
堆排序
【1】完全二叉树
在学习堆排序之前,我们先要了解一下完全二叉树。
若设二叉树的深度为h,除第h层外,其它各层 (1...h-1) 的结点数都达到最大个数,第h层所有的结点都连续集中在最左边,这就是完全二叉树。
完全二叉树特点:
(1) 满二叉树是完全二叉树,完全二叉树不一定是满二叉树。
(2) 在满二叉树的最下一层上,从最右边开始连续删去若干结点后得到的二叉树仍然是一棵完全二叉树。
(3) 在完全二叉树中,若某个结点没有左孩子,则它一定没有右孩子,即该结点必是叶结点。
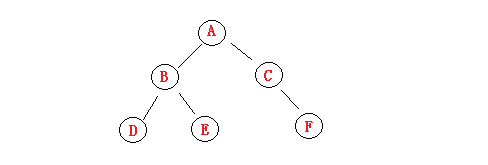
(4)如下图所示,结点C没有左孩子而有右孩子F,故它不是一棵完全二叉树。
(5)如下图所示,两棵完全二叉树(右边b为满二叉树)。
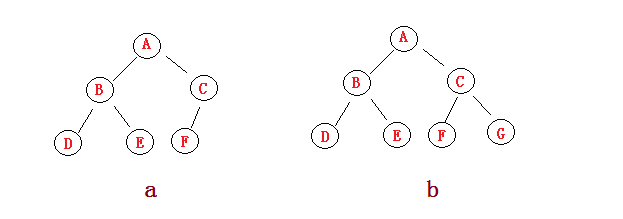
(6)下图是一棵天然的完全二叉树

【2】堆(Heap)
在程序设计领域,堆(Heap)的概念主要有以下两种:
(1)一种数据结构,逻辑上是一颗完全二叉树,存储上是一个数组对象(二叉堆)。也正是本文谈及的堆。
(2)存储区,是软件系统可以编程的内存区域(即就是动态申请的区域)。
数据结构中的堆实质上是满足一定性质的完全二叉树:二叉树中任一非叶子结点关键字的值均小于(大于)它的孩子结点的关键字。
在小根堆中,第一个元素(完全二叉树的根结点)的关键字最小;
大根堆中,第一个元素(完全二叉树的根结点)的关键字最大,
显然,堆中任一子树仍是一个堆。
假设,节点I是数组A中下标为i的节点:
那么,节点I的父节点下标为:(i-1)/2
节点I的左子节点下标为:2 * i + 1
节点I的右子节点下标为:2 * i + 2
详细图解如下存储与逻辑表示
【3】堆存储与逻辑结构表示
如下图所示:
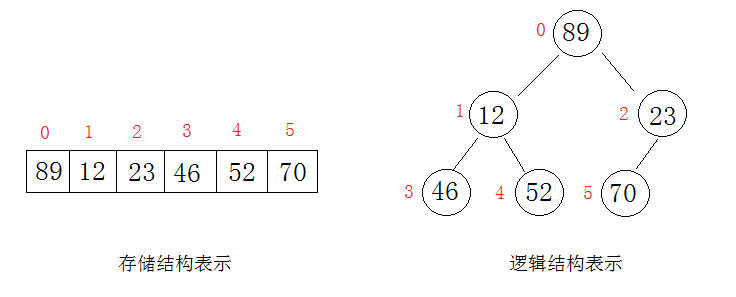
注意:示例中的逻辑结构堆不是最大堆也不是最小堆,仅仅只是为了便于理解堆的逻辑结构。
【4】堆排序定义
n个关键字序列Kl,K2,…,Kn称为堆,当且仅当该序列满足如下性质(简称为堆性质):
(1) ki ≤ K2i 且 ki ≤ K2i+1 或 (2) Ki ≥ K2i 且 ki ≥ K2i+1((i=1,2,…,[n/2],其中[]表示上取整)
若将此序列所存储的向量R[1..n]看做是一棵完全二叉树的存储结构,则堆实质上是满足如下性质的完全二叉树:
树中任一非叶结点的关键字均不大于(或不小于)其左右孩子(若存在)结点的关键字。
【5】堆排序思想
堆排序利用了大根堆(或小根堆)堆顶(根节点)记录的关键字最大(或最小)这一特征,使得在当前无序区中选取最大(或最小)关键字的记录变得简单。
(1)用大根堆排序的基本思想
<1>先将初始文件R[1.....N]建成一个大根堆,此堆为初始的无序区。
<2>再将关键字最大的记录R[1](即堆顶)和无序区的最后一个记录R[n]交换
由此得到新的无序区R[1..n-1]和有序区R[n],且满足R[1..n-1].keys ≤ R[n].key
<3>由于交换后新的根R[1]可能违反堆性质,故应将当前无序区R[1..n-1]调整为堆。
然后再次将R[1..n-1]中关键字最大的记录R[1]和该区间的最后一个记录R[n-1]交换
由此得到新的无序区R[1..n-2]和有序区R[n-1..n],且仍满足关系R[1..n-2].keys ≤ R[n-1..n].keys,同样要将R[1..n-2]调整为堆。
直到无序区只有一个元素为止。
(2)大根堆排序算法的基本操作:
<1> 初始化操作:将R[1..n]构造为初始堆;
<2>每一趟排序的基本操作:将当前无序区的堆顶记录R[1]和该区间的最后一个记录交换,然后将新的无序区调整为堆(亦称重建堆)。
注意:
<1>只需做n-1趟排序,选出较大的n-1个关键字即可以使得文件递增有序。
<2>用小根堆排序与利用大根堆类似,只不过其排序结果是递减有序的。
堆排序和直接选择排序相反:在任何时刻,堆排序中无序区总是在有序区之前,且有序区是在原向量的尾部由后往前逐步扩大至整个向量为止。
(3)排序逻辑结构演示如下图所示:

请结合以上逻辑分析内容或以下实现代码加深对堆排序的理解。
【6】堆排序实现
(1)C++实现与测试代码如下:
1 #include<iostream>
2 using namespace std;
3
4 void swap(int &a,int &b)
5 {
6 int temp = a;
7 a = b;
8 b = temp;
9 }
10
11 void PrintArr(int ar[],int n)
12 {
13 for(int i = 0; i < n; ++i)
14 cout<<ar[i]<<" ";
15 cout<<endl;
16 }
17
18 void AdjustHeap(int data[], int start, int m)
19 {
20 int i = 0, j = 0;
21 int value = data[start];
22 for(i = start, j = 2*i + 1; j <= m; i = j, j = 2*j+1)
23 {
24 cout<<"i = "<<i<<" j = "<<j<<" value = "<<value<<endl;
25 if(j < m && data[j] < data[j+1])
26 {
27 ++j;
28 }
29 if(value > data[j])
30 break;
31 else
32 data[i] = data[j];
33 PrintArr(data, 6);
34 }
35 data[i] = value;
36 PrintArr(data, 6);
