SpringCloud-初见
项目地址:https://gitee.com/zwtgit/spring-cloud-study
前言
微服务架构4个核心问题?
- 服务很多,客户端该怎么访问?
- 这么多服务? 服务之间如何通信?
- 这么多服务? 如何治理?
- 服务挂了怎么办?
解决方案:
- Spring Cloud NetFlix 一站式解决方案!
api网关,zuu1组件
Feign ---HttpClinet ---- Http通信方式,同步,阻塞
服务注册发现: Eureka
熔断机制: Hystrix ………… - Apache Dubbo ZooKeeper 半自动,需要整合别人的东西
- Spring Cloud Alibaba 一站式解决方案!更简单
新概念:服务网格,Server Mesh
但是他们的共同点是解决这几个问题:
-
API网关,服务路由
-
HTTP,RPC框架,异步调用
-
服务注册与发现,高可用
-
熔断机制,服务降级
为什么有这几个问题,还是因为网络的不可靠,所以我们要研究解决他们的方案。
微服务概述
什么是微服务?
微服务(Microservice Architecture) 是近几年流行的一种架构思想,关于它的概念很难一言以蔽之。
究竟什么是微服务呢?我们在此引用ThoughtWorks 公司的首席科学家 Martin Fowler 于2014年提出的一段话:
原文:https://martinfowler.com/articles/microservices.html
汉化:https://www.cnblogs.com/liuning8023/p/4493156.html
- 就目前而言,对于微服务,业界并没有一个统一的,标准的定义。
- 但通常而言,微服务架构是一种架构模式,或者说是一种架构风格,它提倡将单一的应用程序划分成一组小的服务,每个服务运行在其独立的自己的进程内,服务之间互相协调,互相配置,为用户提供最终价值,服务之间采用轻量级的通信机制(HTTP)互相沟通,每个服务都围绕着具体的业务进行构建,并且能够被独立的部署到生产环境中,另外,应尽量避免统一的,集中式的服务管理机制,对具体的一个服务而言,应该根据业务上下文,选择合适的语言,工具(Maven)对其进行构建,可以有一个非常轻量级的集中式管理来协调这些服务,可以使用不同的语言来编写服务,也可以使用不同的数据存储。
再来从技术维度角度理解下:
微服务化的核心就是将传统的一站式应用,根据业务拆分成一个一个的服务,彻底地去耦合,每一个微服务提供单个业务功能的服务,一个服务做一件事情,从技术角度看就是一种小而独立的处理过程,类似进程的概念,能够自行单独启动或销毁,拥有自己独立的数据库。
微服务与微服务架构
微服务
强调的是服务的大小,它关注的是某一个点,是具体解决某一个问题/提供落地对应服务的一个服务应用,狭义的看,可以看作是IDEA中的一个个微服务工程,或者Moudel。 IDEA 工具里面使用Maven开发的一个个独立的小Moudel,它具体是使用SpringBoot开发的一个小模块,专业的事情交给专业的模块来做,一个模块就做着一件事情。 强调的是一个个的个体,每个个体完成一个具体的任务或者功能。
微服务架构
一种新的架构形式,Martin Fowler 于2014年提出。
微服务架构是一种架构模式,它体长将单一应用程序划分成一组小的服务,服务之间相互协调,互相配合,为用户提供最终价值。每个服务运行在其独立的进程中,服务与服务之间采用轻量级的通信机制(如HTTP)互相协作,每个服务都围绕着具体的业务进行构建,并且能够被独立的部署到生产环境中,另外,应尽量避免统一的,集中式的服务管理机制,对具体的一个服务而言,应根据业务上下文,选择合适的语言、工具(如Maven)对其进行构建。
微服务优缺点
优点
- 单一职责原则;
- 每个服务足够内聚,足够小,代码容易理解,这样能聚焦一个指定的业务功能或业务需求;
- 开发简单,开发效率高,一个服务可能就是专一的只干一件事;
- 微服务能够被小团队单独开发,这个团队只需2-5个开发人员组成;
- 微服务是松耦合的,是有功能意义的服务,无论是在开发阶段或部署阶段都是独立的;
- 微服务能使用不同的语言开发;
- 易于和第三方集成,微服务允许容易且灵活的方式集成自动部署,通过持续集成工具,如jenkins,Hudson,bamboo;
- 微服务易于被一个开发人员理解,修改和维护,这样小团队能够更关注自己的工作成果,无需通过合作才能体现价值;
- 微服务允许利用和融合最新技术;
- 微服务只是业务逻辑的代码,不会和HTML,CSS,或其他的界面混合;
- 每个微服务都有自己的存储能力,可以有自己的数据库,也可以有统一的数据库;
缺点
- 开发人员要处理分布式系统的复杂性;
- 多服务运维难度,随着服务的增加,运维的压力也在增大;
- 系统部署依赖问题;
- 服务间通信成本问题;
- 数据一致性问题;
- 系统集成测试问题;
- 性能和监控问题;
微服务技术栈
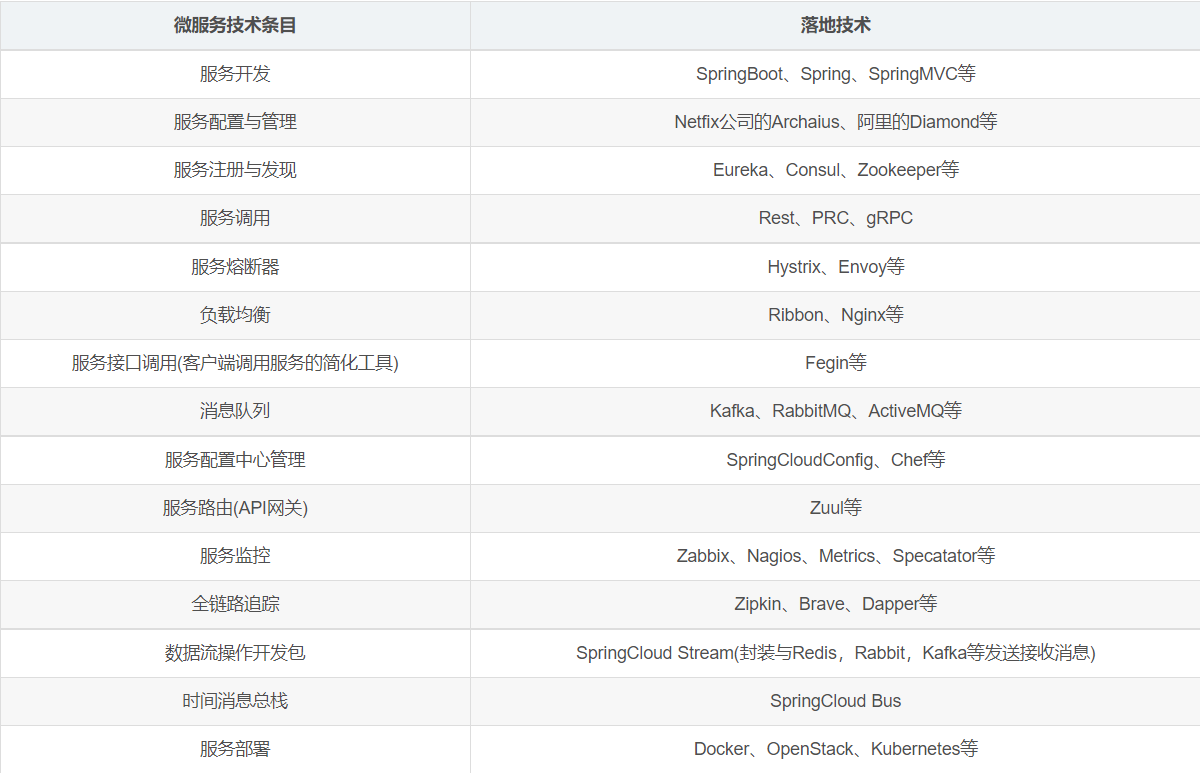
为什么选择SpringCloud作为微服务架构
-
选型依据
- 整体解决方案和框架成熟度
- 社区热度
- 可维护性
- 学习曲线
-
当前各大IT公司用的微服务架构有那些?
