
Hive入门
docker环境搭建:https://gitee.com/laughstorm/docker-centos-hadoop
视频教程:https://edu.aliyun.com/course/1531
文档:https://cwiki.apache.org/confluence/display/Hive/GettingStarted
面试总结:https://zhuanlan.zhihu.com/p/75550159
推荐博客
https://www.cnblogs.com/huifeidezhuzai/p/9251969.html
Hive简介
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。Hive是一个数据仓库基础工具在Hadoop中用来处理结构化数据。它架构在Hadoop之上,总归为大数据,并使得查询和分析方便。
在Hive中,Hive是SQL解析引擎,它将SQL语句转译成M/R Job然后在Hadoop执行。Hive的表其实就是HDFS的目录/文件,按表名把文件夹分开。如果是分区表,则分区值是子文件夹,可以直接在M/RJob里使用这些数据。
最初,Hive是由Facebook开发,后来由Apache软件基金会开发,并作为进一步将它作为名义下ApacheHive为一个开源项目。它用在好多不同的公司。例如,亚马逊使用它在Amazon Elastic、MapReduce。
Hive体系结构
以下组件图描述了Hive的体系结构:
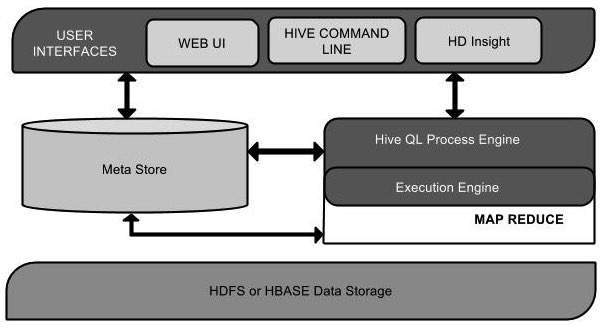
该组件图包含不同的单位。下表描述了每个单元:
| 单元名称 | 操作 |
|---|---|
| 用户界面 | Hive是一个数据仓库基础设施软件,可以创建用户和HDFS之间的交互。Hive支持的用户界面是Hive Web UI,Hive命令行和Hive HD Insight(在Windows服务器中)。 |
| Meta Store | Hive选择相应的数据库服务器来存储表,数据库,列的架构或元数据,表格,数据类型和HDFS映射。 |
| HiveQL流程引擎 | HiveQL与用于查询Metastore上的模式信息的SQL类似。它是MapReduce程序的传统方法的替代之一。我们可以编写MapReduce作业查询并处理它,而不用Java编写MapReduce程序。 |
| 执行引擎 | HiveQL进程引擎和MapReduce的结合部分是Hive执行引擎。执行引擎处理查询并生成与MapReduce结果相同的结果。它使用MapReduce的风格。 |
| HDFS或HBASE | Hadoop分布式文件系统或HBASE是将数据存储到文件系统的数据存储技术。 |
Hive的metastore组件
Hive的metastore组件是hive元数据集中存放地。Metastore组件包括两个部分:metastore服务和后台数据的存储。后台数据存储的介质就是关系数据库,例如hive默认的嵌入式磁盘数据库derby,还有mysql数据库。Metastore服务是建立在后台数据存储介质之上,并且可以和hive服务进行交互的服务组件,默认情况下,metastore服务和hive服务是安装在一起的,运行在同一个进程当中。我也可以把metastore服务从hive服务里剥离出来,metastore独立安装在一个集群里,hive远程调用metastore服务,这样我们可以把元数据这一层放到防火墙之后,客户端访问hive服务,就可以连接到元数据这一层,从而提供了更好的管理性和安全保障。使用远程的metastore服务,可以让metastore服务和hive服务运行在不同的进程里,这样也保证了hive的稳定性,提升了hive服务的效率。
连接到数据库的模式:
有三种模式可以连接到数据库:
-
单用户模式。此模式连接到一个In-memory 的数据库Derby,一般用于Unit Test。
-
多用户模式。通过网络连接到一个数据库中,是最经常使用到的模式。
-
远程服务器模式。用于非Java客户端访问元数据库,在服务器端启动MetaStoreServer,客户端利用Thrift协议通过MetaStoreServer访问元数据库。
Hive的工作
下图描述了Hive和Hadoop之间的工作流程。
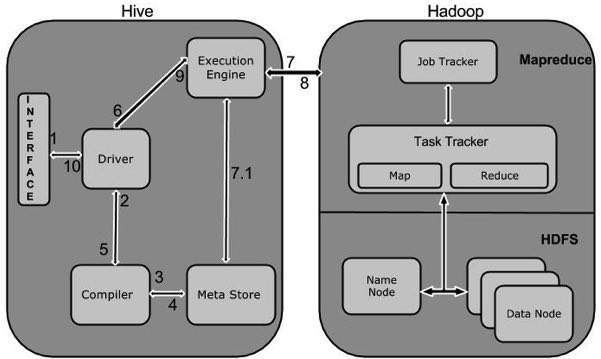
下表定义了Hive如何与Hadoop框架交互:
| 步骤号 | 操作 |
|---|---|
| 1 | **执行查询** Hive接口(如命令行或Web UI)向Driver(任何数据库驱动程序,如JDBC,ODBC等)发送查询以执行。 |
| 2 | **获取计划** 驱动程序在查询编译器的帮助下解析查询以检查语法和查询计划或查询的要求。 |
| 3 | **获取元数据** 编译器将元数据请求发送到Metastore(任何数据库)。 |
| 4 | **发送元数据** Metastore将元数据作为响应发送给编译器。 |
| 5 | **发送计划** 编译器检查需求并将计划重新发送给驱动程序。到此为止,查询的解析和编译已完成。 |
| 6 | **执行计划** 驱动程序将执行计划发送给执行引擎。 |
| 7 | **执行作业** 在内部,执行作业的过程是一个MapReduce作业。执行引擎将作业发送到名称节点中的JobTracker,并将该作业分配给数据节点中的TaskTracker。在这里,查询执行MapReduce作业。 |
| 7.1 | **元数据操作** 同时在执行时,执行引擎可以使用Metastore执行元数据操作。 |
| 8 | **取结果** 执行引擎从Data节点接收结果。 |
| 9 | **发送结果** 执行引擎将这些结果值发送给驱动程序。 |
| 10 | **发送结果** 驱动程序将结果发送给Hive Interfaces。 |
部署
配置环境变量
export JAVA_HOME=/usr/local/software/jdk1.8.0_66 export HADOOP_HOME=/usr/local/software/hadoop_2.7.1 export HBASE_HOME=/usr/local/software/hbase_1.2.2 export HIVE_HOME=/usr/local/software/apache-hive-2.3.0-bin export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar export PATH=.:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HBASE_HOME/bin:$HIVE_HOME/bin:$PATH
