
day1 python基本类型
一,变量
1,定义:变量就是可以变化的量,量指的是事物的状态,比如人的年龄、性别,游戏角色的等级、金钱等等
2,用途:为了让计算机能够像人一样去记忆事物的某种状态,并且状态是可以发生变化的。如,游戏角色中的等级
3,三大组成部分:
-
- 变量名,是指向等号右侧值的内存地址,用来访问等号右侧的值
- 命名规则
1. 变量名只能是 字母、数字或下划线的任意组合 2. 变量名的第一个字符不能是数字 3. 关键字不能声明为变量名 - 命名风格
# 风格一:驼峰体 AgeOfTony = 56 NumberOfStudents = 80 # 风格二:纯小写下划线(在python中,变量名的命名推荐使用该风格) age_of_tony = 56 number_of_students = 80
- 命名规则
- 赋值符号,将变量值的内存地址绑定给变量名
- 变量值,代表记录失误的状态
- 特征
- id:反映变量值的内存地址(注意不是真的内存地址),内存地址不同,id则不同
- type,不同类型的值用来记录不同的状态
- 特征
- 变量名,是指向等号右侧值的内存地址,用来访问等号右侧的值
二,常量,不变的值
但是在python中没有严格意义上的常量,就是说,想改还是可以改的,但是在现实中有些时候确实需要这个概念,比如,游戏中主角的名字。所以,我们约定变量名全部大写表示为常量,此时其他人看到一般情况下就不会更改了。
三,数字类型
1,整数(int)
作用,记录年龄、身份证号、个数等
有关函数:
-
-
- x=int(‘10‘’),输出结果为数字10
- name=input(),输出结果为变量name
- print(10),虽然有打印结果但是没有输出结果。
-
类型转换:
-
-
- 字符串转化为数字类型:x=int(‘10’)
- 十进制与其他进制相互转化
- 了解知识
- 十六进制,其中A-F代表10-15
- 将数字11转化为其他进制
-
1 print(bin(11)) 输出结果为: 0b1011 二进制转化函数 2 print(oct(11)) 输出结果为: 0o13 八进制转化函数 3 print(hex(11))输出结果为: 0xb 十六进制转化函数
- 将其他进制转化为十进制
-
1 print(int('0b1011', 2)) 转化结果为11 2 print(int('0o13', 8)) 转化结果为11 3 print(int('0xb', 16)) 转化结果为11
- 了解知识
-
2,浮点型(float)
作用,记录薪资、身高、体重
类型转化,将字符串转化为浮点型
了解,复数:https://www.bilibili.com/video/av26786159
四,字符串
在python中,加上了双引号、单引号、三引号都代表着这是字符串类型。
1,用处,描述性的内容,如姓名,性别,国籍,种族
注意,字符串可以直接拼接,但只对字符串可以拼接,而且效率极低,不建议使用
2,取值(对msg=“hello python”进行修改):
-
- 按照索引取值
- 正向取:print(msg【1】)
- 反向取:print(msg【-1】)
- 注意,对于字符串来说,只能取值,不能更改
- 切片(顾头不顾尾)
- 取前八个:msg【0:9】:hello pyt
- 步长:msg【0:9:2】:hlopt
- 反向切片:msg【::-1】 :
nohtyp olleh(-1代表从右向左取值)
- 注意:取出来的新的字符串都没有改变原来的字符串,因为字符串是不可改变类型
- 按照索引取值
3,去除空格,函数strip(默认去除收尾空白字符,空格、\t、\n)
-
- 默认去除空格
1 >>> str1 = ' life is short! ' 2 >>> str1.strip() 3 life is short!
- 可以指定去除符号
>>> str2 = '**tony**' >>> str2.strip('*') tony
- 可以指定多个
1 msg='***+++/-*Hello World!+++//**' 2 print(msg.strip('+*/-')) 3 ****** 4 输出结果为 5 Hello World!
