

2017-2018-1 20155222 《信息安全系统设计基础》第十四周学习总结
2017-2018-1 20155222 第十四周 深入理解计算机系统第十二章--并发编程
知识点总结
-
并发的定义
如果逻辑控制流在时间上重叠,那么他们就是并发的。 -
应用级并发的作用
- 访问慢速I/O设备。
当一个应用正在等待来自慢速I/U设备(例如磁盘)的数据到达时,内核会运行其他进程,使CPU保持繁忙。每个应用都可以按照类似的方式,通过交替执行I/O请求和其他有用的工作来利用并发。 - 与人交互。
和计算机交互的人要求计算机有同时执行多个任务的能力。例如,他们在打印一个文档时,可能想要调整一个窗口的大小。现代视窗系统利用并发来提供这种能力。每次用户请求某种操作(比如通过单击鼠标)时,一个独立的并发逻辑流被创建来执行这个操作。 - 通过推迟工作以降低延迟。
有时,应用程序能够通过推迟其他操作和并发地执行它们,利用并发来降低某些操作的延迟。比如,一个动态内存分配器可以通过推迟合并,把它放到一个运行在较低优先级上的并发“合并”流中,在有空闲的CPU周期时充分利用这些空闲周期,从而降低单个free操作的延迟。 - 服务多个网络客户端。
我们在第11章中学习的迭代网络服务器是不现实的,因为它们一次只能为一个客户端提供服务。因此,一个慢速的客户端可能会导致服务器拒绝为所有其他客户端服务。对于一个真正的服务器来说,可能期望它每秒为成百上千的客户端提供服务,由于一个慢速客户端导致拒绝为其他客户端服务,这是不能接受的。一个更好的方法是创建一个并发服务器,它为每个客户端创建一个单独的逻辑流。这就允许服务器同时为多个客户端服务,并且也避免了慢速客户端独占服务器。 - 在多核机器上进行并行计算。
许多现代系统都配备多核处理器,多核处理器中包含有多个CPU。被划分成并发流的应用程序通常在多核机器上比在单处理器机器上运行得快,因为这些流会并行执行,而不是交错执行。使用应用级并发的应用程序称为并发程序(concurrent program)。现代操作系统提供了三种基本的构造并发程序的方法: - 进程。
用这种方法,每个逻辑控制流都是一个进程,由内核来调度和维护。因为进程有独立的虚拟地址空间,想要和其他流通信,控制流必须使用某种显式的进程间通信(interprocess communication, IPC)机制。 - I/O多路复用。
在这种形式的并发编程中,应用程序在一个进程的上下文中显式地调度它们自己的逻辑流。逻辑流被模型化为状态机,数据到达文件描述符后,主程序显式地从一个状态转换到另一个状态。因为程序是一个单独的进程,所以所有的流都共享同一个地址空间。 - 线程。
线程是运行在一个单一进程上下文中的逻辑流,由内核进行调度。你可以把线程看成是其他两种方式的混合体,像进程流一样由内核进行调度,而像I/O多路复用流一样共享同一个虚拟地址空间。本章研究这三种不同的并发编程技术。为了使我们的讨论比较具体,我们始终以同一个应用为例—11. 4. 9节中的迭代ech。服务器的并发版本。
- 访问慢速I/O设备。
-
基于进程的并发编程
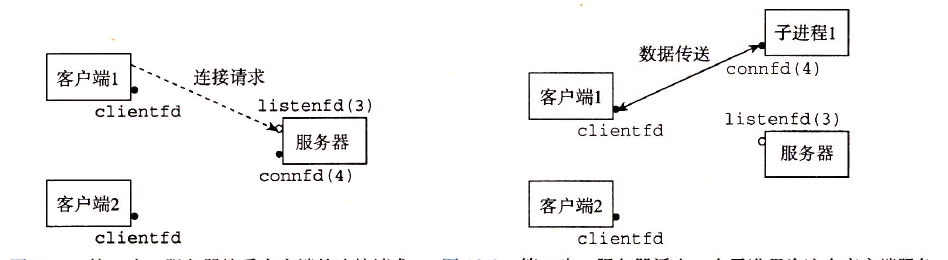
构造并发程序最简单的方法就是用进程,使用那些大家都很熟悉的函数,像fork,exec和waitpid。例如,一个构造并发服务器的自然方法就是,在父进程中接受客户端连接请求,然后创建一个新的子进程来为每个新客户端提供服务。
![]()
![]()
-
基于I/O多路复用的并发编程
假设要求你编写一个echo服务器,它也能对用户从标准输人键人的交互命令做出响应。在这种情况下,服务器必须响应两个互相独立的I/O事件:1>网络客户端发起连接请求,2)用户在键盘上键人命令行。-
使用以前学过的阻塞socket()
大致代码如下while(1) { accept(); //调用accept()函数阻塞的等待请求连接事件 read(); //调用read函数阻塞的等待输入事件 }或者
while(1) { read(); //调用read函数阻塞的等待输入事件 accept(); //调用accept()函数阻塞的等待请求连接事件 }这么做会产生一个问题,在使用第一段代码的情况下,如果有一个输入事件先到来,那么服务器将不能响应处理,因为它被阻塞在accept()函数了。而如果使用第二段代码的情况下,如果一个客户端请求连接,那么服务器将无法处理,因为它被阻塞在read()函数。
