
一个完整的大作业——凤凰网文化(文学)
一、选一个自己感兴趣的主题
因为对网络上爬取相关的数据不是很了解,所以选择比较简单的,网址是:http://culture.ifeng.com/listpage/59665/1/list.shtml。
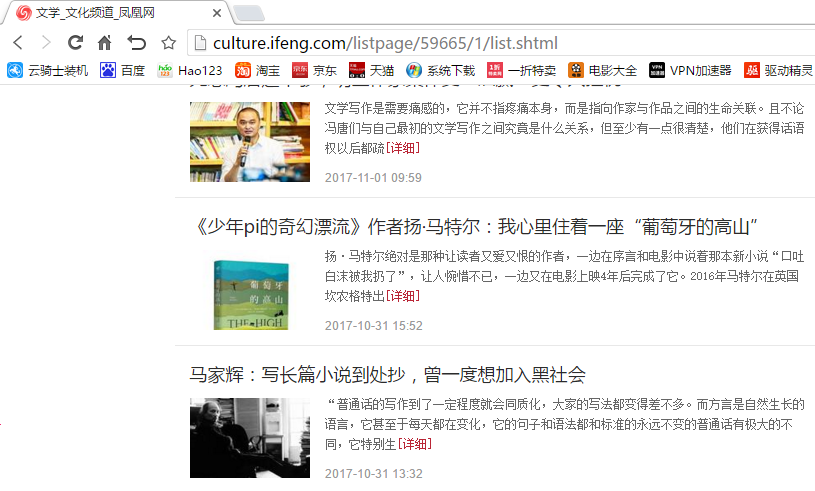
二、网络上爬取相关的数据
1.网络上爬取单条新闻的相关数据
import requests from bs4 import BeautifulSoup from datetime import datetime import re import pandas import sqlite3 import jieba import openpyxl def getdetail(url):#获取单条新闻所有内容 resd = requests.get(url) resd.encoding='utf-8' soupd = BeautifulSoup(resd.text,'html.parser') news = {} news['路径'] = url news['标题'] = soupd.select('h1')[0].text news['发布时间'] = soupd.select('.ss01')[0].text news['来源'] = soupd.select('.ss03')[0].text news['内容'] = soupd.select('.js_selection_area')[0].text return(news) def onepage(url):#获取单条新闻的链接 res = requests.get(url) res.encoding = 'utf-8' soup = BeautifulSoup(res.text,'html.parser') newsls = [] for new in soup.select('.col_L'): for news in new.select('h2'): newsls.append(getdetail(news.select('a')[0]['href'])) break return(newsls) url = 'http://culture.ifeng.com/listpage/59665/1/list.shtml'#新闻的网站 print(onepage(url))

2.爬取网页上所有新闻的相关数据并保存在xlsx文件中
import requests from bs4 import BeautifulSoup from datetime import datetime import re import pandas import sqlite3 import jieba import openpyxl def getdetail(url):#获取网页上所有新闻的相关数据 resd = requests.get(url) resd.encoding='utf-8' soupd = BeautifulSoup(resd.text,'html.parser') news = {} news['路径'] = url news['标题'] = soupd.select('h1')[0].text news['发布时间'] = soupd.select('.ss01')[0].text news['来源'] = soupd.select('.ss03')[0].text news['内容'] = soupd.select('.js_selection_area')[0].text return(news) def onepage(url):#获取网页上所有新闻的链接 res = requests.get(url) res.encoding = 'utf-8' soup = BeautifulSoup(res.text,'html.parser') newsls = [] for new in soup.select('.col_L'): for news in new.select('h2'): newsls.append(getdetail(news.select('a')[0]['href'])) return(newsls) newstotal = [] url = 'http://culture.ifeng.com/listpage/59665/1/list.shtml' newstotal.extend(onepage(url)) df = pandas.DataFrame(newstotal) df.to_excel('news.xlsx')#存放结果的文件
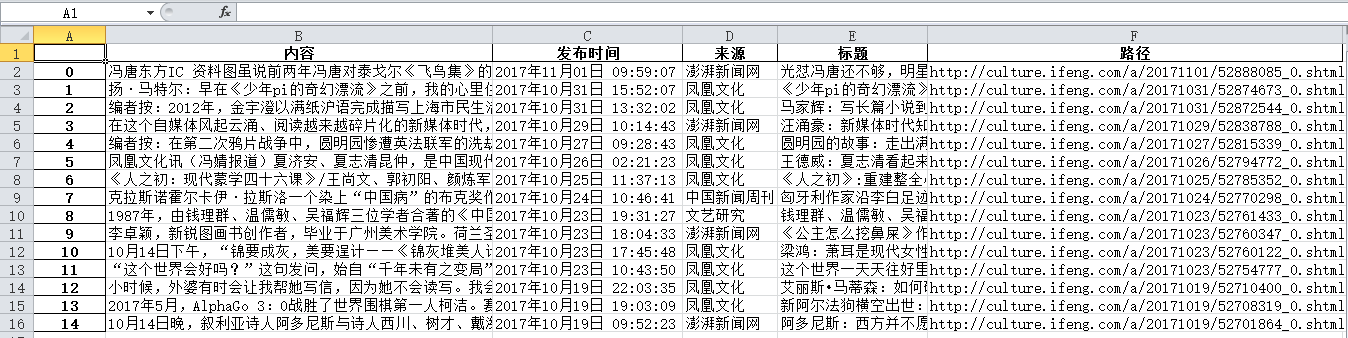
3.将news.xlsx文件中的“内容”列表的内容存放在txt文件中
import openpyxl wb=openpyxl.load_workbook('news.xlsx') #打开excel文件 sheet=wb.get_sheet_by_name('Sheet1') #获取工作表 for i in range(2,sheet.max_row): txt=sheet.cell(row=i,column=2).value txt=txt.replace('\u2022',' ')#替换非法符号 txt=txt.replace('\xa0',' ') open('news.txt',"a").write(txt)

