数据结构和集合类
数据结构基础
学习集合类之前,我们还有最关键的内容需要学习,自底向上才是最佳的学习方向,比起直接带大家认识集合类,不如先了解一下数据结构,只有了解了数据结构基础,才能更好地学习集合类。
同时,数据结构也是你以后深入学习JDK源码的必备条件!(学习不要快餐式!)当然,我们主要是讲解Java,数据结构作为铺垫作用,所以我们只会讲解关键的部分,其他部分可以下去自行了解。
在计算机科学中,数据结构是一种数据组织、管理和存储的格式,它可以帮助我们实现对数据高效的访问和修改。更准确地说,数据结构是数据值的集合,可以体现数据值之间的关系,以及可以对数据进行应用的函数或操作。
通俗地说,我们需要去学习在计算机中如何去更好地管理我们的数据,才能让我们对我们的数据控制更加灵活!
线性表
线性表是最基本的一种数据结构,它是表示一组相同类型数据的有限序列,你可以把它与数组进行参考,但是它并不是数组,线性表是一种表结构,它能够支持数据的插入、删除、更新、查询等,同时数组可以随意存放在数组中任意位置,而线性表只能依次有序排列,不能出现空隙,因此,我们需要进一步的设计。
顺序表
将数据依次存储在连续的整块物理空间中,这种存储结构称为顺序存储结构,而以这种方式实现的线性表,我们称为顺序表。
同样的,表中的每一个个体都被称为元素,元素左边的元素(上一个元素),称为前驱,同理,右边的元素(后一个元素)称为后驱。

我们设计线性表的目标就是为了去更好地管理我们的数据,也就是说,我们可以基于数组,来进行封装,实现增删改查!既然要存储一组数据,那么很容易联想到我们之前学过的数组,数组就能够容纳一组同类型的数据。
目标:以数组为底层,编写以下抽象类的具体实现
/**
* 线性表抽象类
* @param <E> 存储的元素(Element)类型
*/
public abstract class AbstractList<E> {
/**
* 获取表的长度
* @return 顺序表的长度
*/
public abstract int size();
/**
* 添加一个元素
* @param e 元素
* @param index 要添加的位置(索引)
*/
public abstract void add(E e, int index);
/**
* 移除指定位置的元素
* @param index 位置
* @return 移除的元素
*/
public abstract E remove(int index);
/**
* 获取指定位置的元素
* @param index 位置
* @return 元素
*/
public abstract E get(int index);
}
链表
数据分散的存储在物理空间中,通过一根线保存着它们之间的逻辑关系,这种存储结构称为链式存储结构
实际上,就是每一个结点存放一个元素和一个指向下一个结点的引用(C语言里面是指针,Java中就是对象的引用,代表下一个结点对象)

利用这种思想,我们再来尝试实现上面的抽象类,从实际的代码中感受!
比较:顺序表和链表的优异?
顺序表优缺点:
- 访问速度快,随机访问性能高
- 插入和删除的效率低下,极端情况下需要变更整个表
- 不易扩充,需要复制并重新创建数组
链表优缺点:
- 插入和删除效率高,只需要改变连接点的指向即可
- 动态扩充容量,无需担心容量问题
- 访问元素需要依次寻找,随机访问元素效率低下
链表只能指向后面,能不能指向前面呢?双向链表!
栈和队列实际上就是对线性表加以约束的一种数据结构,如果前面的线性表的掌握已经ok,那么栈和队列就非常轻松了!
栈
栈遵循先入后出原则,只能在线性表的一端添加和删除元素。我们可以把栈看做一个杯子,杯子只有一个口进出,最低处的元素只能等到上面的元素离开杯子后,才能离开。

向栈中插入一个元素时,称为入栈(压栈),移除栈顶元素称为出栈,我们需要尝试实现以下抽象类型:
/**
* 抽象类型栈,待实现
* @param <E> 元素类型
*/
public abstract class AbstractStack<E> {
/**
* 出栈操作
* @return 栈顶元素
*/
public abstract E pop();
/**
* 入栈操作
* @param e 元素
*/
public abstract void push(E e);
}
其实,我们的JVM在处理方法调用时,也是一个栈操作:

所以说,如果玩不好递归,就会像这样:
public class Main {
public static void main(String[] args) {
go();
}
private static void go(){
go();
}
}
Exception in thread "main" java.lang.StackOverflowError
at com.test.Main.go(Main.java:13)
at com.test.Main.go(Main.java:13)
at com.test.Main.go(Main.java:13)
at com.test.Main.go(Main.java:13)
at com.test.Main.go(Main.java:13)
at com.test.Main.go(Main.java:13)
at com.test.Main.go(Main.java:13)
at com.test.Main.go(Main.java:13)
...
栈的深度是有限制的,如果达到限制,将会出现StackOverflowError错误(注意是错误!说明是JVM出现了问题)
队列
队列同样也是受限制的线性表,不过队列就像我们排队一样,只能从队尾开始排,从队首出。

所以我们要实现以下内容:
/**
*
* @param <E>
*/
public abstract class AbstractQueue<E> {
/**
* 进队操作
* @param e 元素
*/
public abstract void offer(E e);
/**
* 出队操作
* @return 元素
*/
public abstract E poll();
}
二叉树
本版块主要学习的是二叉树,树也是一种数据结构,但是它使用起来更加的复杂。
树
我们前面已经学习过链表了,我们知道链表是单个结点之间相连,也就是一种一对一的关系,而树则是一个结点连接多个结点,也就是一对多的关系。