- 去除左边lstript
- 去除右边rstript
- 默认去除空格
4,切分,函数split(默认用空格切割)
-
- 可以指定分隔符
1 1 >>> str4 = '127.0.0.1' 2 2 >>> str4.split('.') 3 3 ['127', '0', '0', '1'] # 注意:split切割得到的结果是列表数据类型
- 指定分隔次数
1 msg=('hello:world:yes') 2 print(msg.split(":",1)) 输出结果为:['hello', 'world:yes']
- 从右边开始分隔,函数rsplit:print(msg.rsplit())
- 可以指定分隔符
5,lower、upper
-
- 小写:print(msg.lower())
- 大写:print(msg.upper())
6,format
7,startswith(判断以什么开始),endswith(判断以什么结束)


1 >>> str3 = 'tony jam' 2 3 # startswith()判断字符串是否以括号内指定的字符开头,结果为布尔值True或False 4 >>> str3.startswith('t') 5 True 6 >>> str3.startswith('j') 7 False 8 # endswith()判断字符串是否以括号内指定的字符结尾,结果为布尔值True或False 9 >>> str3.endswith('jam') 10 True 11 >>> str3.endswith('tony') 12 False
8,join,将列表拼接成字符串
1 # 从可迭代对象中取出多个字符串,然后按照指定的分隔符进行拼接,拼接的结果为字符串 2 >>> '%'.join('hello') # 从字符串'hello'中取出多个字符串,然后按照%作为分隔符号进行拼接 3 'h%e%l%l%o' 4 >>> '|'.join(['tony','18','read']) # 从列表中取出多个字符串,然后按照*作为分隔符号进行拼接 5 'tony|18|read'
9,replace,替换
1 # 用新的字符替换字符串中旧的字符 2 >>> str7 = 'my name is tony, my age is 18!' # 将tony的年龄由18岁改成73岁 3 >>> str7 = str7.replace('18', '73') # 语法:replace('旧内容', '新内容') 4 >>> str7 5 my name is tony, my age is 73! 6 7 # 可以指定修改的个数 8 >>> str7 = 'my name is tony, my age is 18!' 9 >>> str7 = str7.replace('my', 'MY',1) # 只把一个my改为MY 10 >>> str7 11 'MY name is tony, my age is 18!'
10,isdigit,判断是否为纯数字
1 # 判断字符串是否是纯数字组成,返回结果为True或False 2 >>> str8 = '5201314' 3 >>> str8.isdigit() 4 True 5 6 >>> str8 = '123g123' 7 >>> str8.isdigit() 8 False
11,了解
11.1,find,rfind,index,rindex,count
-
-
- find与index都有查找的功能,但是,find查找不到是会返回-1,index会报错
- count,计数
-
11.2,center,ljust,rjust,zfill
1 >>> name='tony' 2 >>> name.center(30,'-') # 总宽度为30,字符串居中显示,不够用-填充 3 -------------tony------------- 4 >>> name.ljust(30,'*') # 总宽度为30,字符串左对齐显示,不够用*填充 5 tony************************** 6 >>> name.rjust(30,'*') # 总宽度为30,字符串右对齐显示,不够用*填充 7 **************************tony 8 >>> name.zfill(50) # 总宽度为50,字符串右对齐显示,不够用0填充 9 0000000000000000000000000000000000000000000000tony
11.3,expandtabs,设置制表符代表空格个数
1 >>> name = 'tony\thello' # \t表示制表符(tab键) 2 >>> name 3 tony hello 4 >>> name.expandtabs(1) # 修改\t制表符代表的空格数 5 tony hello
11.4,captalize(首字母大写),swapcase(大小写翻转),title(全部首字母大写)
1 # 4.1 captalize:首字母大写 2 >>> message = 'hello everyone nice to meet you!' 3 >>> message.capitalize() 4 Hello everyone nice to meet you! 5 # 4.2 swapcase:大小写翻转 6 >>> message1 = 'Hi girl, I want make friends with you!' 7 >>> message1.swapcase() 8 hI GIRL, i WANT MAKE FRIENDS WITH YOU! 9 #4.3 title:每个单词的首字母大写 10 >>> msg = 'dear my friend i miss you very much' 11 >>> msg.title() 12 Dear My Friend I Miss You Very Much
