

SQL2005性能分析一些细节功能你是否有用到?(三)
继上篇: SQL2005性能分析一些细节功能你是否有用到?(二)
第一: SET STATISTICS PROFILE ON
当我们比较查询计划中那一个最好时,事实上我们更愿意用SET STATISTICS PROFILE ON,而不是SET SHOWPLAN_TEXT ON。它可以告诉你每种选择的或多或少的查询消耗情况;你还可以同时运行两个或更多查询来看哪个执行的最好。
运行SET STATISTICS PROFILE ON 后,发出现很多信息,这里以stmtText来说明下:
StmtText:
select * from
(
select *,
row_number() over (order by card_no desc) as RowNum
from tblName
) as tbl
where RowNum between 1 and 20
|--Filter(WHERE:([Expr1003]>=(1) AND [Expr1003]<=(20)))
|--Top(TOP EXPRESSION:(CASE WHEN (20) IS NULL OR (20)<(0) THEN (0) ELSE (20) END))
|--Sequence Project(DEFINE:([Expr1003]=row_number))
|--Compute Scalar(DEFINE:([Expr1007]=(1)))
|--Segment
|--Nested Loops(Inner Join, OUTER REFERENCES:([bdg_retail].[dbo].[Card_Ext].[Id], [Expr1005]) WITH ORDERED PREFETCH)
|--Index Scan(OBJECT:([bdg_retail].[dbo].[Card_Ext].[IX_Card_ext_Card_No]), ORDERED BACKWARD)
|--Clustered Index Seek(OBJECT:([bdg_retail].[dbo].[Card_Ext].[PK_CARD_EXT]), SEEK:([bdg_retail].[dbo].[Card_Ext].
[Id]=[bdg_retail].[dbo].[Card_Ext].[Id]) LOOKUP ORDERED FORWARD)
除了显示出当前SQL语句外,还详细的给出了实际运行的情况,怎样查找索引,怎样扫描表,又是怎样排序等等.
Nested Loops:嵌套查询;
Index Scan:索引查找;
Clustered Index Seek:聚集索引查找
第二:sp_spaceused
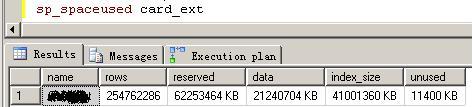
作用:获得表大小的统计信息以供我们分析:
案例:
sp_spaceused employees
Results:
name rows reserved data index_size unused
-------------- -------- --------- ------- -------------- ---------
Employees 2977 2008KB 1504KB 448KB 56KB
效果图:
返回内容说明:
Name 为其请求空间使用信息的表名。
Rows 表中现有的行数。
reserved 表保留的空间总量。
Data 表中的数据所使用的空间量。
index_size 表中的索引所使用的空间量。
Unused 表中未用的空间量。
备注: sp_spaceused 计算数据和索引使用的磁盘空间量以及当前数据库中的表所使用的磁盘空间量。如果没有给定 objname,sp_spaceused 则报告整个当前数据库所使用的空间。
权限:执行权限默认授予 public 角色。
第三:SQL2005 中的排名函数row_number()
分页算法有很多种,这里我想说一下我一直在用的分页方法,SQL2005的新特性:排名函数中的row_number()
ROW_NUMBER (Transact-SQL)
定义: 返回结果集分区内行的序列号,每个分区的第一行从 1 开始。
语法:ROW_NUMBER ( ) OVER ( [ <partition_by_clause> ] <order_by_clause> )
参数:1:<partition_by_clause>:将 FROM 子句生成的结果集划入应用了 ROW_NUMBER 函数的分区。
2:<order_by_clause>:确定将 ROW_NUMBER 值分配给分区中的行的顺序。有关详细信息,请参阅 ORDER BY 子句 (Transact-SQL)。当在排名函数中使用 <order_by_clause> 时,不能用整数表示列。
返回类型:bigint
备注:ORDER BY 子句可确定在特定分区中为行分配唯一 ROW_NUMBER 的顺序。
本节意图:以前我一直有一个误区,就是认为只要是分页时按需所取(查询第几页就取第只取几页的数据),效率就会特别高,后来用上了IO分析,才知道并不像我想像中的那样完美(取任何一页速度都是一样快).
案例:
--取第一页
(20 row(s) affected)
Table 'Card_Ext'. Scan count 1, logical reads 92, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
--取第一百页
(20 row(s) affected)
Table 'Card_Ext'. Scan count 1, logical reads 8157, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
--取第一万页
(20 row(s) affected)
Table 'Card_Ext'. Scan count 1, logical reads 81322, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
解决方案:大数据分页中,无论你采用什么样的分页算法,都会出现性能瓶颈,所以可以采用top n的方法来折中一下:当实际查询结果特别多时,只选取前n条.
本节结论: 上面的结果都是在已经有数据缓存的情况下运行的结果,所以只看到了逻辑读,并没有出现物理读取的记录.记录显示,逻辑读数量在不断变化,根据用户取的页数大小成倍增加,也就是说与页数大小成正比.原因是row_number()的产生是在数据全部查询出来后再按照排序顺序从一开始生成的,所以它要把页数之前的所有数据都先装成内存,才能生成.
这样就非常直接的回答了为什么取数据越到最后速度越慢的原因了.
顺便说下在运用sp_help命令时,是不能同时运行执行计划的.否则会报这样的错:Msg 262, Level 14, State 4, Procedure sp_help, Line 88 SHOWPLAN permission denied in database 'master'.
总结:性能调优是一项特别细的工作,往往更改一个小小的语句性能就会发生翻天覆地的变化;要在不断的实践中总结经验。
注:
本文引用:MSDN

 浙公网安备 33010602011771号
浙公网安备 33010602011771号