一个结点可以有N个子结点,就像上图一样,看起来就像是一棵树。而位于最顶端的结点(没有父结点)我们称为根结点,而结点拥有的子节点数量称为度,每向下一级称为一个层次,树中出现的最大层次称为树的深度(高度)。
二叉树
二叉树是一种特殊的树,每个结点最多有两颗子树,所以二叉树中不存在度大于2的结点,位于两边的子结点称为左右子树(注意,左右子树是明确区分的,是左就是左,是右就是右)

数学性质:
- 在二叉树的第i层上最多有2^(i-1) 个节点。
- 二叉树中如果深度为k,那么最多有2^k-1个节点。
设计一个二叉树结点类:
public class TreeNode<E> {
public E e; //当前结点数据
public TreeNode<E> left; //左子树
public TreeNode<E> right; //右子树
}
二叉树的遍历
顺序表的遍历其实就是依次有序去访问表中每一个元素,而像二叉树这样的复杂结构,我们有四种遍历方式,他们是:前序遍历、中序遍历、后序遍历以及层序遍历,本版块我们主要讨论前三种遍历方式:
- 前序遍历:从二叉树的根结点出发,到达结点时就直接输出结点数据,按照先向左在向右的方向访问。ABCDEF
- 中序遍历:从二叉树的根结点出发,优先输出左子树的节点的数据,再输出当前节点本身,最后才是右子树。CBDAEF
- 后序遍历:从二叉树的根结点出发,优先遍历其左子树,再遍历右子树,最后在输出当前节点本身。CDBFEA
满二叉树和完全二叉树
满二叉树和完全二叉树其实就是特殊情况下的二叉树,满二叉树左右的所有叶子节点都在同一层,也就是说,完全把每一个层级都给加满了结点。完全二叉树与满二叉树不同的地方在于,它的最下层叶子节点可以不满,但是最下层的叶子节点必须靠左排布。

其实满二叉树和完全二叉树就是有一定规律的二叉树,很容易理解。
快速查找
我们之前提到的这些数据结构,很好地帮我们管理了数据,但是,如果需要查找某一个元素是否存在于数据结构中,如何才能更加高效的去完成呢?
哈希表
通过前面的学习,我们发现,顺序表虽然查询效率高,但是插入删除有严重表更新的问题,而链表虽然弥补了更新问题,但是查询效率实在是太低了,能否有一种折中方案?哈希表!
不知大家在之前的学习中是否发现,我们的Object类中,定义了一个叫做hashcode()的方法?而这个方法呢,就是为了更好地支持哈希表的实现。hashcode()默认得到的是对象的内存地址,也就是说,每个对象的hashCode都不一样。
哈希表,其实本质上就是一个存放链表的数组,那么它是如何去存储数据的呢?我们先来看看长啥样:

数组中每一个元素都是一个头结点,用于保存数据,那我们怎么确定数据应该放在哪一个位置呢?通过hash算法,我们能够瞬间得到元素应该放置的位置。
//假设hash表长度为16,hash算法为:
private int hash(int hashcode){
return hashcode % 16;
}
设想这样一个问题,如果计算出来的hash值和之前已经存在的元素相同了呢?这种情况我们称为hash碰撞,这也是为什么要将每一个表元素设置为一个链表的头结点的原因,一旦发现重复,我们可以往后继续添加节点。
当然,以上的hash表结构只是一种设计方案,在面对大额数据时,是不够用的,在JDK1.8中,集合类使用的是数组+二叉树的形式解决的(这里的二叉树是经过加强的二叉树,不是前面讲得简单二叉树,我们下一节就会开始讲)
二叉排序树
我们前面学习的二叉树效率是不够的,我们需要的是一种效率更高的二叉树,因此,基于二叉树的改进,提出了二叉查找树,可以看到结构像下面这样:

不难发现,每个节点的左子树,一定小于当前节点的值,每个节点的右子树,一定大于当前节点的值,这样的二叉树称为二叉排序树。利用二分搜索的思想,我们就可以快速查找某个节点!
平衡二叉树
在了解了二叉查找树之后,我们发现,如果根节点为10,现在加入到结点的值从9开始,依次减小到1,那么这个表就会很奇怪,就像下面这样:

显然,当所有的结点都排列到一边,这种情况下,查找效率会直接退化为最原始的二叉树!因此我们需要维持二叉树的平衡,才能维持原有的查找效率。
现在我们对二叉排序树加以约束,要求每个结点的左右两个子树的高度差的绝对值不超过1,这样的二叉树称为平衡二叉树,同时要求每个结点的左右子树都是平衡二叉树,这样,就不会因为一边的疯狂增加导致失衡。我们来看看以下几种情况:

左左失衡

右右失衡

左右失衡

右左失衡
通过以上四种情况的处理,最终得到维护平衡二叉树的算法。
红黑树
红黑树也是二叉排序树的一种改进,同平衡二叉树一样,红黑树也是一种维护平衡的二叉排序树,但是没有平衡二叉树那样严格(平衡二叉树每次插入新结点时,可能会出现大量的旋转,而红黑树保证不超过三次),红黑树降低了对于旋转的要求,因此效率有一定的提升同时实现起来也更加简单。但是红黑树的效率却高于平衡二叉树,红黑树也是JDK1.8中使用的数据结构!