三、进行文本分析,生成词云
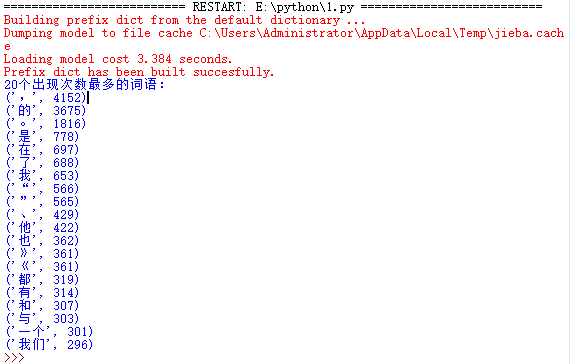
1.使用jieba库,进行中文词频统计,输出TOP20的词及出现次数
import jieba txt = open('news.txt','r').read() words = list(jieba.cut(txt)) dic= {} keys = set(words) for i in keys: dic[i] = words.count(i) wc = list(dic.items()) wc.sort(key=lambda x:x[1],reverse=True) print("20个出现次数最多的词语:") for i in range(20): print(wc[i])
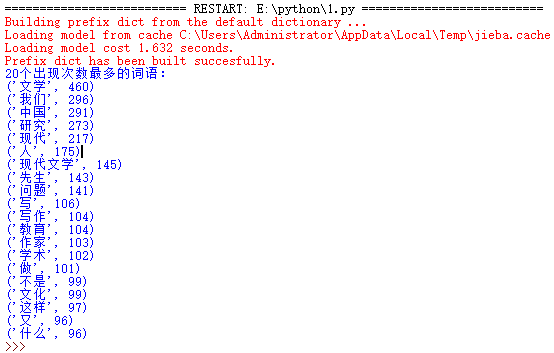
2.排除一些无意义词、合并同一词
import jieba txt = open('news.txt','r').read() exc = {'','的','是','了','我','在','他','也','都','这','和','有','可以','与','就','说','一个','自己','中','对','但','而','就是','现代文','这个','很','你','不','他们','到','年','会','没有','上','把','要'} words = list(jieba.cut(txt,cut_all=True)) dic= {} keys = set(words) for i in exc: keys.remove(i) for i in keys: dic[i] = words.count(i) wc = list(dic.items()) wc.sort(key=lambda x:x[1],reverse=True) print("20个出现次数最多的词语:") for i in range(20): print(wc[i])
3.使用wordcloud库绘制一个词云
from wordcloud import WordCloud import matplotlib.pyplot as plt txt = open('news.txt','r').read() words = WordCloud().generate(txt) plt.imshow(words) plt.axis('off') plt.show()
四、对文本分析结果解释说明
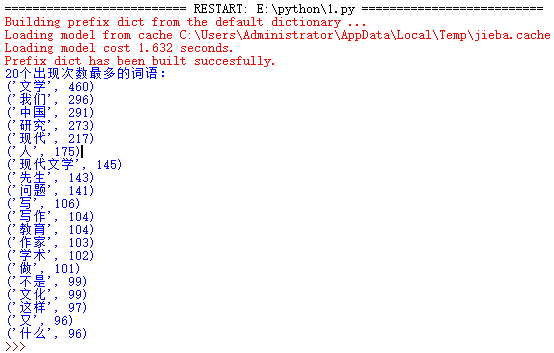
有上图可以看出,词数出现最多的有:“现代文学”、“研究”、“作家”、“教育”、“学术”、“写作”等等,表明了该网页是文学类型的,主要讲了现代文学、教育、写作和研究等方面的内容。
五、完整的源代码
1.中文词频统计,输出TOP20的词及出现次数
import requests from bs4 import BeautifulSoup from datetime import datetime import re import pandas import sqlite3 import jieba import openpyxl def getdetail(url): resd = requests.get(url) resd.encoding='utf-8' soupd = BeautifulSoup(resd.text,'html.parser') news = {} news['路径'] = url news['标题'] = soupd.select('h1')[0].text news['发布时间'] = soupd.select('.ss01')[0].text news['来源'] = soupd.select('.ss03')[0].text news['内容'] = soupd.select('.js_selection_area')[0].text return(news) def onepage(url): res = requests.get(url) res.encoding = 'utf-8' soup = BeautifulSoup(res.text,'html.parser') newsls = [] for new in soup.select('.col_L'): for news in new.select('h2'): newsls.append(getdetail(news.select('a')[0]['href'])) return(newsls) def route(file_save,file_open): wb=openpyxl.load_workbook(file_save) #打开excel文件 sheet=wb.get_sheet_by_name('Sheet1') #获取工作表 for i in