11.5,is数字系列
1 #在python3中 2 num1 = b'4' #bytes 3 num2 = u'4' #unicode,python3中无需加u就是unicode 4 num3 = '四' #中文数字 5 num4 = 'Ⅳ' #罗马数字 6 7 #isdigt:bytes,unicode 8 >>> num1.isdigit() 9 True 10 >>> num2.isdigit() 11 True 12 >>> num3.isdigit() 13 False 14 >>> num4.isdigit() 15 False 16 17 #isdecimal:uncicode(bytes类型无isdecimal方法) 18 >>> num2.isdecimal() 19 True 20 >>> num3.isdecimal() 21 False 22 >>> num4.isdecimal() 23 False 24 25 #isnumberic:unicode,中文数字,罗马数字(bytes类型无isnumberic方法) 26 >>> num2.isnumeric() 27 True 28 >>> num3.isnumeric() 29 True 30 >>> num4.isnumeric() 31 True 32 33 # 三者不能判断浮点数 34 >>> num5 = '4.3' 35 >>> num5.isdigit() 36 False 37 >>> num5.isdecimal() 38 False 39 >>> num5.isnumeric() 40 False 41 42 ''' 43 总结: 44 最常用的是isdigit,可以判断bytes和unicode类型,这也是最常见的数字应用场景 45 如果要判断中文数字或罗马数字,则需要用到isnumeric。
11.6,is其他
1 >>> name = 'tony123' 2 >>> name.isalnum() #字符串中既可以包含数字也可以包含字母 3 True 4 >>> name.isalpha() #字符串中只包含字母 5 False 6 >>> name.isidentifier() 7 True 8 >>> name.islower() # 字符串是否是纯小写 9 True 10 >>> name.isupper() # 字符串是否是纯大写 11 False 12 >>> name.isspace() # 字符串是否全是空格 13 False 14 >>> name.istitle() # 字符串中的单词首字母是否都是大写 15 False
五,列表:索引对应值,索引从0开始,0代表第一个值;也可以倒着取,从-1开始,有序
1,作用:按位置记录多个值,并且可以按照索引取指定位置的值
2,定义:在【】内用逗号分隔开多个任意类型的值,一个值称为一个元素
3,取值: a=[1,2,3,4,5,6,7,8,9] print(a[2])
复杂应用,嵌套:
1 #取出第一个学生的第一个爱好 2 students_info=[ 3 ['egon',18,['play',]], 4 ['alex',18,['play','sleep']] 5 ] 6 print(students_info[0][2][0])
4,类型转换:凡是能够被for循环遍历的类型都可以当成参数传给list()转成列表
比如,字符串、列表、字典
5,内置方法,以l=【111,‘egon’,‘hello’】为例
-
- 索引
- 正向取
- 反向取
- 可以取也可以改
- 无论是取值还是赋值操作,索引不存在就会报错
- 切片,顾头不顾尾,切片相等于浅copy
- 索引
6,追加,l.append("3333"),会在末尾进行追加
7,插入,l.insert(1,444),第一个数字是插入的位置,第二个数字是插入的内容
8,可迭代对象简便追加方法,l.extend("ads"),只要是可迭代对象追加到列表上,就可以使用这个简便的函数
9,删除
-
- 方法一,通用的删除方法 del l[0] ,该方法只是单纯的删除,没有返回值
- 方法二,l.pop,
1 l=[111, 444, 'egon', 'hello', '3333', 'a', 'd', 's'] 2 ret=l.pop(1) #有返回值,会返回删除的结果,注意,默认删除列表中最后一个值 3 print(ret) 4 ******** 5 444
- 方法三,l.remove,删除指定的内容
1 l=[111, 444, 'egon', 'hello', '3333', 'a', 'd', 's'] 2 ret=l.remove('hello') #返回值为None,并且只能通过指定的内容进行删除,不能通过索引 3 进行删除 4 print(ret) 5 print(l) 6 ******* 7 None 8 [111, 444, 'egon', '3333', 'a', 'd', 's']
- 方法三,l.remove,删除指定的内容
10,循环,for,注意在循环的时候尽量不要做修改内容,否则容易产生逻辑问题
11,了解知识,以l=[111,'hello','egon','hello']为例
-
- 计数, print(l.count('hello')) 结果为2 ,计算列表中查找内容出现的次数
- 查找, print(l.index(111)) 结果为0 ,返回查找内容的位置,如果没有的话,就会返回错误
- 清除, l.clear() ,会把列表中的内容清除
- 翻转, l.reverse() ,将列表的内容翻转过来