红黑树的特性:
(1)每个节点或者是黑色,或者是红色。
(2)根节点是黑色。
(3)每个叶子节点的两边也需要表示(虽然没有,但是null也需要表示出来)是黑色。
(4)如果一个节点是红色的,则它的子节点必须是黑色的。
(5)从一个节点到该节点的子孙节点的所有路径上包含相同数目的黑节点。
我们来看看一个节点,是如何插入到红黑树中的:
基本的 插入规则和平衡二叉树一样,但是在插入后:
- 将新插入的节点标记为红色
- 如果 X 是根结点(root),则标记为黑色
- 如果 X 的 parent 不是黑色,同时 X 也不是 root:
-
3.1 如果 X 的 uncle (叔叔) 是红色
-
- 3.1.1 将 parent 和 uncle 标记为黑色
- 3.1.2 将 grand parent (祖父) 标记为红色
- 3.1.3 让 X 节点的颜色与 X 祖父的颜色相同,然后重复步骤 2、3
- 3.1.1 将 parent 和 uncle 标记为黑色
-
3.2 如果 X 的 uncle (叔叔) 是黑色,我们要分四种情况处理
-
- 3.2.1 左左 (P 是 G 的左孩子,并且 X 是 P 的左孩子)
- 3.2.2 左右 (P 是 G 的左孩子,并且 X 是 P 的右孩子)
- 3.2.3 右右 (P 是 G 的右孩子,并且 X 是 P 的右孩子)
- 3.2.4 右左 (P 是 G 的右孩子,并且 X 是 P 的左孩子)
- 其实这种情况下处理就和我们的平衡二叉树一样了
- 3.2.1 左左 (P 是 G 的左孩子,并且 X 是 P 的左孩子)
认识集合类
源码解析:https://www.cnblogs.com/zwtblog/tag/源码/
集合表示一组对象,称为其元素。一些集合允许重复的元素,而另一些则不允许。一些集合是有序的,而其他则是无序的。
集合类其实就是为了更好地组织、管理和操作我们的数据而存在的,包括列表、集合、队列、映射等数据结构。从这一块开始,我们会从源码角度给大家讲解(数据结构很重要!),不仅仅是教会大家如何去使用。
集合类最顶层不是抽象类而是接口,因为接口代表的是某个功能,而抽象类是已经快要成形的类型,不同的集合类的底层实现是不相同的,同时一个集合类可能会同时具有两种及以上功能(既能做队列也能做列表),所以采用接口会更加合适,接口只需定义支持的功能即可。

