
爬虫入门(四)——Scrapy框架入门:使用Scrapy框架爬取全书网小说数据
为了入门scrapy框架,昨天写了一个爬取静态小说网站的小程序
下面我们尝试爬取全书网中网游动漫类小说的书籍信息。
一、准备阶段
明确一下爬虫页面分析的思路:
对于书籍列表页:我们需要知道打开单本书籍的地址、以及获取点开下一页书籍列表页的链接
对于书籍信息页面,我们需要找到提取:(书名、作者、书本简介、书本连载状态)这四点信息
爬虫流程:书籍列表页中点开一本书→提取每一本书的书籍信息;当一页书籍列表页的书籍全部被采集以后,按照获取的下一页链接打开新的商户及列表页→点开一本书的信息→提取每一本书的信息……
二、页面分析
首先,我们先对爬取数据要打开的第一页页面进行分析。
除了使用开发者工具以外,我们还可以使用scrapy shell <url>命令,可以进行前期的爬取实验,从而提高开发的效率。
首先打开cmd(前提必须是安装好了scrapy~,这里就不说怎么按照scrapy了)
输入scrapy shell +<要分析的网址>
可以得到一个这样的结果
运行完这条命令以后,scrapy shell 会用url参数构造一个request对象,并且提交给scrapy引擎,页面下载完以后程序进入一个pyhon shell中,我们可以调用view函数使用浏览器显示response所包含的页面

*进行页面分析的时候view函数解析的页更加可靠。
弹出页面如下:

通过观察源代码,可以发现所有书籍link信息前缀为"http://www.quanshuwang.com/book_"
此时我们可以尝试在scrapy shell中提取这些信息
这里使用LinkExtractor提取这些链接
在scrapy shell 输入信息与展示信息如下:

随后我们寻找下一页标签的链接,查看源代码可以发现在一个class 为next的a标签中

在scrapy shell中尝试提取,发现可以成功提取到目的link

接下来分析单页书籍信息
处理思路和分析书籍页面信息一样,获取网页
在shell中通过fetch函数下载书籍信息页面,然后再通过view函数在浏览器中查看该页面

通过查看网页源代码,发现所有数据包含在class为detail的div模块中。
接下来使用response.css或者response.xpath对数据进行提取
在scrapy shell中尝试如下:(这里只举一个例子,其他的可以自己类似尝试)

逐一确定其他目的提取元素的方式以后,可以开始进行正式的编码实现
三、编码实现
首先,我们在cmd中进到目的python目录中,创建一个scrapy项目
代码如下:

而后进入到创建的新scrapy项目目录下,新建spider文件

运行以后,scrapy genspider命令创建了文件fiction/spiders/fictions.py,并且创建了相应的spider类
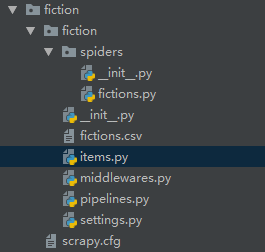
总体文件项如图:(其中,fictions.csv是后面进行爬虫的时候生成的)
接下来我们可以对“框架”按照我们前面的需求进行改写
①首先改写Item项目
在fiction/items.py中修改代码如下
1 # -*- coding: utf-8 -*- 2 3 # Define here the models for your scraped items 4 # 5 # See documentation in: 6 # https://doc.scrapy.org/en/latest/topics/items.html 7 8 import scrapy 9 10 11 class FictionItem(scrapy.Item): 12 # define the fields for your item here like: 13 # name = scrapy.Field() 14 15 bookname = scrapy.Field() 16 statement = scrapy.Field() 17 author = scrapy.Field() 18 simple_content = scrapy.Field() 19 20 21 pass
②实现页面解析函数
修改fiction/spiders/fictions.py代码如下(具体分析前面已经讨论,注释见详细代码)
1 # -*- coding: utf-8 -*- 2 import scrapy 3 from scrapy.linkextractors import LinkExtractor 4 from ..items import FictionItem 5 6 7 class FictionsSpider(scrapy.Spider): 8 name = 'fictions' 9 allowed_domains = ['quanshuwang.com'] 10 start_urls = ['http://www.quanshuwang.com/list/8_1.html'] 11 12 # 书籍列表的页面解析函数 13 def parse(self,response): 14 # 提取书籍列表页面每一本书的链接 15 pattern = 'http://www.quanshuwang.com/book_' 16 le = LinkExtractor(restrict_xpaths='//*[@class="seeWell cf"]',allow=pattern) 17 for link in le.extract_links(response): 18 yield scrapy.Request(link.url,callback=self.parse_book) 19 20 # 提取下一页链接 21 le = LinkExtractor(restrict_xpaths='//*[@id="pagelink"]/a[@class="next"]') 22 links = le.extract_links(response) 23 if links: 24 next_url = links[0].url 25 yield scrapy.Request(next_url,callback=self.parse) 26 27 pass 28 29 30 # 书籍界面的解析函数 31 def parse_book(self, response): 32 book=FictionItem() 33 sel = response.css('div.detail') 34 book['bookname']=sel.xpath('./div[1]/h1/text()').extract_first() 35 book['statement']=sel.xpath('//*[@id="container"]/div[2]/section/div/div[4]/div[1]/dl[1]/dd/text()').extract_first() 36 book['author']=sel.xpath('//*[@id="container"]/div[2]/section/div/div[4]/div[1]/dl[2]/dd/text()').extract_first() 37 book['simple_content']=sel.xpath('string(//*[@id="waa"])').extract() 38 39 yield book
③设置参数防止存储数据乱码
在setting.py中加上这个代码
1 FEED_EXPORT_ENCODING = 'utf-8'
④命令行中调用(要进入到/fiction/fiction中(与setting.py同级目录)才能调用)
在cmd输入代码如下
scrapy crawl books -o fiction.csv
就可以调用我们写的爬虫程序进行数据爬取啦!!!
最后贴个爬下来的数据的图


