

Python 第十二章 数据库编程
1.初识数据库
SQL(结构化查询语言)分为3种类型:
- DDL语句 数据库定义语言:数据库、表、视图、索引、存储过程,例如CREATE DROP ALTER
- DML语句 数据库操纵语言:INSERT、DELETE、UPDATE、SELECT
- DCL语句 数据库控制语言:例如控制用户的访问权限GEANT、REVOKE
SQL语句:
操作文件夹(库)
- 增:create database db1 charset utf8;
- 查:show create database db1 ; show databases;
- 改:alter database db1 charset gbk;
- 删:drop database db1;
操作文件(表)
-
切换文件夹:use db1;
-
查看当前所在文件夹:select database();
-
增:create table t1(id int,name char); #指定两个字段及其类型。
-
查:show create table t1;
show tables;
desc t1;
-
改:alter table t1 modify name char(6); #修改name字段数据类型
alter table t1 change name NAME char(7); # 修改name字段名称和类型
-
删:drop table t1;
操作文件内容(记录)
-
增:insert t1(id,name) values(1,'egon1'),(2,'egon2'),(3,'egon3');
-
查:select id name from db1.t1;
select * from db1.t1;
-
改:update db1.t1 set name='SB';
update db1.t1 set name='ALEX' where id=2;
-
删:delete from t1;
delete from t1 where id=2;
2.库操作
2.1系统数据库
- information_schema:虚拟库:不占用磁盘空间,存储的是数据库启动后的一些参数,例如用户表信息、列信息、权限信息、字符信息等。
- performance_schema:用于收集数据库服务器性能参数,记录处理查询请求时发生的各种事件、锁等现象
- mysql:授权库,主要存储系统用户的权限信息。
- test:系统自动创建的测试数据库。
2.2创建数据库
create database 数据库名 charset utf8;
2.3数据库相关操作
操作文件夹(库)
- 增:create database db1 charset utf8;
- 查:show create database db1 ; show databases;
- 改:alter database db1 charset gbk;
- 删:drop database db1;
3.表操作
3.1存储引擎
存储引擎就是表的类型。用show engines;查看支持的存储引擎。
指定表类型/存储引擎:create table t1(id int)engine=innodb;
不写默认就是innodb
3.2表的增删改查
创建表:create table 表名(字段名1 类型[(宽度) 约束条件],字段名2 类型[(宽度) 约束条件],字段名3 类型[(宽度) 约束条件]);
查看表:desc 表名;查看表结构
show create table 表名\G; 查看表详细结构,可加\G,一行一行显示。
修改表结构:
修改表名:ALTER TABLE 表名 RENAME 新表名;
增加字段:ALTER TABLE 表名 ADD 字段名 数据类型[完整性约束条件],ADD 字段名 数据类型[完整性约束条件];
ADD 字段名 数据类型[完整性约束条件] FIRST; # 放到第一个位置
ADD 字段名 数据类型[完整性约束条件] AFTER 字段名;
删除字段:ALTER TABLE 表名 DROP 字段名;
修改字段:ALTER TABLE 表名 MODIFY 字段名 数据类型[完整性约束条件];
ALTER TABLE 表名 CHANGE 旧字段名 新字段名 旧数据类型 [完整性约束条件];
ALTER TABLE 表名 CHANGE 旧字段名 新字段名 新数据类型 [完整性约束条件];
删除表:DROP TABLE 表名;
复制表:复制表结构+记录(key不会复制:主键、外键和索引)create table new_service select * from service;
只复制表结构:create table new1_service select * from service where 1=2; 条件为假,查不到任何记录
create table t4 like employees;
4数据类型
4.1数值类型
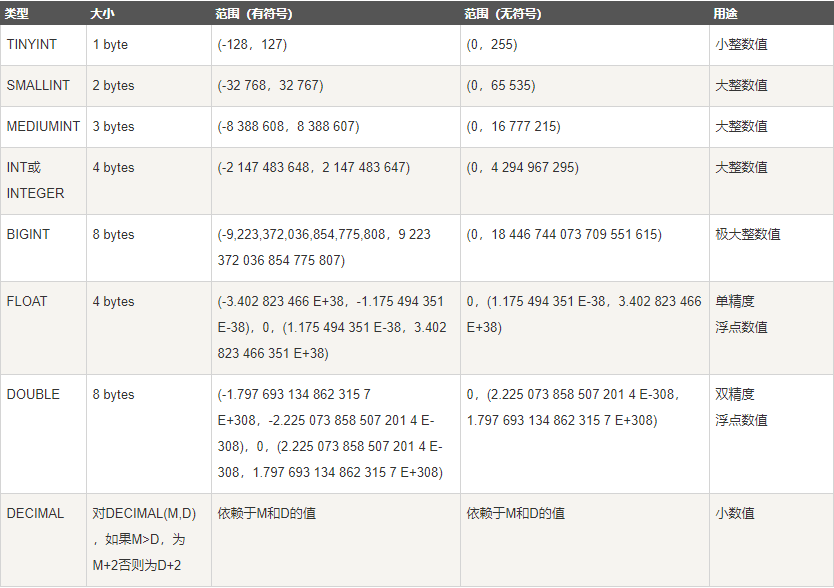
整型:
语句:create table t1(x tinyint unsigned) 给t1表创建一个tinyint类型无符号的字段x,默认是有符号的。