数组与集合
相同之处:
- 它们都是容器,都能够容纳一组元素。
不同之处:
- 数组的大小是固定的,集合的大小是可变的。
- 数组可以存放基本数据类型,但集合只能存放对象。
- 数组存放的类型只能是一种,但集合可以有不同种类的元素。
集合根接口Collection
本接口中定义了全部的集合基本操作,我们可以在源码中看看。
我们再来看看List和Set以及Queue接口。
集合类的使用
List列表
首先介绍ArrayList,它的底层是用数组实现的,内部维护的是一个可改变大小的数组,也就是我们之前所说的线性表!跟我们之前自己写的ArrayList相比,它更加的规范,同时继承自List接口。
先看看ArrayList的源码!
基本操作
List<String> list = new ArrayList<>(); //默认长度的列表
List<String> listInit = new ArrayList<>(100); //初始长度为100的列表
向列表中添加元素:
List<String> list = new ArrayList<>();
list.add("lbwnb");
list.add("yyds");
list.contains("yyds"); //是否包含某个元素
System.out.println(list);
移除元素:
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("lbwnb");
list.add("yyds");
list.remove(0); //按下标移除元素
list.remove("yyds"); //移除指定元素
System.out.println(list);
}
也支持批量操作:
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
list.addAll(new ArrayList<>()); //在尾部批量添加元素
list.removeAll(new ArrayList<>()); //批量移除元素(只有给定集合中存在的元素才会被移除)
list.retainAll(new ArrayList<>()); //只保留某些元素
System.out.println(list);
}
我们再来看LinkedList,其实本质就是一个链表!我们来看看源码。
其实与我们之前编写的LinkedList不同之处在于,它内部使用的是一个双向链表:
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
当然,我们发现它还实现了Queue接口,所以LinkedList也能被当做一个队列或是栈来使用。
public static void main(String[] args) {
LinkedList<String> list = new LinkedList<>();
list.offer("A"); //入队
System.out.println(list.poll()); //出队
list.push("A");
list.push("B"); //进栈
list.push("C");
System.out.println(list.pop());
System.out.println(list.pop()); //出栈
System.out.println(list.pop());
}
利用代码块来快速添加内容
前面我们学习了匿名内部类,我们就可以利用代码块,来快速生成一个自带元素的List
List<String> list = new LinkedList<String>(){{ //初始化时添加
this.add("A");
this.add("B");
}};
如果是需要快速生成一个只读的List,后面我们会讲解Arrays工具类。
集合的排序
List<Integer> list = new LinkedList<Integer>(){ //Java9才支持匿名内部类使用钻石运算符
{
this.add(10);
this.add(2);
this.add(5);
this.add(8);
}
};
list.sort((a, b) -> { //排序已经由JDK实现,现在只需要填入自定义规则,完成Comparator接口实现
return a - b; //返回值小于0,表示a应该在b前面,返回值大于0,表示b应该在a后面,等于0则不进行交换
});
System.out.println(list);
迭代器
集合的遍历
所有的集合类,都支持foreach循环!
public static void main(String[] args) {
List<Integer> list = new LinkedList<Integer>(){ //Java9才支持匿名内部类使用钻石运算符
{
this.add(10);
this.add(2);
this.add(5);
this.add(8);
}
};
for (Integer integer : list) {
System.out.println(integer);
}
}
当然,也可以使用JDK1.8新增的forEach方法,它接受一个Consumer接口实现:
list.forEach(i -> {
System.out.println(i);
});
从JDK1.8开始,lambda表达式开始逐渐成为主流,我们需要去适应函数式编程的这种语法,包括批量替换,也是用到了函数式接口来完成的。
list.replaceAll((i) -> {
if(i == 2) return 3; //将所有的2替换为3
else return i; //不是2就不变
});
System.out.println(list);
Iterable和Iterator接口
我们之前学习数据结构时,已经得知,不同的线性表实现,在获取元素时的效率也不同,因此我们需要一种更好地方式来统一不同数据结构的遍历。
由于ArrayList对于随机访问的速度更快,而LinkedList对于顺序访问的速度更快,
因此在上述的传统for循环遍历操作中,ArrayList的效率更胜一筹,因此我们要使得LinkedList遍历效率提升,就需要采用顺序访问的方式进行遍历,
如果没有迭代器帮助我们统一标准,那么我们在应对多种集合类型的时候,就需要对应编写不同的遍历算法,很显然这样会降低我们的开发效率,而迭代器的出现就帮助我们解决了这个问题。
我们先来看看迭代器里面方法:
public interface Iterator<E> {
//...
}
每个集合类都有自己的迭代器,通过iterator()方法来获取:
Iterator<Integer> iterator = list.iterator(); //生成一个新的迭代器
while (iterator.hasNext()){ //判断是否还有下一个元素
Integer i = iterator.next(); //获取下一个元素(获取一个少一个)
System.out.println(i);
}
迭代器生成后,默认指向第一个元素,每次调用next()方法,都会将指针后移,当指针移动到最后一个元素之后,调用hasNext()将会返回false,迭代器是一次性的,用完即止,如果需要再次使用,需要调用iterator()方法。
//List还有一个更好地迭代器实现ListIterator
ListIterator<Integer> iterator = list.listIterator();
ListIterator是List中独有的迭代器,在原有迭代器基础上新增了一些额外的操作。
Set集合
我们之前已经看过Set接口的定义了,我们发现接口中定义的方法都是Collection中直接继承的,因此,Set支持的功能其实也就和Collection中定义的差不多,只不过使用方法上稍有不同。
Set集合特点:
- 不允许出现重复元素
- 不支持随机访问(不允许通过下标访问)
首先认识一下HashSet,它的底层就是采用哈希表实现的(我们在这里先不去探讨实现原理,因为底层实质上维护的是一个HashMap,我们学习了Map之后再来讨论)
public static void main(String[] args) {
HashSet<Integer> set = new HashSet<>();
set.add(120); //支持插入元素,但是不支持指定位置插入
set.add(13);
set.add(11);
for (Integer integer : set) {
System.out.println(integer);
}
}
运行上面代码发现,最后Set集合中存在的元素顺序,并不是我们的插入顺序,这是因为HashSet底层是采用哈希表来实现的,实际的存放顺序是由Hash算法决定的。
那么我们希望数据按照我们插入的顺序进行保存该怎么办呢?我们可以使用LinkedHashSet:
public static void main(String[] args) {
LinkedHashSet<Integer> set = new LinkedHashSet<>(); //会自动保存我们的插入顺序
set.add(120);
set.add(13);
set.add(11);
for (Integer integer : set) {
System.out.println(integer);
}
}
LinkedHashSet底层维护的不再是一个HashMap,而是LinkedHashMap,它能够在插入数据时利用链表自动维护顺序,因此这样就能够保证我们插入顺序和最后的迭代顺序一致了。
还有一种Set叫做TreeSet,它会在元素插入时进行排序:
public static void main(String[] args) {
TreeSet<Integer> set = new TreeSet<>();
set.add(1);
set.add(3);
set.add(2);
System.out.println(set);
}
可以看到最后得到的结果并不是我们插入顺序,而是按照数字的大小进行排列。当然,我们也可以自定义排序规则:
public static void main(String[] args) {
TreeSet<Integer> set = new TreeSet<>((a, b) -> b - a); //在创建对象时指定规则即可
set.add(1);
set.add(3);
set.add(2);
System.out.println(set);
}
现在的结果就是我们自定义的排序规则了。
虽然Set集合只是粗略的进行了讲解,但是学习Map之后,我们还会回来看我们Set的底层实现,所以说最重要的还是Map。本节只需要记住Set的性质、使用即可。
Map映射
什么是映射
我们在高中阶段其实已经学习过映射了,映射指两个元素的之间相互“对应”的关系,也就是说,我们的元素之间是两两对应的,是以键值对的形式存在。

Map接口
Map就是为了实现这种数据结构而存在的,我们通过保存键值对的形式来存储映射关系。
我们先来看看Map接口中定义了哪些操作。
HashMap和LinkedHashMap
HashMap的实现过程,相比List,就非常地复杂了,它并不是简简单单的表结构,而是利用哈希表存放映射关系,我们来看看HashMap是如何实现的,首先回顾我们之前学习的哈希表,它长这样:

