

颜色格式转换: rgb2gray 从实现到优化
Update: 2025.04.20
1. 概要
rgb 图像转为灰度图, 是图像预处理中很常见的一个任务。 本文从 naive 的实现开始,一步步优化性能。
环境:设备为 mac-mini 2020 款,芯片是 M1(aarch64), 编译器是 Apple Clang 15.0.0。 输入图像为 7680(宽) x 4320(高) 大小. 耗时单位为毫秒 (ms)。 OpenCV 为 4.11.0 版本。
2. 接口设计
重点在于性能优化, 就不自行定义图像类型的数据结构了, 直接使用 OpenCV 的 cv::Mat. 结果图像的内存申请,也用 cv::Mat::create( ) 来自动处理. cv::cvtColor( ) 默认会启用多线程,用 cv::parallel_for_ 做加速, 个人认为这个方法不灵活, 在多个算法SDK集成使用时,每个SDK能使用的线程数量不一样,因此允许传入线程数量是不错的选择。
设计出的接口如下:
struct Option
{
int num_threads{};
};
void rgb_to_gray_(const cv::Mat& rgb, cv::Mat& gray, const Option& opt)
{
gray.create(rgb.size(), CV_8UC1);
...
}
3. 实验
3.1 naive 实现: 浮点计算
void rgb_to_gray(const cv::Mat& rgb, cv::Mat& gray, const Option& opt)
{
gray.create(rgb.size(), CV_8UC1);
const int h = rgb.rows;
const int w = rgb.cols;
constexpr float cr = 0.299f;
constexpr float cg = 0.587f;
constexpr float cb = 0.114f;
for (int i=0; i<h; i++)
{
const uint8_t* sp = rgb.data + i * rgb.step;
uint8_t* dp = gray.data + i * gray.step;
for (int j=0; j<w; j++)
{
const uint8_t& r = sp[0];
const uint8_t& g = sp[1];
const uint8_t& b = sp[2];
const int gray = static_cast<int>(r * cr + g * cg + b * cb + 0.5f);
*dp = gray > 255 ? 255 : (gray < 0 ? 0 : gray);
sp += 3;
dp++;
}
}
}
| 实现方式. | 耗时(Debug) | 耗时(Release) |
|---|---|---|
| cv::cvtColor | N/A | 4 |
| 浮点 | 160 | 20 |
3.2 加速:定点化
void rgb_to_gray(const cv::Mat& rgb, cv::Mat& gray, const Option& opt)
{
gray.create(rgb.size(), CV_8UC1);
const int h = rgb.rows;
const int w = rgb.cols;
// 0.299 * 256 = 76.644 -> 77
// 0.587 * 256 = 150.272 -> 150
// 0.114 * 256 = 29.184 -> 29
constexpr uint16_t cr = 77;
constexpr uint16_t cg = 150;
constexpr uint16_t cb = 29;
for (int i=0; i<h; i++)
{
const uint8_t* sp = rgb.data + i * rgb.step;
uint8_t* dp = gray.data + i * gray.step;
int remain = w;
for (; remain > 0; remain--)
{
const uint8_t& r = sp[0];
const uint8_t& g = sp[1];
const uint8_t& b = sp[2];
const uint16_t gray = static_cast<uint16_t>(r * cr + g * cg + b * cb + 128) >> 8;
*dp = gray > 255 ? 255 : (gray < 0 ? 0 : gray);
sp += 3;
dp++;
}
}
}
| 实现方式. | 耗时(Debug) | 耗时(Release) |
|---|---|---|
| cv::cvtColor | N/A | 4 |
| 浮点 | 160 | 20 |
| 定点化 | 101 | 11 |
定点化的位数,如果设置不当,例如 uint32_t, 有些平台上可能耗时会增加
const uint8_t& r = sp[0];
const uint8_t& g = sp[1];
const uint8_t& b = sp[2];
//const uint16_t gray = static_cast<uint16_t>(r * cr + g * cg + b * cb + 128) >> 8;
