
第二次结对项目
软工实践结对作业第二次
结队成员
王国超
陈龙江
编译环境:c++
一.Github传送门
二.数据生成程序的原理以及你们所考虑的因素
先贴出我们生成的一组最“好”的数据
对于学生标签,部门编号,星期这些个数比较小的,我们采用枚举。

学生的学号生成
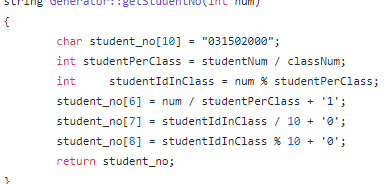
而输入数据的生成采用随机算法。这里我们默认学生的标签(兴趣)之间不会有冲突(学生兴趣广泛)以及部门与标签之间的从属关系是否符合逻辑= = 毕竟我们只有部门的id。
三.核心算法(Match 函数)
该算法设置了匹配系数。
当学生和部门进行匹配时,产生匹配系数 = 意愿优先级*意愿系数 + 匹配时间段数*时间系数 + 匹配标签数*标签系数,匹配系数从高到低排序。
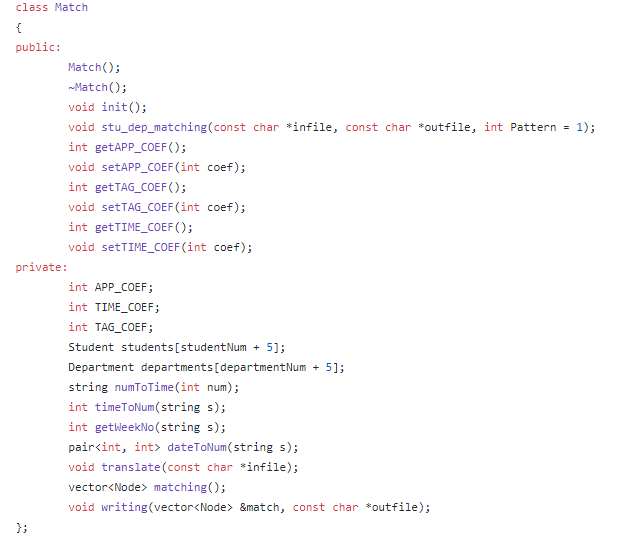
主要分成三部分
首先将输入文件进行解析,然后进行match,最后将得到的数据转化成jason格式输出。
四.代码规范
命名规范 用下划线来断开一个变量名中的不同的单词

一屏原则:一个方法体的代码幅应该在一屏比较和合理;逻辑复杂的代码可以抽离出方法体
给变量起名字真的很容易卡壳= =
五.结果评估
时间比较赶,没有进行优化。 感觉匹配算法的结果不是非常令人满意。选择了比较简便的匹配参数排序的方式导致当学生数量在一定时,会有许多学生没有匹配到部门。
四.结对感受,以及两个人对彼此结对中的闪光点或建议的分享
这次结对作业在国庆期间。。。。。。。 二号的时侯和队友讨论了一下这次作业的事情。然后国庆那几天玩疯了。回过神来就是八号了。所以九号的时侯确实是来不及完成这次作业了。没办法,只能先交了博文
然后慢慢完成。多亏龙江力挽狂澜,大力帮助。才能顺利完成这次作业。总的来说,发现自己确实挺爱拖的,这是不好的习惯。一定要加强自己的监督啊。还有就是初次见到作业,对于json真的是一点都不了解。这应该是这次作业最值得学习的知识点了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号