哈希表的本质其实就是一个用于存放后续节点的头结点的数组,数组里面的每一个元素都是一个头结点(也可以说就是一个链表),当要新插入一个数据时,会先计算该数据的哈希值,找到数组下标,然后创建一个新的节点,添加到对应的链表后面。
而HashMap就是采用的这种方式,我们可以看到源码中同样定义了这样的一个结构:
/**
* The table, initialized on first use, and resized as
* necessary. When allocated, length is always a power of two.
* (We also tolerate length zero in some operations to allow
* bootstrapping mechanics that are currently not needed.)
*/
transient Node<K,V>[] table;
这个表会在第一次使用时初始化,同时在必要时进行扩容,并且它的大小永远是2的倍数!
/**
* The default initial capacity - MUST be a power of two.
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
我们可以看到默认的大小为2的4次方,每次都需要是2的倍数,也就是说,下一次增长之后,大小会变成2的5次方。
我们现在需要思考一个问题,当我们表中的数据不断增加之后,链表会变得越来越长,这样会严重导致查询速度变慢,首先想到办法就是,我们可以对数组的长度进行扩容,来存放更多的链表,那么什么情况下会进行扩容呢?
/**
* The load factor for the hash table.
*
* @serial
*/
final float loadFactor;
我们还发现HashMap源码中有这样一个变量,也就是负载因子,那么它是干嘛的呢?
负载因子其实就是用来衡量当前情况是否需要进行扩容的标准。我们可以看到默认的负载因子是0.75
/**
* The load factor used when none specified in constructor.
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
那么负载因子是怎么控制扩容的呢?0.75的意思是,在插入新的结点后,如果当前数组的占用率达到75%则进行扩容。在扩容时,会将所有的数据,重新计算哈希值,得到一个新的下标,组成新的哈希表。
但是这样依然有一个问题,链表过长的情况还是有可能发生,所以,为了从根源上解决这个问题,在JDK1.8时,引入了红黑树这个数据结构。
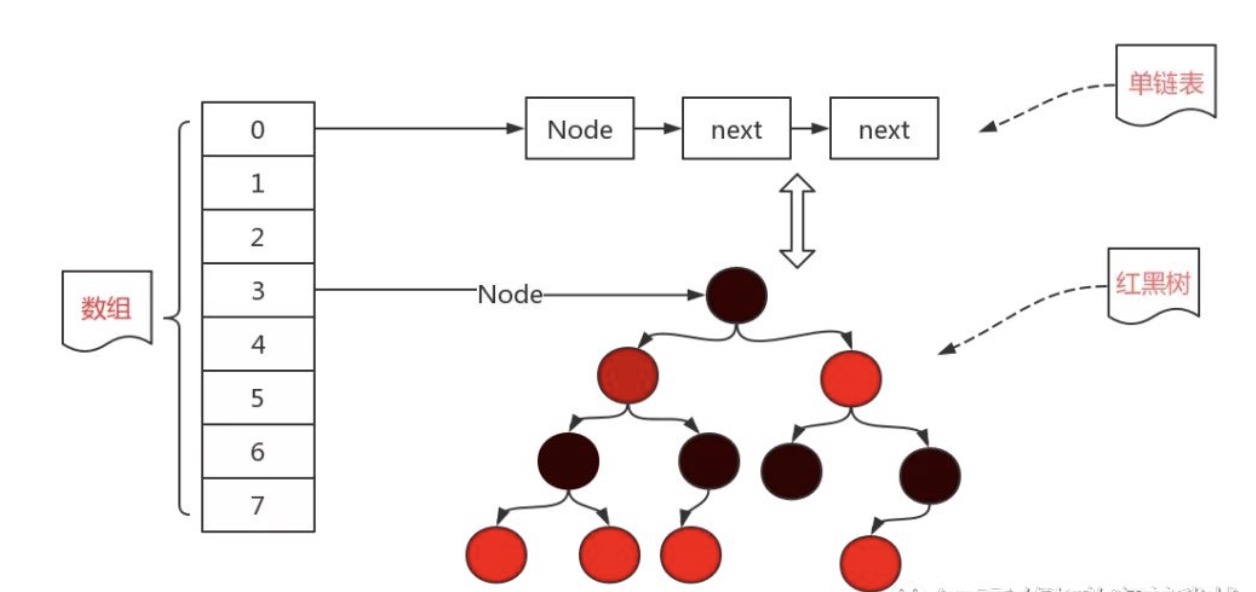
当链表的长度达到8时,会自动将链表转换为红黑树,这样能使得原有的查询效率大幅度降低!当使用红黑树之后,我们就可以利用二分搜索的思想,快速地去寻找我们想要的结果,而不是像链表一样挨个去看。
/**
* Entry for Tree bins. Extends LinkedHashMap.Entry (which in turn
* extends Node) so can be used as extension of either regular or
* linked node.
*/
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
除了Node以外,HashMap还有TreeNode,很明显这就是为了实现红黑树而设计的内部类。不过我们发现,TreeNode并不是直接继承Node,而是使用了LinkedHashMap中的Entry实现,它保存了前后节点的顺序(也就是我们的插入顺序)。
/**
* HashMap.Node subclass for normal LinkedHashMap entries.
*/
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
LinkedHashMap是直接继承自HashMap,具有HashMap的全部性质,同时得益于每一个节点都是一个双向链表,保存了插入顺序,这样我们在遍历LinkedHashMap时,顺序就同我们的插入顺序一致。当然,也可以使用访问顺序,也就是说对于刚访问过的元素,会被排到最后一位。
public static void main(String[] args) {
LinkedHashMap<Integer, String> map = new LinkedHashMap<>(16, 0.75f, true); //以访问顺序
map.put(1, "A");
map.put(2, "B");
map.put(3, "C");
map.get(2);
System.out.println(map);
}
观察结果,我们发现,刚访问的结果被排到了最后一位。
TreeMap
TreeMap其实就是自动维护顺序的一种Map,就和我们前面提到的TreeSet一样:
/**
* The comparator used to maintain order in this tree map, or
* null if it uses the natural ordering of its keys.
*
* @serial
*/
private final Comparator<? super K> comparator;
private transient Entry<K,V> root;
/**
* Node in the Tree. Doubles as a means to pass key-value pairs back to
* user (see Map.Entry).
*/
static final class Entry<K,V> implements Map.Entry<K,V> {
我们发现它的内部直接维护了一个红黑树,就像它的名字一样,就是一个Tree,因为它默认就是有序的,所以说直接采用红黑树会更好。我们在创建时,直接给予一个比较规则即可。
Map的使用
我们首先来看看Map的一些基本操作:
public static void main(String[] args) {
Map<Integer, String> map = new HashMap<>();
map.put(1, "A");
map.put(2, "B");
map.put(3, "C");
System.out.println(map.get(1)); //获取Key为1的值
System.out.println(map.getOrDefault(0, "K")); //不存在就返回K
map.remove(1); //移除这个Key的键值对
}
由于Map并未实现迭代器接口,因此不支持foreach,但是JDK1.8为我们提供了forEach方法使用:
public static void main(String[] args) {
Map<Integer, String> map = new HashMap<>();
map.put(1, "A");
map.put(2, "B");
map.put(3, "C");
map.forEach((k, v) -> System.out.println(k+"->"+v));
for (Map.Entry<Integer, String> entry : map.entrySet()) { //也可以获取所有的Entry来foreach
int key = entry.getKey();
String value = entry.getValue();
System.out.println(key+" -> "+value);
}
}
我们也可以单独获取所有的值或者是键:
public static void main(String[] args) {
Map<Integer, String> map = new HashMap<>();
map.put(1, "A");
map.put(2, "B");
map.put(3, "C");
System.out.println(map.keySet()); //直接获取所有的key
