
我们来对比EXISTS和IN查询,如下:
USE TSQL2012 GO SELECT t1.* FROM dbo.table1 AS t1 WHERE t1.id IN (SELECT t1id FROM dbo.table12) SELECT t1.* FROM dbo.table1 AS t1 WHERE exists (SELECT * FROM dbo.table12 AS t2 WHERE t1.id = t2.t1id)

此时二者返回的结果都是正确,接下来我们再来看其他情况,我们需要获取所有table1中数据没有在table2中的所有行。
USE TSQL2012 GO SELECT t1.* FROM dbo.table1 AS t1 WHERE NOT EXISTS (SELECT * FROM dbo.table12 AS t2 WHERE t1.id = t2.t1id) SELECT t1.* FROM dbo.table1 as t1 WHERE t1.id NOT IN (SELECT t1id FROM dbo.table12 as t2)

此时利用EXISTS得到了正确的结果,而通过IN查询未达到我们查询的目的,原因之前也有说过IN是基于三值逻辑,此时遇到NULL则会当做UNKNOWN来处理,所以最终得到的结果集是错误的。我们继续往下探讨。
探讨2(手写错误导致意外结果)
我们重新创建测试表并插入测试数据,如下:
USE TSQL2012 GO CREATE TABLE TestTable1 (id1 int) CREATE TABLE TestTable2 (id2 int) INSERT TestTable1 VALUES(1),(2),(3) INSERT TestTable2 VALUES(1),(2)
我们首先进行如下查询:
USE TSQL2012 GO SELECT * FROM TestTable1 WHERE id1 IN (SELECT id2 FROM TestTable2)

此时结果是正确的,假如在子查询中我们将列id2写成了id1,那么情况又会是怎样的呢?
SELECT *
FROM TestTable1
WHERE id1 IN (SELECT id1 FROM TestTable2)

不知你是否注意到什么没有,表面是没什么问题,我们接着运行下上述子查询
SELECT id1 FROM TestTable2

单独运行查询时,结果居然出错了,到这了我们再看下创建的表的列,id1是在Table1中而非在Table2中,所以导致了这种意外的错误,如果手写错误,结果数据也有,一般是不会觉察不到,通过使用IN查询就导致了意外的出现。而如下利用EXISTS时会直接报错,而不是得到错误的结果集
SELECT *
FROM t1
WHERE EXISTS (SELECT * FROM TestTable2 t2 WHERE t2.id2 = t1.id1 )
当然了也有人会说根本不会犯这样低级错误,但是谁能保证呢,SQL有智能提示更加容易犯这样的错误,因为直接在子查询就会有这样的列出现,但是该列在子查询表中根本不存在。所以基于探讨的两点,利用EXISTS更加保险。到此,关于EXISTS和IN的介绍算是结束,下此结论。
EXISTS和IN性能分析结论:我们推荐使用EXISTS,而不是IN,原因不是EXISTS性能优于IN,二者性能开销是一样的,而是利用EXISTS比IN更加灵活,更加安全、保险不会出现意想不到的结果。
总结
本节我们讲解了EXISTS和IN,关于其二者在性能方面还是有点疑惑,毕竟场景不够,当然最后还是推荐使用EXISTS,而原因不在于性能。我们下节讲解LEFT JOIN和NOT EXISTS,简短的内容,深入的理解,我们下节再会。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号