
模块
一,模块
在Python中,一个py文件就是一个模块,文件名为xxx.py模块名则是xxx,导入模块可以引用模块中已经写好的功能。
1,分类:1,内置模块;2,第三方模块;3,自定义模块
2,四种形式:
-
- 使用python编写的.py文件
- 已被编译为共享库或DLL或C或C++扩展
- 把一系类模块组织到一起的文件夹,文件夹下有一个__init__.py文件,该文件夹称之为包
- 使用c编写并链接到python解释器的内置模块
3,首次导入会发生的三件事
-
- 1,执行foo.py
- 2,产生foo.py的名称空间,将foo.py运行过程产生的名字都丢到foo的名称空间
- 3,在当前文件中产生一个foo这个名字,并该名字指向2产生的名称空间
- 注意,之后的导入都是直接引用首次产生的结果
4,引用:
举例:print(foo.x)
强调1:模块名.名字,是指名道姓的问某一个模块要名字对应的值,不会影响当前文件的变量名
强调2:无论是查看还是修改与调用位置无关
5,导入模块
-
- 多行导入,建议使用这种
1 import time 2 import random
- 不建议这种
1 import time,random
- 不建议这种
- 导入模块规范
- 1,python内置模块
- 2,第三方模块
- 3,自定义模块
- 起别名
1 import time as t
- 自定义米快的命名应该采用纯小写+下划线的风格
- 在函数内导入模块
- 多行导入,建议使用这种
6,.py文件的用处,每个py文件内部都有__name__这个变量
-
- 被当成程序运行
- 当程序运行结束时,名称空间关闭
- __name__的值为__main__
- 被当成模块导入
- 当模块内部变量名全部引用完毕时,该模块的命名空间关闭
- 当被模块运行时,__name__的值为模块名称
- 总结:可以
1 if __name__ == '__main__': 2 print("文件被执行") 3 else: 4 print('文件被导入')
- 被当成程序运行
7,导入模块进阶
- import math,这种导入的变量名会放置在开辟的模块名称空间里
![]()
-
from math import sqrt,这种导入的变量名会放置在本文件中的名称空间里
也发生了三件事
1,产生一个模块的名称空间
2,运行模块过程中产生的变量名都丢到模块的名称空间去
3,在当前空间中也创建与模块名称空间相同的名字,并且该名字与模块名称空间中对应的地址是对应的![]()
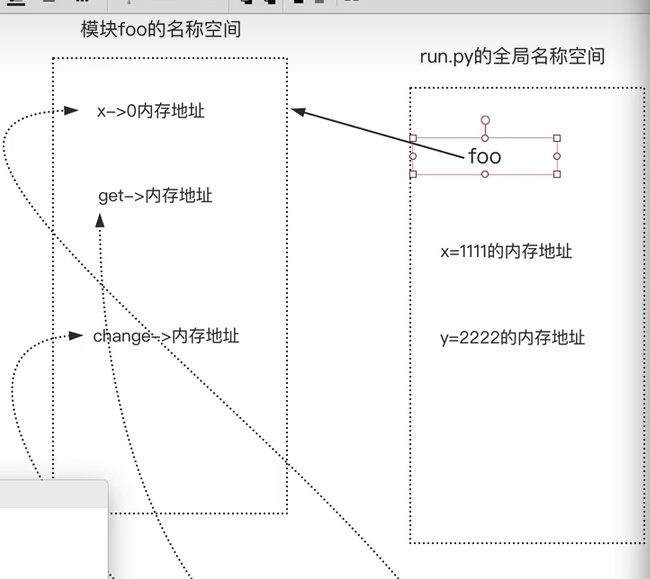

-
from ... import ...