- 排序, l.sort() #默认为从小到大的升序进行排序 l.sort(reverse=True) #可以改变参数达到降序的效果 ,可以对纯数字、纯字母排序(按照ASCI码表排序)
- 补充:字符串大小是按照ASCI码表排序,不是按照长度比的,比较原则是按照对应字母的大小比较
- 列表也可以比较大小,比较原则与字符串相似
六,布尔值(可以用0和1进行代替。)
分类:第一大类:显示布尔值
-
- 可以是比较运算符: print(10>5)
- 可以是:True、False
第二大类:隐式布尔值,
所有数据类型中0、None、空(空字符串、空列表、空字段)代表的都为False,其余为真。
总结:对上述数据类型进行一个总结:可变与不可变类型
#1.可变类型:在改变值的情况下,id不变,则称为可变类型,如列表,字典 #2. 不可变类型:在值改变的情况下,id也改变,则称为不可变类型(id变,意味着创建了新的内存空间)
如,整数、小数、str、布尔值(对于这四个,都被设计成了不可分割的整体,不能够被改变)
七,字典
1,定义:{}内用逗号隔开,用key:value填充,注意key不可重复
2,其中value可以使任意类型,key可以必须是不可变类型,比如字符串。元组、数字
3,快速建造初始化字典
1 keys=['name', 'age', 'height', 'weight'] 2 d={}.fromkeys(keys,None) 3 print(d) 4 ***************** 5 {'name': None, 'age': None, 'height': None, 'weight': None}
4,内置方法
-
- 取
1 >>> dic = { 2 ... 'name': 'xxx', 3 ... 'age': 18, 4 ... 'hobbies': ['play game', 'basketball'] 5 ... } 6 >>> dic['name'] 7 'xxx' 8 >>> dic['hobbies'][1] 9 'basketball'
- 赋值
1 # 1.2 对于赋值操作,如果key原先不存在于字典,则会新增key:value 2 >>> dic['gender'] = 'male' 3 >>> dic 4 {'name': 'tony', 'age': 18, 'hobbies': ['play game', 'basketball'],'gender':'male'} 5 # 1.3 对于赋值操作,如果key原先存在于字典,则会修改对应value的值 6 >>> dic['name'] = 'tony' 7 >>> dic 8 {'name': 'tony', 'age': 18, 'hobbies': ['play game', 'basketball']}
- 删除、也可以用del
1 >>> dic.pop('name') # 通过指定字典的key来删除字典的键值对 2 >>> dic 3 {'age': 18, 'hobbies': ['play game', 'basketball']}
- 还有popitem函数可以进行删除操作,有随机删除的特点,返回一个元组,其中包含随机删除的key与value
键keys(),值values(),键值对items()1 >>> dic = {'age': 18, 'hobbies': ['play game', 'basketball'], 'name': 'xxx'} 2 # 获取字典所有的key 3 >>> dic.keys() 4 dict_keys(['name', 'age', 'hobbies']) 5 # 获取字典所有的value 6 >>> dic.values() 7 dict_values(['xxx', 18, ['play game', 'basketball']]) 8 # 获取字典所有的键值对 9 >>> dic.items() 10 dict_items([('name', 'xxx'), ('age', 18), ('hobbies', ['play game', 'basketball'])])
- 循环
1 # 6.1 默认遍历的是字典的key 2 >>> for key in dic: 3 ... print(key) 4 ... 5 age 6 hobbies 7 name 8 # 6.2 只遍历key 9 >>> for key in dic.keys(): 10 ... print(key) 11 ... 12 age 13 hobbies 14 name 15 # 6.3 只遍历value 16 >>> for key in dic.values(): 17 ... print(key) 18 ... 19 18 20 ['play game', 'basketball'] 21 xxx 22 # 6.4 遍历key与value 23 >>> for key in dic.items(): 24 ... print(key) 25 ... 26 ('age', 18) 27 ('hobbies', ['play game', 'basketball']) 28 ('name', 'xxx')
- 取
5,需要掌握的函数
-
- 更新字典,
用新字典更新旧字典,有则修改,无则添加,update()1 >>> dic={'k1':111,'k2':222} 2 >>> res=dic.setdefault('k3',333) 3 >>> res 4 333 5 >>> dic # 字典中新增了键值对 6 {'k1': 111, 'k3': 333, 'k2': 222}
- 获取值,一般获取的如果没有的话就会报错,但是get会返回None,get()