-
使用I/O多路复用技术
大致代码如下:/*将所有可能被改变的描述符放到一个集合中,你只能对描述符进行三种操作:1)分配他们 ;2)将一个此种类型的变量复制给另一个变量;3)用FD_ZERO、FD_SET、FD_CLR、FD_ISSET宏指令来修改他们*/ fd_set read_set ; //定义一个“读集合” fd_set ready_set; //定义读集合的一个子集“就绪集合” FD_ZERO(&read_set); //将读集合清空 FD_SET(STDIN_FILENO,&read_set); //将标准输入描述符加入“读集合” FD_SET(listenfd,&read_set); //将监听描述符加入“读集合” while(1) { ready_set=read_set; /*先将read_set的内容复制到ready_set中,因为接下来的Select函数会修改其中一个参数——描述符集合的指针,转而指向他的一个子集称为“就绪集合”,这个集合是由“读集合”中准备好可以读的描述符组成的,因此不能直接把“读集合”的指针作为参数放到函数Select中,否则将失去这个集合,并且我们还要在每次循环的开始将它重置给ready_set;*/ Select(listenfd+1,&ready_set,NULL,NULL,NULL); /*Select函数的作用是指示内核阻塞等待一段时间,在这段时间里可能会有某些事件的到来使得读集合中相应的描述符变为就绪状态。 第一个参数为待测试的描述符的个数,即最大的描述符加一,因为描述符是从0开始依次计数的。内核将对“读集合”中的描述符0、1、2……maxfd-1依次测试其是否可读,测试的方法是尝试读取一个字节,能读取表示可读,也即有相应时间到来,若读取一个字节的请求阻塞,说明不可读,即没有相应事件到来。 第二个参数为待测试的读集合的指针,函数返回后指针指向一个就续集合,由可读的描述符组成。 第三个参数为待测试的写集合的指针,这里为空,不做详细说明 第四个参数为待测试的异常集合的指针,这里为空,不做详细说明(其实是不会,嘿嘿) 第五个参数为阻塞等待的时间,类型为一个时间结构体 struct timeval{ long tv_sec; //秒 long tv_usec; //微秒 }; 1)若为NULL,Select会永远阻塞等待,直到有一个描述符就绪。 2)等待不超过timeval中的时间,有一个描述符准备好时立即返回。 3)timeval中时间为0,则不等待,检查所有描述符后立即返回,称为轮询。 返回值:就绪描述符的数目,超时返回0,出错返回-1 */ if(FD_ISSET(STDIN_FILENO,&ready_set)) //用FD_ISSET函数判断描述符是否可读 commed(); //处理事件 if(FD_ISSET(listenfd,&ready_set)){ connfd=accept(……);
}
-
-
基于线程的并发编程
线程(thread)就是运行在进程上下文中的逻辑流。在本书里迄今为止,程序都是由每个进程中一个线程组成的。但是现代系统也允许我们编写一个进程里同时运行多个线程的程序。线程由内核自动调度。每个线程都有它自己的线程上下文(thread context),包括一个唯一的整数线程ID(Thread ID, TID)、栈、栈指针、程序计数器、通用目的寄存器和条件码。所有的运行在一个进程里的线程共享该进程的整个虚拟地址空间。
基于线程的逻辑流结合了基于进程和基于I/O多路复用的流的特性。同进程一样,线程由内核自动调度,并且内核通过一个整数ID来识别线程。同基于I/O多路复用的流一样,多个线程运行在单一进程的上下文中,因此共享这个进程虚拟地址空间的所有内容,包括它的代码、数据、堆、共享库和打开的文件。 -
线程的分离与结合
在任何一个时间点上,线程是可结合的(joinable),或者是分离的(detached)。一个可结合的线程能够被其他线程收回其资源和杀死;在被其他线程回收之前,它的存储器资源(如栈)是不释放的。相反,一个分离的线程是不能被其他线程回收或杀死的,它的存储器资源在它终止时由系统自动释放。
