[译]JavaScript源码转换:非破坏式与再生式
很多的JavaScript工具都需要对JavaScript源码进行转换,包括压缩器(minifier)和转译器(transpiler).这些工具所使用的转换的技术可以分为两种:对源码进行非破坏式的(non-destructive)修改和从语法树完全再生(full regeneration)出新的源码.这两种技术服务于不同的需求,且往往是相辅相成的.
无论选择哪种技术,输入的源码都需要先被解析.这项任务可以交给一个解析器(比如Esprima)来做.之后,再对解析器生成的语法树进行两种不同的操作,如下图所示:
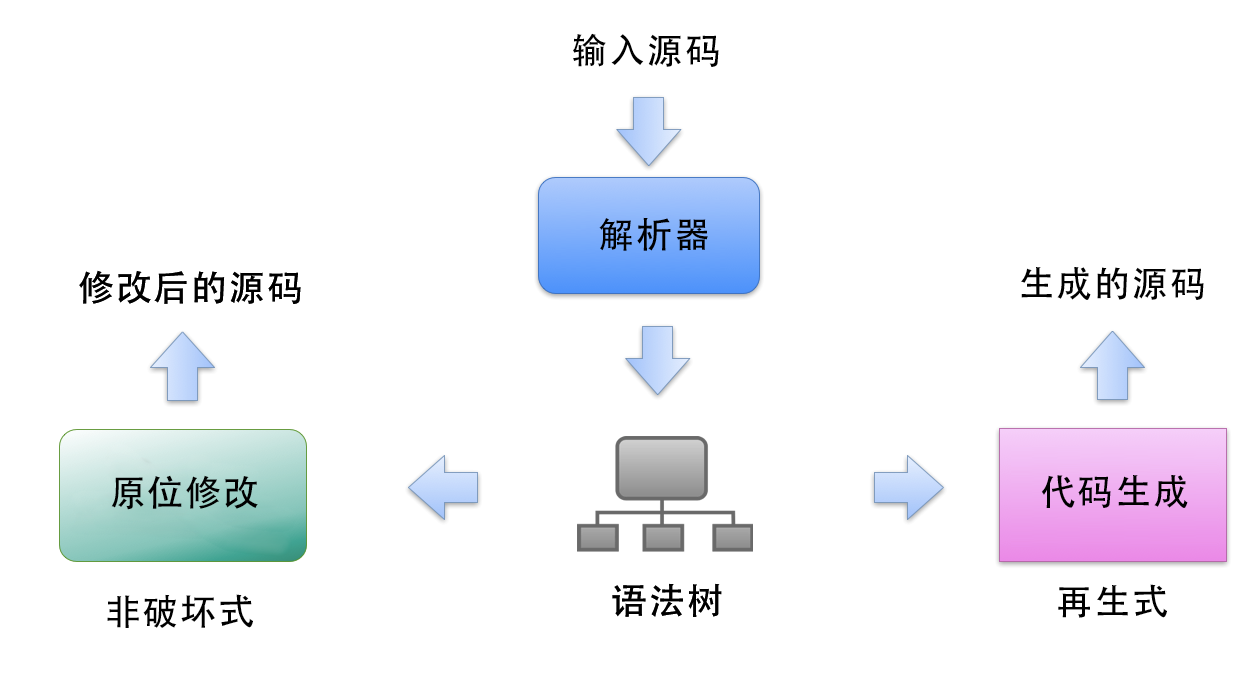
如果使用非破坏式的修改,则我们需要利用语法树中相关语法节点(syntax node)和词法单元(tokens)的位置信息来计算出应该在输入源码的哪段位置处进行修改.举个简单的例子,就是把源码中字符串两边的双引号转换成单引号(或者反或来):通过定位字符串字面量,我们就能知道引号的具体位置,从而能够对这个引号进行原位替换(in-place replacement),注意字符串本身的内容可能需要转义,因为其中可能包含引号.
完全再生的方式可以用在语法转译(syntax transpilation)的需求中.比如,如果我们现在就想使用上ECMAScript 6中的块级作用域(block scope)特性,则我们需要对自己写的代码进行转换(已经有了现成的defs.js),让输出的代码能够正确的运行在目前更通用的ECMAScript 5环境中.具体要做的就是将let声明语句转换成等效的var语句(主要考虑如何对变量的作用域进行限制).
非破坏式转换的优点是,我们不会丢失那些输入源码中与语法无关且不影响程序执行但也有必要保留的那部分代码.比如,在将双引号转换成单引号这一需求中,所有已有的缩进,注释等应当被完全保留.非破坏式转换工具只对它感兴趣的部分代码做修改,其他的所有代码都应该保持完全不变.
但如果我们想要编写的这个工具不需要保留输入源码中的注释和缩进,则完全扔掉原始代码,根据语法树生成一份新源码的方式会更简单点.比如,一个压缩器生成的源码从语义上要完全等同于输入源码,只是少了额外的空白,就应该使用完全再生的方式.另外现在大部分高级压缩器还会去做一些缩短变量名,移除无用代码的一些处理,因为这些处理能让代码变的更短.
译者注:目前比较有名的三个压缩器YUI Compressor, Closure Compiler, UglifyJS都是使用再生的方式生成源码的.不过前两者使用的解析器是Mozilla的Rhino(Java编写),后者使用的解析器是parse-js(JavaScript编写).