-
阿里:Dubbo+HFS
-
京东:JFS
-
新浪:Motan
-
当当网:DubboX
…
-
-
各微服务框架对比
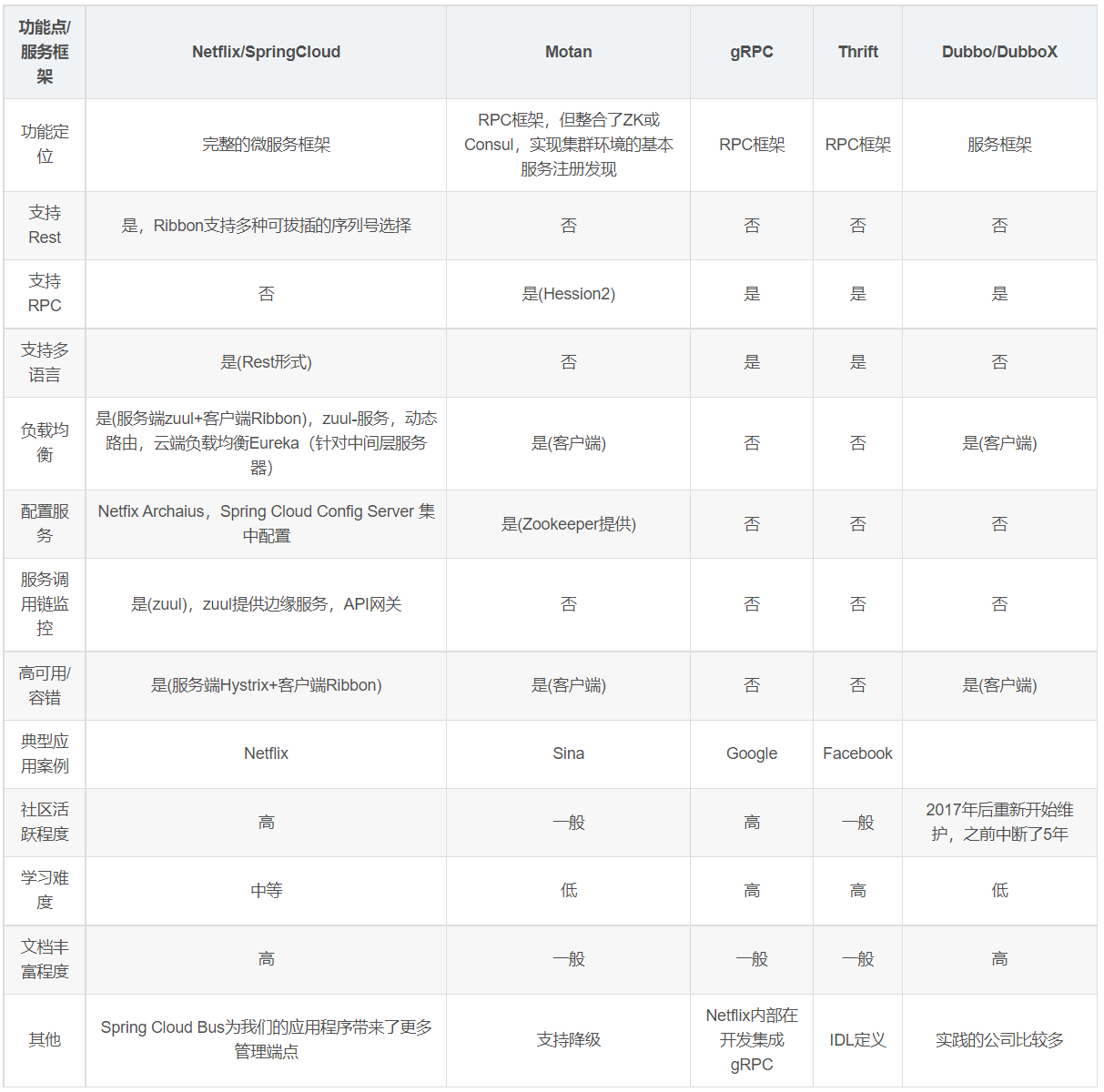
SpringCloud入门
Spring官网:https://spring.io/

SpringCloud,基于SpringBoot提供了一套微服务解决方案, 包括服务注册与发现,配置中心,全链路监控,服务网关,负载均衡,熔断器等组件,除了基于NetFlix的开源组件做高度抽象封装之外,还有一些选型中立的开源组件。
SpringCloud利用SpringBoot的开发便利性,巧妙地简化了分布式系统基础设施的开发, SpringCloud为开发人员提供了快速构建分布式系统的一些工具,包括配置管理,服务发现,断路器,路由,微代理,事件总线,全局锁,决策竞选,分布式会话等等,他们都可以用SpringBoot的开发风格做到一键启动和部署。
SpringBoot并没有重复造轮子,它只是将目前各家公司开发的比较成熟,经得起实际考验的服务框架组合起来,通过SpringBoot风格进行再封装,屏蔽掉了复杂的配置和实现原理,最终给开发者留出了一套简单易懂,易部署和易维护的分布式系统开发工具包。
SpringCloud是分布式微服务架构下的一站式解决方案,是各个微服务架构落地技术的集合体,俗称微服务全家桶。
SpringCloud和SpringBoot的关系
- SpringBoot专注于开发方便的开发单个个体微服务;
- SpringCloud是关注全局的微服务协调整理治理框架,它将SpringBoot开发的一个个单体微服务,整合并管理起来,为各个微服务之间提供:配置管理、服务发现、断路器、路由、为代理、事件总栈、全局锁、决策竞选、分布式会话等等集成服务;
- SpringBoot可以离开SpringCloud独立使用,开发项目,但SpringCloud离不开SpringBoot,属于依赖关系;
- SpringBoot专注于快速、方便的开发单个个体微服务,SpringCloud关注全局的服务治理框架;
Dubbo 和 SpringCloud技术选型
- 分布式+服务治理Dubbo
目前成熟的互联网架构,应用服务化拆分+消息中间件
- Dubbo 和 SpringCloud对比
可以看一下社区活跃度:
https://github.com/spring-cloud
设计模式+微服务拆分
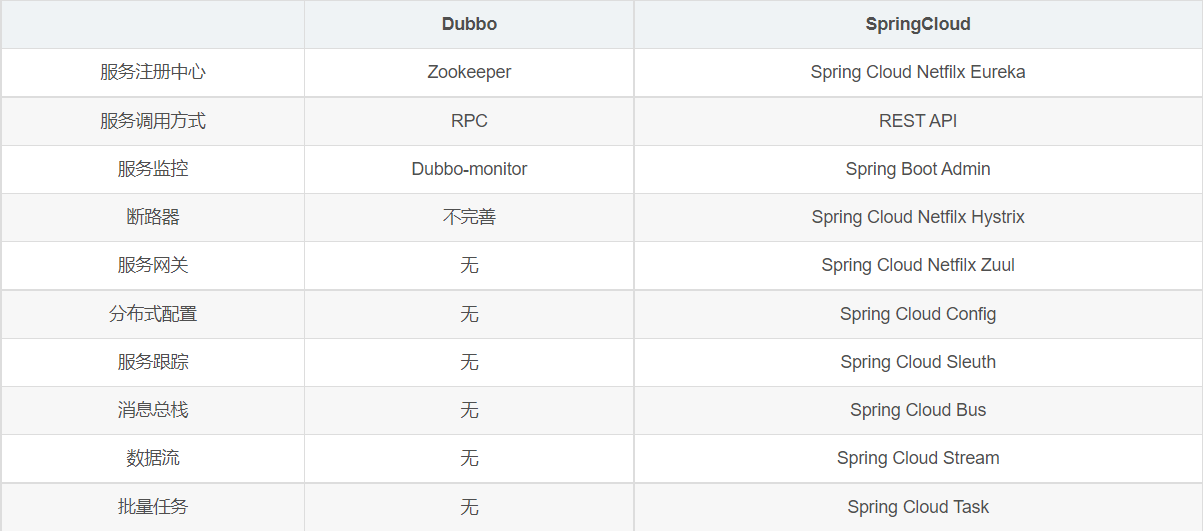
最大区别:Spring Cloud 抛弃了Dubbo的RPC通信,采用的是基于HTTP的REST方式
严格来说,这两种方式各有优劣。虽然从一定程度上来说,后者牺牲了服务调用的性能,但也避免了上面提到的原生RPC带来的问题。而且REST相比RPC更为灵活,服务提供方和调用方的依赖只依靠一纸契约,不存在代码级别的强依赖,这个优点在当下强调快速演化的微服务环境下,显得更加合适。
总结:
二者解决的问题域不一样:Dubbo的定位是一款RPC框架,而SpringCloud的目标是微服务架构下的一站式解决方案。
SpringCloud能干嘛?