线程的分离状态决定一个线程以什么样的方式来终止自己。在默认情况下线程是非分离状态的,这种情况下,原有的线程等待创建的线程结束。只有当pthread_join()函数返回时,创建的线程才算终止,才能释放自己占用的系统资源。而分离线程不是这样子的,它没有被其他的线程所等待,自己运行结束了,线程也就终止了,马上释放系统资源。程序员应该根据自己的需要,选择适当的分离状态。所以如果我们在创建线程时就知道不需要了解线程的终止状态,则可以pthread_attr_t结构中的detachstate线程属性,让线程以分离状态启动。
设置线程分离状态的函数为pthread_attr_setdetachstate(pthread_attr_t *attr, int detachstate)。第二个参数可选PTHREAD_CREATE_DETACHED(分离线程)和 PTHREAD _CREATE_JOINABLE(非分离线程)。这里要注意的一点是,如果设置一个线程为分离线程,而这个线程运行又非常快,它很可能在pthread_create函数返回之前就终止了,它终止以后就可能将线程号和系统资源移交给其他的线程使用,这样调用pthread_create的线程就得到了错误的线程号。要避免这种情况可以采取一定的同步措施,最简单的方法之一是可以在被创建的线程里调用pthread_cond_timewait函数,让这个线程等待一会儿,留出足够的时间让函数pthread_create返回。设置一段等待时间,是在多线程编程里常用的方法。但是注意不要使用诸如wait()之类的函数,它们是使整个进程睡眠,并不能解决线程同步的问题。
如果不关心一个线程的结束状态,那么也可以将一个线程设置为 detached 状态,从而让操作系统在该线程结束时来回收它所占的资源。将一个线程设置为detached 状态可以通过两种方式来实现。一种是调用 pthread_detach() 函数,可以将线程 th 设置为 detached 状态。另一种方法是在创建线程时就将它设置为 detached 状态,首先初始化一个线程属性变量,然后将其设置为 detached 状态,最后将它作为参数传入线程创建函数 pthread_create(),这样所创建出来的线程就直接处于 detached 状态。
创建 detach 线程:pthread_t tid; pthread_attr_t attr; pthread_attr_init(&attr); pthread_attr_setdetachstate(&attr, PTHREAD_CREATE_DETACHED); pthread_create(&tid, &attr, THREAD_FUNCTION, arg);总之为了在使用 pthread 时避免线程的资源在线程结束时不能得到正确释放,从而避免产生潜在的内存泄漏问题,在对待线程结束时,要确保该线程处于 detached 状态,否着就需要调用 pthread_join() 函数来对其进行资源回收。
-
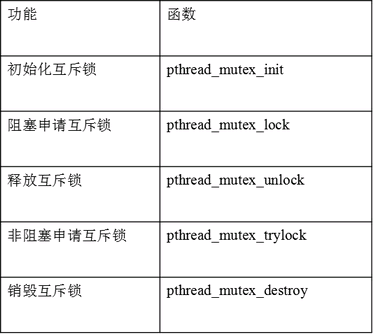
线程同步与互斥:互斥锁
互斥锁是一种简单的加锁的方法来控制对共享资源的访问,互斥锁只有两种状态,即上锁( lock )和解锁( unlock )。
互斥锁的操作流程如下:
1)在访问共享资源后临界区域前,对互斥锁进行加锁。
2)在访问完成后释放互斥锁导上的锁。
3)对互斥锁进行加锁后,任何其他试图再次对互斥锁加锁的线程将会被阻塞,直到锁被释放。互斥锁的数据类型是: pthread_mutex_t。
互斥锁基本操作
![]()
以下函数需要的头文件:#include <pthread.h>-
1)初始化互斥锁
int pthread_mutex_init(pthread_mutex_t *mutex, const pthread_mutexattr_t *attr);功能:初始化一个互斥锁。
参数:
mutex:互斥锁地址。类型是 pthread_mutex_t 。
attr:设置互斥量的属性,通常可采用默认属性,即可将 attr 设为 NULL。可以使用宏 PTHREAD_MUTEX_INITIALIZER 静态初始化互斥锁,比如:
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;这种方法等价于使用 NULL 指定的 attr 参数调用 pthread_mutex_init() 来完成动态初始化,不同之处在于 PTHREAD_MUTEX_INITIALIZER 宏不进行错误检查。
返回值:
成功:0,成功申请的锁默认是打开的。
