



简易解说拉格朗日对偶(Lagrange duality)
引言:尝试用最简单易懂的描述解释清楚机器学习中会用到的拉格朗日对偶性知识,非科班出身,如有数学专业博友,望多提意见!
1.原始问题
假设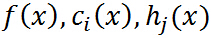 是定义在
是定义在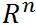 上的连续可微函数(为什么要求连续可微呢,后面再说,这里不用多想),考虑约束最优化问题:
上的连续可微函数(为什么要求连续可微呢,后面再说,这里不用多想),考虑约束最优化问题:
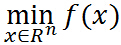
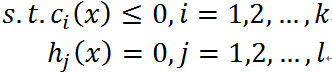
称为约束最优化问题的原始问题。
现在如果不考虑约束条件,原始问题就是:
因为假设其连续可微,利用高中的知识,对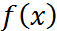 求导数,然后令导数为0,就可解出最优解,很easy. 那么,问题来了(呵呵。。。),偏偏有约束条件,好烦啊,要是能想办法把约束条件去掉就好了,bingo! 拉格朗日函数就是干这个的。
求导数,然后令导数为0,就可解出最优解,很easy. 那么,问题来了(呵呵。。。),偏偏有约束条件,好烦啊,要是能想办法把约束条件去掉就好了,bingo! 拉格朗日函数就是干这个的。
引进广义拉格朗日函数(generalized Lagrange function):
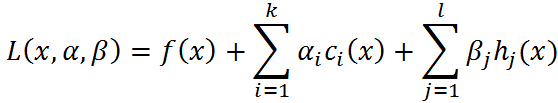
不要怕这个式子,也不要被拉格朗日这个高大上的名字给唬住了,让我们慢慢剖析!这里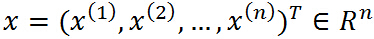 ,
,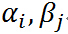 是拉格朗日乘子(名字高大上,其实就是上面函数中的参数而已),特别要求
是拉格朗日乘子(名字高大上,其实就是上面函数中的参数而已),特别要求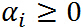 .
.
现在,如果把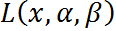 看作是关于的函数,要求其最大值,即
看作是关于的函数,要求其最大值,即
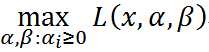
再次注意是一个关于的函数,经过我们优化(不要管什么方法),就是确定的值使得取得最大值(此过程中把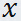 看做常量),确定了的值,就可以得到的最大值,因为已经确定,显然最大值就是只和有关的函数,定义这个函数为:
看做常量),确定了的值,就可以得到的最大值,因为已经确定,显然最大值就是只和有关的函数,定义这个函数为:
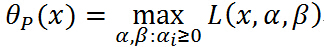
其中
下面通过是否满足约束条件两方面来分析这个函数:
- 考虑某个
![]() 违反了原始的约束,即
违反了原始的约束,即![]() 或者
或者![]() ,那么:
,那么:
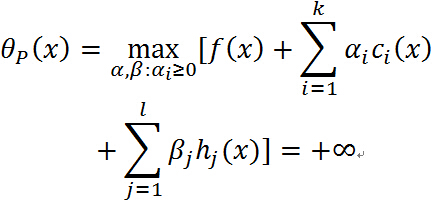
注意中间的最大化式子就是确定的之后的结果,若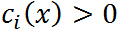 ,则令
,则令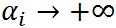 ,如果
,如果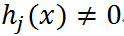 ,很容易取值
,很容易取值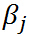 使得
使得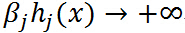
- 考虑
![]() 满足原始的约束,则:
满足原始的约束,则:![]() ,注意中间的最大化是确定
,注意中间的最大化是确定![]() 的过程,
的过程,![]() 就是个常量,常量的最大值显然是本身.
就是个常量,常量的最大值显然是本身.
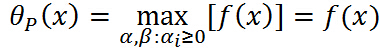 ,注意中间的最大化是确定
,注意中间的最大化是确定
通过上面两条分析可以得出:

那么在满足约束条件下:
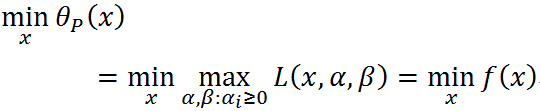
即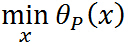 与原始优化问题等价,所以常用代表原始问题,下标 P 表示原始问题,定义原始问题的最优值:
与原始优化问题等价,所以常用代表原始问题,下标 P 表示原始问题,定义原始问题的最优值:
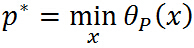
原始问题讨论就到这里,做一个总结:通过拉格朗日这位大神的办法重新定义一个无约束问题(大家都喜欢无拘无束),这个无约束问题等价于原来的约束优化问题,从而将约束问题无约束化!
2.对偶问题
定义关于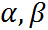 的函数:
的函数:
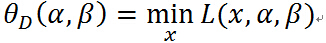
注意等式右边是关于的函数的最小化,确定以后,最小值就只与有关,所以是一个关于的函数.
考虑极大化,即
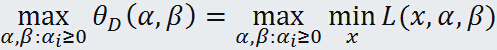
这就是原始问题的对偶问题,再把原始问题写出来:
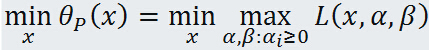
形式上可以看出很对称,只不过原始问题是先固定中的,优化出参数,再优化最优,而对偶问题是先固定,优化出最优,然后再确定参数.
定义对偶问题的最优值:
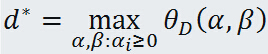
3. 原始问题与对偶问题的关系
定理:若原始问题与对偶问题都有最优值,则
证明:对任意的和,有
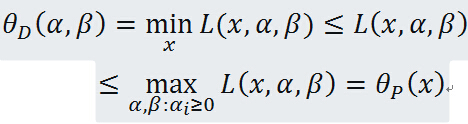
即

