
python学习笔记:"爬虫+有道词典"实现一个简单的英译汉程序
1.有道的翻译
网页: www.youdao.com

Fig1

Fig2
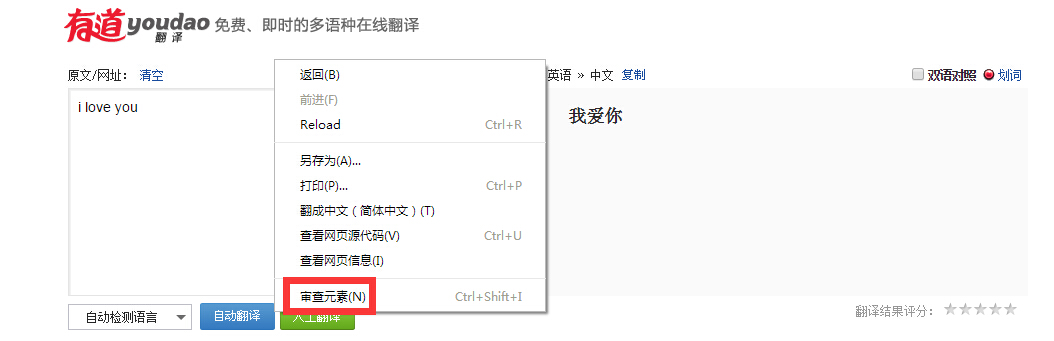
Fig3

Fig4
再次点击"自动翻译"->选中'Network'->选中'第一项',如下:

Fig5
然后显示出如下内容,红框画出的部分是等会编写代码需要的地方:

Fig6
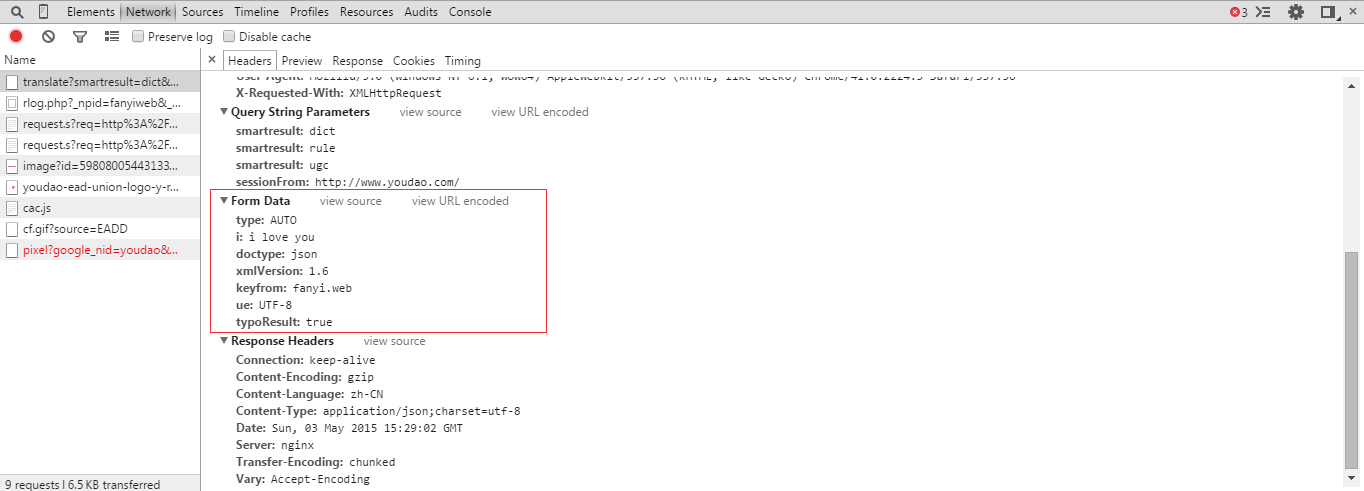
Fig7
再看看翻译的结果:

Fig8
2.python实现英译汉:
原理:把需要翻译的内容输入给有道词典,然后通过程序把翻译的结果爬下来。
1 # -*- coding:utf-8 -*-
2 """
3 Created on Sun May 03 09:36:12 2015
4
5 @author: 90Zeng
6 """
7
8 import urllib
9 import json
10
11 # 注意这里用unicode编码,否则会显示乱码
12 content = input(u"请输入要翻译的内容:")
13 # 网址是Fig6中的 Response URL
14 url = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&smartresult=ugc&sessionFrom=http://www.youdao.com/'
15 # 爬下来的数据 data格式是Fig7中的 Form Data
16 data = {}
17 data['type'] = 'AUTO'
18 data['i'] = content
19 data['doctype'] = 'json'
20 data['xmlVersion'] = '1.6'
21 data['keyfrom'] = 'fanyi.web'
22 data['ue'] = 'UTF-8'
23 data['typoResult'] = 'true'
24
25 # 数据编码
26 data = urllib.urlencode(data)
27
28 # 按照data的格式从url爬内容
29 response = urllib.urlopen(url, data)
30 # 将爬到的内容读出到变量字符串html,
31 html = response.read()
32 # 将字符串转换成Fig8所示的字典形式
33 target = json.loads(html)
34 # 根据Fig8的格式,取出最终的翻译结果
35 result = target["translateResult"][0][0]['tgt']
36
37 # 这里用unicode显示中文,避免乱码
38 print(u"翻译结果:%s" % (target["translateResult"][0][0]['tgt']))
运行:


学习资料来源:小甲鱼的视频‘零基础入门python’
请尊重原创知识,本人非常愿意与大家分享
转载请注明出处:http://www.cnblogs.com/90zeng/
作者:博客园-90Zeng