失败:非 0 错误码 -
2)上锁
int pthread_mutex_lock(pthread_mutex_t *mutex);功能:对互斥锁上锁,若互斥锁已经上锁,则调用者一直阻塞,直到互斥锁解锁后再上锁。
参数:mutex:互斥锁地址。
返回值:
成功:0
失败:非 0 错误码int pthread_mutex_trylock(pthread_mutex_t *mutex);调用该函数时,若互斥锁未加锁,则上锁,返回 0;若互斥锁已加锁,则函数直接返回失败,即 EBUSY。
-
3)解锁
int pthread_mutex_unlock(pthread_mutex_t * mutex);功能:对指定的互斥锁解锁。
参数:mutex:互斥锁地址。
返回值:
成功:0
失败:非 0 错误码 -
4)销毁互斥锁
int pthread_mutex_destroy(pthread_mutex_t *mutex);功能:
销毁指定的一个互斥锁。互斥锁在使用完毕后,必须要对互斥锁进行销毁,以释放资源。
参数:mutex:互斥锁地址。
返回值:
成功:0
失败:非 0 错误码
-

练习题解析
-
12.1
在图12-5中,并发服务器的第33行上,父进程关闭了已连接描述符后,子进程仍然能够使用该描述符和客户端通信。为什么?解析:当父进程派生子进程时,它得到一个已连接描述符的副本,并将相关文件表中的引用计数从1增加到2。当父进程关闭它的描述符副本时,引用计数就从2减少到1。因为内核不会关闭一个文件,直到文件表中它的引用计数值变为零,所以子进程这边的连接端将保持打开。
-
12.2
如果我们要删除图12-5中关闭已连接描述符的第30行,从没有内存泄漏的角度来说,代码将仍然是正确的。为什么?解析:当一个进程因为某种原因终止时,内核将关闭所有打开的描述符。因此,当子进程退出时,它的已连接文件描述符的副本也将被自动关闭。
-
12.3
在Linux系统里,在标准输入上键入Ctrl+D表示EOF。图12-6中的程序阻塞在对select的调用上时,如果你键入Ctrl-D会发生什么?解析:回想一下,如果一个从描述符中读一个字节的请求不会阻塞,那么这个描述符就准备好可以读了。假如EOF在一个描述符上为真,那么描述符也准备好可读了,因为读操作将立即返回一个零返回码,表示EOF。因此,键人Ctrl+ D会导致select函数返回,准备好的集合中有描述符O。
-
12.4
重新初始化图12-8所示的服务器中,我们在每次调用select之前都立即小心地pool.ready_ set变量。为什么?解析:因为变量pool.read_set既作为输人参数也作为输出参数,所以我们在每一次调用select之前都重新初始化它。在输人时,它包含读集合。在输出,它包含准备好的集合。
-
12.5
在图12-5中基于进程的服务器中,我们在两个位置小心地关闭了已连接描述符:父进程和子进程。然而,在图12-14中基于线程的服务器中,我们只在一个位置关闭了已连接描述符:对等线程。为什么?解析:因为线程运行在同一个进程中,它们都共享相同的描述符表。无论有多少线程使用这个已连接描述符,这个已连接描述符的文件表的引用计数都等于1。因此,当我们用完它时,一个close操作就足以释放与这个已连接描述符相关的内存资源了。
-
12.6
A.利用12. 4节中的分析,为图12-15中的示例程序在下表的每个条目中填写“是”或者“否”。在第一列中,符号v. t表示变量二的一个实例,它驻留在线程t的本地栈中,其中t要么是m(主线程),要么是p0(对等线程0)或者p1(对等线程1)。变量实例 主线程引用的? 对等线程0引用的 对等线程1引用的 ptr 是 是 是 cnt 否 是 是 i.m 是 否 否 msgd.m 是 是 是 myid.po 否 是 否 myid.pI 否 否 是 说明: ptr:一个被主线程写和被对等线程读的全局变量。 cnt:一个静态变量,在内存中只有一个实例,被两个对等线程读和写。 i.m:一个存储在主线程栈中的本地自动变量。虽然它的值被传递给对等线程,但是对等线程也绝不会在栈中引用它,因此它不是共享的。 msgs.m:一个存储在主线程栈中的本地自动变量,被两个对等线程通过ptr间接地引用。 myid.0和myid.1:一个本地自动变量的实例,分别驻留在对等线程。和线程1的栈中。 B.根据A部分的分析,变量ptr,cnt、i、msgD和myid哪些是共享的?
