


python数据分析笔记(自学)
1.python range() 函数可创建一个整数列表,一般用在 for 循环中。
函数语法
range(start, stop[, step])
参数说明:
- start: 计数从 start 开始。默认是从 0 开始。例如range(5)等价于range(0, 5);
- stop: 计数到 stop 结束,但不包括 stop。例如:range(0, 5) 是[0, 1, 2, 3, 4]没有5
- step:步长,默认为1。例如:range(0, 5) 等价于 range(0, 5, 1)
实例
>>>range(10) # 从 0 开始到 10
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> range(1, 11) # 从 1 开始到 11
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
>>> range(0, 30, 5) # 步长为 5
[0, 5, 10, 15, 20, 25]
>>> range(0, 10, 3) # 步长为 3
[0, 3, 6, 9]
>>> range(0, -10, -1) # 负数
[0, -1, -2, -3, -4, -5, -6, -7, -8, -9]
>>> range(0)
[]
>>> range(1, 0)
[]
以下是 range 在 for 中的使用,循环出runoob 的每个字母:
>>>x = 'runoob'
>>> for i in range(len(x)) :
... print(x[i])
...
r
u
n
o
o
b
>>>
2.numpy常用函数之randn
numpy.random.randn(d0, d1, ..., dn)
这个函数的作用就是从标准正态分布中返回一个或多个样本值。什么是标准正态分布,大哥,你别吓我,上过高中吗?标准正态分布俗称高斯分布,正态分布是大自然中最常见的分布,标准正态分布就是期望为0,方差为1的正态分布。
如果没有参数,则返回一个值,如果有参数,则返回(d0, d1, …, dn)个值,这些值都是从标准正态分布中随机取样得到的。
d0, d1, …, dn都应该是整数,是浮点数也没关系,系统会自动把浮点数的整数部分截取出来。
参数
-
d0, d1, …, dn:应该为正整数,表示维度。
返回值
-
Z:ndarray或者float。
看几个例子吧:
np.random.randn()
返回:
-0.8405297****8702
再比如:
2.5 * np.random.randn(2, 4) + 3
返回:
array([[ 4.128****53, 1.764****44 , 2.732****92, 2.90839231],
[ 0.174****86, 4.92026887, 1.574****66, -0.4305991 ]])
3.numpy中的mean()函数
mean() 函数定义:
numpy.mean(a, axis, dtype, out,keepdims )
mean()函数功能:求取均值
经常操作的参数为axis,以m * n矩阵举例:
- axis 不设置值,对 m*n 个数求均值,返回一个实数
- axis = 0:压缩行,对各列求均值,返回 1* n 矩阵
- axis =1 :压缩列,对各行求均值,返回 m *1 矩阵
例子:
1. 数组的操作:
>>> a = np.array([[1, 2], [3, 4]])
>>> a
array([[1, 2],
[3, 4]])
>>> np.mean(a)
2.5
>>> np.mean(a, axis=0) # axis=0,计算每一列的均值
array([ 2., 3.])
>>> np.mean(a, axis=1) # 计算每一行的均值
array([ 1.5, 3.5])
>>>
2.矩阵的操作:
>>> import numpy as np
>>> num1 = np.array([[1,2,3],[2,3,4],[3,4,5],[4,5,6]])
>>> num1
array([[1, 2, 3],
[2, 3, 4],
[3, 4, 5],
[4, 5, 6]])
>>> num2 = np.mat(num1)
>>> num2
matrix([[1, 2, 3],
[2, 3, 4],
[3, 4, 5],
[4, 5, 6]])
>>> np.mean(num2) # 对所有元素求均值
3.5
>>> np.mean(num2,0) # 压缩行,对各列求均值
matrix([[ 2.5, 3.5, 4.5]])
>>> np.mean(num2,1) # 压缩列,对各行求均值
matrix([[ 2.],
[ 3.],
[ 4.],
[ 5.]])