- Distributed/versioned configuration 分布式/版本控制配置
- Service registration and discovery 服务注册与发现
- Routing 路由
- Service-to-service calls 服务到服务的调用
- Load balancing 负载均衡配置
- Circuit Breakers 断路器
- Distributed messaging 分布式消息管理
- …
SpringCloud下载
官网:http://projects.spring.io/spring-cloud/
SpringCloud没有采用数字编号的方式命名版本号,而是采用了伦敦地铁站的名称,同时根据字母表的顺序来对应版本时间顺序,比如最早的Realse版本:Angel,第二个Realse版本:Brixton,然后是Camden、Dalston、Edgware,目前最新的是Hoxton SR4 CURRENT GA通用稳定版。
学习资料:
SpringCloud Netflix 中文文档:https://springcloud.cc/spring-cloud-netflix.html
SpringCloud 中文API文档(官方文档翻译版):https://springcloud.cc/spring-cloud-dalston.html
SpringCloud中国社区:http://springcloud.cn/
SpringCloud中文网:https://springcloud.cc
Rest学习环境搭建
首先导入我们需要的依赖
<!--打包方式-->
<packaging>pom</packaging>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<junit.version>4.12</junit.version>
<log4j.version>1.2.17</log4j.version>
<lombok.version>1.16.18</lombok.version>
</properties>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-alibaba-dependencies</artifactId>
<version>0.2.0.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!--springCloud的依赖-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>Greenwich.SR1</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!--SpringBoot-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>2.1.4.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!--数据库-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.47</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.10</version>
</dependency>
<!--SpringBoot 启动器-->
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>1.3.2</version>
</dependency>
<!--日志测试~-->
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-core</artifactId>
<version>1.2.3</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>${junit.version}</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>${log4j.version}</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>${lombok.version}</version>
</dependency>
</dependencies>
</dependencyManagement>
API模块
新建数据库,Navicat中的springcloudstudy01,后面有多个数据库,因为是一个分布式的项目。

然后编写实体类,注意要序列化,ORM类表关系映射。
package com.zwt.springcloud.pojo;
import lombok.Data;
import lombok.NoArgsConstructor;
import lombok.experimental.Accessors;
import java.io.Serializable;
@Data
@NoArgsConstructor
@Accessors(chain = true) //链式写法
/*
Dept dept = new Dept()
dept.setDeptNo(11).setDname(''lijiatu).set…………
*/
public class Dept implements Serializable {
private Long deptno;
private String dname;
private String db_source;
public Dept(String dname) {
this.dname = dname;
}
}
这时候一个微服务就已经写好了。
Provider-8001模块
<!--因为要拿到实体类,所以要配置API模块-->
<dependencies>
<dependency>
<groupId>groupId</groupId>
<artifactId>API</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-core</artifactId>
</dependency>
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
</dependency>
<!--test-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-test</artifactId>
<version>2.1.4.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<version>2.1.4.RELEASE</version>
</dependency>
<!--jetty-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jetty</artifactId>
<version>2.1.4.RELEASE</version>
</dependency>
<!--热部署-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<version>2.5.2</version>
</dependency>
</dependencies>
mybatis-config.xml里面编写配置
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
</configuration>
dao层(或者叫mapper层)写接口,再在mapper文件夹中编写sql
package com.zwt.springcloud.dao;
import com.zwt.springcloud.pojo.Dept;
import org.apache.ibatis.annotations.Mapper;
import org.springframework.stereotype.Repository;
import java.util.List;
@Mapper
@Repository
public interface DeptDao {
public boolean addDept(Dept dept);
public Dept queryDept(Long id);
public List<Dept> queryAll();
}
mapper层
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.zwt.springcloud.dao">
<insert id="addDept" parameterType="Dept">
insert into dept (dname, db_source)
values (#{dname}, DATABASE())
</insert>
<select id="queryById" resultType="Dept" parameterType="Long">
select *
from dept
where deptno = #{deptno};
</select>
<select id="queryAll" resultType="Dept" parameterType="Long">
select *
from dept;
</select>
</mapper>
service层
package com.zwt.springcloud.service;
import com.zwt.springcloud.pojo.Dept;
import java.util.List;
public interface DeptService {
public boolean addDept(Dept dept);
public Dept queryById(Long id);
public List<Dept> queryAll();
}
//实现类
package com.zwt.springcloud.service;
import com.zwt.springcloud.dao.DeptDao;
import com.zwt.springcloud.pojo.Dept;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.List;
@Service
public class DeptServiceImpl implements DeptService{
@Autowired
private DeptDao deptDao;
@Override
public boolean addDept(Dept dept) {
return deptDao.addDept(dept);
}
@Override
public Dept queryById(Long id) {
return deptDao.queryById(id);
}
@Override
public List<Dept> queryAll() {
return deptDao.queryAll();
}
}
controller层
package com.zwt.springcloud.controller;
import com.zwt.springcloud.pojo.Dept;
import com.zwt.springcloud.service.DeptService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.List;
//提供Restful服务
@RestController
public class DeptController {
@Autowired
private DeptService deptService;
@PostMapping("/dept/add")
public boolean addDept(Dept dept) {
return deptService.addDept(dept);
}
@GetMapping("/dept/get/{id}")
public Dept queryById(@PathVariable("id") Long id) {
return deptService.queryById(id);
}
@PostMapping("/dept/list")
public List<Dept> queryAll() {
return deptService.queryAll();
}
}
启动类
package com.zwt.springcloud;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
//启动类
@SpringBootApplication
public class DeptProvider_8001 {
public static void main(String[] args) {
SpringApplication.run(DeptProvider_8001.class, args);
}
}
启动后发现上面代码中的 devtools版本不兼容,注释即可。
启动项目后报错,Invalid bound statement (not found),后发现是DeptMapper.xml中
<mapper namespace="com.zwt.springcloud.dao.DeptDao">
写成了
<mapper namespace="com.zwt.springcloud.dao">
导致没有对应到相应的文件,所以编写代码的时候要细心,bug也不可避免,检查要有条理,不着急。
consumer-80模块
添加依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>spring-cloud-study</artifactId>
<groupId>groupId</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>consumer-80</artifactId>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<!--实体类+web-->
<dependencies>
<dependency>
<groupId>groupId</groupId>
<artifactId>API</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
</dependencies>
</project>
application.yml
server:
port: 80
controller
package com.zwt.spingcloud.config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.client.RestTemplate;
/**
* @author ML李嘉图
* @version createtime: 2021-10-25
* Blog: https://www.cnblogs.com/zwtblog/
*/
@Configuration
public class ConfigBean {
// @Configuration----spring applicationContext.xml
@Bean
public RestTemplate getRestTemplate() {
return new RestTemplate();
}
}
package com.zwt.spingcloud.controller;
import com.zwt.springcloud.pojo.Dept;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.client.RestTemplate;
import java.util.List;
/**
* @author ML李嘉图
* @version createtime: 2021-10-25
* Blog: https://www.cnblogs.com/zwtblog/
*/
public class DeptConsumerController {
// 理解,消费者不应该有service层
// RestTemplate 供我们直接调用,注册到spring中
@Autowired
private RestTemplate restTemplate;
private static final String REST_URL_PREFIX = "http://localhost:8001";
@RequestMapping("/consumer/dept/add")
public boolean add(Dept dept) {
return restTemplate.postForObject(REST_URL_PREFIX + "/dept/add", dept, boolean.class);
}
@RequestMapping("/consumer/dept/get/{id}")
public Dept get(@PathVariable("id") Long id) {
return restTemplate.getForObject(REST_URL_PREFIX + "/dept/get" + id, Dept.class);
}
@RequestMapping("/consumer/dept/list")
public List<Dept> list() {
return restTemplate.getForObject(REST_URL_PREFIX + "/dept/list", List.class);
}
}
然后编写启动类,先启动provider载启动consumer。
Eureka
什么是Eureka?