1 >>> dic= {'k1':'jason','k2':'Tony','k3':'JY'} 2 >>> dic.get('k1') 3 'jason' # key存在,则获取key对应的value值 4 >>> res=dic.get('xxx') # key不存在,不会报错而是默认返回None 5 >>> print(res) 6 None 7 >>> res=dic.get('xxx',666) # key不存在时,可以设置默认返回的值 8 >>> print(res) 9 666 10 # ps:字典取值建议使用get方法
- fromkeys(),取所有的key值
1 1 >>> dic = dict.fromkeys(['k1','k2','k3'],[]) 2 2 >>> dic 3 3 {'k1': [], 'k2': [], 'k3': []}
- setdefauit(),有则不动,没则定之
1 # key不存在则新增键值对,并将新增的value返回 2 >>> dic={'k1':111,'k2':222} 3 >>> res=dic.setdefault('k3',333) 4 >>> res 5 333 6 >>> dic # 字典中新增了键值对 7 {'k1': 111, 'k3': 333, 'k2': 222} 8 9 # key存在则不做任何修改,并返回已存在key对应的value值 10 >>> dic={'k1':111,'k2':222} 11 >>> res=dic.setdefault('k1',666) 12 >>> res 13 111 14 >>> dic # 字典不变 15 {'k1': 111, 'k2': 222}
- 更新字典,
八,元组,就是一个不可变的列表,注意这个不可改变的是里面的内存地址,所以里面入过有列表的话可以进行更改,有序
1,作用:放置多个值,只用于读,不用于改
2,定义:()用多个逗号分隔多个任意类型的元素
3,类型转换:
-
- 字符串
tuple('wdad') # 结果:('w', 'd', 'a', 'd')
- 列表
tuple([1,2,3]) # 结果:(1, 2, 3) - 字典
tuple({"name":"jason","age":18}) # 结果:('name', 'age') - 元组
uple((1,2,3)) # 结果:(1, 2, 3) - 集合
tuple({1,2,3,4}) # 结果:(1, 2, 3, 4)
- 字符串
4,内置函数
1 >>> tuple1 = (1, 'hhaha', 15000.00, 11, 22, 33) 2 # 1、按索引取值(正向取+反向取):只能取,不能改否则报错! 3 >>> tuple1[0] 4 1 5 >>> tuple1[-2] 6 22 7 >>> tuple1[0] = 'hehe' # 报错:TypeError: 8 9 # 2、切片(顾头不顾尾,步长) 10 >>> tuple1[0:6:2] 11 (1, 15000.0, 22) 12 13 # 3、长度 14 >>> len(tuple1) 15 6 16 17 # 4、成员运算 in 和 not in 18 >>> 'hhaha' in tuple1 19 True 20 >>> 'hhaha' not in tuple1 21 False 22 23 # 5、循环 24 >>> for line in tuple1: 25 ... print(line) 26 1 27 hhaha 28 15000.0 29 11 30 22 31 33 32 》》》6,l=(1,2,3,4,5,6,7,8,9) 33 l.index(5) 34 l.count(5)
九,集合
1,作用:
-
- 关系运算
- 去重
2,定义:在{}内用逗号分隔开多个元素,集合具备以下三个特点:
-
每个元素必须是不可变类型- 集合内没有重复的元素
集合内元素无序- 注意:
d = {} # 默认是空字典;s = set() # 这才是定义空集合
- 注意:
3,类型转换
-
- 字典,因为字典中的key是不可变类型,所以可以转换字典
1 d={"k1":1,'k2':22} 2 s=set(d) 3 print(s) 4 *********** 5 {'k1', 'k2'}
- 字符串
1 d='123456' 2 s=set(d) 3 print(s) 4 ************* 5 {'5', '4', '6', '3', '2', '1'}
- 注意:数字不可以,因为数字虽然满足上述条件,但是因为是不可迭代的所以没有办法转化为集合
- 字典,因为字典中的key是不可变类型,所以可以转换字典
4,内置函数
-
- 关系运算
- 取交集,两者共同的好友
1 friends1 & friends2 2 {'jason', 'egon'}
- 取并集,两者所有的好友
1 friends1 | friends2 2 {'kevin', 'ricky', 'zero', 'jason', 'Jy', 'egon'}
- 取差集,有先后顺序
1 >>> friends1 - friends2 # 求用户1独有的好友 2 {'kevin', 'zero'} 3 >>> friends2 - friends1 # 求用户2独有的好友 4 {'ricky', 'Jy'}
- 取两者独有的,就是去掉共有的
1 friends1 ^ friends2 2 {'kevin', 'zero', 'ricky', 'Jy'}
- 父子集,包含的关系
1 >>> {1,2,3} > {1,2} 2 True 3 >>> {1,2,3} >= {1,2} 4 True 5 # 6.2 不存在包含关系,则返回False 6 >>> {1,2,3} > {1,3,4,5} 7 False 8 >>> {1,2,3} >= {1,3,4,5} 9 False