- 优点:代码更加精简
- 缺点:容易与当前名称空间混淆,而且容易代码更新不及时会导致引用混乱
8,其他知识
-
-
from time import *,导入该模块的全部变量名
-
__all__=[ 'x']可以控制*导入的变量名
-
9,模块中的循环互相导入会导致引用时出错
比如:
1 m1.py中 2 3 print('正在导入m1') 4 from m2 import y 5 6 x='m1' 7 8 m2.py中 9 10 print('正在导入m2') 11 from m1 import x 12 13 y='m2'
解决方案:
1 # 方案一:导入语句放到最后,保证在导入时,所有名字都已经加载过 2 # 文件:m1.py 3 print('正在导入m1') 4 5 x='m1' 6 7 from m2 import y 8 9 # 文件:m2.py 10 print('正在导入m2') 11 y='m2' 12 13 from m1 import x 14 15 # 文件:run.py内容如下,执行该文件,可以正常使用 16 import m1 17 print(m1.x) 18 print(m1.y) 19 20 # 方案二:导入语句放到函数中,只有在调用函数时才会执行其内部代码 21 # 文件:m1.py 22 print('正在导入m1') 23 24 def f1(): 25 from m2 import y 26 print(x,y) 27 28 x = 'm1' 29 30 # 文件:m2.py 31 print('正在导入m2') 32 33 def f2(): 34 from m1 import x 35 print(x,y) 36 37 y = 'm2' 38 39 # 文件:run.py内容如下,执行该文件,可以正常使用 40 import m1 41 42 m1.f1()
注意:循环导入问题大多数情况是因为程序设计失误导致,上述解决方案也只是在烂设计之上的无奈之举,在我们的程序中应该尽量避免出现循环/嵌套导入,如果多个模块确实都需要共享某些数据,可以将共享的数据集中存放到某一个地方,然后进行导入
10,模块查找顺序
-
- 首先在内存中查找
- 然后按照sys.path中存放的文件顺序依次查找要导入的模块
- 了解
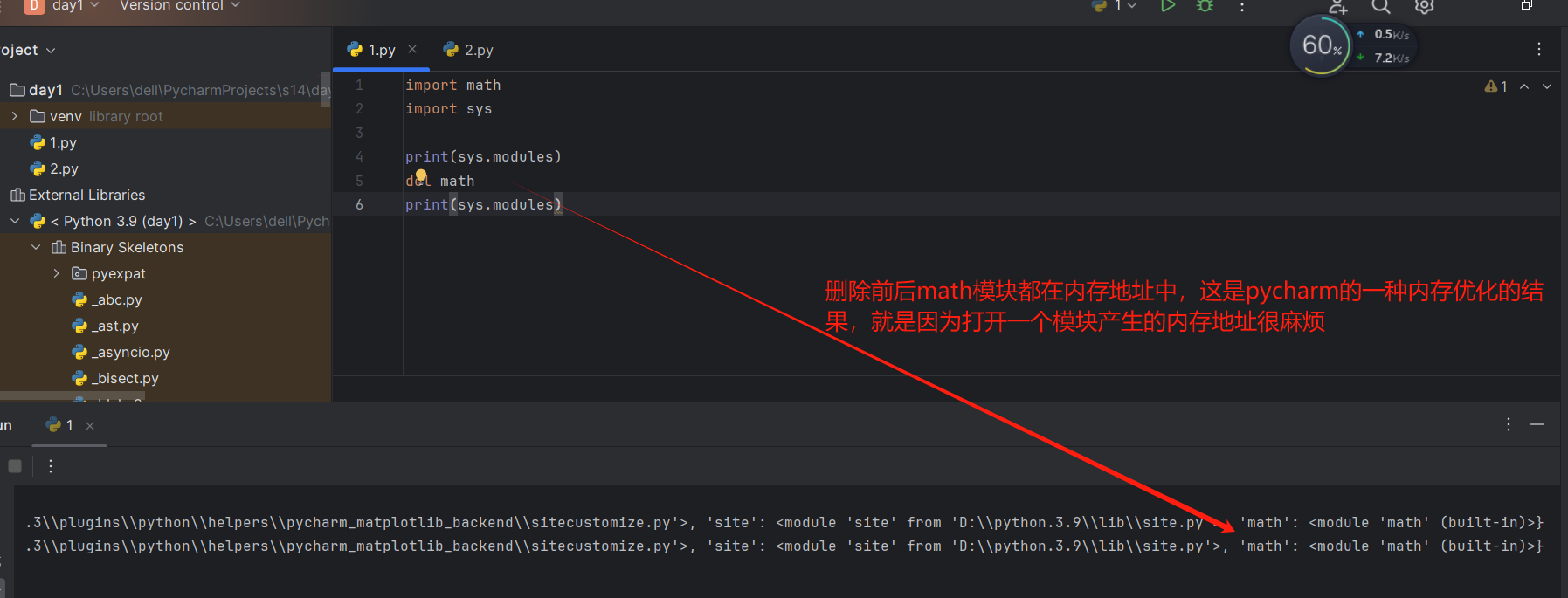
- 导入模块后就算是用del,导入模块产生的内存地址还是没有消失
![]()