解析:变量ptr, cnt和msgs被多于一个线程引用,因此它们是共享的。 -
12.7根据badcn七.c的指令顺序完成下表:
步骤 线程 指令 %rdx1 %rdx2 cnt 1 1 H1 0 2 1 L1 0 0 3 2 H2 0 4 2 L2 0 0 5 2 U2 1 0 6 2 S2 1 1 7 1 U1 1 1 8 1 S1 1 1 9 1 T1 1 1 10 2 T2 1 1 这种顺序会产生一个正确的cnt值吗? 解析:变量cnt最终有一个不正确的值1。 -
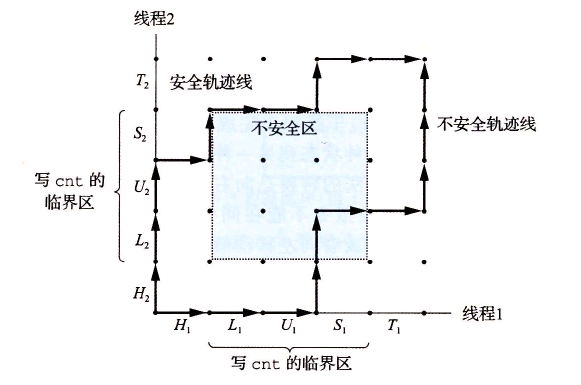
12.8使用图12-21中的进度图,将下列轨迹线划分为安全的或者不安全的。
A. H1,L1,U1,S1,H2,L2,U2,S2,T2,T1
B. H2,L2,H1,L1,U1,S1,T1,U2,S2,T2
C. H1,H2,L2,U2,S2,L1,U1,S1,T1,T2
![]()
安全和不安全轨迹线。临界区的交集形成了不安全区。
绕开不安全区的轨迹线能够正确更新计数器变量解析:
A. H1 , L1 , U1 , S1 , H2 , L2 , U2 , S2 , T2 , T1:安全的
B. H2 , L2 , H1 , L1 , U1 , S1 , T1 , U2 , S2 ,T2:不安全的
C. H1,H2,L2,U2,S2,L1,U1,S1,T1 , T2:安全的 -
12.9设p表示生产者数量,c表示消费者数量,而n表示以项目单元为单位的缓冲区大小。对于下面的每个场景,指出sbuf_insert和sbuf_remove中的互斥锁信号量是否是必需的。
A. p=1,c=1,n>1
B. p =1,c=1,n=1
C. p>1,c>1,n=1解析:
A. p=1,c=1, n>1:是,互斥锁是需要的,因为生产者和消费者会并发地访问缓冲区。
B. p=1, c=1, n=1:不是,在这种情况中不需要互斥锁信号量,因为一个非空的缓冲区就等于满的缓冲区。当缓冲区包含一个项目时,生产者就被阻塞了。当缓冲区为空时,消费者就被阻塞了。所以在任意时刻,只有一个线程可以访问缓冲区,因此不用互斥锁也能保证互斥。
C. p>1, c>1, n=1:不是,在这种情况中,也不需要互斥锁,原因与前面一种情况相同。 -
12.10图12-2 6所示的对第一类读者一写者问题的解答给予读者较高的优先级,但是从某种意义上说,这种优先级是很弱的,因为一个离开临界区的写者可能重启一个在等待的写者,而不是一个在等待的读者。描述出一个场景,其中这种弱优先级会导致一群写者使得一个读者饥饿。
解析:假设一个特殊的信号量实现为每一个信号量使用了一个LIFO的线程栈。当一个线程在P操作中阻塞在一个信号量上,它的ID就被压人栈中。类似地,V操作从栈中弹出栈顶的线程ID,并重启这个线程。根据这个栈的实现,一个在它的临界区中的竞争的写者会简单地等待,直到在它释放这个信号量之前另一个写者阻塞在这个信号量上。在这种场景中,当两个写者来回地传递控制权时,正在等待的读者可能会永远地等待下去。注意,虽然用FIFO队列而不是用LIFO更符合直觉,但是使用LIFO)的栈也是对的,而且也没有违反尸和V操作的语义。