配置hive-env.sh
cd apache-hive-1.2.1-bin/conf cp hive-env.sh.template hive-env.sh vim hive-env.sh
添加hadoop的路径,如下:HADOOP_HOME=/usr/local/hadoop/hadoop-2.9.2
(以下所有配置均在该路径下。)
在HDFS中创建目录和设置权限
启动hadoop,在hadoop中创建hive需要用到的目录并设置权限。
hadoop fs -mkdir -p /user/hive/warehouse # hadoop fs -mkdir -p /user/hive/tmp # hadoop fs -mkdir -p /user/hive/log # hadoop fs -chmod -R 777 /user/hive/warehouse # hadoop fs -chmod g+w /user/hive/warehouse # hadoop fs -chmod -R 777 /user/hive/tmp # hadoop fs -chmod -R 777 /user/hive/log mkdir -p /opt/module/apache-hive-2.3.7-bin/tmp mkdir -p /opt/module/apache-hive-2.3.7-bin/log/hadoop
配置hive-site.xml
cp hive-default.xml.template hive-site.xml vi hive-site.xml
配置详情
<configuration>
<!--Hive的元数据库,这是连接master.hadoop:3306端口的hive数据库,如果库不存在就可以创建-->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://master:3306/hive?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<!--连接元数据的驱动名-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<!--数据库的用户名-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
<description>username to use against metastore database</description>
</property>
<!--数据库的密码-->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive</value>
<description>password to use against metastore database</description>
</property>
<!--表示数据在hdfs中的存储位置-->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>hdfs://mycluster/user/hive/warehouse</value>
</property>
<!--动态分区的模式,默认strict,表示必须指定至少一个分区为静态分区,nonstrict模式表示允许所有的分区字段都可以使用动态分区。-->
<property>
<name>hive.exec.dynamic.partition.mode</name>
<value>nonstrict</value>
</property>
<!--默认情况下,HiveServer2以提交查询的用户执行查询(true),如果hive.server2.enable.doAs设置为false,查询将以运行hiveserver2进程的用户运行。-->
<property>
<name>hive.server2.enable.doAs</name>
<value>false</value>
</property>
<!-- hive.metastore.schema.verification值为false即可解决“Caused by: MetaException(message:Version information not found in metastore.)”-->
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<!--/user/hive/tmp(hadoop目录)不好使,后改为: -->
<property>
<name>hive.exec.scratchdir</name>
<value>/opt/module/apache-hive-2.3.7-bin/tmp</value>
</property>
<!--/user/hive/tmp(hadoop目录)不好使,后改为: -->
<property>
<name>hive.downloaded.resources.dir</name>
<value>/opt/module/apache-hive-2.3.7-bin/tmp</value>
<description>Temporary local directory for added resources in the remote file system.</description>
</property>
<!--/user/hive/log/hadoop(hadoop目录)不好使,后改为: -->
<property>
<name>hive.querylog.location</name>
<value>/opt/module/apache-hive-2.3.7-bin/log/hadoop</value>
<description>Location of Hive run time structured logfile</description>
</property>
</configuration>
修改hive-config.sh
进入目录:/usr/local/hive/apache-hive-1.2.2-bin/bin
