计算机网络-TCP篇
TCP篇
之前的总结文章:TCP简单版本介绍-三次握手等
基本认识
TCP 是⾯向连接的(⼀定是「⼀对⼀」才能连接)、可靠的、基于字节流的传输层通信协议。
RFC 793 是如何定义「连接」的:⽤于保证可靠性和流量控制维护的某些状态信息,这些信息的组合,包括Socket、序列号和窗⼝⼤⼩称为连接。
建⽴⼀个 TCP 连接是需要客户端与服务器端达成上述三个信息的共识。
Socket:由 IP 地址和端⼝号组成
序列号:⽤来解决乱序问题等
窗⼝⼤⼩:⽤来做流量控制
TCP 四元组可以唯⼀的确定⼀个连接,四元组包括如下:
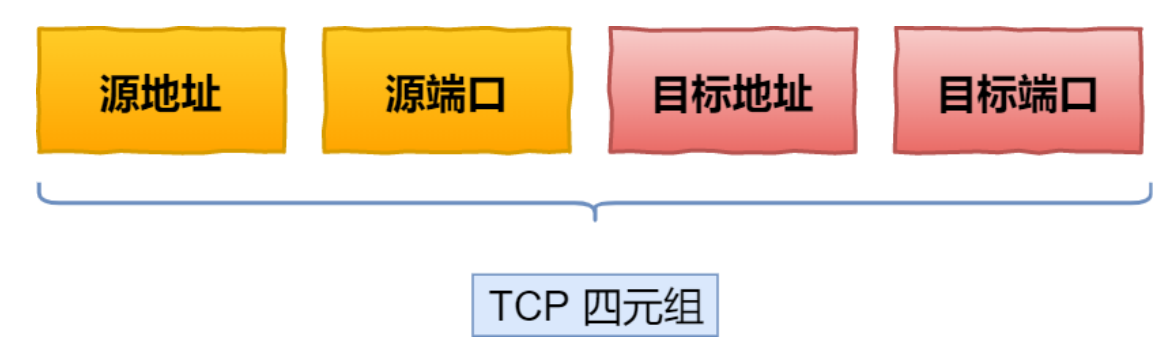
格式

序列号:在建⽴连接时由计算机⽣成的随机数作为其初始值,通过 SYN 包传给接收端主机,每发送⼀次数据,就「累加」⼀次该「数据字节数」的⼤⼩。⽤来解决⽹络包乱序问题。
确认应答号:指下⼀次「期望」收到的数据的序列号,发送端收到这个确认应答以后可以认为在这个序号以前的数据都已经被正常接收。⽤来解决不丢包的问题。
控制位:
ACK:该位为 1 时,「确认应答」的字段变为有效,TCP 规定除了最初建⽴连接时的 SYN 包之外该位必须设置为 1 。
RST:该位为 1 时,表示 TCP 连接中出现异常必须强制断开连接。
SYN:该位为 1 时,表示希望建⽴连接,并在其「序列号」的字段进⾏序列号初始值的设定。
FIN:该位为 1 时,表示今后不会再有数据发送,希望断开连接。当通信结束希望断开连接时,通信双⽅的
主机之间就可以相互交换 FIN 位为 1 的 TCP 段。
TCP 和 UDP 区别
- 连接
TCP 是⾯向连接的传输层协议,传输数据前先要建⽴连接。
UDP 是不需要连接,即刻传输数据。
- 服务对象
TCP 是⼀对⼀的两点服务,即⼀条连接只有两个端点。
UDP ⽀持⼀对⼀、⼀对多、多对多的交互通信
- 可靠性
TCP 是可靠交付数据的,数据可以⽆差错、不丢失、不重复、按需到达。
UDP 是尽最⼤努⼒交付,不保证可靠交付数据。
- 拥塞控制、流量控制
TCP 有拥塞控制和流量控制机制,保证数据传输的安全性。
UDP 则没有,即使⽹络⾮常拥堵了,也不会影响 UDP 的发送速率。
- ⾸部开销
TCP ⾸部⻓度较⻓,会有⼀定的开销,⾸部在没有使⽤「选项」字段时是 20 个字节,如果使⽤了「选项」字段则会变⻓的。
UDP ⾸部只有 8 个字节,并且是固定不变的,开销较⼩。
- 传输⽅式
TCP 是流式传输,没有边界,但保证顺序和可靠。
UDP 是⼀个包⼀个包的发送,是有边界的,但可能会丢包和乱序。
- 分⽚不同
TCP 的数据⼤⼩如果⼤于 MSS ⼤⼩,则会在传输层进⾏分⽚,⽬标主机收到后,
也同样在传输层组装 TCP数据包,如果中途丢失了⼀个分⽚,只需要传输丢失的这个分⽚。
UDP 的数据⼤⼩如果⼤于 MTU ⼤⼩,则会在 IP 层进⾏分⽚,⽬标主机收到后,在 IP 层组装完数据,
接着再传给传输层,但是如果中途丢了⼀个分⽚,在实现可靠传输的 UDP 时则就需要重传所有的数据包,这样传输效率⾮常差,所以通常 UDP 的报⽂应该⼩于 MTU。
TCP 和 UDP 应⽤场景
由于 TCP 是⾯向连接,能保证数据的可靠性交付,因此经常⽤于:
- FTP ⽂件传输
- HTTP / HTTPS
由于 UDP ⾯向⽆连接,它可以随时发送数据,再加上UDP本身的处理既简单⼜⾼效,因此经常⽤于:
- 包总量较少的通信,如 DNS 、 SNMP 等
- 视频、⾳频等多媒体通信
- ⼴播通信
TCP 连接建⽴
TCP 是⾯向连接的协议,所以使⽤ TCP 前必须先建⽴连接,⽽建⽴连接是通过三次握⼿来进⾏的。
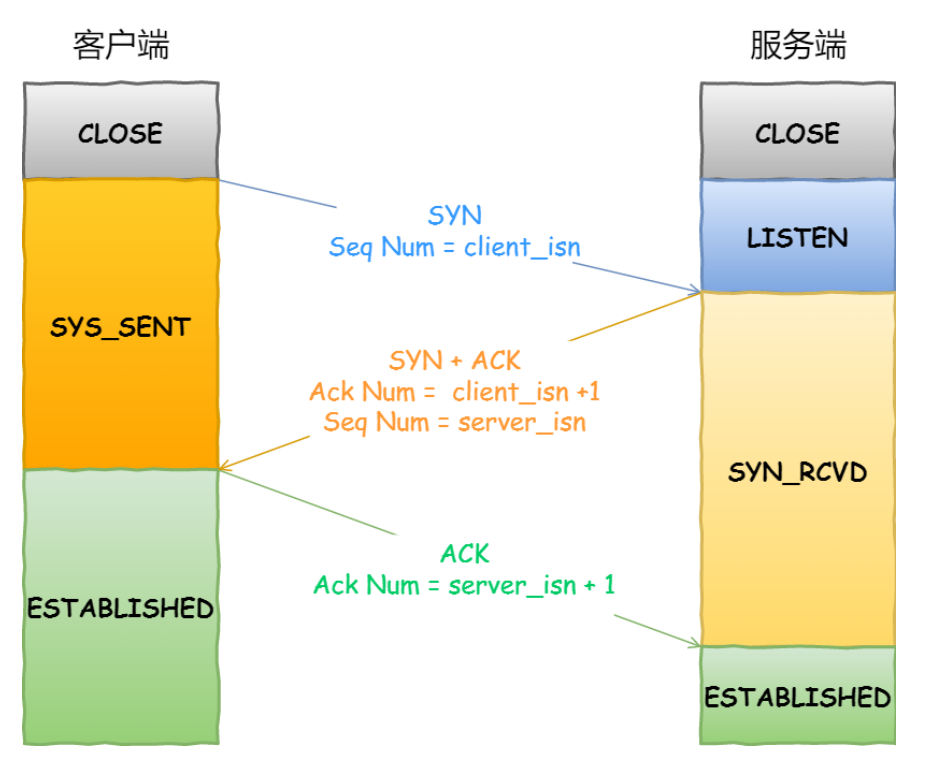
TCP 的连接状态查看,在 Linux 可以通过 netstat -napt 命令查看。
为什么是三次握⼿?不是两次、四次?