- sys.path.append(虽然是临时加的):就是将文件外的模块导入到sys.path里面
- 导入模块后就算是用del,导入模块产生的内存地址还是没有消失
11,模块的书写规范
1 !/usr/bin/env python #通常只在类unix环境有效,作用是可以使用脚本名来执行,而无需直接调用解释器。 2 3 "The module is used to..." #模块的文档描述 4 5 import sys #导入模块 6 7 x=1 #定义全局变量,如果非必须,则最好使用局部变量,这样可以提高代码的易维护性,并且可以节省内存提高性能 8 9 class Foo: #定义类,并写好类的注释 10 'Class Foo is used to...' 11 pass 12 13 def test(): #定义函数,并写好函数的注释 14 'Function test is used to…' 15 pass 16 17 if __name__ == '__main__': #主程序 18 test() #在被当做脚本执行时,执行此处的代码
模块的提示信息
1 def fun1(name:str,age:int,height:(1,2))->int: 2 #提示信息第一种 3 print("Hello") 4 return 11 5 def fun2(name:str='str',age:int=11,height:tuple=(1,2))->int: 6 # 提示信息第二种 7 print("Hello") 8 return 11 9 def fun3(name:'传个名字',age:'传年龄',height:tuple=(1,2))->int: 10 # 提示信息第三种 11 print("Hello") 12 return 11 13 print(fun2.__annotations__) #查看提示信息
12,包
包就是模块的一种,只不过是一个文件夹,是一个模块的集合体。最大的特征就是包里有一个__init__.py的文件。
打开流程:
-
- 产生一个名称空间
- 运行包__init__.py文件,将运行过程中产生名字都丢到产生的名称空间里
- 在当前执行执行文件的名称空间产生了指向上面名称空间的一个变量名
![]()
-
注意:
-
#1. 在python3中,即使包下没有__init__.py文件,import 包仍然不会报错,而在python2中,包下一定要有该文件,否则import 包报错 #2. 创建包的目的不是为了运行,而是被导入使用,记住,包只是模块的一种形式而已,包的本质就是一种模