insert into t1 values(-1),(256); # 只能插入0和255
create table t2(id int(5) unsigned zerofill);
insert into t2 values(1); # 5代表显示宽度,不够用0填充。超过就正常填充。
int的存储宽度是4个Bytes,即32个bit,即2**32。
整形类型没有必要指定宽度,用默认的就行。
浮点型:
定点数类型DEC等同于DECIMAL
浮点类型:FLOAT DOUBLE
作用:存储薪资、身高、体重等
语句:create table t(x float(255,30)); # 255是数字总个数,30是小数点后个数。
create table t(x double(255,30));
create table t(x decimal(65,30));
4.2日期类型
create table student(
id int,
name char(6),
born_year year,
birth_date date,
class_time time,
reg_time datetime
);
insert into student values
(1,'egon',now(),now(),now(),now());

insert into student values
(2,'alex',"1997","1997-12-12","12:12:12","2018-2-12 12:12:12");

4.3字符串类型
char:定长
varchar:变长
# 宽度指的是字符的个数
create table t1(name char(5));
create table t2(name varchar(5));
insert into t1 values('李杰 '); # '李杰 ' 5个宽度
insert into t2 values('李杰 '); # '李杰 ' 3个宽度
select char_length(name) from t1; 5
select char_length(name) from t2; 3
一般多使用char。
4.4枚举类型和集合类型
字段的值只能在给定范围中选择,如单选框,多选框。
enum 单选 只能在给定的范围内选一个值,如性别 sex 男male/女 female
set 多选 在给定的范围内可以选择一个或一个以上的值 (爱好1,爱好2,爱好3。。。)
create table consumer(
id int,
name char(16),
sex enum('male','female'),
level enum('vip1','vip2','vip3'),
hobbies set('play','music','read','run')
);
insert into consumer values
(1,'egon','male','vip2','music,read');
5完整性约束
5.1sex字段不能传入空值,传入则使用默认值。
create table t1(
id int,
name char(6),
sex enum('male','female') not null default 'male'
);
单列唯一:
方式一:
create table department(id int unique,name char(10) unique);
方式二:
create table department(id int,name char(10),unique(id),unique(name));
联合唯一:
create table services(
id int,
ip char(15),
port int,
unique(id),
unique(ip,port));
insert into services values(1,'192.168.11.10',80); # ip和端口不能都一样
5.2主键primary key:
约束:not null unique 不为空且唯一
存储引擎(innodb):一张表必须有一个主键。
单列主键:
create table t1(id int primary key,name char(16));
复合主键:
create table t2(ip char(15),port int,primary key(ip,port);
5.3自增长:auto_increment
create table t1(
id int primary key auto_increment,
name char(16));
insert into t1(name) values ('zzd'),(zzc);
5.4清空表:
delete from t1 where id = 3; #清空后自增长从原来的开始
truncate t1; #清空后自增长从1开始 应该用这个。
5.5foreign key:建立表之间的关系
先建立被关联的表,并且保证被关联的字段唯一。
create table dep(
id int primary key,
name char(16),
comment char(50));
再建关联的表。