- Netflix在涉及Eureka时,遵循的就是API原则。
- Eureka是Netflix的有个子模块,也是核心模块之一。Eureka是基于REST的服务,用于定位服务,以实现云端中间件层服务发现和故障转移,服务注册与发现对于微服务来说是非常重要的,有了服务注册与发现,只需要使用服务的标识符,就可以访问到服务,而不需要修改服务调用的配置文件了,功能类似于Dubbo的注册中心,比如Zookeeper。
原理理解
Eureka基本的架构
- SpringCloud 封装了Netflix公司开发的Eureka模块来实现服务注册与发现 (对比Zookeeper)。
- Eureka采用了C-S的架构设计,EurekaServer作为服务注册功能的服务器,他是服务注册中心。
- 而系统中的其他微服务,使用Eureka的客户端连接到EurekaServer并维持心跳连接。这样系统的维护人员就可以通过EurekaServer来监控系统中各个微服务是否正常运行,SpringCloud 的一些其他模块 (比如Zuul) 就可以通过EurekaServer来发现系统中的其他微服务,并执行相关的逻辑。
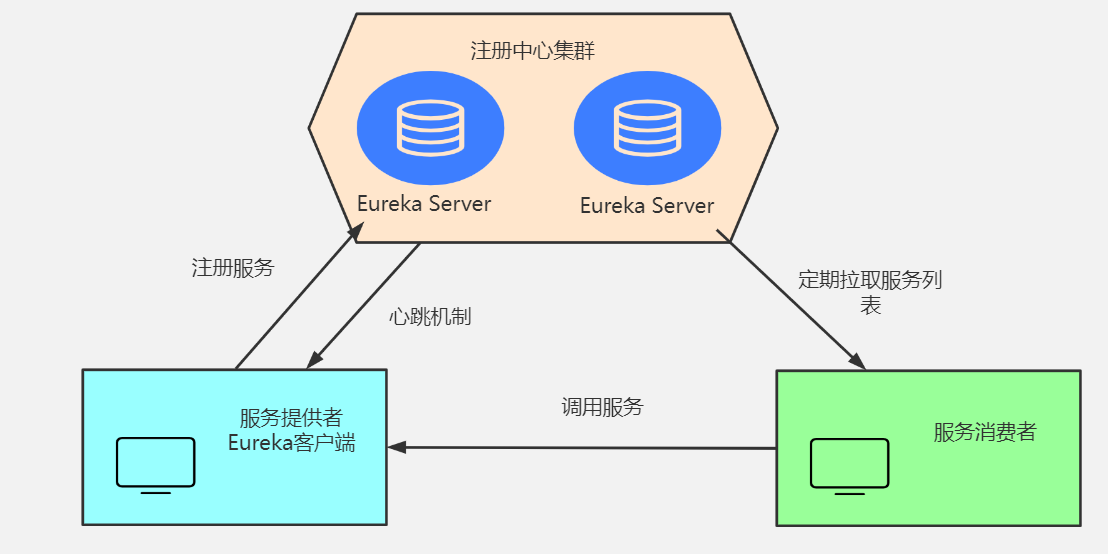
Eureka 包含两个组件:Eureka Server 和 Eureka Client。
-
Eureka Server 提供服务注册,各个节点启动后,回在EurekaServer中进行注册,这样Eureka Server中的服务注册表中将会储存所有课用服务节点的信息,服务节点的信息可以在界面中直观的看到。
-
Eureka Client 是一个Java客户端,用于简化EurekaServer的交互,客户端同时也具备一个内置的,使用轮询负载算法的负载均衡器。在应用启动后,将会向EurekaServer发送心跳 (默认周期为30秒) 。如果Eureka Server在多个心跳周期内没有接收到某个节点的心跳,EurekaServer将会从服务注册表中把这个服务节点移除掉 (默认周期为90s)。
-
三大角色
- Eureka Server:提供服务的注册与发现
- Service Provider:服务生产方,将自身服务注册到Eureka中,从而使服务消费方能狗找到
- Service Consumer:服务消费方,从Eureka中获取注册服务列表,从而找到消费服务
构建步骤(重点)-所有的服务收都是这个步骤
1. 导入依赖
2. 编写配置文件
3. 开启这个功能 @EnableXXX
4. 配置类
导入依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-eureka-server</artifactId>
<version>1.4.6.RELEASE</version>
</dependency>
编写配置文件
server:
port: 7001
eureka:
instance:
hostname: localhost
client:
register-with-eureka: false
fetch-registry: false
service-url:
defaultZone: http://${eureka.instance.hostname}:${server.port}/eureka/
开启这个功能 @EnableXXX
package com.zwt.springcloud;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.netflix.eureka.server.EnableEurekaServer;
/**
* @author ML李嘉图
* @version createtime: 2021-10-25
* Blog: https://www.cnblogs.com/zwtblog/
*/
@SpringBootApplication
@EnableEurekaServer
public class EurekaServer_7001 {
public static void main(String[] args) {
SpringApplication.run(EurekaServer_7001.class, args);
}
}
Eureka服务注册
要注册服务,所以在Provider-8001中添加Eureka的依赖并且编写相应的配置。
eureka:
client:
service-url:
defaultZone: http://localhost:7001/eureka/
info:
app.name: zwt
blog.name: https://www.cnblogs.com/zwtblog/
@EnableEurekaServer一下
Eureka自我保护机制
一句话总结就是:某时刻某一个微服务不可用,Eureka不会立即清理,依旧会对该微服务的信息进行保存!
- 默认情况下,当eureka server在一定时间内没有收到实例的心跳,便会把该实例从注册表中删除(默认是90秒),但是,如果短时间内丢失大量的实例心跳,便会触发eureka server的自我保护机制,比如在开发测试时,需要频繁地重启微服务实例,但是我们很少会把eureka server一起重启(因为在开发过程中不会修改eureka注册中心),当一分钟内收到的心跳数大量减少时,会触发该保护机制。可以在eureka管理界面看到Renews threshold和Renews(last min),当后者(最后一分钟收到的心跳数)小于前者(心跳阈值)的时候,触发保护机制,会出现红色的警告:EMERGENCY!EUREKA MAY BE INCORRECTLY CLAIMING INSTANCES ARE UP WHEN THEY’RE NOT.RENEWALS ARE LESSER THAN THRESHOLD AND HENCE THE INSTANCES ARE NOT BEGING EXPIRED JUST TO BE SAFE. 从警告中可以看到,eureka认为虽然收不到实例的心跳,但它认为实例还是健康的,eureka会保护这些实例,不会把它们从注册表中删掉。
- 该保护机制的目的是避免网络连接故障,在发生网络故障时,微服务和注册中心之间无法正常通信,但服务本身是健康的,不应该注销该服务,如果eureka因网络故障而把微服务误删了,那即使网络恢复了,该微服务也不会重新注册到eureka server了,因为只有在微服务启动的时候才会发起注册请求,后面只会发送心跳和服务列表请求,这样的话,该实例虽然是运行着,但永远不会被其它服务所感知。所以,eureka server在短时间内丢失过多的客户端心跳时,会进入自我保护模式,该模式下,eureka会保护注册表中的信息,不在注销任何微服务,当网络故障恢复后,eureka会自动退出保护模式。自我保护模式可以让集群更加健壮。
- 但是我们在开发测试阶段,需要频繁地重启发布,如果触发了保护机制,则旧的服务实例没有被删除,这时请求有可能跑到旧的实例中,而该实例已经关闭了,这就导致请求错误,影响开发测试。所以,在开发测试阶段,我们可以把自我保护模式关闭,只需在eureka server配置文件中加上如下配置即可:eureka.server.enable-self-preservation=false
DeptController.java新增方法, //获取一些配置的信息,得到具体的微服务!
//获取一些配置的信息,得到具体的微服务!