Socket、序列号和窗⼝⼤⼩称为连接。
所以,重要的是为什么三次握⼿才可以初始化Socket、序列号和窗⼝⼤⼩并建⽴ TCP 连接。
接下来以三个⽅⾯分析三次握⼿的原因:
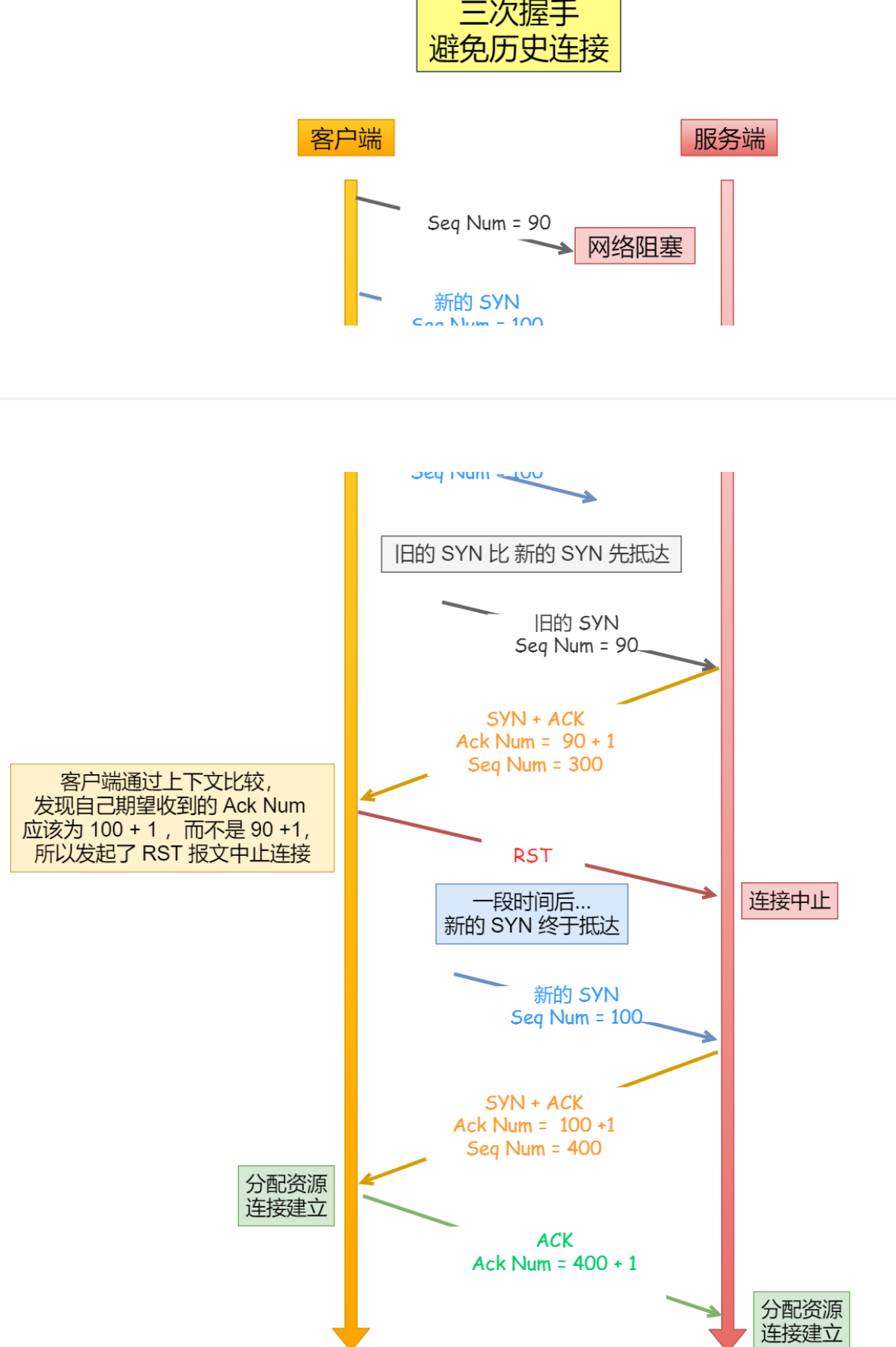
- 三次握⼿才可以阻⽌重复历史连接的初始化(主要原因)
- 三次握⼿才可以同步双⽅的初始序列号
- 三次握⼿才可以避免资源浪费
阻⽌重复历史连接的初始化
同步双⽅初始序列号