-
- 强调:
1.关于包相关的导入语句也分为import和from ... import ...两种,但是无论哪种,无论在什么位置,在导入时都必须遵循一个原则:凡是在导入时带点的,点的左边都必须是一个包,否则非法。可以带有一连串的点,如import 顶级包.子包.子模块,但都必须遵循这个原则。但对于导入后,在使用时就没有这种限制了,点的左边可以是包,模块,函数,类(它们都可以用点的方式调用自己的属性)。-
2、包A和包B下有同名模块也不会冲突,如A.a与B.a来自俩个命名空间 -
3、import导入文件时,产生名称空间中的名字来源于文件,import 包,产生的名称空间的名字同样来源于文件,即包下的__init__.py,导入包本质就是在导入该文件

相对导入:绝对导入:以顶级包为起始 1 #pool下的__init__.py 2 from pool import versions
相对导入:相对导入:.代表当前文件所在的目录,..代表当前目录的上一级目录,依此类推(注意只能在包之内使用) 1 #pool下的__init__.py 2 from . import versions
from 包 import *
在使用包时同样支持from pool.futures import * ,毫无疑问*代表的是futures下__init__.py中所有的名字,通用是用变量__all__来控制*代表的意思 1 #futures下的__init__.py 2 __all__=['process','thread']
二,软件开发的目录规范
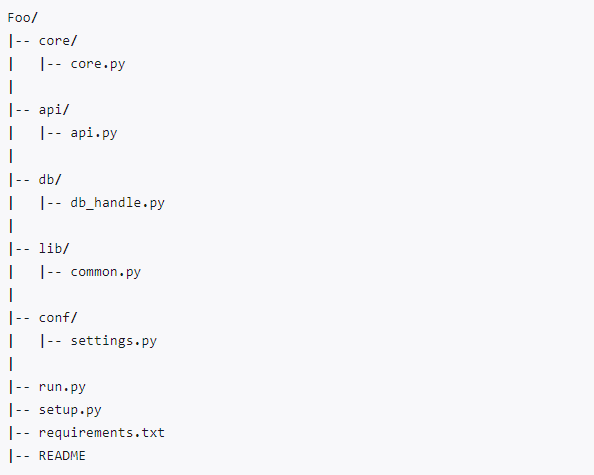
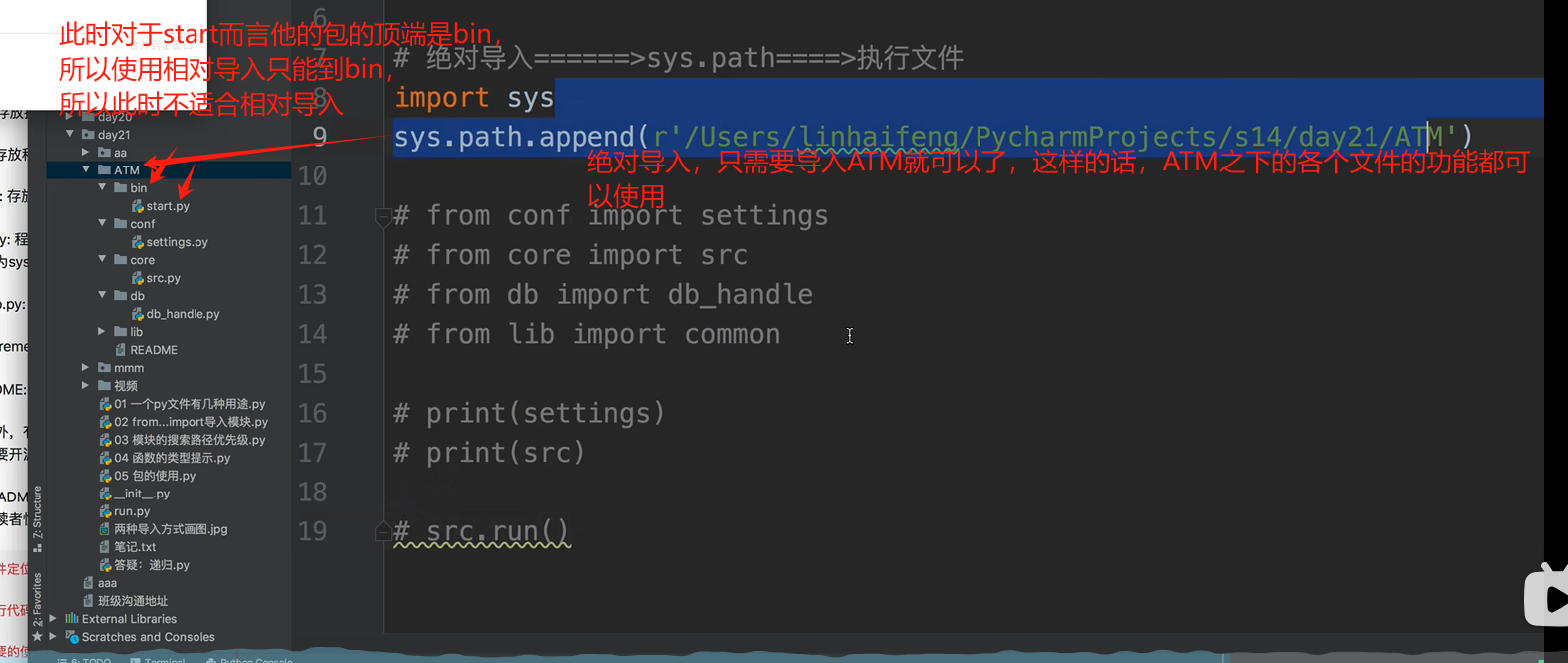
优化方案:获取当前文件位置与当前文件上级目录
1 import os 2 print(os.getcwd()) # 获取当前工作目录路径 3 print(os.path.abspath('.')) # 获取当前工作目录路径 4 print(os.path.dirname(os.getcwd())) #获取上级目录
posted on 2024-02-07 04:52 我才是最帅的那个男人 阅读(16) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号