
Scrapy爬虫模块
登录


import scrapy from scrapy.http import request class RenRen(scrapy.Spider): """主要测试登录""" name = 'renren' allowed_domains = ['renren.com'] start_urls = ['http://www.renren.com/PLogin.do'] custom_settings = { 'DEFAULT_REQUEST_HEADERS': { 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 'Accept-Language': 'en', 'Referer': 'http://www.renren.com/', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36', } } def start_requests(self): data = { 'email': '970138074@qq.com', 'password': 'pythonspider', } yield scrapy.FormRequest(url=self.start_urls[0],formdata=data) def parse(self, response): print(response.text)
验证码
手动输入验证码
# -*- coding: utf-8 -*- import scrapy from urllib import request from PIL import Image appcode = '0c1abee1a5fc4cbba18450eb1cf8a4cc' class DpubanSpiderSpider(scrapy.Spider): name = 'douban_spider' allowed_domains = ['douban.com'] start_urls = ['https://www.douban.com/'] def parse(self, response): img_url = response.xpath("//img[@id='captcha_image']/@src").get() captcha_id = response.xpath("//input[@name='captcha-id']/@value").get() img_name = 'captcha.png' request.urlretrieve(img_url,img_name) with open(img_name,'rb') as f: img = Image.open(f) img.show() captcha_value = input('请输入验证码:') data = { 'source': 'index_nav', 'form_email':'970138074@qq.com', 'form_password':'pythonspider', 'captcha-solution': captcha_value, 'captcha-id':captcha_id, } url = 'https://www.douban.com/accounts/login' yield scrapy.FormRequest(url=url,formdata=data,callback=self.login_index) def login_index(self,response): print(response.text)
阿里云图片验证码识别,自动登录
https://fuwu.aliyun.com/products/57126001/cmapi014396.html#sku=yuncode839600006
# -*- coding: utf-8 -*- import scrapy from urllib import request from base64 import b64encode import requests class DpubanSpiderSpider(scrapy.Spider): name = 'douban_spider_auto' allowed_domains = ['douban.com'] start_urls = ['https://www.douban.com/'] def parse(self, response): img_url = response.xpath("//img[@id='captcha_image']/@src").get() captcha_id = response.xpath("//input[@name='captcha-id']/@value").get() img_name = 'captcha.png' request.urlretrieve(img_url,img_name) with open(img_name,'rb') as f: img_content = f.read() img_content = b64encode(img_content) getcode_url = 'http://jisuyzmsb.market.alicloudapi.com/captcha/recognize?type=e' appcode = '0c1abee1a5fc4cbba18450eb1cf8a4cc' headers = { 'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8', 'Authorization': 'APPCODE ' + appcode } bodys={} bodys['pic'] = img_content result = requests.post(url=getcode_url,data=bodys,headers=headers) result = result.json() captcha_value = result['result']['code'] print(captcha_value) data = { 'source': 'index_nav', 'form_email':'970138074@qq.com', 'form_password':'pythonspider', 'captcha-solution': captcha_value, 'captcha-id':captcha_id, } url = 'https://www.douban.com/accounts/login' yield scrapy.FormRequest(url=url,formdata=data,callback=self.login_index) def login_index(self,response): print(response.text)
User-Agent池
import random class UserAgentMiddleware(object): USER_AGENTS = [ "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)", "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)", "Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)", "Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)", "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)", "Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)", "Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)", "Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)", "Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6", "Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1", "Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0", "Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5", "Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.8) Gecko Fedora/1.9.0.8-1.fc10 