const uint32_t gray = static_cast<uint32_t>(r * cr + g * cg + b * cb + 128) >> 8;
*dp = gray > 255 ? 255 : (gray < 0 ? 0 : gray);
3.3 加速:多线程
将图像的高度方向上,按照线程数量划分。例如两个线程,则每个线程处理一半:
|--------------------------------- |
| |
| thread 1 |
| |
| -------------------------------- |
| |
| thread 2 |
| |
| -------------------------------- |
对于近年来手机 SoC 的 「超大核-大核-小核」 架构, 这未必是最佳的划分方式; 但用户可以显式传入线程数量、而不是全局用同一份线程数量,解耦了线程的控制,更容易调出较优性能。
简单起见,手写一个 parallel_for() 函数, 而不是依赖 OpenCV 的同名函数, 这样便于后续移植。
void parallel_for(int start, int end, std::function<void(int)> f, size_t num_threads)
{
using Index = int;
Index total = end - start;
if (total <= 0) return;
if (num_threads == 0) num_threads = 1;
if (num_threads == 1)
{
for (int i = start; i < end; i++)
{
f(i);
}
}
else
{
Index block_size = (total + num_threads - 1) / num_threads; // 向上取整
std::vector<std::thread> threads;
for (size_t t = 0; t < num_threads; ++t) {
Index block_start = start + t * block_size;
Index block_end = std::min(block_start + block_size, end);
// 避免启动没有任务的线程
if (block_start >= block_end) break;
threads.emplace_back([=]() {
for (Index i = block_start; i < block_end; ++i)
f(i);
});
}
for (auto& th : threads) th.join();
}
}
具体的 rgb2gray 实现,基于先前定点化的实现,我们将
for (int i=0; i<h; i++)
{
...
}
改为
::parallel_for(0, h, [&](int i) {
...
}, opt.thread_num);
完整代码是:
void rgb_to_gray(const cv::Mat& rgb, cv::Mat& gray, const Option& opt)
{
gray.create(rgb.size(), CV_8UC1);
const int h = rgb.rows;
const int w = rgb.cols;
// 0.299 * 256 = 76.644 -> 77
// 0.587 * 256 = 150.272 -> 150
// 0.114 * 256 = 29.184 -> 29
constexpr uint16_t cr = 77;
constexpr uint16_t cg = 150;
constexpr uint16_t cb = 29;
::parallel_for(0, h, [&](int i) {
const uint8_t* sp = rgb.data + i * rgb.step;
uint8_t* dp = gray.data + i * gray.step;
int remain = w;
for (; remain > 0; remain--)
{
const uint8_t& r = sp[0];
const uint8_t& g = sp[1];
const uint8_t& b = sp[2];
const uint16_t gray = static_cast<uint16_t>(r * cr + g * cg + b * cb + 128) >> 8;
*dp = gray > 255 ? 255 : (gray < 0 ? 0 : gray);
sp += 3;
dp++;
}
}, opt.thread_num);
}
| 实现方式. | 耗时(Debug) | 耗时(Release) |
|---|---|---|
| cv::cvtColor | N/A | 4 |
| 浮点 | 160 | 20 |
| 定点化 | 101 | 11 |
| 定点化+2线程 | 54 | 7 |
| 定点化+4线程 | 32 | 4 |
其中 OpenCV 的 cv::cvtColor() 是 8 线程:
std::cout << "OpenCV using " << cv::getNumThreads() << " threads" << std::endl;
3.4 neon: 未必提供优化
以往在 Android 上的 neon 性能优化经验是, 手写 neon intrinsics 基本上能提高性能。 但是 Apple Clang 15.0.0 似乎优化做的不错, 以至于, 我手写的 intrinsics 反倒让性能变慢。 那么为了让代码能同时在 Android 手机和 Apple-M1 电脑上运行, 不妨把 manual_neon 也作为 Option 可以配置的内容项:
struct Option
{
int num_threads{};
bool manual_neon{}; // new added
};
代码变得稍微复杂了点:
void rgb_to_gray(const cv::Mat& rgb, cv::Mat& gray, const Option& opt)
{
gray.create(rgb.size(), CV_8UC1);
const int h = rgb.rows;
const int w = rgb.cols;
// 0.299 * 256 = 76.644 -> 77
// 0.587 * 256 = 150.272 -> 150
// 0.114 * 256 = 29.184 -> 29
constexpr uint16_t cr = 77;
constexpr uint16_t cg = 150;
constexpr uint16_t cb = 29;
#if __ARM_NEON
const uint8x8_t vcr = vdup_n_u8(cr);
const uint8x8_t vcg = vdup_n_u8(cg);
const uint8x8_t vcb = vdup_n_u8(cb);
const uint16x8_t vhalf = vdupq_n_u16(128); // 2 << (8 - 1)
#endif
::parallel_for(0, h, [&](int i) {
const uint8_t* sp = rgb.data + i * rgb.step;
uint8_t* dp = gray.data + i * gray.step;
int remain = w;
int nn = 0;
#if __ARM_NEON
if (opt.manual_neon)
{
nn = w >> 3;
remain = w - (nn << 3);
}
#endif
#if __ARM_NEON
if (opt.manual_neon)
{
for (int j=0; j<nn; j++)
{
uint8x8x3_t vs = vld3_u8(sp);
uint16x8_t vres = vmull_u8(vs.val[0], vcr); // r * cr
vres = vmlal_u8(vres, vs.val[1], vcg); // + g * cg
vres = vmlal_u8(vres, vs.val[2], vcb); // + b * cb
vres = vaddq_u16(vres, vhalf); // + 128四舍五入
uint8x8_t vgray = vshrn_n_u16(vres, 8); // / 256
vst1_u8(dp, vgray);
sp += 24; // 8 * 3 channels
dp += 8;
}
}
#endif
for (; remain > 0; remain--)
{
const uint8_t& r = sp[0];
const uint8_t& g = sp[1];
const uint8_t& b = sp[2];
const uint16_t gray = static_cast<uint16_t>(r * cr + g * cg + b * cb + 128) >> 8;
*dp = gray > 255 ? 255 : (gray < 0 ? 0 : gray);
sp += 3;
dp++;
}
}, opt.num_threads);
}
在 Debug 模式下的性能提示还是明显的 (32 -> 27), Release 则几乎没提升, 有时候还会跑到小核上,导致耗时变为9ms。。。
| 实现方式. | 耗时(Debug) | 耗时(Release) |
|---|---|---|
| cv::cvtColor | N/A | 4 |
| 浮点 | 160 | 20 |
| 定点化 | 101 | 11 |
| 定点化+2线程 | 54 | 7 |
| 定点化+4线程 | 32 | 4 |
| 定点化+4线程+neon | 27 | 3 |
4. 总结
本文给出了 rgb2gray 的实现和优化。
定点化带来的性能提升是显著的,无论是 Debug 还是 Release 模式。
多线程带来的性能提升也是显著的,但如果是在 大小核、 超大-大-小核的 SoC 上,带来的性能提升不一定是按线程数量计算的。
手写 neon intrinsics 在 Apple M1 芯片上,在 Debug 模式下稍有一些性能提升, 在 Release 模式下的提升则不太明显, 而一旦程序跑到小核上, 还会表现出耗时明显增多的情况。
以下为初版博客内容
环境和原理说明
测试设备: 小米11, QCOM888.