System.out.println(map.values()); //直接获取所有的值
}
再谈Set原理
通过观察HashSet的源码发现,HashSet几乎都在操作内部维护的一个HashMap,也就是说,HashSet只是一个表壳,而内部维护的HashMap才是灵魂!
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
我们发现,在添加元素时,其实添加的是一个键为我们插入的元素,而值就是PRESENT常量:
/**
* Adds the specified element to this set if it is not already present.
* More formally, adds the specified element <tt>e</tt> to this set if
* this set contains no element <tt>e2</tt> such that
* <tt>(e==null ? e2==null : e.equals(e2))</tt>.
* If this set already contains the element, the call leaves the set
* unchanged and returns <tt>false</tt>.
*
* @param e element to be added to this set
* @return <tt>true</tt> if this set did not already contain the specified
* element
*/
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
观察其他的方法,也几乎都是在用HashMap做事,所以说,HashSet利用了HashMap内部的数据结构,轻松地就实现了Set定义的全部功能!
再来看TreeSet,实际上用的就是我们的TreeMap:
/**
* The backing map.
*/
private transient NavigableMap<E,Object> m;
同理,这里就不多做阐述了。
JDK1.8新增方法使用
最后,我们再来看看JDK1.8中集合类新增的一些操作(之前没有提及的)首先来看看compute方法:
public static void main(String[] args) {
Map<Integer, String> map = new HashMap<>();
map.put(1, "A");
map.put(2, "B");
map.compute(1, (k, v) -> { //compute会将指定Key的值进行重新计算,若Key不存在,v会返回null
return v+"M"; //这里返回原来的value+M
});
map.computeIfPresent(1, (k, v) -> { //当Key存在时存在则计算并赋予新的值
return v+"M"; //这里返回原来的value+M
});
System.out.println(map);
}
也可以使用computeIfAbsent,当不存在Key时,计算并将键值对放入Map
public static void main(String[] args) {
Map<Integer, String> map = new HashMap<>();
map.put(1, "A");
map.put(2, "B");
map.computeIfAbsent(0, (k) -> { //若不存在则计算并插入新的值
return "M"; //这里返回M
});
System.out.println(map);
}
merge方法用于处理数据:
public static void main(String[] args) {
List<Student> students = Arrays.asList(
new Student("yoni", "English", 80),
new Student("yoni", "Chiness", 98),
new Student("yoni", "Math", 95),
new Student("taohai.wang", "English", 50),
new Student("taohai.wang", "Chiness", 72),
new Student("taohai.wang", "Math", 41),
new Student("Seely", "English", 88),
new Student("Seely", "Chiness", 89),
new Student("Seely", "Math", 92)
);
Map<String, Integer> scoreMap = new HashMap<>();
students.forEach(student -> scoreMap.merge(student.getName(), student.getScore(), Integer::sum));
scoreMap.forEach((k, v) -> System.out.println("key:" + k + "总分" + "value:" + v));
}
static class Student {
private final String name;
private final String type;
private final int score;
public Student(String name, String type, int score) {
this.name = name;
this.type = type;
this.score = score;
}
public String getName() {
return name;
}
public int getScore() {
return score;
}
public String getType() {
return type;
}
}
集合的嵌套
既然集合类型中的元素类型是泛型,那么能否嵌套存储呢?
public static void main(String[] args) {
Map<String, List<Integer>> map = new HashMap<>(); //每一个映射都是 字符串<->列表
map.put("卡布奇诺今犹在", new LinkedList<>());
map.put("不见当年倒茶人", new LinkedList<>());
System.out.println(map.keySet());
System.out.println(map.values());
}
通过Key获取到对应的值后,就是一个列表:
map.get("卡布奇诺今犹在").add(10);
System.out.println(map.get("卡布奇诺今犹在").get(0));
让套娃继续下去:
public static void main(String[] args) {
Map<Integer, Map<Integer, Map<Integer, String>>> map = new HashMap<>();
}
你也可以使用List来套娃别的:
public static void main(String[] args) {
List<Map<String, Set<String>>> list = new LinkedList<>();
}
流Stream和Optional的使用
Java 8 API添加了一个新的抽象称为流Stream,可以让你以一种声明的方式处理数据。Stream 使用一种类似用 SQL 语句从数据库查询数据的直观方式来提供一种对 Java 集合运算和表达的高阶抽象。Stream API可以极大提高Java程序员的生产力,让程序员写出高效率、干净、简洁的代码。这种风格将要处理的元素集合看作一种流, 流在管道中传输, 并且可以在管道的节点上进行处理, 比如筛选, 排序,聚合等。元素流在管道中经过中间操作(intermediate operation)的处理,最后由最终操作(terminal operation)得到前面处理的结果。