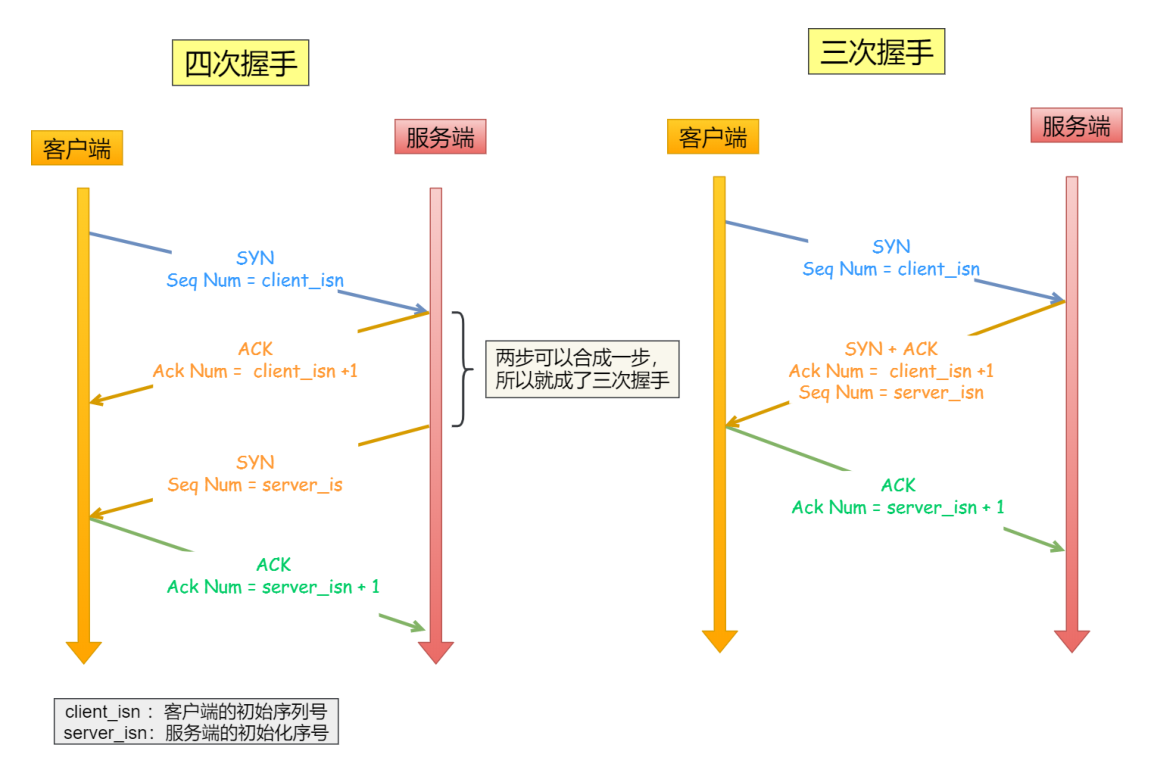
四次握⼿其实也能够可靠的同步双⽅的初始化序号,但由于第⼆步和第三步可以优化成⼀步,
所以就成了「三次握⼿」。
避免资源浪费
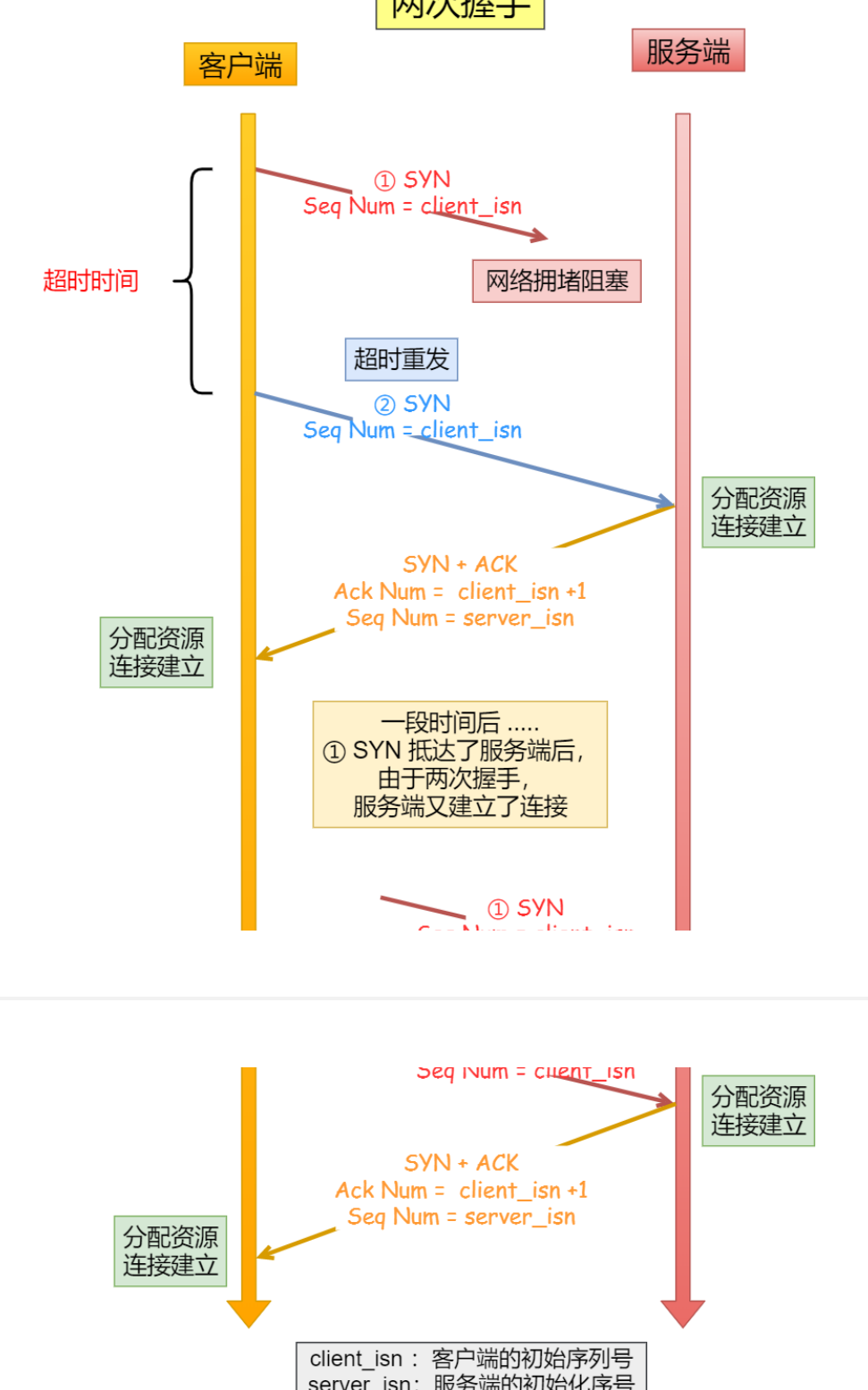
两次握⼿会造成消息滞留情况下,服务器重复接受⽆⽤的连接请求 SYN 报⽂,⽽造成重复分配资源。
一些问题
为什么客户端和服务端的初始序列号 ISN 是不相同的?