@Autowired
private DiscoveryClient client;
//注册进来的微服务~,获取一些消息~
@GetMapping("/dept/discovery")
public Object discovery() {
//获取微服务列表的清单
List<String> services = client.getServices();
System.out.println("discovery=>services:" + services);
//得到一个具体的微服务信息,通过具体的微服务id,applicaioinName;
List<ServiceInstance> instances = client.getInstances("SPRINGCLOUD-PROVIDER-DEPT");
for (ServiceInstance instance : instances) {
System.out.println(
instance.getHost() + "\t" + // 主机名称
instance.getPort() + "\t" + // 端口号
instance.getUri() + "\t" + // uri
instance.getServiceId() // 服务id
);
}
return this.client;
}
Eureka集群配置
简单复制一下
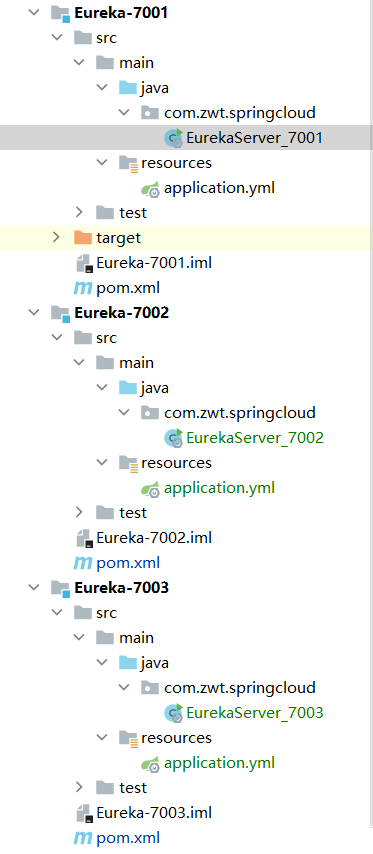
但是这三个现在还没有关系,所以我们配置他们之间的关系。
改一下host之后这三个的配置文件是:

server:
port: 7001
eureka:
instance:
hostname: eureka7001.com
client:
register-with-eureka: false
fetch-registry: false
service-url:
# defaultZone: http://${eureka.instance.hostname}:${server.port}/eureka/
defaultZone: http://eureka7002.com:7002/eureka/,http://eureka7003.com:7003/eureka/
server:
port: 7002
eureka:
instance:
hostname: eureka7002.com
client:
register-with-eureka: false
fetch-registry: false
service-url:
defaultZone: http://eureka7001.com:7001/eureka/,http://eureka7003.com:7003/eureka/
server:
port: 7003
eureka:
instance:
hostname: eureka7003.com
client:
register-with-eureka: false
fetch-registry: false
service-url:
defaultZone: http://eureka7001.com:7001/eureka/,http://eureka7002.com:7002/eureka/
然后把发布服务中的配置也修改一下,启动三个注册中心,再启动服务。
eureka:
client:
service-url:
defaultZone: http://eureka7001.com:7001/eureka/,http://eureka7002.com:7002/eureka/,http://eureka7003.com:7003/eureka/
EurekaCAP原则和对比Zookeeper
CAP原则又称CAP定理,指的是在一个分布式系统中,一致性(Consistency)、可用性(Availability)、分区容错性(Partition tolerance)。CAP 原则指的是,这三个要素最多只能同时实现两点,不可能三者兼顾。
一个分布式系统不可能同时很好的满足一致性,可用性和分区容错性这三个需求,根据CAP原理,将NoSQL数据库分成了满足CA原则,满足CP原则和满足AP原则三大类:
- CA:单点集群,满足一致性,可用性的系统,通常可扩展性较差
- CP:满足一致性,分区容错的系统,通常性能不是特别高
- AP:满足可用性,分区容错的系统,通常可能对一致性要求低一些
Zookeeper保证的是CP
当向注册中心查询服务列表时,我们可以容忍注册中心返回的是几分钟以前的注册信息,但不能接收服务直接down掉不可用。也就是说,服务注册功能对可用性的要求要高于一致性。但zookeeper会出现这样一种情况,当master节点因为网络故障与其他节点失去联系时,剩余节点会重新进行leader选举。问题在于,选举leader的时间太长,30-120s,且选举期间整个zookeeper集群是不可用的,这就导致在选举期间注册服务瘫痪。在云部署的环境下,因为网络问题使得zookeeper集群失去master节点是较大概率发生的事件,虽然服务最终能够恢复,但是,漫长的选举时间导致注册长期不可用,是不可容忍的。
Eureka保证的是AP
Eureka看明白了这一点,因此在设计时就优先保证可用性。Eureka各个节点都是平等的,几个节点挂掉不会影响正常节点的工作,剩余的节点依然可以提供注册和查询服务。而Eureka的客户端在向某个Eureka注册时,如果发现连接失败,则会自动切换至其他节点,只要有一台Eureka还在,就能保住注册服务的可用性,只不过查到的信息可能不是最新的,除此之外,Eureka还有之中自我保护机制,如果在15分钟内超过85%的节点都没有正常的心跳,那么Eureka就认为客户端与注册中心出现了网络故障,此时会出现以下几种情况:
- Eureka不在从注册列表中移除因为长时间没收到心跳而应该过期的服务
- Eureka仍然能够接受新服务的注册和查询请求,但是不会被同步到其他节点上 (即保证当前节点依然可用)
- 当网络稳定时,当前实例新的注册信息会被同步到其他节点中
因此,Eureka可以很好的应对因网络故障导致部分节点失去联系的情况,而不会像zookeeper那样使整个注册服务瘫痪。
Ribbon
是什么?
- Spring Cloud Ribbon 是基于Netflix Ribbon 实现的一套客户端负载均衡的工具。
- 简单的说,Ribbon 是 Netflix 发布的开源项目,主要功能是提供客户端的软件负载均衡算法,将 Netflix 的中间层服务连接在一起。Ribbon 的客户端组件提供一系列完整的配置项,如:连接超时、重试等。简单的说,就是在配置文件中列出 LoadBalancer (简称LB:负载均衡) 后面所有的及其,Ribbon 会自动的帮助你基于某种规则 (如简单轮询,随机连接等等) 去连接这些机器。我们也容易使用 Ribbon 实现自定义的负载均衡算法。
Ribbon能干嘛?
- LB,即负载均衡 (LoadBalancer) ,在微服务或分布式集群中经常用的一种应用。
- 负载均衡简单的说就是将用户的请求平摊的分配到多个服务上,从而达到系统的HA (高用)。
- 常见的负载均衡软件有 Nginx、Lvs 等等。
- Dubbo、SpringCloud 中均给我们提供了负载均衡,SpringCloud 的负载均衡算法可以自定义。
- 负载均衡简单分类:
- 集中式LB
- 即在服务的提供方和消费方之间使用独立的LB设施,如Nginx,由该设施负责把访问请求通过某种策略转发至服务的提供方。
- 进程式LB
- 将LB逻辑集成到消费方,消费方从服务注册中心获知有哪些地址可用,然后自己再从这些地址中选出一个合适的服务器。
- Ribbon 就属于进程内LB,它只是一个类库,集成于消费方进程,消费方通过它来获取到服务提供方的地址。
- 集中式LB
使用Ribbon实现负载均衡
导入依赖-80
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-ribbon</artifactId>
<version>1.4.6.RELEASE</version>
</dependency>
配置
server:
port: 80
eureka:
client:
register-with-eureka: false
service-url:
defaultZone: http://eureka7001.com:7001/eureka/,http://eureka7002.com:7002/eureka/,http://eureka7003.com:7003/eureka/
再使用@EnableEurekaClient开启Eureka服务以及@LoadBalanced使用负载均衡。
更改controller的地址
// private static final String REST_URL_PREFIX = "http://localhost:8001";
private static final String REST_URL_PREFIX = "http://PROVIDER";
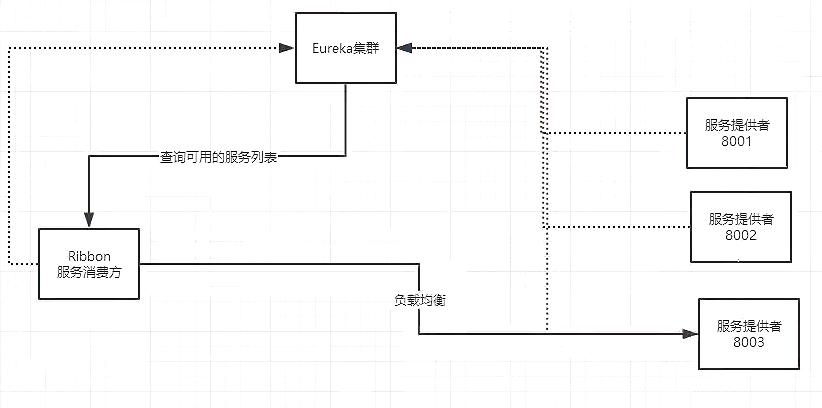
为了观察负载均衡的效果,我们设计多个数据库来看
sql语句:
/*
Navicat MySQL Data Transfer
Source Server : MySQL
Source Server Version : 80020
Source Host : localhost:3306
Source Database : springcloudstudy01
Target Server Type : MYSQL
Target Server Version : 80020
File Encoding : 65001
*/
SET FOREIGN_KEY_CHECKS=0;
-- ----------------------------
-- Table structure for dept
-- ----------------------------
DROP TABLE IF EXISTS `dept`;
CREATE TABLE `dept` (
`deptno` bigint NOT NULL AUTO_INCREMENT,
`dname` varchar(60) DEFAULT NULL,
`db_source` varchar(60) DEFAULT NULL,
PRIMARY KEY (`deptno`)
) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=utf8 COMMENT='部门表';
-- ----------------------------
-- Records of dept
-- ----------------------------
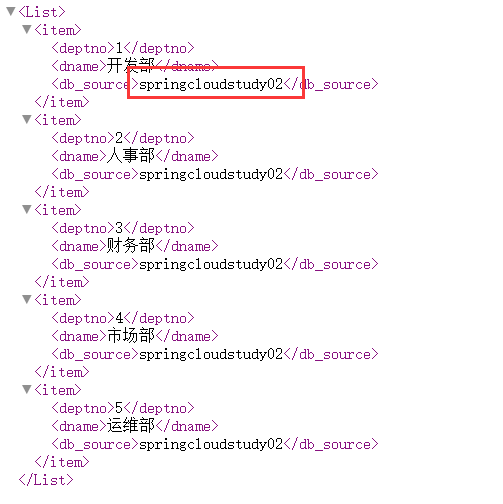
INSERT INTO `dept` VALUES ('1', '开发部', 'springcloudstudy01');
INSERT INTO `dept` VALUES ('2', '人事部', 'springcloudstudy01');
INSERT INTO `dept` VALUES ('3', '财务部', 'springcloudstudy01');
INSERT INTO `dept` VALUES ('4', '市场部', 'springcloudstudy01');
INSERT INTO `dept` VALUES ('5', '运维部', 'springcloudstudy01');
然后Provider-8001也要同步变为Provider-8002和Provider-8003。
效果图:
自定义负载均衡算法
@SpringBootApplication
@EnableEurekaClient
@RibbonClient(name = "Provider",configuration = zwtRule.class)
public class DeptConsumer_80 {
public static void main(String[] args) {
SpringApplication.run(DeptConsumer_80.class, args);
}
}
@Configuration
public class zwtRule extends AbstractLoadBalancerRule {
/**
* 每个服务访问5次则换下一个服务(总共3个服务)
* <p>
* total=0,默认=0,如果=5,指向下一个服务节点
* index=0,默认=0,如果total=5,index+1
*/
private int total = 0;//被调用的次数
private int currentIndex = 0;//当前是谁在提供服务
//@edu.umd.cs.findbugs.annotations.SuppressWarnings(value = "RCN_REDUNDANT_NULLCHECK_OF_NULL_VALUE")
public Server choose(ILoadBalancer lb, Object key) {
if (lb == null) {
return null;
}
Server server = null;
while (server == null) {
if (Thread.interrupted()) {
return null;
}
List<Server> upList = lb.getReachableServers();//获得当前活着的服务
List<Server> allList = lb.getAllServers();//获取所有的服务
int serverCount = allList.size();
if (serverCount == 0) {
/*
* No servers. End regardless of pass, because subsequent passes
* only get more restrictive.