它看起来就像一个工厂的流水线一样!我们就可以把一个Stream当做流水线处理:
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("A");
list.add("B");
list.add("C");
//移除为B的元素
Iterator<String> iterator = list.iterator();
while (iterator.hasNext()){
if(iterator.next().equals("B")) iterator.remove();
}
//Stream操作
list = list //链式调用
.stream() //获取流
.filter(e -> !e.equals("B")) //只允许所有不是B的元素通过流水线
.collect(Collectors.toList()); //将流水线中的元素重新收集起来,变回List
System.out.println(list);
}
可能从上述例子中还不能感受到流处理带来的便捷,我们通过下面这个例子来感受一下:
public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
list.add(3);
list = list
.stream()
.distinct() //去重(使用equals判断)
.sorted((a, b) -> b - a) //进行倒序排列
.map(e -> e+1) //每个元素都要执行+1操作
.limit(2) //只放行前两个元素
.collect(Collectors.toList());
System.out.println(list);
}
当遇到大量的复杂操作时,我们就可以使用Stream来快速编写代码,这样不仅代码量大幅度减少,而且逻辑也更加清晰明了(如果你学习过SQL的话,你会发现它更像一个Sql语句)
注意:不能认为每一步是直接依次执行的!
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
list.add(3);
list = list
.stream()
.distinct() //断点
.sorted((a, b) -> b - a)
.map(e -> {
System.out.println(">>> "+e); //断点
return e+1;
})
.limit(2) //断点
.collect(Collectors.toList());
//实际上,stream会先记录每一步操作,而不是直接开始执行内容,当整个链式调用完成后,才会依次进行!
接下来,我们用一堆随机数来进行更多流操作的演示:
public static void main(String[] args) {
Random random = new Random(); //Random是一个随机数工具类
random
.ints(-100, 100) //生成-100~100之间的,随机int型数字(本质上是一个IntStream)
.limit(10) //只获取前10个数字(这是一个无限制的流,如果不加以限制,将会无限进行下去!)
.filter(i -> i < 0) //只保留小于0的数字
.sorted() //默认从小到大排序
.forEach(System.out::println); //依次打印
}
我们可以生成一个统计实例来帮助我们快速进行统计:
public static void main(String[] args) {
Random random = new Random(); //Random是一个随机数工具类
IntSummaryStatistics statistics = random
.ints(0, 100)
.limit(100)
.summaryStatistics(); //获取语法统计实例
System.out.println(statistics.getMax()); //快速获取最大值
System.out.println(statistics.getCount()); //获取数量
System.out.println(statistics.getAverage()); //获取平均值
}
普通的List只需要一个方法就可以直接转换到方便好用的IntStream了:
public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(1);
list.add(2);
list.add(3);
list.add(4);
list.stream()
.mapToInt(i -> i) //将每一个元素映射为Integer类型(这里因为本来就是Integer)
.summaryStatistics();
}
我们还可以通过flat来对整个流进行进一步细分:
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("A,B");
list.add("C,D");
list.add("E,F"); //我们想让每一个元素通过,进行分割,变成独立的6个元素
list = list
.stream() //生成流
.flatMap(e -> Arrays.stream(e.split(","))) //分割字符串并生成新的流
.collect(Collectors.toList()); //汇成新的List
System.out.println(list); //得到结果
}
我们也可以只通过Stream来完成所有数字的和,使用reduce方法:
public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
int sum = list
.stream()
.reduce((a, b) -> a + b) //计算规则为:a是上一次计算的值,b是当前要计算的参数,这里是求和
.get(); //我们发现得到的是一个Optional类实例,不是我们返回的类型,通过get方法返回得到的值
System.out.println(sum);
}
通过上面的例子,我们发现,Stream不喜欢直接给我们返回一个结果,而是通过Optinal的方式,那么什么是Optional呢?
Optional类是Java8为了解决null值判断问题,使用Optional类可以避免显式的null值判断(null的防御性检查),避免null导致的NPE(NullPointerException)。总而言之,就是对控制的一个判断,为了避免空指针异常。
public static void main(String[] args) {
String str = null;
if(str != null){ //当str不为空时添加元素到List中
list.add(str);
}
}
有了Optional之后,我们就可以这样写:
public static void main(String[] args) {
String str = null;
Optional<String> optional = Optional.ofNullable(str); //转换为Optional
optional.ifPresent(System.out::println); //当存在时再执行方法
}
就类似于Kotlin中的:
var str : String? = null
str?.upperCase()
我们可以选择直接get或是当值为null时,获取备选值:
public static void main(String[] args) {
String str = null;
Optional optional = Optional.ofNullable(str); //转换为Optional(可空)
System.out.println(optional.orElse("lbwnb"));
// System.out.println(optional.get()); 这样会直接报错
}
同样的,Optional也支持过滤操作和映射操作,不过是对于单对象而言:
public static void main(String[] args) {
String str = "A";
Optional optional = Optional.ofNullable(str); //转换为Optional(可空)
System.out.println(optional.filter(s -> s.equals("B")).get()); //被过滤了,此时元素为null,获取时报错
}
public static void main(String[] args) {
List<String> list = new ArrayList<>();
String str = "A";
Optional optional = Optional.ofNullable(str); //转换为Optional(可空)
System.out.println(optional.map(s -> s + "A").get()); //在尾部追加一个A
}
其他操作自学了解。
Arrays和Collections的使用
Arrays是一个用于操作数组的工具类,它给我们提供了大量的工具方法:
/**
* This class contains various methods for manipulating arrays (such as
* sorting and searching). This class also contains a static factory
* that allows arrays to be viewed as lists. <- 注意,这句话很关键
*
* @author Josh Bloch
* @author Neal Gafter
* @author John Rose
* @since 1.2
*/
public class Arrays {
由于操作数组并不像集合那样方便,因此JDK提供了Arrays类来增强对数组操作,比如:
public static void main(String[] args) {
int[] array = {1, 5, 2, 4, 7, 3, 6};
Arrays.sort(array); //直接进行排序(底层原理:进行判断,元素少使用插入排序,大量元素使用双轴快速/归并排序)
System.out.println(array); //由于int[]是一个对象类型,而数组默认是没有重写toString()方法,因此无法打印到想要的结果
System.out.println(Arrays.toString(array)); //我们可以使用Arrays.toString()来像集合一样直接打印每一个元素出来
}
public static void main(String[] args) {
int[] array = {1, 5, 2, 4, 7, 3, 6};
Arrays.sort(array);
System.out.println("排序后的结果:"+Arrays.toString(array));
System.out.println("目标元素3位置为:"+Arrays.binarySearch(array, 3)); //二分搜素,必须是已经排序好的数组!
}
public static void main(String[] args) {
int[] array = {1, 5, 2, 4, 7, 3, 6};
Arrays
.stream(array) //将数组转换为流进行操作
.sorted()
.forEach(System.out::println);
}
public static void main(String[] args) {
int[] array = {1, 5, 2, 4, 7, 3, 6};
int[] array2 = Arrays.copyOf(array, array.length); //复制一个一模一样的数组
System.out.println(Arrays.toString(array2));
System.out.println(Arrays.equals(array, array2)); //比较两个数组是否值相同
Arrays.fill(array, 0); //将数组的所有值全部填充为指定值
System.out.println(Arrays.toString(array));
Arrays.setAll(array2, i -> array2[i] + 2); //依次计算每一个元素(注意i是下标位置)
System.out.println(Arrays.toString(array2)); //这里计算让每个元素值+2
}
思考:当二维数组使用Arrays.equals()进行比较以及Arrays.toString()进行打印时,还会得到我们想要的结果吗?
public static void main(String[] args) {
Integer[][] array = {{1, 5}, {2, 4}, {7, 3}, {6}};
Integer[][] array2 = {{1, 5}, {2, 4}, {7, 3}, {6}};
System.out.println(Arrays.toString(array)); //这样还会得到我们想要的结果吗?
System.out.println(Arrays.equals(array2, array)); //这样还会得到true吗?
System.out.println(Arrays.deepToString(array)); //使用deepToString就能到打印多维数组
System.out.println(Arrays.deepEquals(array2, array)); //使用deepEquals就能比较多维数组
}
那么,一开始提到的当做List进行操作呢?我们可以使用Arrays.asList()来将数组转换为一个 固定长度的List
public static void main(String[] args) {
Integer[] array = {1, 5, 2, 4, 7, 3, 6};
List<Integer> list = Arrays.asList(array); //不支持基本类型数组,必须是对象类型数组
Arrays.asList("A", "B", "C"); //也可以逐个添加,因为是可变参数
list.add(1); //此List实现是长度固定的,是Arrays内部单独实现的一个类型,因此不支持添加操作
list.remove(0); //同理,也不支持移除
list.set(0, 8); //直接设置指定下标的值就可以
list.sort(Comparator.reverseOrder()); //也可以执行排序操作
System.out.println(list); //也可以像List那样直接打印
}
文字游戏:allows arrays to be viewed as lists,实际上只是当做List使用,本质还是数组,因此数组的属性依然存在!因此如果要将数组快速转换为实际的List,可以像这样:
public static void main(String[] args) {
Integer[] array = {1, 5, 2, 4, 7, 3, 6};
List<Integer> list = new ArrayList<>(Arrays.asList(array));
}
通过自行创建一个真正的ArrayList并在构造时将Arrays的List值传递。
既然数组操作都这么方便了,集合操作能不能也安排点高级的玩法呢?那必须的,JDK为我们准备的Collocations类就是专用于集合的工具类:
public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
Collections.max(list);
Collections.min(list);
}
当然,Collections提供的内容相比Arrays会更多,希望大家下去自行了解,这里就不多做介绍了。