如果⼀个已经失效的连接被重⽤了,但是该旧连接的历史报⽂还残留在⽹络中,
如果序列号相同,那么就⽆法分辨出该报⽂是不是历史报⽂,
如果历史报⽂被新的连接接收了,则会产⽣数据错乱。
每次建⽴连接前重新初始化⼀个序列号主要是为了通信双⽅能够根据序号将不属于本连接的报⽂段丢弃。
另⼀⽅⾯是为了安全性,防⽌⿊客伪造的相同序列号的 TCP 报⽂被对⽅接收。
初始序列号 ISN 是如何随机产⽣的?
起始 ISN 是基于时钟的,每 4 毫秒 + 1,转⼀圈要 4.55 个⼩时。
RFC1948 中提出了⼀个较好的初始化序列号 ISN 随机⽣成算法。
ISN = M + F (localhost, localport, remotehost, remoteport)
既然 IP 层会分⽚,为什么 TCP 层还需要 MSS 呢?
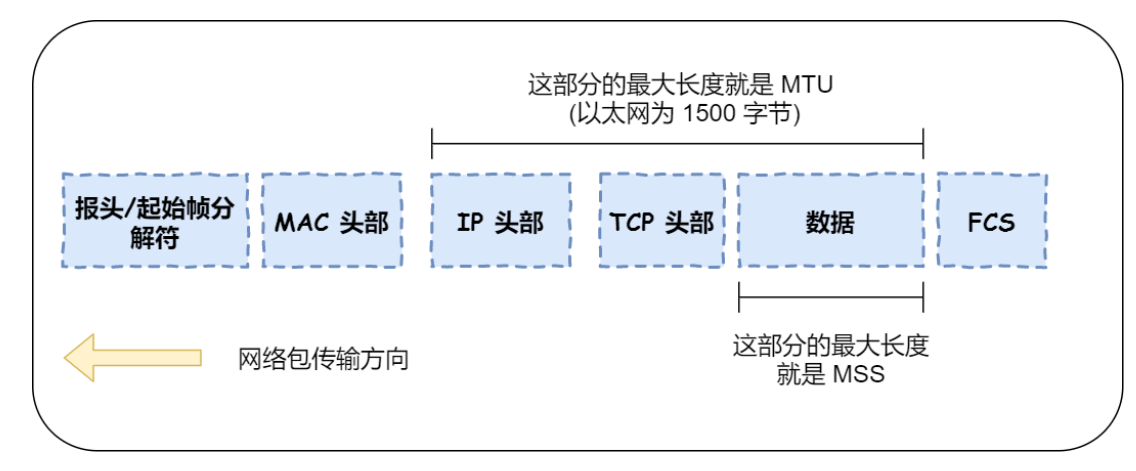
MTU :⼀个⽹络包的最⼤⻓度,以太⽹中⼀般为 1500 字节;
MSS :除去 IP 和 TCP 头部之后,⼀个⽹络包所能容纳的 TCP 数据的最⼤⻓度;
当 IP 层有⼀个超过 MTU ⼤⼩的数据(TCP 头部 + TCP 数据)要发送,那么 IP 层就要进⾏分⽚,
把数据分⽚成若⼲⽚,保证每⼀个分⽚都⼩于 MTU。把⼀份 IP 数据报进⾏分⽚以后,
由⽬标主机的 IP 层来进⾏重新组装后,再交给上⼀层 TCP 传输层。
这看起来井然有序,但这存在隐患的,那么当如果⼀个 IP 分⽚丢失,整个 IP 报⽂的所有分⽚都得重传。
因为 IP 层本身没有超时重传机制,它由传输层的 TCP 来负责超时和重传。
当接收⽅发现 TCP 报⽂(头部 + 数据)的某⼀⽚丢失后,则不会响应 ACK 给对⽅,
那么发送⽅的 TCP 在超时后,就会重发「整个 TCP 报⽂(头部 + 数据)」。
因此,可以得知由 IP 层进⾏分⽚传输,是⾮常没有效率的。
所以,为了达到最佳的传输效能 TCP 协议在建⽴连接的时候通常要协商双⽅的 MSS 值,
当 TCP 层发现数据超过MSS 时,则就先会进⾏分⽚,
当然由它形成的 IP 包的⻓度也就不会⼤于 MTU ,⾃然也就不⽤ IP 分⽚了。
经过 TCP 层分⽚后,如果⼀个 TCP 分⽚丢失后,进⾏重发时也是以 MSS 为单位,
⽽不⽤重传所有的分⽚,⼤⼤增加了重传的效率。
什么是 SYN 攻击?如何避免 SYN 攻击?