*/
return null;
}
//int index = chooseRandomInt(serverCount);//生成区间随机数
//server = upList.get(index);//从或活着的服务中,随机获取一个
//=====================自定义代码=========================
if (total < 5) {
server = upList.get(currentIndex);
total++;
} else {
total = 0;
currentIndex++;
if (currentIndex > upList.size()) {
currentIndex = 0;
}
server = upList.get(currentIndex);//从活着的服务中,获取指定的服务来进行操作
}
//======================================================
if (server == null) {
/*
* The only time this should happen is if the server list were
* somehow trimmed. This is a transient condition. Retry after
* yielding.
*/
Thread.yield();
continue;
}
if (server.isAlive()) {
return (server);
}
// Shouldn't actually happen.. but must be transient or a bug.
server = null;
Thread.yield();
}
return server;
}
protected int chooseRandomInt(int serverCount) {
return ThreadLocalRandom.current().nextInt(serverCount);
}
@Override
public Server choose(Object key) {
return choose(getLoadBalancer(), key);
}
@Override
public void initWithNiwsConfig(IClientConfig clientConfig) {
// TODO Auto-generated method stub
}
}
Feign
Feign简介
Feign是声明式Web Service客户端,它让微服务之间的调用变得更简单,类似controller调用service。SpringCloud集成了Ribbon和Eureka,可以使用Feigin提供负载均衡的http客户端
只需要创建一个接口,然后添加注解即可。
Feign,主要是社区版,大家都习惯面向接口编程。这个是很多开发人员的规范。调用微服务访问两种方法:
- 微服务名字 【ribbon】
- 接口和注解 【feign】
Feign能干什么?
- Feign旨在使编写Java Http客户端变得更容易
- 前面在使用Ribbon + RestTemplate时,利用RestTemplate对Http请求的封装处理,形成了一套模板化的调用方法。但是在实际开发中,由于对服务依赖的调用可能不止一处,往往一个接口会被多处调用,所以通常都会针对每个微服务自行封装一个客户端类来包装这些依赖服务的调用。所以,Feign在此基础上做了进一步的封装,由他来帮助我们定义和实现依赖服务接口的定义,在Feign的实现下,我们只需要创建一个接口并使用注解的方式来配置它 (类似以前Dao接口上标注Mapper注解,现在是一个微服务接口上面标注一个Feign注解),即可完成对服务提供方的接口绑定,简化了使用Spring Cloud Ribbon 时,自动封装服务调用客户端的开发量。
Feign默认集成了Ribbon
利用Ribbon维护了MicroServiceCloud-Dept的服务列表信息,并且通过轮询实现了客户端的负载均衡,而与Ribbon不同的是,通过Feign只需要定义服务绑定接口且以声明式的方法,优雅而简单的实现了服务调用。
Hystrix
分布式系统面临的问题
复杂分布式体系结构中的应用程序有数十个依赖关系,每个依赖关系在某些时候将不可避免失败!
服务雪崩
多个微服务之间调用的时候,假设微服务A调用微服务B和微服务C,微服务B和微服务C又调用其他的微服务,这就是所谓的“扇出”,如果扇出的链路上某个微服务的调用响应时间过长,或者不可用,对微服务A的调用就会占用越来越多的系统资源,进而引起系统崩溃,所谓的“雪崩效应”。