-
12.11对于下表中的并行程序,填写空白处。假设使用强扩展。
线程(t) 1 2 4 核(p) 1 2 4 运行时间(Tp) 12 8 6 加速比(Sp) 1 1.5 2 效率比(Ep) 100% 75% 50% -
12.12图12-38中的come is函数是线程安全的,但不是可重入的。请解释说明。
解析:ctime_ts函数不是可重人函数,因为每次调用都共享相同的由gethostbyname函数返回的static变量。然而,它是线程安全的,因为对共享变量的访问是被尸和V操作保护的,因此是互斥的。
-
12.13在图12-43中,我们可能想要在主线程中的第14行后立即释放已分配的内存块,而不是在对等线程中释放它。但是这会是个坏注意。为什么?
解析:如果在第14行调用了pthread_ create之后,我们立即释放块,那么将引人一个新的竞争,这次竟争发生在主线程对free的调用和线程例程中第24行的赋值语句之间。
-
12.14
A.在图12-43中,我们通过为每个整数ID分配一个独立的块来消除竞争。给出一个不调用malloc或者free函数的不同的方法。
B.这种方法的利弊是什么?解析:
A.for(i=0;i<N,i++) Pthread_create(&tid[i],NULL,thread,(void *)i);在线程例程中,我们将参数强制转换成一个int类型,并将它赋值给myid:
int myid = (int) vargp;B.优点是它通过消除对malloc和free的调用降低了开销。一个明显的缺点是,它假设指针至少和int一样大。即便这种假设对于所有的现代系统来说都为真,但是它对于那些过去遗留下来的或今后的系统来说可能就不为真了。
-
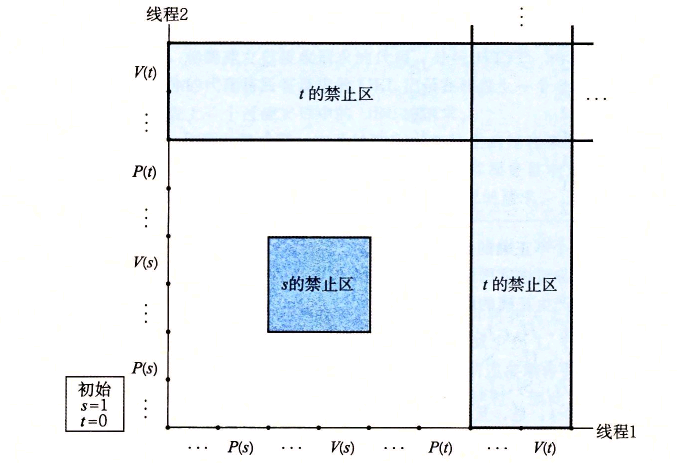
12.15思考下面的程序,它试图使用一对信号量来实现互斥。
初始时:s=1, t=0.
线程1: 线程2:
P(s); P(s);
V(s); V(s);
P(t); P(t);
V(t); v(t);
A.画出这个程序的进度图。
B.它总是会死锁吗?
C.如果是,那么对初始信号量的值做哪些简单的改变就能消除这种潜在的死锁呢?
D.画出得到的无死锁程序的进度图。解析:
A.
![]()
B.因为任何可行的轨迹最终都陷人死锁状态中,所以这个程序总是会死锁。
C.为了消除潜在的死锁,将二元信号量t初始化为1而不是0。
D.改成后的程序的进度图如图12-49所示。
![]()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号