SYN 攻击
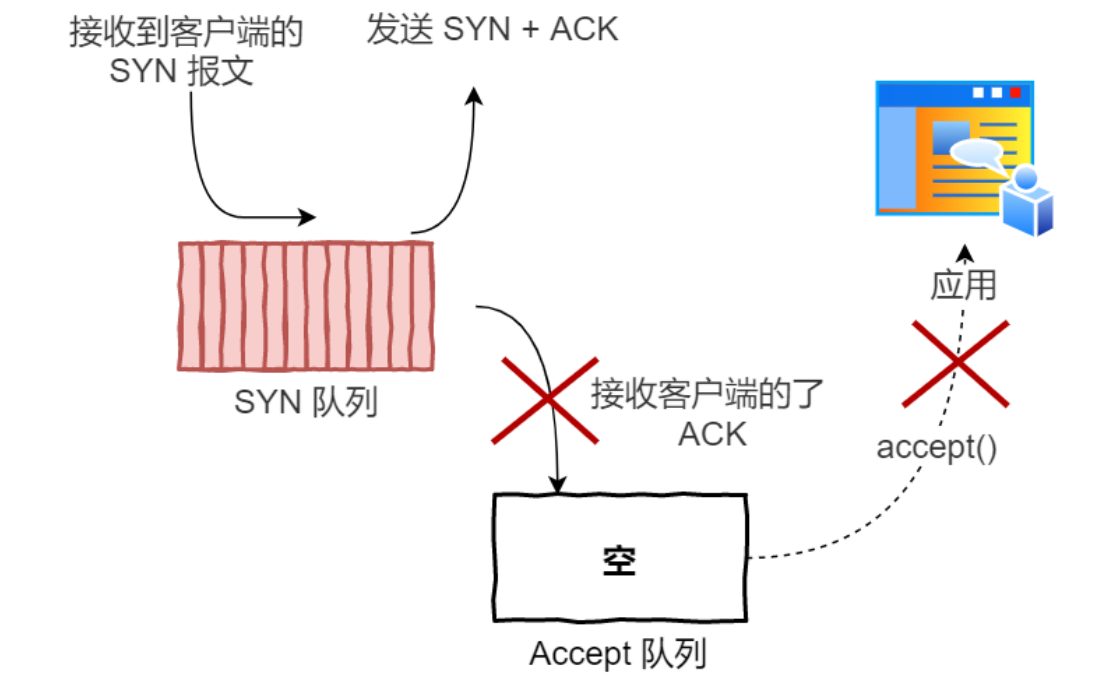
我们都知道 TCP 连接建⽴是需要三次握⼿,假设攻击者短时间伪造不同 IP 地址的 SYN 报⽂,
服务端每接收到⼀个 SYN 报⽂,就进⼊ SYN_RCVD 状态,但服务端发送出去的 ACK + SYN 报⽂,
⽆法得到未知 IP 主机的ACK 应答,
久⽽久之就会占满服务端的 SYN 接收队列(未连接队列),使得服务器不能为正常⽤户服务。

避免 SYN 攻击⽅式⼀
其中⼀种解决⽅式是通过修改 Linux 内核参数,控制队列⼤⼩和当队列满时应做什么处理。
当⽹卡接收数据包的速度⼤于内核处理的速度时,会有⼀个队列保存这些数据包。
控制该队列的最⼤值如下参数:
-
SYN_RCVD 状态连接的最⼤个数:
net.core.netdev_max_backlog
net.ipv4.tcp_max_syn_backlog
-
超出处理能时,对新的 SYN 直接回报 RST,丢弃连接:
避免 SYN 攻击⽅式⼆
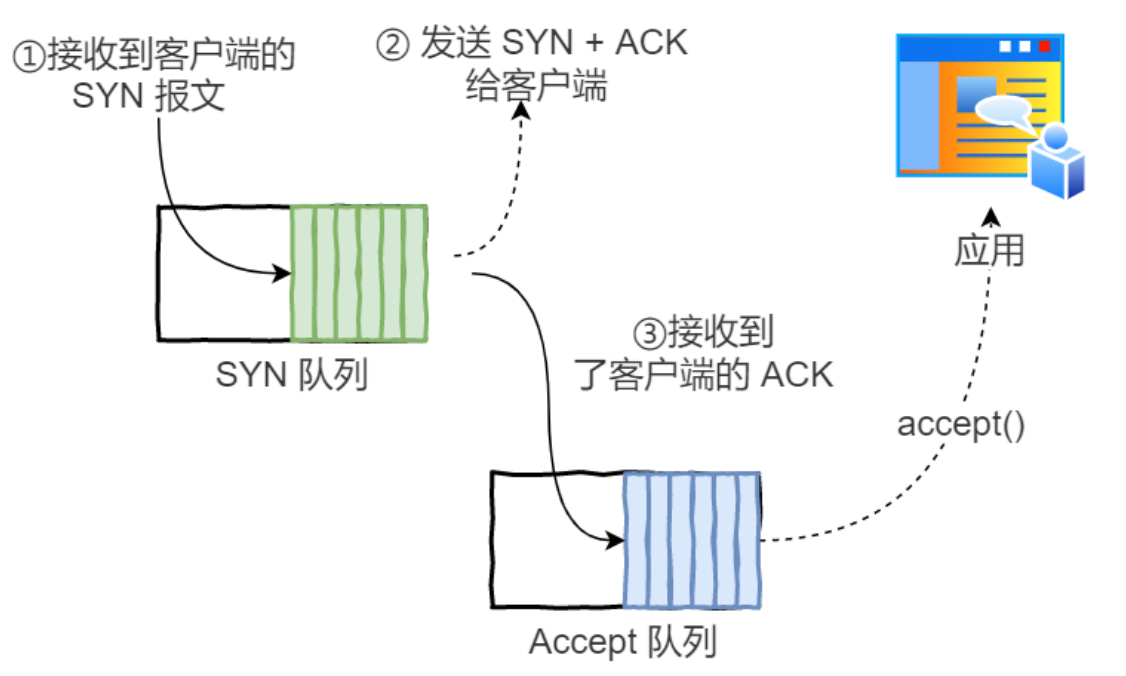
正常流程:
收到攻击之后:
TCP 连接断开
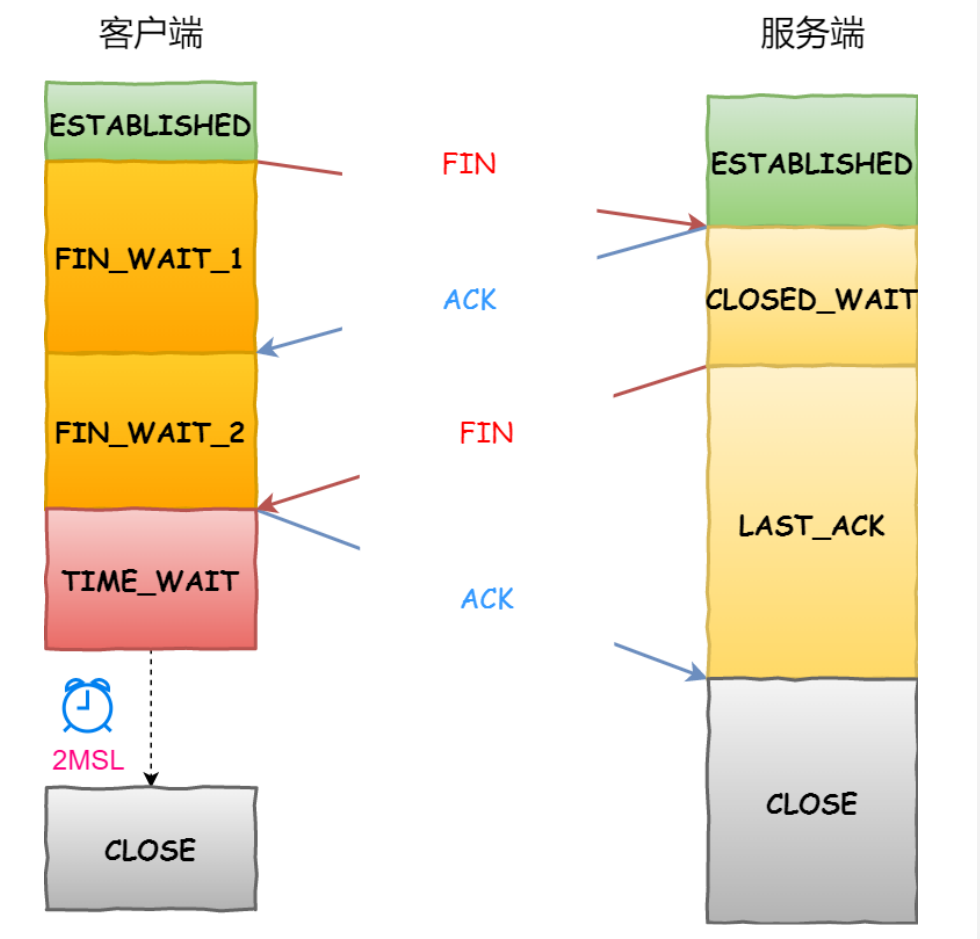
你可以看到,每个⽅向都需要⼀个 FIN 和⼀个 ACK,因此通常被称为四次挥⼿。
这⾥⼀点需要注意是:主动关闭连接的,才有 TIME_WAIT 状态。
为什么挥⼿需要四次?
再来回顾下四次挥⼿双⽅发 FIN 包的过程,就能理解为什么需要四次了。
- 关闭连接时,客户端向服务端发送 FIN 时,仅仅表示客户端不再发送数据了但是还能接收数据。