create table emp(
id int primary key,
name char(10),
sex enum('male','female'),
dep_id int,
foreign key(dep_id) references dep(id)
on delete cascade # 删除的话和被关联的同步
on update cascade # 更新同步
);
先往被关联表插入数据再往关联表插入数据。
5.6两张表之间的关系:
多对一,多对多,一对一。
一对多或多对一:
press出版社book书
create table press(
id int primary key auto_increment,
name varchar(20)
);
create table book(
id int primary key auto_increment,
name varchar(20),
press_id int not null,
foreign key(press_id) references press(id)
on delete cascade
on update cascade
);
插入数据(先往被关联的表插):
mysql> insert into press(name) values
-> ('zzd出版社1'),
-> ('出版社2'),
-> ('出版社3');
insert into book(name,press_id) values
('shu1',1),
('shu2',2),
('shu3',3),
('shu4',3)
;
多对多:先建书和作者两表,再建关联表
create table author(
id int primary key auto_increment,
name varchar(20)
);
insert into author(name) values ('zzd1'),('zzd2'),('zzd3');
create table author2book(
id int not null unique auto_increment,
author_id int not null,
book_id int not null,
constraint fk_author foreign key(author_id) references author(id)
on delete cascade
on update cascade,
constraint fk_book foreign key(book_id) references book(id)
on delete cascade
on update cascade,
primary key(author_id,book_id)
);
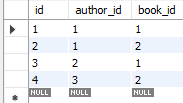
一对一:
create table customer(
id int primary key auto_increment,
name varchar(20) not null,
qq varchar(10) not null,
phone char(16) not null);
create table student(
id int primary key auto_increment,
class_name char(10) not null,
customer_id int unique, # 该字段的值一定要唯一
foreign key(customer_id) references customer(id)
on delete cascade
on update cascade);
插入数据:
insert into customer(name,qq,phone) values
('zzd1','111111111',22222222),
('zzd2','33333333',44444444),
('zzd3','55555555',666666666);
insert into student(class_name,customer_id) values
('18班',2),
('17班',1),
('19班',3);
6.数据操作
6.1插入完整数据(顺序插入)
语法一:
insert into 表名(字段1,字段2。。。) values(值1,值2。。。);
语法二:
insert into 表名 values(值1,值2,值3);
6.2插入多条数据
语法:
insert into 表名 values
(值1,值2,值3。。。),
(值1,值2,值3。。。),
(值1,值2,值3。。。);
6.3插入查询结果
语法:insert into 表名(字段1,字段2。。。)
select (字段1,字段2。。。) from 表2
where。。。;
6.4更新数据
语法:
update 表名 set
字段1=值1,
字段2=值2,
where condition;
示例:update mysql.user set password=password('123') where user='root' and host='localhost';
6.5删除数据
语法:
delete from 表名 where condition;
示例:delete from mysql.user where password='';
6.6查询数据
单表查询:distinct去重
select distinct 字段1,字段2 from 库.表
where 条件
group by 分组条件
having 过滤
order by 排序字段
limit n;
简单查询:select id,name,sex,age,hire_date,post,post_comment from employee;
select * from employee;
避免重复:select distinct post from employee;
通过四则运算查询:select name,salary*12 from employee;
select name,salary*12 as annual_salary from employee; 指定别名as后面,不加也行。
select name,salary*12 annual_salary from employee;
定义显示格式:concat() 函数用于连接字符串
select concat('姓名:',name,'年薪',salary*12) as annual_salary from employee;
concat_ws() 第一个参数为分隔符
select concat_ws(':',name,salary*12) as annual_salary from employee;
where约束:
单条件查询:select name from employee where post='sale';
多条件查询:select name,salary from employee where post='teacher' and salary >10000;
多关键字between and:select name,salary from employee where salary between 10000 and 2000;
select name,salary from employee where salary not between 10000 and 2000;
关键字is null:select name,post_comment from employee where post_comment is null;
select name,post_comment from employee where post_comment is not null;
关键字in:select * from employee where age in (23,75,9);
关键字like:select * from employee where name like "jin%" 后面任意字符
select * from employee where name like "jin_" 后面几个_就有几个字符
Group By分组查询:
-
分组发生在where之后,是基于where之后得到的记录而进行的。
-
分组指的是将所有记录按照某个字段进行归类。
-
select * from employee group by post只能查看post字段每个组的第一个值,要在MySQL中设置set global sql_mode="ONLY_FULL_GROUP_BY";只能查某个字段。退出重登后生效。
-
聚合函数:max、min、avg、sum、count。
比如:select post,count(id) as emp_count from employee group by post;
select post,group_concat(name) from employee group by post; group_concat拼接字符串
having过滤:
执行优先级高低:where>group by>having
查询各岗位内包含的员工个数小于2的岗位名、岗位内包含员工名字、个数:
select post,group_concat(name),count(id) from employee group by post having count(id) < 2;
order by:
select * from employee order by age asc; # 升序
select * from employee order by age desc; # 降序
select * from employee order by age asc,id desc; # 先按照age升序排,如果age相同则按照id降序排。
limit:
限制显示的条数。
select * from employee limit 5,5;从第5条开始往后数5条
7.连表操作
7.1内连接
只去两张表的共同部分:select * from employee inner join department on employee.dep_id = depatment.id;
7.2左连接