range(2,sheet.max_row): txt=sheet.cell(row=i,column=2).value txt=txt.replace('\u2022',' ') txt=txt.replace('\xa0',' ') open(file_open,"a").write(txt) txt = open(file_open,'r').read() return(txt) newstotal = [] url = 'http://culture.ifeng.com/listpage/59665/1/list.shtml' newstotal.extend(onepage(url)) df = pandas.DataFrame(newstotal) df.to_excel('news.xlsx') txt = route('news.xlsx','news.txt') exc = {'','的','是','了','我','在','他','也','都','这','和','有','可以','与','就','说','一个','自己','中','对','但','而','就是','现代文','这个','很','你','不','他们','到','年','会','没有','上','把','要'} words = list(jieba.cut(txt,cut_all=True)) dic= {} keys = set(words) for i in exc: keys.remove(i) for i in keys: dic[i] = words.count(i) wc = list(dic.items()) wc.sort(key=lambda x:x[1],reverse=True) print("20个出现次数最多的词语:") for i in range(20): print(wc[i])
2.使用wordcloud库绘制一个词云
import requests from bs4 import BeautifulSoup from datetime import datetime import re import pandas import sqlite3 import jieba import openpyxl from wordcloud import WordCloud import matplotlib.pyplot as plt def getdetail(url): resd = requests.get(url) resd.encoding='utf-8' soupd = BeautifulSoup(resd.text,'html.parser') news = {} news['路径'] = url news['标题'] = soupd.select('h1')[0].text news['发布时间'] = soupd.select('.ss01')[0].text news['来源'] = soupd.select('.ss03')[0].text news['内容'] = soupd.select('.js_selection_area')[0].text return(news) def onepage(url): res = requests.get(url) res.encoding = 'utf-8' soup = BeautifulSoup(res.text,'html.parser') newsls = [] for new in soup.select('.col_L'): for news in new.select('h2'): newsls.append(getdetail(news.select('a')[0]['href'])) return(newsls) def route(file_save,file_open): wb=openpyxl.load_workbook(file_save) #打开excel文件 sheet=wb.get_sheet_by_name('Sheet1') #获取工作表 for i in range(2,sheet.max_row): txt=sheet.cell(row=i,column=2).value txt=txt.replace('\u2022',' ') txt=txt.replace('\xa0',' ') open(file_open,"a").write(txt) txt = open(file_open,'r').read() return(txt) newstotal = [] url = 'http://culture.ifeng.com/listpage/59665/1/list.shtml' newstotal.extend(onepage(url)) df = pandas.DataFrame(newstotal) df.to_excel('news.xlsx') txt = route('news.xlsx','news.txt') words = WordCloud().generate(txt) plt.imshow(words) plt.axis('off') plt.show()