- 服务器收到客户端的 FIN 报⽂时,先回⼀个 ACK 应答报⽂,⽽服务端可能还有数据需要处理和发送,等服务端不再发送数据时,才发送 FIN 报⽂给客户端来表示同意现在关闭连接。
从上⾯过程可知,服务端通常需要等待完成数据的发送和处理,
所以服务端的 ACK 和 FIN ⼀般都会分开发送,从⽽⽐三次握⼿导致多了⼀次。
为什么 TIME_WAIT 等待的时间是 2MSL?
MSL 是 Maximum Segment Lifetime,报⽂最⼤⽣存时间,它是任何报⽂在⽹络上存在的最⻓时间,
超过这个时间报⽂将被丢弃。
因为 TCP 报⽂基于是 IP 协议的,⽽ IP 头中有⼀个 TTL 字段,是 IP 数据报可以经过的最⼤路由数,每经过⼀个处理他的路由器此值就减 1,当此值为 0 则数据报将被丢弃,同时发送 ICMP 报⽂通知源主机。
MSL 与 TTL 的区别: MSL 的单位是时间,⽽ TTL 是经过路由跳数。
所以 MSL 应该要⼤于等于 TTL 消耗为 0 的时间,以确保报⽂已被⾃然消亡。
TIME_WAIT 等待 2 倍的 MSL,
⽐较合理的解释是: ⽹络中可能存在来⾃发送⽅的数据包,当这些发送⽅的数据包被接收⽅处理后⼜会向对⽅发送响应,所以⼀来⼀回需要等待 2 倍的时间。
2MSL 的时间是从客户端接收到 FIN 后发送 ACK 开始计时的。
如果在 TIME-WAIT 时间内,因为客户端的 ACK没有传输到服务端,客户端⼜接收到了服务端重发的 FIN 报⽂,那么 2MSL 时间将重新计时。
在 Linux 系统⾥ 2MSL 默认是 60 秒,那么⼀个 MSL 也就是 30 秒。Linux 系统停留在 TIME_WAIT 的时
间为固定的 60 秒。
为什么需要 TIME_WAIT 状态?
主动发起关闭连接的⼀⽅,才会有 TIME-WAIT 状态。
需要 TIME-WAIT 状态,主要是两个原因:
- 防⽌具有相同「四元组」的「旧」数据包被收到;
- 保证「被动关闭连接」的⼀⽅能被正确的关闭,即保证最后的 ACK 能让被动关闭⽅接收,从⽽帮助其正常关闭;
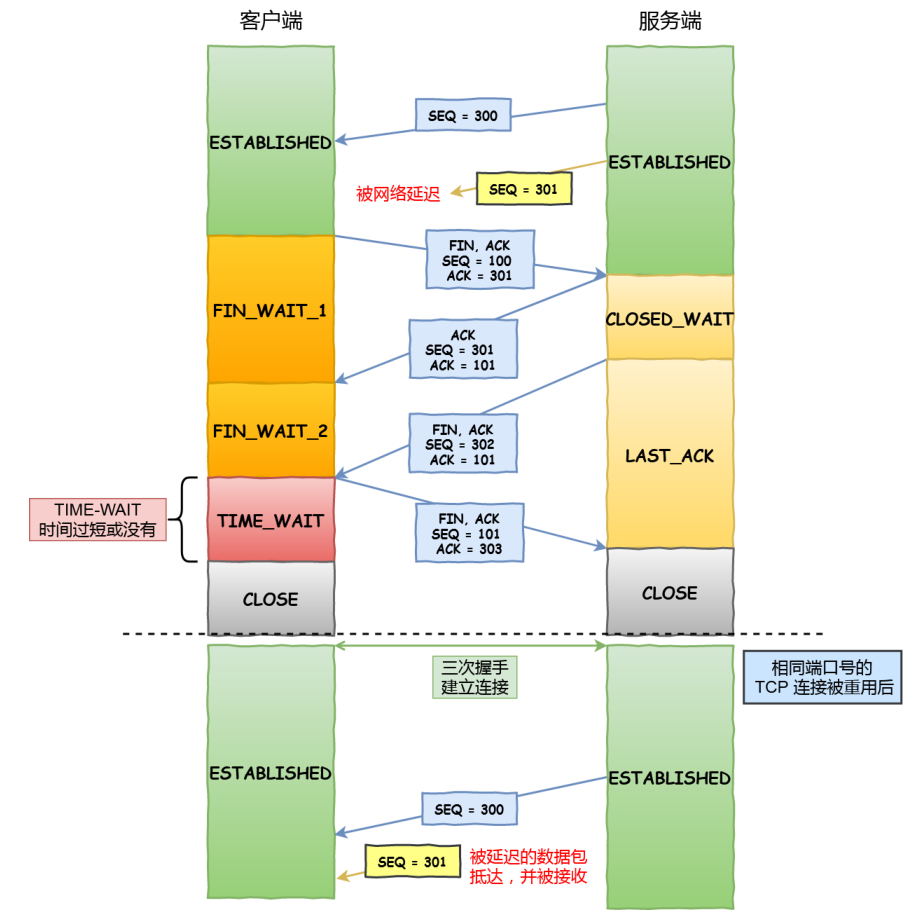
原因⼀:防⽌旧连接的数据包
TCP 就设计出了这么⼀个机制,经过 2MSL 这个时间,⾜以让两个⽅向上的数据包都被丢弃,
使得原来连接的数据包在⽹络中都⾃然消失,再出现的数据包⼀定都是新建⽴连接所产⽣的。
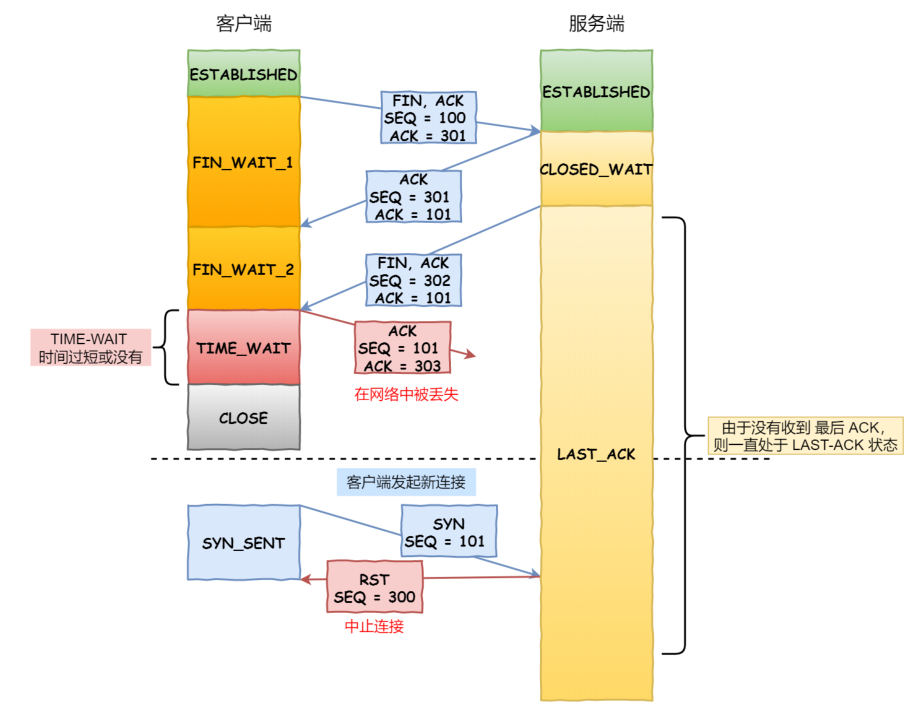
原因⼆:保证连接正确关闭
TIME-WAIT 作⽤是等待⾜够的时间以确保最后的 ACK 能让被动关闭⽅接收,从⽽帮助其正常关闭。
TIME_WAIT 过多有什么危害
过多的 TIME-WAIT 状态主要的危害有两种:
- 第⼀是内存资源占⽤;
- 第⼆是对端⼝资源的占⽤,⼀个 TCP 连接⾄少消耗⼀个本地端⼝;
第⼆个危害是会造成严重的后果的,要知道,端⼝资源也是有限的,⼀般可以开启的端⼝为 32768~61000 ,也可以通过如下参数设置指定
如果发起连接⼀⽅的 TIME_WAIT 状态过多,占满了所有端⼝资源,则会导致⽆法创建新连接。
如何优化 TIME_WAIT?
更新中…………
Socket 编程
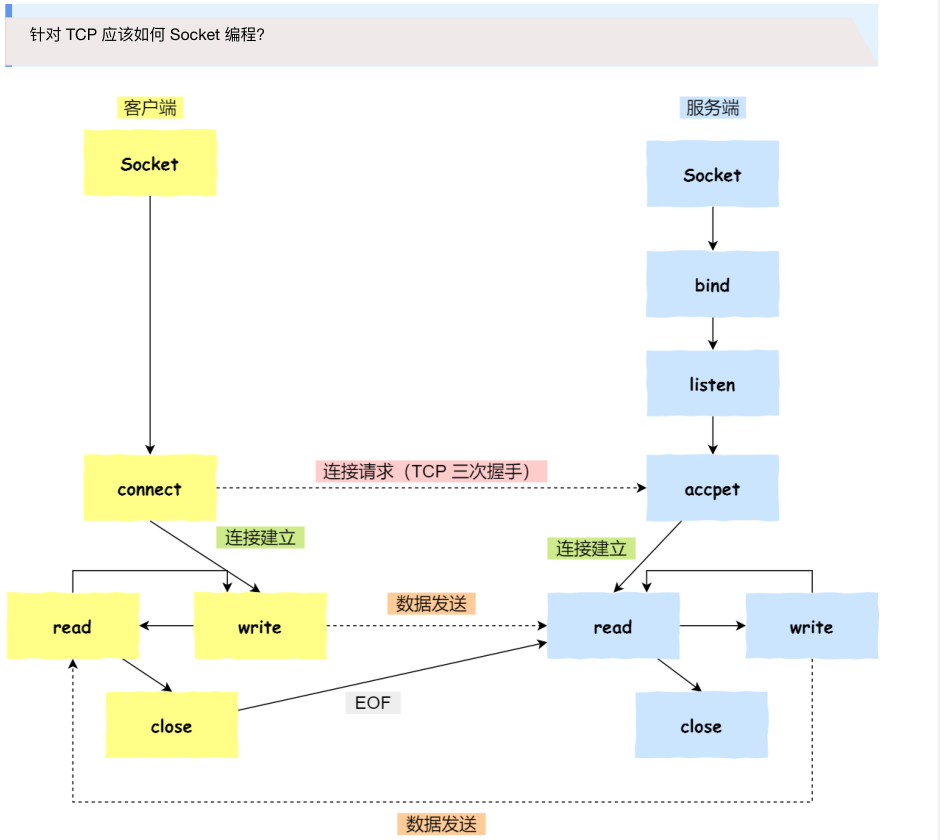
所以,监听的 socket 和真正⽤来传送数据的 socket,是「两个」 socket,⼀个叫作监听 socket,⼀个叫作已完成连接 socket。
成功连接建⽴之后,双⽅开始通过 read 和 write 函数来读写数据,就像往⼀个⽂件流⾥⾯写东⻄⼀样。
listen 时候参数 backlog 的意义?