- 是否相等
1 friends1 == friends2
- 取交集,两者共同的好友
- 去重,有局限性:1,只能针对不可变类型;2,无法保证顺序
- 关系运算
总结:
十,与用户交互
1,接受用户输入
python3中:input
输入的所有内容都是字符串类型
python2.7中:input、raw_input
input是必须输入同一类型的数据
raw_input与python3中的input一样
2,字符串的格式化输出:%、format0
-
-
- 第一种,值按照位置与%s意义对应,少一个、多一个都不行
-
res='my name is %s and my age is %s'%('alex','18') print(res) ************ my name is alex and my age is 18
- 以字典的形式填充可以打破顺序
res='my name is %(name)s and my age is %(age)s'%{'name':'alex', 'age':18} print(res) ********** my name is alex and my age is 18
-
- 第一种,值按照位置与%s意义对应,少一个、多一个都不行
-
-
-
- 第二种,format
- 按位置传值
res='my name is {} and my age is {}'.format('alex',18) print(res) ********* my name is alex and my age is 18
- 可选择的
res='my name is {0} and my age is {1}'.format('alex',18) print(res) ********** my name is alex and my age is 18
- 打破位置的限制,按照key=value传值
res='my name is {name} and my age is {age}'.format(name='alex',age=18) print(res) ********* my name is alex and my age is 18
- 按位置传值
- 第三种,f(python3.5之后)
x='alex' y=18 res=f'my name is {x} and my age is {y}' print(res) ********** my name is alex and my age is 18
- 第二种,format
-
十一,基本运算符
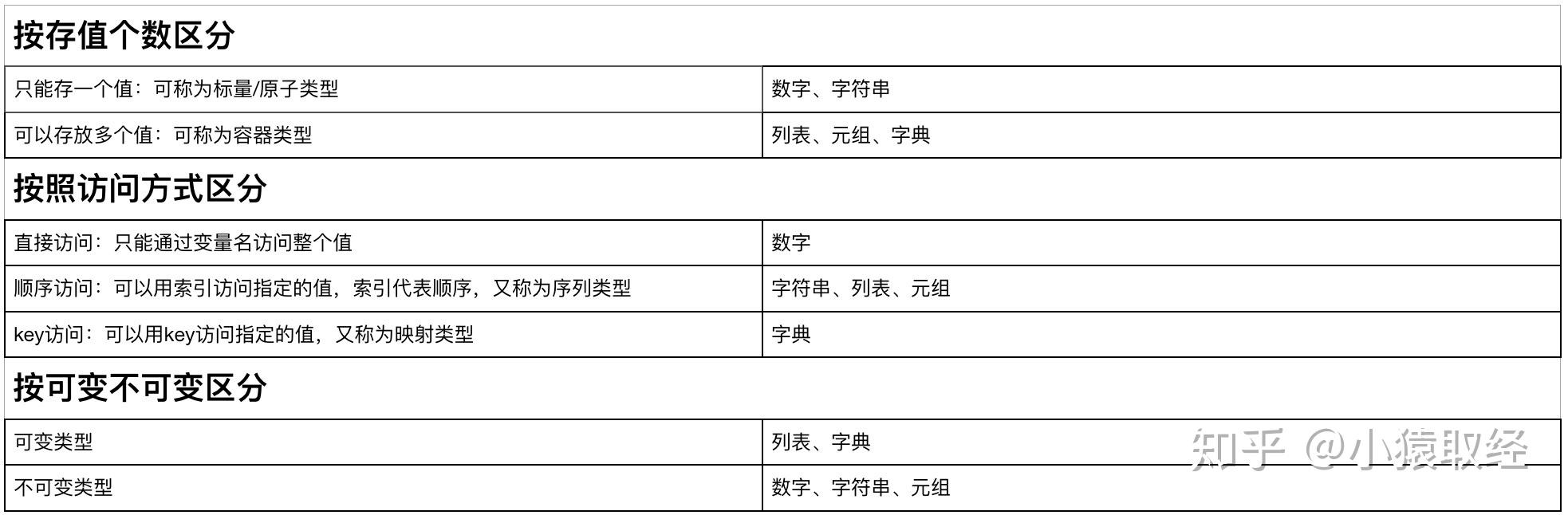
- 算数运算符
![]()
- 赋值运算符
- =,效果为赋值
- 增量赋值
![]()
- 链式赋值
1 >>> z=10 2 >>> y=z 3 >>> x=y 4 >>> x,y,z 5 (10, 10, 10) 6 可以简化为 7 >>> x=y=z=10 8 >>> x,y,z 9 (10, 10, 10)
- 交叉赋值
1 m=10 2 n=20 3 如果要相互交换的话 4 第一种 5 >>> temp=m 6 >>> m=n 7 >>> n=temp 8 >>> m,n 9 (20, 10) 10 第二种 11 >>> m,n=n,m # 交叉赋值 12 >>> m,n 13 (20, 10)
- 解压赋值
想把列表中的多个值取出来依次赋值给多个变量名 第一种: >>> nums=[11,22,33,44,55] >>> >>> a=nums[0] >>> b=nums[1] >>> c=nums[2] >>> d=nums[3] >>> e=nums[4] >>> a,b,c,d,e (11, 22, 33, 44, 55) 第二种(数量必须对上,多一个、少一个都不行) >>> a,b,c,d,e=nums # nums包含多个值,就好比一个压缩包,解压赋值因此得名 >>> a,b,c,d,e (11, 22, 33, 44, 55) 如果取前两个: >>> a,b,*_=nums >>> a,b (11, 22) 如果取后两个: >>> *_,a,b=nums >>> a,b (44,55) 如果取两边的两个: >>> a,*_,b=nums >>> a,b (11, 55) 注意,引入*不能取到中间的
- 比较运算符
![]()
- 逻辑运算符
- not、and、or(区分优先级:not>and>or)
- and:对于and两边的条件,只由两边的条件都为真,该判断才为真
- or:对于两边的条件只要一个为真,则该判断为真
- 优先级
- 如果只有and或or连接的话,就从左到右的顺序判断即可
- 如果是混用的话。就依据not>and>or进行判断即可
- 了解,短路运算
- not、and、or(区分优先级:not>and>or)
- 成员运算符
- in
-
1 print('e' in 'my name is elal') #判断一个字符串是否在另一个字符串里 2 print('elal' in 'my name is elal')#判断一个字母是否在另一个字符串里
- print('111' in [111,222,333,444,555]) #判断元素是否在列表里
-
print(111 in {'k1':111, 'k2':222, 'k3':333}) #输出结果为 Flase print('k1' in {'k1':111, 'k2':222, 'k3':333}) #输出结果为 Ture
-
- in
- 身份运算符
- is,判断id是否相等


十二,if...else...