使用 NDK-r22 编译器. 使用 OpenCV 的 Mat, imread/imwrite 等基础设施,以及作为对照比较性能。
使用 C++ 模板技术: 由于确定了是 RGB 因此编译器确定通道数量为3;同时想支持 BGR,因此增加 bIdx 这一模板参数。
测试图片: W=7680, H=4320,3通道。
RGB 转 Gray 的公式是 Gray = R2Y * R + G2Y * G + B2Y * B, 其中
R2Y = 0.299;
G2Y = 0.587;
B2Y = 0.114;
naive 实现
template<int bIdx>
void cvtcolor_bgr_to_gray(const cv::Mat& src, cv::Mat& dst)
{
if (src.depth() != CV_8U)
{
CV_Error(cv::Error::StsBadArg, "only support uchar type");
}
if (src.channels() != 3)
{
CV_Error(cv::Error::StsBadArg, "src is not 3 channels");
}
if (bIdx != 0 && bIdx != 2)
{
CV_Error(cv::Error::StsBadArg, "bIdx should be 0 or 2");
}
const int srcw = src.cols;
const int srch = src.rows;
const int channels = 3;
dst.create(src.size(), CV_8UC1);
for (int i = 0; i < srch; i++)
{
for (int j = 0; j < srcw; j++)
{
uchar b = src.ptr(i, j)[bIdx];
uchar g = src.ptr(i, j)[1];
uchar r = src.ptr(i, j)[2-bIdx];
dst.ptr(i, j)[0] = (0.299*r + 0.587*g + 0.114*b);
}
}
}
优化策略和实现
加速策略包括:
- 编译期确定 src channels 等于3,编译期确定 bIdx (naive实现)
也尝试了编译期确定 srch, srcw, 但没有加速效果 - 像素访问从 Mat.ptr(i, j) 改为指针 (cvtcolor_bgr_to_gray_v1)
- 提速明显
- 定点化到 uint16 (shift=8) (cvtcolor_bgr_to_gray_v2)
- 提速明显
- ARM NEON Intrinsics (cvtcolor_bgr_to_gray_v3)
- 几乎不提速
- 多线程(使用 cv::parallel_for_ + lambda 实现, 也可以用 OpenMP) (cvtcolor_bgr_to_gray_v4)
- 小幅加速
naive 实现和最优实现的速度差很多,同时也要注意大小核心的性能相差很多:
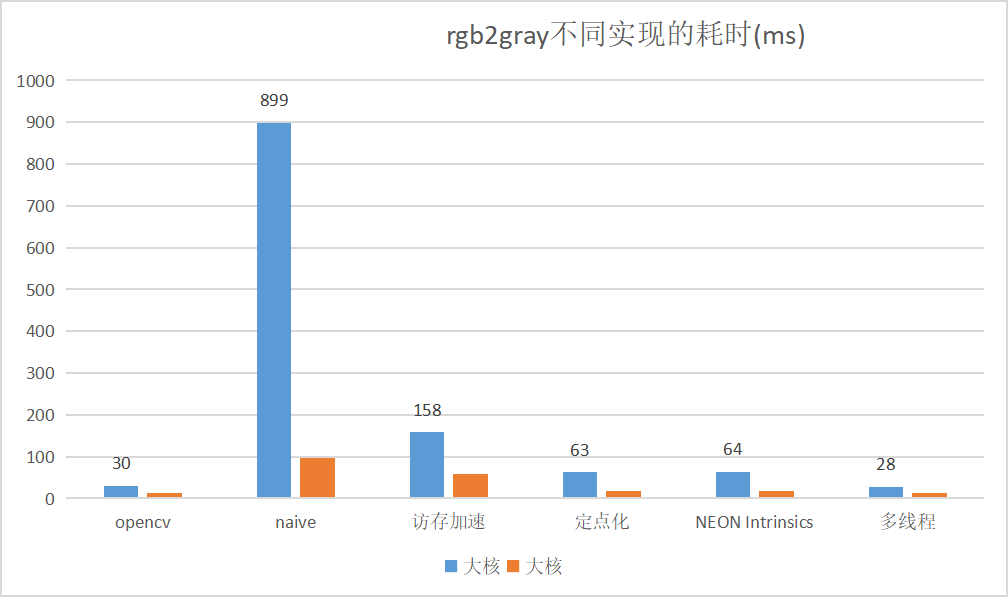
v4 的代码:
template<int bIdx = 0>
void cvtcolor_bgr_to_gray_v4(const cv::Mat& src, cv::Mat& dst)
{
if (src.depth() != CV_8U)
{
CV_Error(cv::Error::StsBadArg, "only support uchar type");
}
if (src.channels() != 3)
{
CV_Error(cv::Error::StsBadArg, "src is not 3 channels");
}
if (bIdx != 0 && bIdx != 2)
{
CV_Error(cv::Error::StsBadArg, "bIdx should be 0 or 2");
}
const int srcw = src.cols;
const int srch = src.rows;
const int channels = 3;
dst.create(src.size(), CV_8UC1);