Linux内核中会维护两个队列:
- 未完成连接队列(SYN 队列):接收到⼀个 SYN 建⽴连接请求,处于 SYN_RCVD 状态;
- 已完成连接队列(Accpet 队列):已完成 TCP 三次握⼿过程,处于 ESTABLISHED 状态;
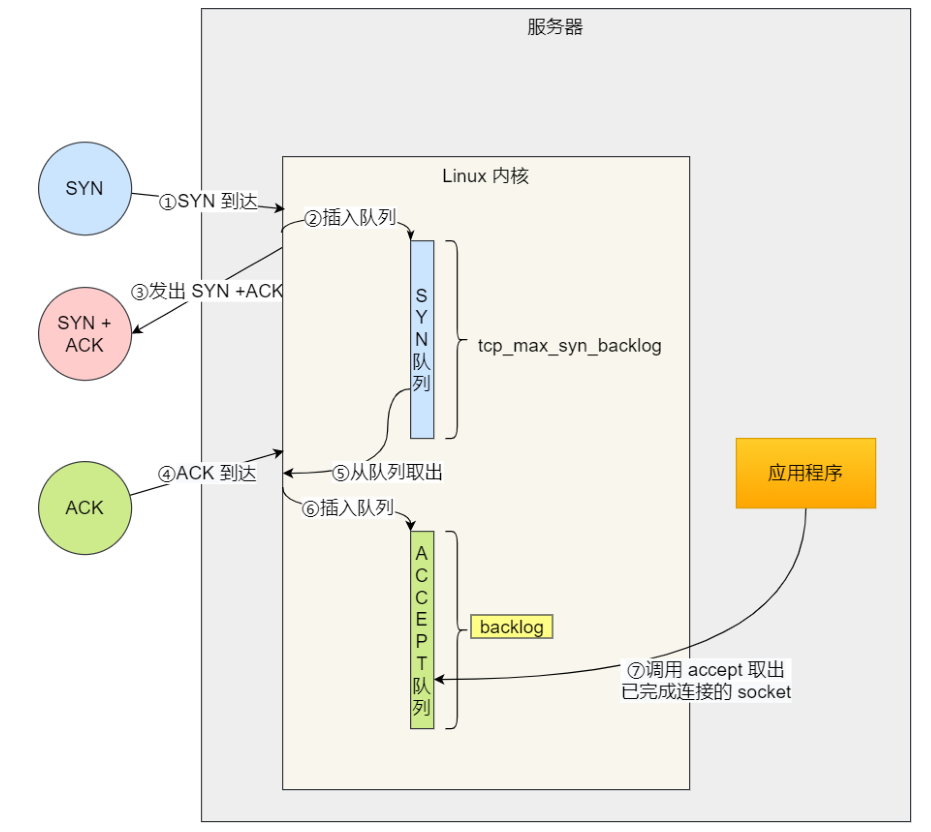
accept 发⽣在三次握⼿的哪⼀步?
客户端连接服务端时,发送了什么?
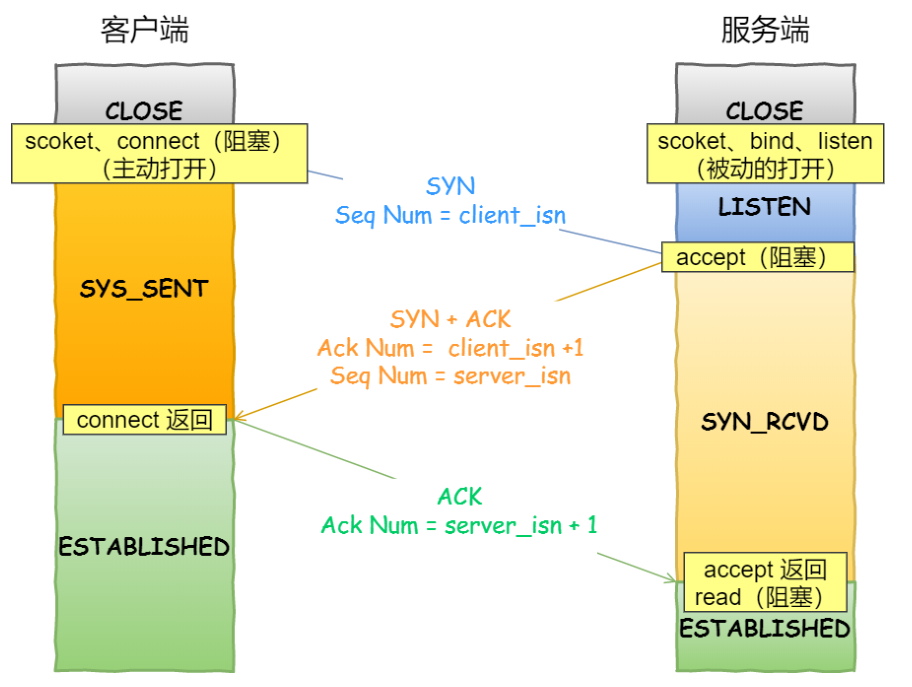
客户端 connect 成功返回是在第⼆次握⼿,服务端 accept 成功返回是在三次握⼿成功之后。
正所谓知道的越多,不知道的也越多。
参考:图解网络
我这里只是一个自己的学习笔记,大家有兴趣一定去看原文!!! 谢谢大家的阅读!!
大家有兴趣一定去看原文,这只是我自己的一个笔记总结!!
大家有兴趣一定去看原文,这只是我自己的一个笔记总结!!
大家有兴趣一定去看原文,这只是我自己的一个笔记总结!!