用法:
- 1 if 条件: 2 代码 3 else: 4 代码
-
1 第一种: 2 if 条件: 3 代码 4 elif:代码 5 else: 6 代码 7 第二种 8 if 条件: 9 代码 10 else: 11 代码 12 ************* 13 第一种虽然更加简洁,但是第二种更加灵活。 14 因为第一种是一条路走到头的。
十三,copy之深浅
需求:1,拷贝一下原列表产生一个新列表
2,想让两个列表完全独立开,就是保留原列表的数据还对新的列表进行更改。
1, 浅copy:是把原列表第一层内存地址不加区分完全copy一份给新列表。如果列表中只有不可变类型还是可以的,但是如果里边有列表这种不可变类型是没有用的。
a=[1,2,[3,4]] b=a.copy() print(id(a)) print(id(b)) ********* 1996050762624 1996051995776
2,深copy:是将所有的可变类型的容器进行复制,直到不可变类型
1 a=[1,2,[3,4]] 2 import copy 3 b=copy.deepcopy(a) 4 print(id(a[2])) 5 print(id(b[2])) 6 *********** 7 2112001102976 8 2112001102720
十四,循环之while
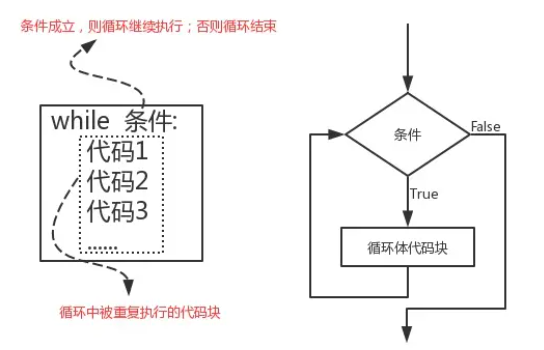
1,语法:
1 while 条件: 2 代码1 3 代码2 4 代码3 5 while的运行步骤: 6 步骤1:如果条件为真,那么依次执行:代码1、代码2、代码3、...... 7 步骤2:执行完毕后再次判断条件,如果条件为True则再次执行:代码1、代码2、代码3、......,如果条件为False,则循环终止
2,死循环与效率关系
1 #第一种 2 a=1 3 while 1: 4 print(a) 5 #第二种 6 while 1: 7 name=input('请输入你的名字:') 8 print(name) 9 #第三种 10 while 1: 11 1+1
这三种死循环,第一种与第二种只有是输出,即使是死循环也危害不大,但是第三种是在cpu中纯计算无IO进行死循环的这种是很有危害的。
3,while结束循环的方法
-
-
- 设置变量值tag=Ture
username = "jason" password = "123" count = 0 tag = True while tag: inp_name = input("请输入用户名:") inp_pwd = input("请输入密码:") if inp_name == username and inp_pwd == password: print("登陆成功") while tag: cmd = input('>>: ') if cmd == 'quit': tag = False # tag变为False, 所有while循环的条件都变为False break print('run <%s>' % cmd) break # 用于结束本层循环,即第一层循环 else: print("输入的用户名或密码错误!") count += 1
- 第二种,使用break进行终止
1 username = "jason" 2 password = "123" 3 # 记录错误验证的次数 4 count = 0 5 while count < 3: 6 inp_name = input("请输入用户名:") 7 inp_pwd = input("请输入密码:") 8 if inp_name == username and inp_pwd == password: 9 print("登陆成功") 10 break # 用于结束本层循环 11 else: 12 print("输入的用户名或密码错误!") 13 count += 1
- while+continue(在continue后面加上同级代码毫无意义,因为无法运行)
1 # 打印1到10之间,除7以外的所有数字 2 number=11 3 while number>1: 4 number -= 1 5 if number==7: 6 continue # 结束掉本次循环,即本次循环continue之后的代码都不会运行了,而是直接进入下一次循环 7 print(number)
- while+else
count = 0 while count <= 5 : count += 1 if count == 3: break print("Loop",count) else: #else后面的代码是否可以执行取决于上面有没有break,有的话容易被打断无法执行 print("循环正常执行完啦") print("-----out of while loop ------") 输出 Loop 1 Loop 2 -----out of while loop ------ #由于循环被break打断了,所以不执行else后的输出语句
- 设置变量值tag=Ture
-
十五,循环之for
与while相比:
- 相同之处:都是循环,for循环可以干的事,while都可以干
- 不同之处:
- while循环你称之为条件循环,循环次数取决于条件何时变为假
- for循环称之为取值循环,循环次数取决于in后面包含值的个数
- for在遍历方面上更加简洁
语法:
for 变量名 in 可迭代对象(包括列表、字典、字符串。元组。集合): 代码1 代码2 .......