对于高流量的应用来说,单一的后端依赖可能会导致所有服务器上的所有资源都在几十秒内饱和。比失败更糟糕的是,这些应用程序还可能导致服务之间的延迟增加,备份队列,线程和其他系统资源紧张,导致整个系统发生更多的级联故障,这些都表示需要对故障和延迟进行隔离和管理,以便单个依赖关系的失败,不能取消整个应用程序或系统。
我们需要,弃车保帅。
什么是Hystrix?
Hystrix是一个应用于处理分布式系统的延迟和容错的开源库,在分布式系统里,许多依赖不可避免的会调用失败,比如超时,异常等,Hystrix能够保证在一个依赖出问题的情况下,不会导致整个体系服务失败,避免级联故障,以提高分布式系统的弹性。
“断路器”本身是一种开关装置,当某个服务单元发生故障之后,通过断路器的故障监控 (类似熔断保险丝) ,向调用方方茴一个服务预期的,可处理的备选响应 (FallBack) ,而不是长时间的等待或者抛出调用方法无法处理的异常,这样就可以保证了服务调用方的线程不会被长时间,不必要的占用,从而避免了故障在分布式系统中的蔓延,乃至雪崩。
Hystrix能干嘛?
- 服务降级
- 服务熔断
- 服务限流
- 接近实时的监控
…
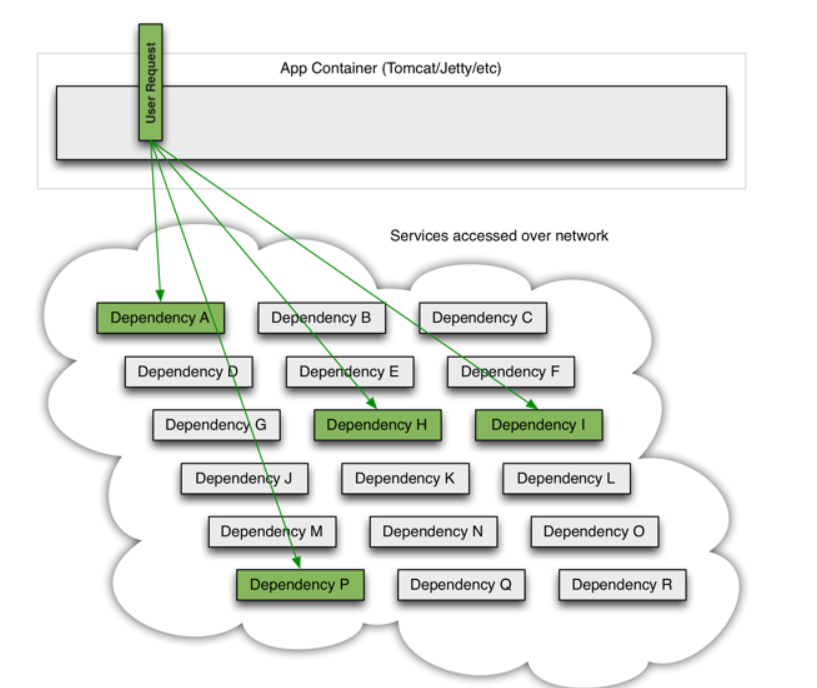
当一切正常时,请求流可以如下所示:
当许多后端系统中有一个问题时,它可以阻止整个用户请求:
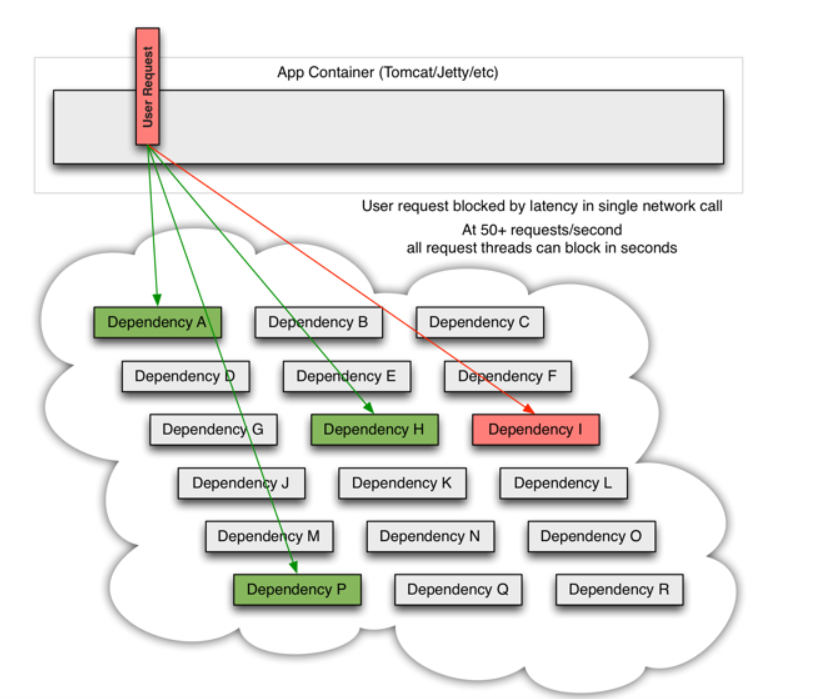
随着大容量通信量的增加,单个后端依赖项的潜在性会导致所有服务器上的所有资源在几秒钟内饱和。
应用程序中通过网络或客户端库可能导致网络请求的每个点都是潜在故障的来源。比失败更糟糕的是,这些应用程序还可能导致服务之间的延迟增加,从而备份队列、线程和其他系统资源,从而导致更多跨系统的级联故障。
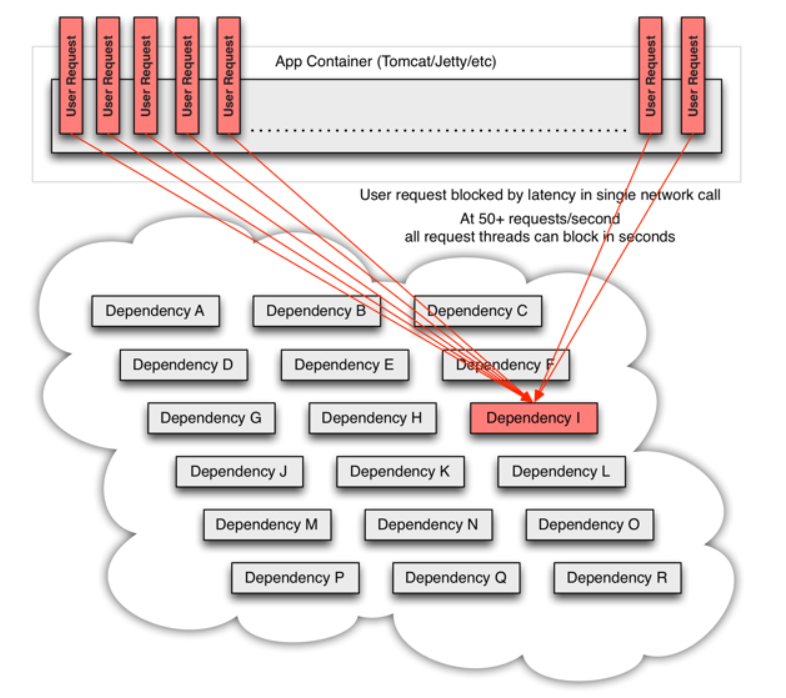
当使用hystrix包装每个基础依赖项时,上面的图表中所示的体系结构会发生类似于以下关系图的变化。每个依赖项是相互隔离的,限制在延迟发生时它可以填充的资源中,并包含在回退逻辑中,该逻辑决定在依赖项中发生任何类型的故障时要做出什么样的响应:
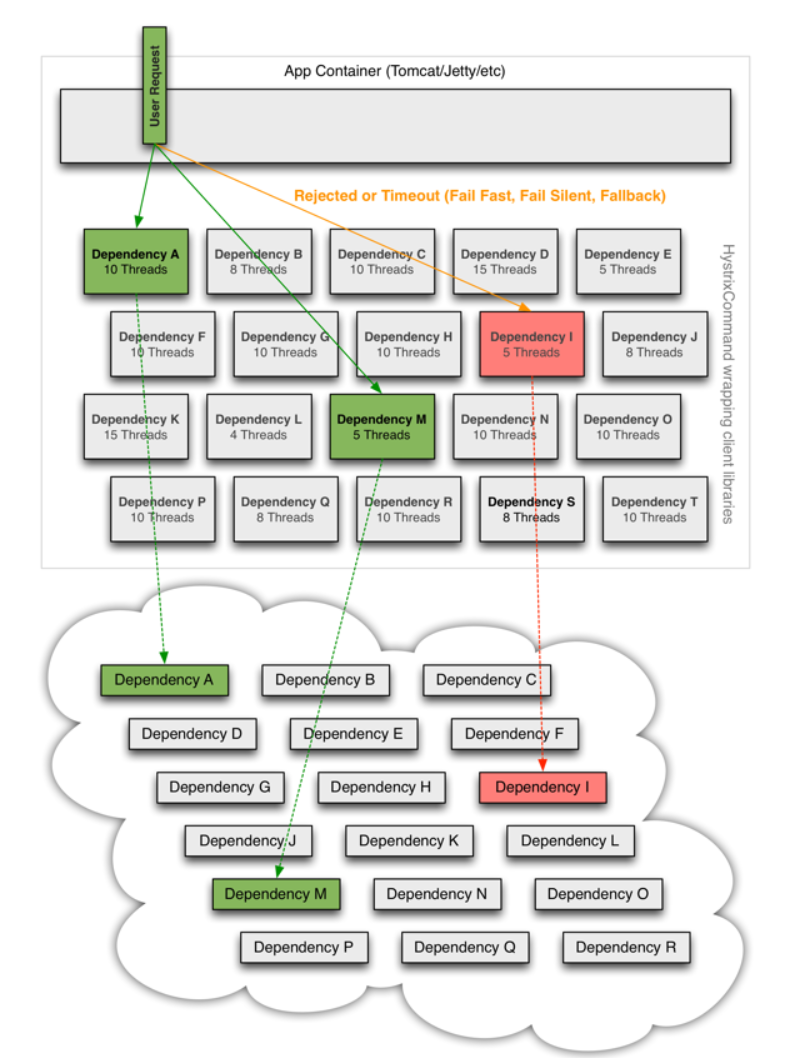
官网资料:https://github.com/Netflix/Hystrix/wiki
服务熔断
什么是服务熔断?
熔断机制是雪崩效应的一种微服务链路保护机制。
在微服务架构中,微服务之间的数据交互通过远程调用完成,微服务A调用微服务B和微服务C,微服务B和微服务C又调用其它的微服务,此时如果链路上某个微服务的调用响应时间过长或者不可用,那么对微服务A的调用就会占用越来越多的系统资源,进而引起系统崩溃,导致“雪崩效应”。
服务熔断是应对雪崩效应的一种微服务链路保护机制。例如在高压电路中,如果某个地方的电压过高,熔断器就会熔断,对电路进行保护。同样,在微服务架构中,熔断机制也是起着类似的作用。当调用链路的某个微服务不可用或者响应时间太长时,会进行服务熔断,不再有该节点微服务的调用,快速返回错误的响应信息。当检测到该节点微服务调用响应正常后,恢复调用链路。
当扇出链路的某个微服务不可用或者响应时间太长时,会进行服务的降级,进而熔断该节点微服务的调用,快速返回错误的响应信息。检测到该节点微服务调用响应正常后恢复调用链路。在SpringCloud框架里熔断机制通过Hystrix实现。Hystrix会监控微服务间调用的状况,当失败的调用到一定阀值缺省是5秒内20次调用失败,就会启动熔断机制。熔断机制的注解是:@HystrixCommand 。
服务熔断解决如下问题:
- 当所依赖的对象不稳定时,能够起到快速失败的目的;
- 快速失败后,能够根据一定的算法动态试探所依赖对象是否恢复。
为了避免因某个微服务后台出现异常或错误而导致整个应用或网页报错,使用熔断是必要的。
服务降级
服务降级是指 当服务器压力剧增的情况下,根据实际业务情况及流量,对一些服务和页面有策略的不处理或换种简单的方式处理,从而释放服务器资源以保证核心业务正常运作或高效运作。说白了,就是尽可能的把系统资源让给优先级高的服务。
资源有限,而请求是无限的。如果在并发高峰期,不做服务降级处理,一方面肯定会影响整体服务的性能,严重的话可能会导致宕机某些重要的服务不可用。所以,一般在高峰期,为了保证核心功能服务的可用性,都要对某些服务降级处理。比如当双11活动时,把交易无关的服务统统降级,如查看蚂蚁深林,查看历史订单等等。
服务降级主要用于什么场景呢?