Kazehakase/0.5.6", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20", "Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; fr) Presto/2.9.168 Version/11.52", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/2.0 Safari/536.11", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER", "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; LBBROWSER)", "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E; LBBROWSER)", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 LBBROWSER", "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)", "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; QQBrowser/7.0.3698.400)", "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)", "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; 360SE)", "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)", "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E)", "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1", "Mozilla/5.0 (iPad; U; CPU OS 4_2_1 like Mac OS X; zh-cn) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8C148 Safari/6533.18.5", "Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:2.0b13pre) Gecko/20110307 Firefox/4.0b13pre", "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:16.0) Gecko/20100101 Firefox/16.0", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11", "Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36", ] def process_request(self, request, spider): request.headers['User-Agent'] = random.choice(self.USER_AGENTS)
代理池
从数据库获取代理
import pymysql import logging class MyProxyMiddleware(object): http_n = 0 https_n = 0 def __init__(self): self.ips = GetIp().get_ips() def process_request(self, request, spider): # Set ths locaion of the proxy if request.url.startswith("http://"): n = self.http_n n = n if n < len(self.ips['http']) else 0 request.meta['proxy'] = "http://%s:%d" % (self.ips['http'][n][0], int(self.ips['http'][n][1])) logging.info('Squence - http: %s - %s' % (n, str(self.ips['http'][n]))) self.http_n += 1 if request.url.startswith("https://"): n = self.https_n n = n if n < len(self.ips['https']) else 0 request.meta['proxy'] = "https://%s:%d" % (self.ips['https'][n][0], int(self.ips['https'][n][1])) logging.info('Squence - https: %s - %s' % (n, str(self.ips['https'][n]))) self.https_n += 1 class Singleton(object): def __new__(cls, *args, **kwargs): if not hasattr(cls,'_instance'): cls._instance = super().__new__(cls) return cls._instance class GetIp(Singleton): #获取代理结果 def __init__(self): self.connection = pymysql.connect(host='localhost', user='root', password='', db='test', charset='utf8', cursorclass=pymysql.cursors.DictCursor) with self.connection.cursor() as cursor: sql = '''select 'IP','PORT','TYPE' from 'proxy' where 'TYPE' regexp 'HTTP|HTTPS' and 'speed' <5 or 'speed' is null order by 'proxy' ,'type' asc limit 50''' cursor.execute(sql, ('111111111',)) result = cursor.fetchall() print(result) self.result = result def del_ip(self,record): '''delete ip that can not use''' with self.connection.cursor() as cursor: sql = "delete from proxy where IP='%s' and PORT='%s'" print(sql) cursor.execute(sql, (record[0], record[1])) self.connection.commit() print(record," was deleted") def jugde_ip(self,record): '''Judge IP can use or not''' http_url = "http://www.baidu.com" https_url = "https://www.alipay.com" proxy_type = record[2].lower() url = http_url if proxy_type == 'http' else https_url proxy = "%s:%s"%(record[0],record[1]) try: import urllib3 proxy = urllib3.ProxyManager(proxy,timeout=2.5) response = proxy.request('GET', url=url) except Exception as e: print("Request Error:",e) self.del_ip(record) return False else: code = response.getcode() if code >= 200 and code<300: print("Effective proxy",record) return True else: print("Invalide proxy",record) self.del_ip(record) return False def get_ips(self): print("Proxy getip was executed") http = [h[0:2] for h in self.result if h[2]=='HTTP' and self.jugde_ip(h)] https = [h[0:2] for h in self.result if h[2]=='HTTPS' and self.jugde_ip(h)] print("HTTP:",len(http),"Https:",len(https)) return {'http':http,"https":https} def __del__(self): self.connection.close() # def counter(start_at=0): # """Function:counter number # Usage: f=counter(i) print(f()) #i+1""" # count = [start_at] # def incr(): # count[0] += 1 # return count[0] # return incr() # def use_proxy(browser,proxy,url): # """Open browser with proxy""" # #After visited transfer ip # profile = browser.profile # profile.set_preference('network.proxy.type',1) # profile.set_preference('network.proxy.http',proxy[0]) # profile.set_preference('network.proxy.http_port',int(proxy[1])) # profile.set_preference('permissions.default.image',2) # profile.update_preferences() # browser.profile = profile # browser.get(url) # browser.implicitly_wait(30) # return browser
动态代理
1、使用ProxyPool框架
链接:https://github.com/Python3WebSpider/ProxyPool#%E8%8E%B7%E5%8F%96%E4%BB%A3%E7%90%86
2、在下载中间件中使用代理
import requests class ProxyMiddleware(object): def process_request(self, request, spider): res = requests.get('http://127.0.0.1:5555/random') print(res.text) request.meta['proxy']= 'http://'+res.text
更改请求头、查看请求头
class ZhihuSpiderSpider(scrapy.Spider): name = 'zhihu_spider' allowed_domains = ['zhihu.com'] start_urls = ['https://httpbin.org/get'] custom_settings = { 'USER_AGENT': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)', }
注意:这里的用户代理键是USER_AGENT(和Settings文件中一致),而不是User-Agent
import scrapy class ScrapySpider(scrapy.Spider): name = "scrapy_spider" allowed_domains = ["httpbin.org"] start_urls = ( # 请求的链接 "https://httpbin.org/get?show_env=1", ) def parse(self, response): # 打印出相应结果 print response.text if __name__ == '__main__': from scrapy import cmdline cmdline.execute("scrapy crawl scrapy_spider".split())
python中HTML文档转义与反转义方法介绍
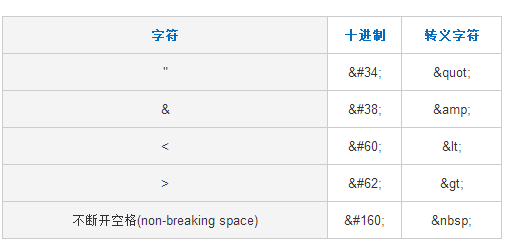
import html str1 = html.escape("<div></div>") str2 = html.unescape(str1) print(str1) #<div></div> print(str2) #<div></div>
字典数据格式化输出
print(json.dumps(data, sort_keys=False, indent=2,ensure_ascii=False))
保存数据到mongo
import pymongo class MongoPipeline(object): '''数据存储(MongoDB)''' def __init__(self, mongo_uri, mongo_db): self.mongo_uri = mongo_uri self.mongo_db = mongo_db @classmethod def from_crawler(cls, crawler): return cls( mongo_uri=crawler.settings.get('MONGO_URI'), mongo_db=crawler.settings.get('MONGO_DATABASE') ) def open_spider(self, spider): self.client = pymongo.MongoClient(self.mongo_uri) self.db = self.client[self.mongo_db] def close_spider(self, spider): self.client.close() def process_item(self, item, spider): #如果不存在update的记录,则插入 self.db['zhihu_user'].update({'name':item['name']},{'$set':item},upsert=True) return item #settings文件 #MONGO_URI = 'mongodb://localhost:27017' #MONGO_DATABASE = 'zhihu'
CrawlSpider-LinkExtractor
def parse(self,response): link = LinkExtractor(restrict_xpaths='//ul[@class="note-list"]/li') links = link.extract_links(response) if links: for link_one in links: print(link_one)
from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider, Rule class GirlSpider(CrawlSpider): name = 'girl' allowed_domains = ['win4000.com'] start_urls = ['http://www.win4000.com/wallpaper_2285_0_10_1.html'] rules = ( Rule(LinkExtractor(allow=r'wallpaper_2285_0_10_\d+.html',restrict_xpaths="//div[@class='pages']"), follow=True), Rule(LinkExtractor(allow=r'http://www.win4000.com/wallpaper_detail_\d+(_\d+|).html', restrict_xpaths=["//div[@class='scroll-img-cont']/ul/li","//div[@class='tab_box']"]), callback='parse_detail', follow=True), ) def parse_detail(self, response): url = response.xpath("//div[@class='pic_main']//div[@class='pic-meinv']/a/img/@src").extract_first() image_urls = [url] yield {'image_urls': image_urls}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号