
再谈hive-1.0.0与hive-1.2.1到JDBC编程忽略细节问题
不多说,直接上干货,这个问题一直迷惑已久,今天得到亲身醒悟。
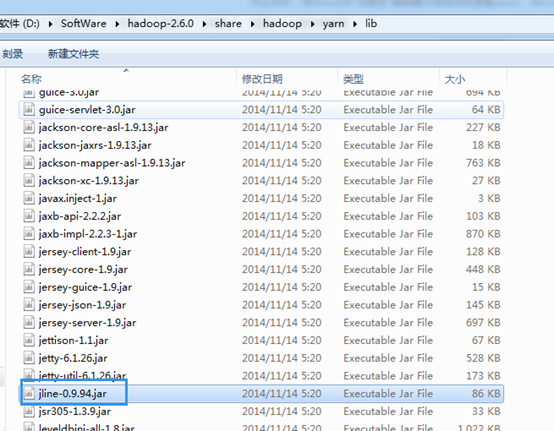
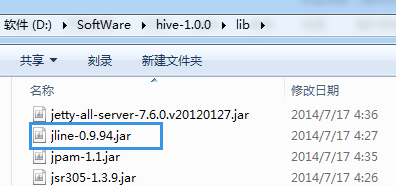

所以,建议hadoop-2.6.0.tar.gz的用户与hive-1.0.0搭配使用。当然,也可以去用高版本去覆盖它。
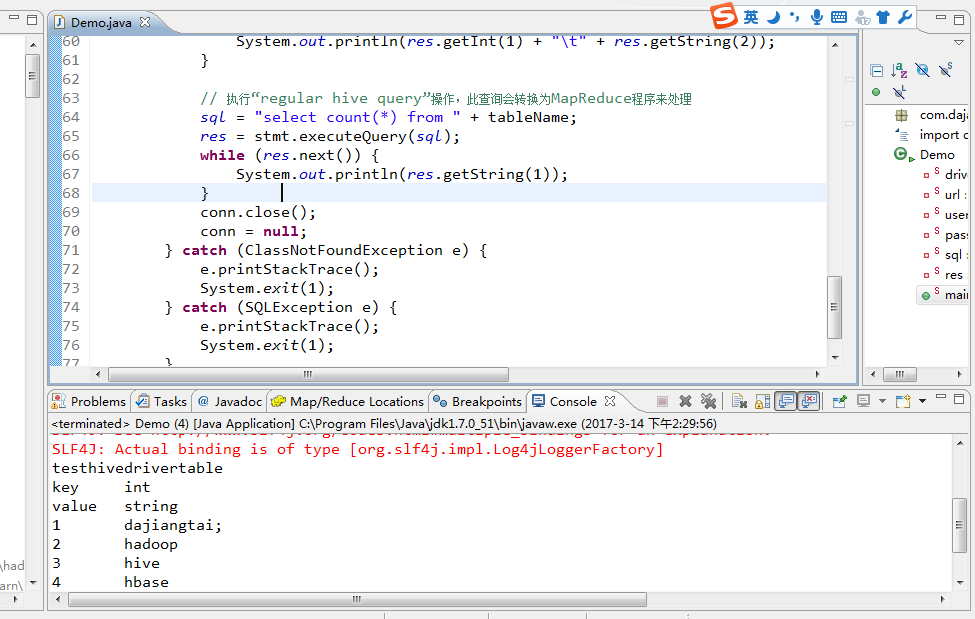
log4j:WARN No appenders could be found for logger (org.apache.hive.jdbc.Utils).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/D:/SoftWare/hadoop-2.6.0/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/D:/SoftWare/hive-1.0.0/lib/hive-jdbc-1.0.0-standalone.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
testhivedrivertable
key int
value string
1 dajiangtai;
2 hadoop
3 hive
4 hbase
5 spark
5
注意:在编程这端运行成功的同时:
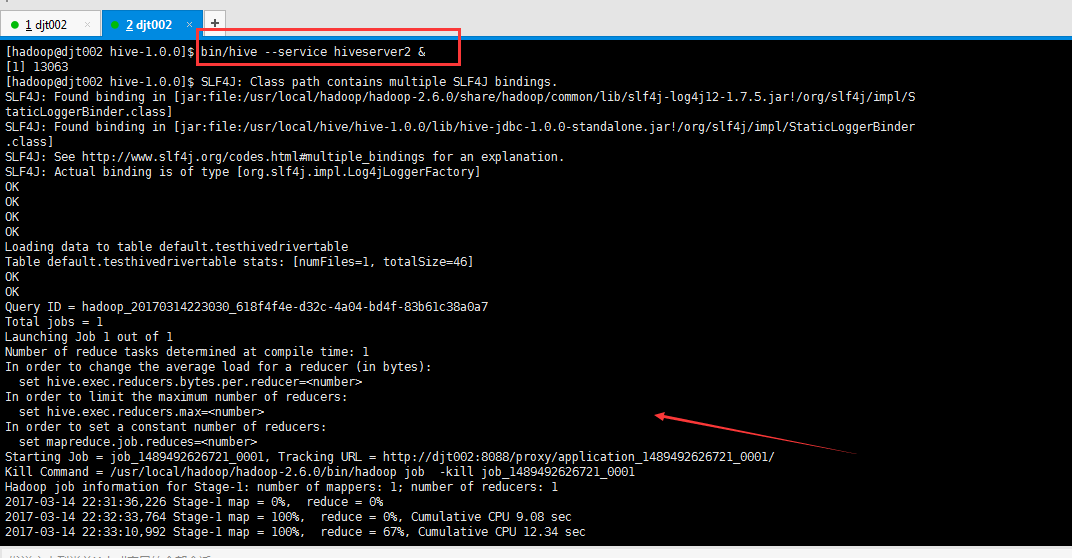
[hadoop@djt002 hive-1.0.0]$ bin/hive --service hiveserver2 &
[1] 13063
[hadoop@djt002 hive-1.0.0]$ SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/local/hive/hive-1.0.0/lib/hive-jdbc-1.0.0-standalone.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
OK
OK
OK
OK
Loading data to table default.testhivedrivertable
Table default.testhivedrivertable stats: [numFiles=1, totalSize=46]
OK
OK
Query ID = hadoop_20170314223030_618f4f4e-d32c-4a04-bd4f-83b61c38a0a7