当整个微服务架构整体的负载超出了预设的上限阈值或即将到来的流量预计将会超过预设的阈值时,为了保证重要或基本的服务能正常运行,可以将一些 不重要 或 不紧急 的服务或任务进行服务的 延迟使用 或 暂停使用。降级的方式可以根据业务来,可以延迟服务,比如延迟给用户增加积分,只是放到一个缓存中,等服务平稳之后再执行 ;或者在粒度范围内关闭服务,比如关闭相关文章的推荐。
例子
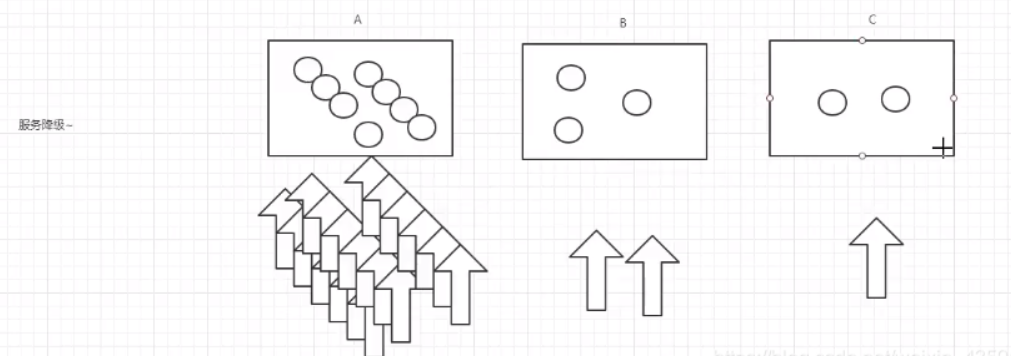
由上图可得,当某一时间内服务A的访问量暴增,而B和C的访问量较少,为了缓解A服务的压力,这时候需要B和C暂时关闭一些服务功能,去承担A的部分服务,从而为A分担压力,叫做服务降级。
服务降级需要考虑的问题
1)那些服务是核心服务,哪些服务是非核心服务?
2)那些服务可以支持降级,那些服务不能支持降级,降级策略是什么?
3)除服务降级之外是否存在更复杂的业务放通场景,策略是什么?
自动降级分类
1)超时降级:主要配置好超时时间和超时重试次数和机制,并使用异步机制探测回复情况。
2)失败次数降级:主要是一些不稳定的api,当失败调用次数达到一定阀值自动降级,同样要使用异步机制探测回复情况。
3)故障降级:比如要调用的远程服务挂掉了(网络故障、DNS故障、Http服务返回错误的状态码、RPC服务抛出异常),则可以直接降级。降级后的处理方案有:默认值(比如库存服务挂了,返回默认现货)、兜底数据(比如广告挂了,返回提前准备好的一些静态页面)、缓存(之前暂存的一些缓存数据)。
4)限流降级:秒杀或者抢购一些限购商品时,此时可能会因为访问量太大而导致系统崩溃,此时会使用限流来进行限制访问量,当达到限流阀值,后续请求会被降级;降级后的处理方案可以是:排队页面(将用户导流到排队页面等一会重试)、无货(直接告知用户没货了)、错误页(如活动太火爆了,稍后重试)。
服务熔断和降级的区别
- 服务熔断—>服务端:某个服务超时或异常,引起熔断,类似于保险丝(自我熔断)。
- 服务降级—>客户端:从整体网站请求负载考虑,当某个服务熔断或者关闭之后,服务将不再被调用,此时在客户端,我们可以准备一个 FallBackFactory ,返回一个默认的值(缺省值)。会导致整体的服务下降,但是好歹能用,比直接挂掉强。
- 触发原因不太一样,服务熔断一般是某个服务(下游服务)故障引起,而服务降级一般是从整体负荷考虑;管理目标的层次不太一样,熔断其实是一个框架级的处理,每个微服务都需要(无层级之分),而降级一般需要对业务有层级之分(比如降级一般是从最外围服务开始)。
- 实现方式不太一样,服务降级具有代码侵入性(由控制器完成/或自动降级),熔断一般称为自我熔断。
限流:限制并发的请求访问量,超过阈值则拒绝。
降级:服务分优先级,牺牲非核心服务(不可用),保证核心服务稳定;从整体负荷考虑。
熔断:依赖的下游服务故障触发熔断,避免引发本系统崩溃;系统自动执行和恢复。
入门案例
服务雪崩&服务熔断
package com.zwt.controller;
import com.netflix.hystrix.contrib.javanica.annotation.HystrixCommand;
import com.zwt.service.DeptService;
import com.zwt.springcloud.pojo.Dept;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RestController;
/**
* @author ML李嘉图
* @version createtime: 2021-10-26
* Blog: https://www.cnblogs.com/zwtblog/
*/
@RestController
public class DeptController {
@Autowired
private DeptService service;
@GetMapping("/dept/get/id")
@HystrixCommand(fallbackMethod = "hystrixGet")
public Dept get(@PathVariable("id") Long id) {
Dept dept = service.queryDeptById(id);
if (dept == null) {
throw new RuntimeException("id=>" + id + "不存在,无法获取");
}
return dept;
}
public Dept Hystrix_get(@PathVariable("id") Long id) {
return new Dept()
.setDeptno(id)
.setDname("id" + id)
.setDb_source("no");
}
}
启动类中使用@EnableCircuitBreaker启动,CircuitBreaker(断路器)
服务降级
@FeignClient(fallbackFactory = DeptServiceFallbackFactory.class)
package com.zwt.service;
import com.zwt.springcloud.pojo.Dept;
import com.zwt.springcloud.service.DeptClientService;
import feign.hystrix.FallbackFactory;
import org.springframework.stereotype.Component;
/**
* @author ML李嘉图
* @version createtime: 2021-10-26
* Blog: https://www.cnblogs.com/zwtblog/
*/
//降级
@Component
public class DeptServiceFallbackFactory implements FallbackFactory {
@Override
public Object create(Throwable throwable) {
return new DeptClientService() {
@Override
public Dept queryById(Long id) {
return new Dept()
.setDeptno(id)
.setDname("id" + id)
.setDb_source("no");
}
@Override
public Dept queryAll() {
return null;
}
@Override
public Dept add(Dept dept) {
return null;
}
};
}
}
feign:
hystrix:
enabled: true
Dashboard 流监控
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
<version>2.2.9.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix-dashboard</artifactId>
<version>2.2.9.RELEASE</version>
</dependency>
//开启Dashboard
@EnableHystrixDashboard
被监控的服务添加一个bean
public class DeptProvider_8001 {
public static void main(String[] args) {
SpringApplication.run(DeptProvider_8001.class, args);
}
//time: 2021/10/26
public ServletRegistrationBean hystrixMetricsStreamServlet() {
ServletRegistrationBean servletRegistrationBean = new ServletRegistrationBean(new HystrixMetricsStreamServlet());
servletRegistrationBean.addUrlMappings("/actuator/hystrix.stream");
return servletRegistrationBean;
}
}
Zuul
什么是Zuul?
Zull包含了对请求的路由(用来跳转的)和过滤两个最主要功能:
其中路由功能负责将外部请求转发到具体的微服务实例上,是实现外部访问统一入口的基础,而过滤器功能则负责对请求的处理过程进行干预,是实现请求校验,服务聚合等功能的基础。Zuul和Eureka进行整合,将Zuul自身注册为Eureka服务治理下的应用,同时从Eureka中获得其他服务的消息,也即以后的访问微服务都是通过Zuul跳转后获得。
注意:Zuul服务最终还是会注册进Eureka。
提供:代理+路由+过滤 三大功能
Zuul能干嘛?
-
路由
-
过滤
官方文档:https://github.com/Netflix/zuul/
入门案例
<!--导入zuul依赖-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zuul</artifactId
<version>1.4.6.RELEASE</version>
</dependency>
application.yml
zuul:
routes:
mydept.serviceId: springcloud-provider-dept # 原来id的名字
mydept.path: /mydept/**
ignored-services: "*" # 不能再使用某个(*:全部)路径访问了,ignored : 忽略,隐藏全部的~
prefix: /ljt # 设置公共的前缀,实现隐藏原有路由
@SpringBootApplication
@EnableZuulProxy //开启Zuul
public class ZuulApplication_9527 {
public static void main(String[] args) {
SpringApplication.run(ZuulApplication_9527.class,args);
}
}
详情参考springcloud中文社区zuul组件 :https://www.springcloud.cc/spring-cloud-greenwich.html#_router_and_filter_zuul
Config
Spring Cloud Config为分布式系统中的外部配置提供服务器和客户端支持。
使用Config Server,您可以在所有环境中管理应用程序的外部属性。客户端和服务器上的概念映射与Spring Environment和PropertySource抽象相同,因此它们与Spring应用程序非常契合,但可以与任何以任何语言运行的应用程序一起使用。随着应用程序通过从开发人员到测试和生产的部署流程,您可以管理这些环境之间的配置,并确定应用程序具有迁移时需要运行的一切。服务器存储后端的默认实现使用git,因此它轻松支持标签版本的配置环境,以及可以访问用于管理内容的各种工具。很容易添加替代实现,并使用Spring配置将其入。
总结
学无止境,加油。