搭配使用:
-
- for+range(0(开始值,默认为0),1(结束值),2(步长))
- for+continue
- for循环嵌套:外层循环一次,内层循环一遍
- for+break,终止循环
十六,内存管理:垃圾回收机制
当内存中的值与变量名断了关系后,此时的值已经不可能被引用了,所以此时的值被称为垃圾,然后内存管理就会将垃圾进行回收,以释放内存。
相关名词:1,垃圾,当一个变量值被绑定的变量名的个数为0时,该变量值也就无法被访问,此值被称为垃圾
2,引用计数,就是变量值被引用的个数。
可以分为:
-
-
-
-
- 直接引用,就是直接对变量值的内存地址进行引用的一种方式
- 比如,
x=10 y=x print(id(x)) print(id(y)) *********1973569284688 1973569284688
- 比如,
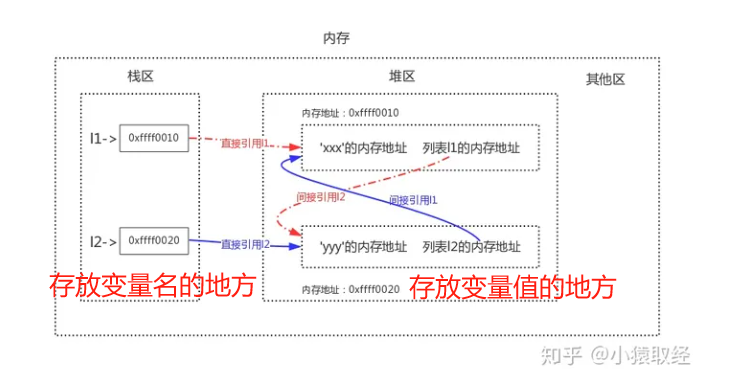
- 间接引用,比如列表,对于列表l而言,他的直接引用地址是后面的列表。
![]()
![]()
- 直接引用,就是直接对变量值的内存地址进行引用的一种方式
-
-
-


3,循环引用
1 a=[1,2] 2 b=[3,4] 3 a.append(b) 4 b.append(a) #c此时对于a、b而言有直接引用,间接引用两种 5 print(a) 6 del a 7 del b #虽然把a、b的直接引用已经去除,但是间接引用任然存在,这就会导致虽然没办法引用,也无法清除。
为了应对这种情况,就会在内存不够用时先扫描栈区,通过栈区的变量名可以直接引用的变量值打上存活的标记,然后再扫描堆区清除没有标记的变量值。
进步方案,因为这种扫描和清除还是比较耗费时间所以加上了权重
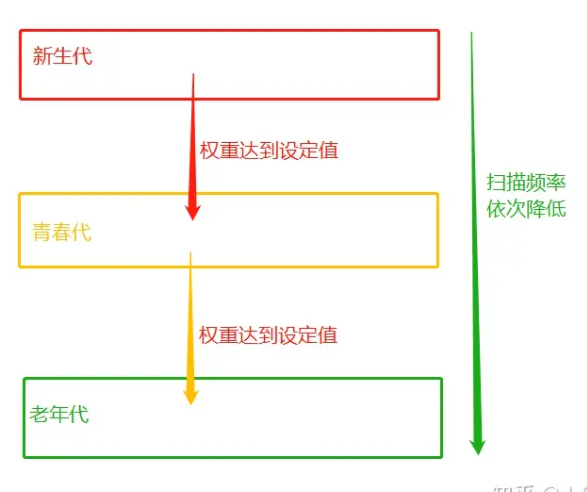
减少计数方法:1, x=10 del x
2,将新的变量值赋值于变量
十七,is与==的不同
is:比较左右两个值身份ID是否相同
==:比较左右两个他们的值是否相同
id不同,值可能相同。即两块不同的内存空间可以存相同的值
id相同,值一定相同。即,x is y成立,x = = y必然成立
补充,小整数池,一般的解释器会运转时会自发的整理一些数据,比如-5到256的整数、一些常见的字母组合,这样的话需要使用这些数据时就会直接引用这些内存地址,以达到节省内存的效果。(pycharm不知是小整数池太大还是直接优化成一样的了,怎么比较也比较不出来两者的区别)
posted on 2024-01-27 23:05 我才是最帅的那个男人 阅读(13) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号