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1489492626721_0001, Tracking URL = http://djt002:8088/proxy/application_1489492626721_0001/
Kill Command = /usr/local/hadoop/hadoop-2.6.0/bin/hadoop job -kill job_1489492626721_0001
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2017-03-14 22:31:36,226 Stage-1 map = 0%, reduce = 0%
2017-03-14 22:32:33,764 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 9.08 sec
2017-03-14 22:33:10,992 Stage-1 map = 100%, reduce = 67%, Cumulative CPU 12.34 sec
2017-03-14 22:33:14,485 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 14.51 sec
MapReduce Total cumulative CPU time: 14 seconds 510 msec
Ended Job = job_1489492626721_0001
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 14.51 sec HDFS Read: 266 HDFS Write: 2 SUCCESS
Total MapReduce CPU Time Spent: 14 seconds 510 msec
OK
[hadoop@djt002 hive-1.0.0]$
总结,在用hive编程时,hive-1.0.0与hadoop-2.6.0搭配。还是最好的一个搭档。
我这里是手动新建的普通项目,即,将hadoop下的lib下所有的jar包和hive下的lib下的所有jar包,都导进入。
作者:大数据和人工智能躺过的坑
出处:http://www.cnblogs.com/zlslch/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接,否则保留追究法律责任的权利。
如果您认为这篇文章还不错或者有所收获,您可以通过右边的“打赏”功能 打赏我一杯咖啡【物质支持】,也可以点击右下角的【好文要顶】按钮【精神支持】,因为这两种支持都是我继续写作,分享的最大动力!