Esprima作为目前最好的js parser in js,怎么会没有基于Esprima的压缩器呢.于是我咨询了本文的作者,也就是Esprima的作者,他让我看看Escodegen和Esmangle.其中,Escodegen是一个代码生成器,可以把AST转换成JavaScript代码,刚好干了和解析器相反的工作,这里有一个demo.Esmangle是一个压缩器,但它和其他的压缩器不同,它的输入是解析器生成的AST,返回的是压缩过的AST,也就是说Esprima + Esmangle + Escodegen配合在一起,才能算是完整的JavaScript代码压缩器,这里有一个demo.
如果要做代码覆盖率分析,则代码插装(code instrumentation)是最重要的一步操作.一个代码覆盖率工具比如Istanbul会把它的插装代码(instrumentation code)包装在目标代码的每个语法节点上.通过这种方式,就可以跟踪到那些真正被JavaScript引擎执行过的语句和代码分支了.这样的插装器(instrumenter)也是代码再生技术的又一个用武之地.在代码插装完毕之后,新生成的代码马上就要被解释器执行了,也就没有人会去关心代码长什么样,有没有缩进等外观方面的事情了.
译者注:讲一个我自己的真实案例,情节稍有简化.就是在公司的项目中,需要在js文件中拼接mastache模板字符串,像这样
var template =
'<ul>' + '{{#list}}' +
'<li>' +
'{{value}}' +
'</li>' + '{{/list}}' +
'</ul>' +
......显然,这种写法可维护性不好.于是我想出了一种解决办法,就是利用提取函数多行注释来实现多行字符串.像这样
var template = heredoc(function(){/* <ul> {{#list}} <li> {{value}} </li> {{/list}} </ul>
...... */})两种写法下template的值应该是一样的.heredoc是一个工具函数,负责从参数函数的source里提取出多行注释作为字符串,怎么实现的我这里就不说了.
重点是,在发布的时候,这样的代码会经过UglifyJS的压缩.注释被删除,程序错误,这是可以预料到的.于是我写了一个node脚本,负责在发布的时候把所有js文件中的heredoc函数的调用转换成单行的字符串,转换之后的代码就变成了
......
var template = '<ul>{{#list}}<li>{{value}}</li>{{/list}</ul>'
......省略号代表了其他部分的代码,是不会有任何修改的.下一步再交给UglifyJS压缩,这样就没问题了.
这个node脚本是怎么写的,我正是用到了本文中所讲的非破坏式修改源码的技术,使用的解析器是Esprima.其代码比起双引号转单引号的那个例子要复杂一些,只遍历tokens数组是不够的,需要遍历整棵语法树以及comments数组.完整的代码如下
还有个浏览器中的demovar fs = require("fs"); var path = process.argv[2]; var esprima = require("esprima"); var source = fs.readFileSync(path, "utf-8"); var ast = esprima.parse(source, { //将源码解析成ast comment: true, //把所有的注释节点放到ast.comments数组内 range: true //输出所有语法节点的位置信息 }); var collectedDatas = []; JSON.stringify(ast, function (key, value) { //遍历所有的语法节点,找到heredoc的函数调用,抽取出多行注释 if (value && value.type === "CallExpression" && value.callee.name === "heredoc" && value.arguments.length === 1 && value.arguments[0].type === "FunctionExpression" && value.arguments[0].body.body.length === 0) { //找到heredoc函数调用,且参数必须是一个不包含任何语句的空函数 var heredocCallExpression = value; var blockStatementRange = heredocCallExpression.arguments[0].body.range; var blockStatementSource = source.slice(blockStatementRange[0] + 1, blockStatementRange[1] - 1); var offsetLeft = blockStatementSource.match(/^\s*/)[0].length; var offsetRight = blockStatementSource.match(/\s*$/)[0].length; var commentRange = [blockStatementRange[0] + offsetLeft + 1, blockStatementRange[1] - offsetRight - 1]; //假设这个空函数只包含一个多行注释,计算出该注释的位置信息 ast.comments.some(function (comment) { //和解析出来的comments数组做对比,如果有相同位置信息的,则说明已经正确定位到了一个约定好的多行字符串写法 if (comment.range[0] == commentRange[0] && comment.range[1] == commentRange[1]) { var commentSourceRange = [commentRange[0] + 2, commentRange[1] - 2]; var commentSource = source.slice(commentSourceRange[0], commentSourceRange[1]); var escapedCommentSource = ("'" + commentSource.replace(/(?=\\|')/g, "\\") + "'").replace(/\s*^\s*/mg, ""); collectedDatas.push({ range: heredocCallExpression.range, replaceString: escapedCommentSource }); } }); } return value; }) for (var i = collectedDatas.length - 1; i >= 0; i--) { //从后往前修改输入源码,就可以不用考虑偏移量的问题了 var range = collectedDatas[i].range; var replaceString = collectedDatas[i].replaceString; source = source.slice(0, range[0]) + replaceString + source.slice(range[1]); } fs.writeFileSync(path, source, "utf-8"); //将修改后的源码写回源文件

 浙公网安备 33010602011771号
浙公网安备 33010602011771号