在内连接的基础上保留左表的记录:select * from employee left join department on employee.dep_id = depatment.id;
7.3右连接
在内连接的基础上保留右表的记录:select * from employee right join department on employee.dep_id = depatment.id;
7.4全外连接
在内连接的基础上保留左右两表没有对应关系的记录:
select * from employee left join department on employee.dep_id = depatment.id;
union
select * from employee right join department on employee.dep_id = depatment.id;
语句执行顺序:
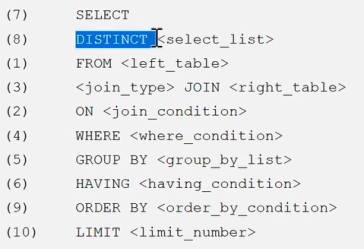
8.子查询
是将一个查询结果嵌套在另一个查询语句中。
内层查询的语句的查询结果,可以为外层查询语句提供查询条件。
子查询中包含:in、not in、any、all、exists、not exists等还可以包含运算符。
8.1带in关键字的子查询
查询平均年龄在25岁以上的部门名:
select id,name from department where id in (select dep_id from employee group by dep_id having avg(age) > 25);
查询技术部员工姓名:
select name from employee where dep_id=(select id from department where name="技术");
查看不足1人的部门名:
select name from department where id not in (select distinct dep_id from employee);
8.2带比较运算符的子查询
查询大于所有人平均年龄的员工名与年龄:
select name,age from employee where age > (select avg(age) from employee);
8.3带exists关键字的子查询
可以将一个表的查询结果用括号括起来加上as 和别名来和其他表或自己连用。
9.权限管理
9.1创建账号
# 本地帐号:
create user 'zzd1'@'localhost' identified by '1234'; # mysql -uzzd1 -p1234
远程账号:
create user 'zzd2'@'192.168.31.10' identified by '1234'; # mysql -uzzd2 -p1234 -h 服务端ip 前面的是客户端ip,在一台机器上登陆;
create user 'zzd3'@'192.168.31.%' identified by '1234'; # mysql -uzzd3 -p1234 -h 服务端ip 前面的是客户端ip,在一个网段上登陆;
create user 'zzd4'@'%' identified by '1234'; # mysql -uzzd4 -p1234 -h 服务端ip
9.2授权
user:*.*
db:db1.*
tables_priv:bd1.t1
columns_priv:id,name
grant all on *.* to 'zzd1'@'localhost';
grant select on *.* to 'zzd1'@'localhost';
10.pymysql模块的使用
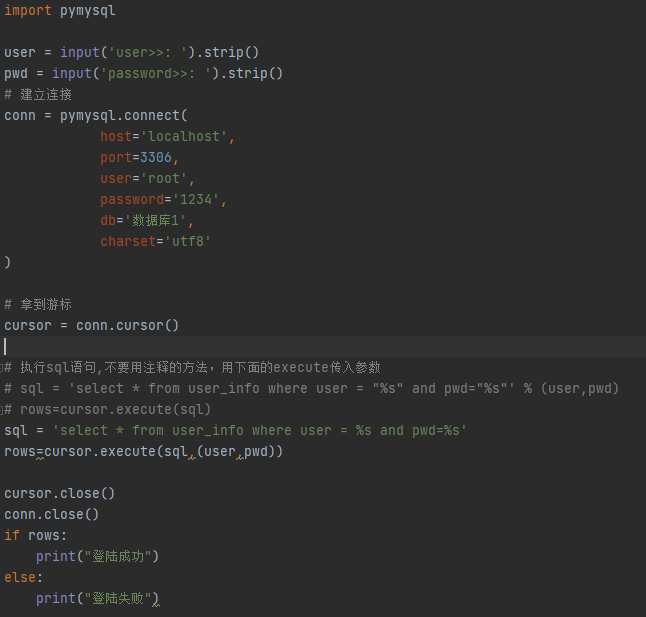
数据增删改:
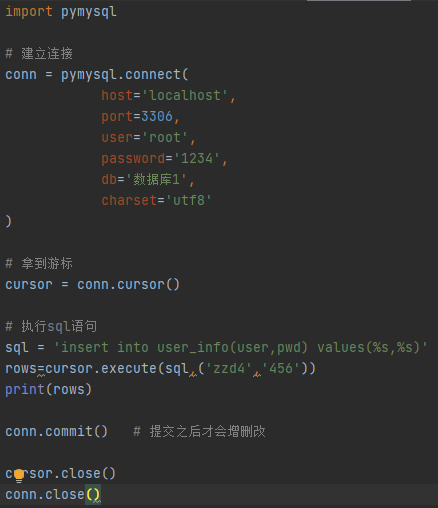
插入多条数据:

查:
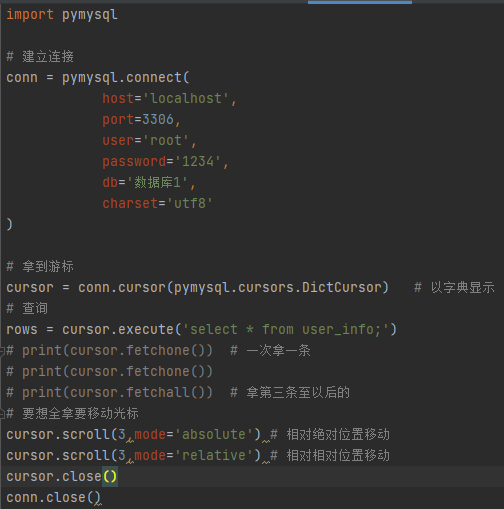
11.MySQL内置功能
11.1视图
当你创建了一个在内存的虚拟表并想多次使用可将其保存为视图:
create view 表名 as 查询语句;
11.2触发器
使用触发器可以定制用户对表进行增删改操作时前后的行为,没有查询。
创建触发器:
# 插入前对于tb1的每一行操作前做begin-end里面的操作。
# 同时还有updata、after updata
create trigger tri_before_insert_tb1 before insert on tb1 for each row
begin
...
end
# 插入后
create trigger tri_after_insert_tb1 after insert on tb1 for each row
begin
...
end
# 删除前
create trigger tri_before_delete_tb1 before delete on tb1 for each row
begin
...
end
# 删除后
create trigger tri_after_delete_tb1 before delete on tb1 for each row
begin
...