37 }
38
39 void HeapSort(int data[],int size)
40 {
41 int i = 0;
42 cout<<"调整为最大堆的过程:"<<endl;
43 for(i = size/2-1; i >= 0; --i)
44 {
45 cout<<"i = "<<i<<" size = "<<size<<endl;
46 AdjustHeap(data, i, size-1);
47 }
48 cout<<"调整为最大堆结果如下:"<<endl;
49 PrintArr(data, size);
50 cout<<"整个排序过程如下:"<<endl;
51 for(i = size - 1; i >= 1; --i)
52 {
53 swap(data[0], data[i]);
54 PrintArr(data, size);
55 AdjustHeap(data, 0, i-1);
56 PrintArr(data, size);
57 }
58 }
59
60 void main()
61 {
62 int ar[] = {12, 88, 32, 5, 16, 67};
63 int len = sizeof(ar)/sizeof(int);
64 cout<<"原数据序列为:"<<endl;
65 PrintArr(ar, len);
66 HeapSort(ar, len);
67 cout<<"排序后结果如下:"<<endl;
68 PrintArr(ar, len);
69 }
70 /*
71 原数据序列为:
72 12 88 32 5 16 67
73 调整为最大堆的过程:
74 i = 2 size = 6
75 i = 2 j = 5 value = 32
76 12 88 67 5 16 67
77 12 88 67 5 16 32
78 i = 1 size = 6
79 i = 1 j = 3 value = 88
80 12 88 67 5 16 32
81 i = 0 size = 6
82 i = 0 j = 1 value = 12
83 88 88 67 5 16 32
84 i = 1 j = 3 value = 12
85 88 16 67 5 16 32
86 88 16 67 5 12 32
87 调整为最大堆结果如下:
88 88 16 67 5 12 32
89 整个排序过程如下:
90 32 16 67 5 12 88
91 i = 0 j = 1 value = 32
92 67 16 67 5 12 88
93 67 16 32 5 12 88
94 67 16 32 5 12 88
95 12 16 32 5 67 88
96 i = 0 j = 1 value = 12
97 32 16 32 5 67 88
98 32 16 12 5 67 88
99 32 16 12 5 67 88
100 5 16 12 32 67 88
101 i = 0 j = 1 value = 5
102 16 16 12 32 67 88
103 16 5 12 32 67 88
104 16 5 12 32 67 88
105 12 5 16 32 67 88
106 i = 0 j = 1 value = 12
107 12 5 16 32 67 88
108 12 5 16 32 67 88
109 5 12 16 32 67 88
110 5 12 16 32 67 88
111 5 12 16 32 67 88
112 排序后结果如下:
113 5 12 16 32 67 88
114 */
(2)堆排序代码示例:
1 void swap(int &a,int &b)
2 {
3 int temp = a;
4 a = b;
5 b = temp;
6 }
7
8 void AdjustHeap(int data[], int start, int m)
9 {
10 int i = 0, j = 0;
11 int value = data[start];
12 for(i = start, j = 2*i + 1; j <= m; i = j, j = 2*j+1)
13 {
14 if(j < m && data[j] < data[j+1])
15 {
16 ++j;
17 }
18 if(value > data[j])
19 break;
20 else
21 data[i] = data[j];
22 }
23 data[i] = value;
24
25 }
26
27 void HeapSort(int data[],int size)
28 {
29 int i = 0;
30 for(i = size/2-1; i >= 0; --i)
31 {
32 AdjustHeap(data, i, size-1);
33 }
34 for(i = size - 1; i >= 1; --i)
35 {
36 swap(data[0], data[i]);
37 AdjustHeap(data, 0, i-1);
38 }
39 }
堆排序的实现代码有很多种实现方式,在此仅作为参考。
【7】堆排序分析
堆排序的时间,主要由建立初始堆和反复重建堆这两部分的时间开销构成,它们均是通过调用堆调整函数实现的。
堆排序的最坏时间复杂度为O(nlgn)(参见随笔《算法复杂度》)。堆排序的平均性能较接近于最坏性能。
由于建初始堆所需的比较次数较多,所以堆排序不适宜于记录数较少的文件。
堆排序是就地排序,辅助空间为O(1)。
它是不稳定的排序方法(参见随笔《常用排序算法稳定性分析》)。
Good Good Study, Day Day Up.
顺序 选择 循环 坚持 总结