由于原始问题与对偶问题都有最优值,所以
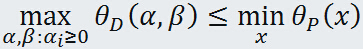
即
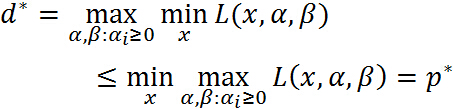
也就是说原始问题的最优值不小于对偶问题的最优值,但是我们要通过对偶问题来求解原始问题,就必须使得原始问题的最优值与对偶问题的最优值相等,于是可以得出下面的推论:
推论:设
分别是原始问题和对偶问题的可行解,如果
,那么
分别是原始问题和对偶问题的最优解。
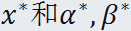 分别是原始问题和对偶问题的可行解,如果
分别是原始问题和对偶问题的可行解,如果所以,当原始问题和对偶问题的最优值相等: 时,可以用求解对偶问题来求解原始问题(当然是对偶问题求解比直接求解原始问题简单的情况下),但是到底满足什么样的条件才能使的呢,这就是下面要阐述的 KKT 条件
时,可以用求解对偶问题来求解原始问题(当然是对偶问题求解比直接求解原始问题简单的情况下),但是到底满足什么样的条件才能使的呢,这就是下面要阐述的 KKT 条件
4. KKT 条件
定理:对于原始问题和对偶问题,假设函数
和
是凸函数,
是仿射函数(即由一阶多项式构成的函数,f(x)=Ax + b, A是矩阵,x,b是向量);并且假设不等式约束
是严格可行的,即存在
,对所有
有
,则存在
,使得
是原始问题的最优解,
是对偶问题的最优解,并且
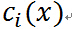 是凸函数,
是凸函数,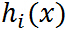 是仿射函数(即由一阶多项式构成的函数,f(x)=Ax + b, A是矩阵,x,b是向量);并且假设不等式约束
是仿射函数(即由一阶多项式构成的函数,f(x)=Ax + b, A是矩阵,x,b是向量);并且假设不等式约束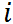 有
有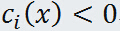 ,则存在
,则存在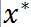 是原始问题的最优解,
是原始问题的最优解,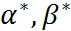 是对偶问题的最优解,并且
是对偶问题的最优解,并且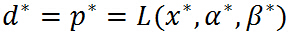
定理:对于原始问题和对偶问题,假设函数
和
是凸函数,
是仿射函数(即由一阶多项式构成的函数,f(x)=Ax + b, A是矩阵,x,b是向量);并且假设不等式约束
是严格可行的,即存在
,对所有
有
,则
分别是原始问题和对偶问题的最优解的充分必要条件是
满足下面的Karush-Kuhn-Tucker(KKT)条件:
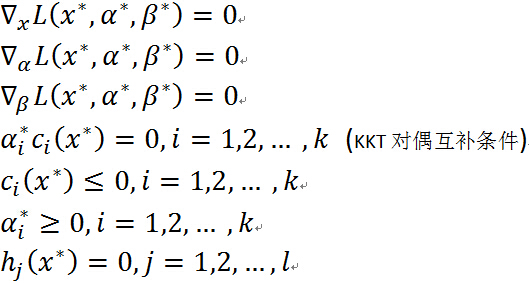
关于KKT 条件的理解:前面三个条件是由解析函数的知识,对于各个变量的偏导数为0(这就解释了一开始为什么假设三个函数连续可微,如果不连续可微的话,这里的偏导数存不存在就不能保证),后面四个条件就是原始问题的约束条件以及拉格朗日乘子需要满足的约束。
特别注意当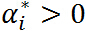 时,由KKT对偶互补条件可知:
时,由KKT对偶互补条件可知: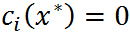 ,这个知识点会在 SVM 的推导中用到.
,这个知识点会在 SVM 的推导中用到.
5. 总结
一句话,某些条件下,把原始的约束问题通过拉格朗日函数转化为无约束问题,如果原始问题求解棘手,在满足KKT的条件下用求解对偶问题来代替求解原始问题,使得问题求解更加容易。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号