end
delimiter声明sql语句遇到//才执行结束。
给cmd表插入之后进行判断,不符合要求的插入errlog表。

11.3存储过程
类似于函数,封装好成p1()
# 无参存储过程
delimiter //
create procedure p1()
bigin
select * from db7.teacher; # 要在db7执行。
end //
delimiter;
# Mysql中调用
call p1();
# python中调用
cuesor.callproc('p1')
# 有参存储过程
delimiter //
create procedure p2(in n1 int,in n2 int,out res int)
begin
select * from db7.teacher where tid > n1 and tid < n2;
set res =1 # 声明一个返回值,成功返回就是1
end //
delimiter;
# Mysql中调用
set @x=0
call p2(2,4,@x); # 拿到2,4之间,即3的数据,@x返回1
select @x;
# python中调用
cuesor.callproc('p2',(2,4,0)) # @p2_0=2,@p2_1=4,@p2_2=0
cursor.excute('select @_p2_2')
cursor.fetchone() # 1
12.补充:SQLite数据库
Python自带了SQLite数据库和其API模块。SQLite只是一个嵌入式的数据库引擎,专门适用于在资源有限的设备上(如手机)进行适量数据的存取。它不需要像其他数据库那样需要安装、启动服务器进程,它只是一个文件。
SQLite内部只支持NULL、INTEGER、REAL(浮点数)、TEXT(文本)、BLOB(大二进制对象)。
SQLite允许把各种类型的数据保存到任何类型的字段中。
12.1创建数据表
# 导入访问SQLite的模块
import sqlite3
# ①、打开或创建数据库
# 也可以使用特殊名::memory:代表创建内存中的数据库
conn = sqlite3.connect('first.db')
# ②、获取游标
c = conn.cursor()
# ③、执行DDL语句创建数据表
c.execute('''create table user_tb(
_id integer primary key autoincrement,
name text,
pass text,
gender text)''')
# 执行DDL语句创建数据表
c.execute('''create table order_tb(
_id integer primary key autoincrement,
item_name text,
item_price real,
item_number real,
user_id inteter,
foreign key(user_id) references user_tb(_id) )''')
# ④、关闭游标
c.close()
# ⑤、关闭连接
conn.close()
12.2使用序列重复执行DML语句
使用游标的execute()方法可以执行增删改。
?代表占位符
# 导入访问SQLite的模块
import sqlite3
# ①、打开或创建数据库
# 也可以使用特殊名::memory:代表创建内存中的数据库
conn = sqlite3.connect('first.db')
# ②、获取游标
c = conn.cursor()
# ③、调用执行insert语句插入数据
c.execute('insert into user_tb values(null, ?, ?, ?)',
('孙悟空', '123456', 'male'))
c.execute('insert into order_tb values(null, ?, ?, ?, ?)',
('鼠标', '34.2', '3', 1))
conn.commit()
# ④、关闭游标
c.close()
# ⑤、关闭连接
conn.close()
使用executemany()方法多次执行同一条sql语句:
# 导入访问SQLite的模块
import sqlite3
# ①、打开或创建数据库
# 也可以使用特殊名::memory:代表创建内存中的数据库
conn = sqlite3.connect('first.db')
# ②、获取游标
c = conn.cursor()
# ③、调用executemany()方法把同一条SQL语句执行多次
c.executemany('insert into user_tb values(null, ?, ?, ?)',
(('sun', '123456', 'male'),
('bai', '123456', 'female'),
('zhu', '123456', 'male'),
('niu', '123456', 'male'),
('tang', '123456', 'male')))
conn.commit()
# ④、关闭游标
c.close()
# ⑤、关闭连接
conn.close()
重复执行update语句:
# 导入访问SQLite的模块
import sqlite3
# ①、打开或创建数据库
# 也可以使用特殊名::memory:代表创建内存中的数据库
conn = sqlite3.connect('first.db')
# ②、获取游标
c = conn.cursor()
# ③、调用executemany()方法把同一条SQL语句执行多次
c.executemany('update user_tb set name=? where _id=?',
(('小孙', 2),
('小白', 3),
('小猪', 4),