const uchar* src_line = src.data;
const int src_step = src.step1();
uchar* dst_line = dst.data;
const int dst_step = dst.step1();
const uint8_t R2Y_fx_u8 = 77; // 0.299 * (1 >> 8)
const uint8_t G2Y_fx_u8 = 150; // 0.587 * (1 >> 8)
const uint8_t B2Y_fx_u8 = 29; // 0.114 * (1 >> 8)
const uint16_t R2Y_fx = R2Y_fx_u8;
const uint16_t G2Y_fx = G2Y_fx_u8;
const uint16_t B2Y_fx = B2Y_fx_u8;
const uint16_t shift = 8;
const uint16_t half_fx = (1 << (shift - 1));
#if __ARM_NEON
uint8x8_t v_R2Y_fx = vdup_n_u8(R2Y_fx_u8);
uint8x8_t v_G2Y_fx = vdup_n_u8(G2Y_fx_u8);
uint8x8_t v_B2Y_fx = vdup_n_u8(B2Y_fx_u8);
uint16x8_t v_half_fx = vdupq_n_u16(half_fx);
#endif // __ARM_NEON
cv::parallel_for_(cv::Range(0, srch), [&](const cv::Range& range)
{
for (int i = range.start; i < range.end; i++)
{
const uchar* src_pixel = src_line;
uchar* dst_pixel = dst_line;
#if __ARM_NEON
int nn = srcw >> 3;
int remain = srcw - (nn << 3);
#else
int remain = srcw;
#endif // __ARM_NEON
#if __ARM_NEON
for (int j = 0; j < nn; j++)
{
uint8x8x3_t v_src = vld3_u8(src_pixel);
uint16x8_t v_b2p = vmull_u8(v_src.val[0], v_B2Y_fx);
uint16x8_t v_g2p = vmull_u8(v_src.val[1], v_G2Y_fx);
uint16x8_t v_r2p = vmull_u8(v_src.val[2], v_R2Y_fx);
uint16x8_t v_gray = vaddq_u16(vaddq_u16(vaddq_u16(v_b2p, v_g2p), v_r2p), v_half_fx);
uint8x8_t v_gray_u8 = vshrn_n_u16(v_gray, 8);
vst1_u8(dst_pixel, v_gray_u8);
src_pixel += 8*channels;
dst_pixel += 8;
}
#endif // __ARM_NEON
for (; remain > 0; remain--)
{
uchar b = src_pixel[0];
uchar g = src_pixel[1];
uchar r = src_pixel[2];
//uint16_t gray = (77 * r + 151 * g + 28 * b + (1 << 7)) >> 8;
uint16_t gray = (R2Y_fx * r + G2Y_fx * g + B2Y_fx * b + half_fx) >> shift;
*dst_pixel++ = cv::saturate_cast<uint8_t>(gray);
src_pixel += channels;
}
src_line += src_step;
dst_line += dst_step;
}
});
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号