>>>
4.NumPy中dot()函数的理解
一、dot()的使用
参考文档:https://docs.scipy.org/doc/numpy/reference/generated/numpy.dot.html
dot()返回的是两个数组的点积(dot product)
1.如果处理的是一维数组,则得到的是两数组的內积(顺便去补一下数学知识)
In : d = np.arange(0,9)
Out: array([0, 1, 2, 3, 4, 5, 6, 7, 8])
In : e = d[::-1]
Out: array([8, 7, 6, 5, 4, 3, 2, 1, 0])
In : np.dot(d,e)
Out: 84
2.如果是二维数组(矩阵)之间的运算,则得到的是矩阵积(mastrix product)。
In : a = np.arange(1,5).reshape(2,2)
Out:
array([[1, 2],
[3, 4]])
In : b = np.arange(5,9).reshape(2,2)
Out: array([[5, 6],
[7, 8]])
In : np.dot(a,b)
Out:
array([[19, 22],
[43, 50]])
所得到的数组中的每个元素为,第一个矩阵中与该元素行号相同的元素与第二个矩阵与该元素列号相同的元素,两两相乘后再求和。
这句话有点难理解,但是这句话里面没有哪个字是多余的。结合下图理解这句话。
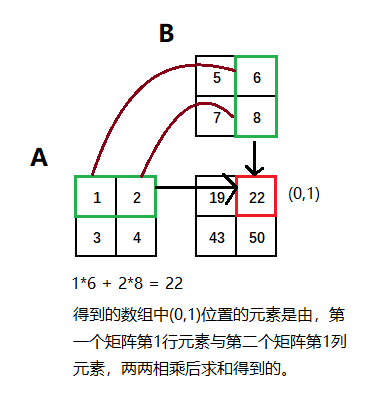
3.dot()函数可以通过numpy库调用,也可以由数组实例对象进行调用。a.dot(b) 与 np.dot(a,b)效果相同。
矩阵积计算不遵循交换律,np.dot(a,b) 和 np.dot(b,a) 得到的结果是不一样的。
5.numpy.random.randint()
官方文档中给出的用法是:numpy.random.randint(low,high=None,size=None,dtype)
low、high、size三个参数。默认high是None,如果只有low,那范围就是[0,low)。如果有high,范围就是[low,high)。
>>> np.random.randint(2, size=10)
array([1, 0, 0, 0, 1, 1, 0, 0, 1, 0])
>>> np.random.randint(1, size=10)
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0])
>>> np.random.randint(5, size=(2, 4))
array([[4, 0, 2, 1],
[3, 2, 2, 0]])
6.Pandas 数据导入问题
在pandas中数据导入有对应的模块;本节解决三个关键问题:
(1)路径斜线问题;
(2)中文路径问题;
(3)编码问题;
正常导入见下,若没问题则完事大吉,但往往没这么顺利。
1、导入路径斜线问题
当错误类型如下,则一般是路径斜线问题。
ValueError: stat: embedded null character in path
在win中的直接复制的路径,斜线默认是“\”;但在python中路径一般首选是“/”;有3种合理解决方案:
file_path1 = 'D:/0Raw_data/ftm_p.csv'
file_path2 = 'D:\\0Raw_data\\ftm_p.csv'
file_path3 = r'D:\0Raw_data\ftm_p.csv'
2、中文路径问题
当错误类型如下,则一般是中文路径问题。
OSError: Initializing from file failed
不废话,解决方案就是先用open打开,而且一般用open先打开,能直接解决编码问题:
file_path = 'D:/0Raw_data/zhaoyang_charge_sta/京AW7531'
path = open(file_path)
data = pd.read_csv(path)
3、编码问题
当错误类型如下,则一般是编码问题。panda读取时会先检测第一个字符的编码类型,若不是'utf-8'则会报错。
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xb9 in position 0: invalid start byte
还是不废话,直接解决方案:
解决方案1,用open,请注意报错问题,可以合理配置encoding,在中国一般就为'utf-8'或者'gbk'。
import pandas as pd
file_path = 'D:/0Raw_data/zhaoyang_charge_sta/京AW7531'
f = open(file_path,encoding='utf-8')
data = pd.read_csv(f)
f.close()
解决方案2,配置pandas的encoding;
import pandas as pd
file_path = 'D:/0Raw_data/zhaoyang_charge_sta/京AW7531'
data = pd.read_csv('D:/0Raw_data/ftm_p.csv',encoding='gbk')


 浙公网安备 33010602011771号
浙公网安备 33010602011771号