('小牛', 5),
('小唐', 6)))
# 通过rowcount获取被修改的记录条数
print('修改的记录条数:', c.rowcount)
conn.commit()
# ④、关闭游标
c.close()
# ⑤、关闭连接
conn.close()
12.3执行查询
# 导入访问SQLite的模块
import sqlite3
# ①、打开或创建数据库
# 也可以使用特殊名::memory:代表创建内存中的数据库
conn = sqlite3.connect('first.db')
# ②、获取游标
c = conn.cursor()
# ③、调用执行select语句查询数据
c.execute('select * from user_tb where _id > ?', (2,))
print('查询返回的记录数:', c.rowcount)
# 通过游标的description属性获取列信息
for col in (c.description):
print(col[0], end='\t')
print('\n--------------------------------')
while True:
# 获取一行记录,每行数据都是一个元组
row = c.fetchone()
# 如果抓取的row为None,退出循环
if not row :
break
print(row)
print(row[1] + '-->' + row[2])
# ④、关闭游标
c.close()
# ⑤、关闭连接
conn.close()
12.4事务控制
事务是由一步或几步数据库操作序列组成的逻辑执行单元,这一系列操作要么全部执行,要么全部放弃执行。
12.5执行SQL脚本
# 导入访问SQLite的模块
import sqlite3
# ①、打开或创建数据库
# 也可以使用特殊名::memory:代表创建内存中的数据库
conn = sqlite3.connect('first.db')
# ②、获取游标
c = conn.cursor()
# ③、调用executescript()方法执行一段SQL脚本
c.executescript('''
insert into user_tb values(null, '武松', '3444', 'male');
insert into user_tb values(null, '林冲', '44444', 'male');
create table item_tb(_id integer primary key autoincrement,
name,
price);
''')
conn.commit()
# ④、关闭游标
c.close()
# ⑤、关闭连接
conn.close()
12.6创建自定义函数
create_function(name,num_params,func)
# 导入访问SQLite的模块
import sqlite3
# 先定义一个普通函数,准备注册为SQL中的自定义函数
def reverse_ext(st):
# 对字符串反转,前后加方括号
return '[' + st[::-1] + ']'
# ①、打开或创建数据库
# 也可以使用特殊名::memory:代表创建内存中的数据库
conn = sqlite3.connect('first.db')
# 调用create_function注册自定义函数:enc
conn.create_function('enc', 1, reverse_ext)
# ②、获取游标
c = conn.cursor()
# ③、在SQL语句中使用enc自定义函数
c.execute('insert into user_tb values(null, ?, enc(?), ?)',
('贾宝玉', '123456', 'male'))
conn.commit()
# ④、关闭游标
c.close()
# ⑤、关闭连接
conn.close()
12.7创建聚集函数
求和、平均值、统计记录条数、最大最小值。
create_aggregate(name,num_params,aggregate_class)方法注册一个自定义的聚集函数
# 导入访问SQLite的模块
import sqlite3
# 先定义一个普通类,准备注册为SQL中的自定义聚集函数
class MinLen:
def __init__(self):
self.min_len = None
def step(self, value):
# 如果self.min_len还未赋值,直接将当前value赋值给self.min_lin
if self.min_len is None :
self.min_len = value
return
# 找到一个长度更短的value,用value代替self.min_len
if len(self.min_len) > len(value):
self.min_len = value
def finalize(self):
return self.min_len
# ①、打开或创建数据库
# 也可以使用特殊名::memory:代表创建内存中的数据库
conn = sqlite3.connect('first.db')
# 调用create_aggregate注册自定义聚集函数:min_len
conn.create_aggregate('min_len', 1, MinLen)
# ②、获取游标
c = conn.cursor()
# ③、在SQL语句中使用min_len自定义聚集函数
c.execute('select min_len(pass) from user_tb')
print(c.fetchone()[0])
conn.commit()
# ④、关闭游标
c.close()
# ⑤、关闭连接
conn.close()