sudo vi hive-config.sh
在该文件的最前面添加以下内容:
export JAVA_HOME=/usr/local/java/jdk1.8.0_191 export HADOOP_HOME=/usr/local/hadoop/hadoop-2.9.2 export HIVE_HOME=/usr/local/hive/apache-hive-1.2.2-bin
配置mysql
安装MySQL Server
sudo apt-get install mysql-server
Mysql配置 /etc/my.cnf
[mysqld] skip-name-resolve #参数的目的是不再进行反解析(ip不反解成域名),这样可以加快数据库的反应时间。 sql_mode=NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES #默认用的是严格模式,mysql 5.6默认用innodb ,所以用STRICT_TRANS_TABLES也容易理解。用了这个选项的话, 那么数据库中如果是非空值的话就得设置默认值了,否则是报错的
MariaDB [(none)]> create database hive; MariaDB [(none)]> grant all privileges on hive.* to hive@"192.168.14.%" identified by 'hive'; #如果hive服务端不在本机要设置这么一条 MariaDB [(none)]> grant all privileges on hive.* to hive@localhost identified by 'hive'; MariaDB [(none)]> flush privileges; MariaDB [(none)]> exit
验证
mysql -uhive -phive -h localhost -e "show databases";
下载MySQL JDBC驱动器
去mysql官网找GA version下载
wget https://cdn.mysql.com//Downloads/Connector-J/mysql-connector-java-5.1.49.tar.gz # wget https://dev.mysql.com/get/Downloads/Connector-J/mysql-connector-java-5.1.47.tar.gz tar -zxvf mysql-connector-java-5.1.47.tar.gz cp mysql-connector-java-5.1.40-bin.jar apache-hive-1.2.2-bin/lib
初始化meta数据库
初始化Hive元数据对应的MySQL数据库:
./apache-hive-2.3.7-bin/bin/schematool -initSchema -dbType mysql
验证是否产生Hive元数据
mysql -uroot -p123456 -e "use hive;show tables;" #查看一下hive库里面产生了一堆元数据相关的表
启动Hive
启动hive前,确保hadoop集群启动
$ start-all.sh $ hive
进入hive shell测试
apache-hive/bin/hive
Hive服务端的启动
推荐
bin/hiveserver2 nohup bin/hiveserver2 1>/var/log/hiveserver.log 2>/var/log/hiveserver.err &
其他
hive --service metastore & #要启动metastore服务 apache-hive/bin/hive --service metastore >/home/hadoop/apache-hive/hive_metastore.log 2>&1 #当然更好的方式是指定日志后台启动
17420 RunJar #多了一个进程
端口号验证
netstat -lntup|grep 9083 #默认启动的是9083端口
Hive客户端的测试
方式一Beeline:
#HiveServer2客户端(beeline):https://cwiki.apache.org/confluence/display/Hive/HiveServer2+Clients#HiveServer2Clients-Beeline–NewCommandLineShell
工作模式:
- 本地嵌入模式:它返回一个嵌入式的Hive(类似于Hive CLI)
- 远程模式:通过Thrift协议与某个单独的HiveServer2进程进行连接通信。
服务端启动服务(启动ThifServer):
$ /home/hadoop/apache-hive/bin/hive --service hiveserver2 10000>/dev/null 2>/dev/null & $ netstat -lntup|grep 10000
#正常的hive仅允许使用HiveQL执行查询、更新等操作,并且该方式比较笨拙单一。幸好Hive提供了轻客户端的实现,通过HiveServer或者HiveServer2,客户端可以在不启动CLI的情况下对Hive中的数据进行操作,
两者都允许远程客户端使用多种编程语言如Java、Python向Hive提交请求,取回结果 使用jdbc协议连接hive的thriftserver服务器.
bin/beeline -u jdbc:hive2://mimi1:10000 -n root 或 bin/beeline ! connect jdbc:hive2://mimi1:10000
方式二:
发送到一个datanode客户端
scp -r /home/hadoop/apache-hive-1.2.2-bin 192.168.14.52:/home/hadoop/
修改客户端配置文件apache-hive-1.2.2-bin/conf/hive-site.xml
<configuration>
<property>
<name>hive.metastore.uris</name>
<value>thrift://master.hadoop:9083</value>
</property>
</configuration>
客户端测试访问
apache-hive-1.2.2-bin/bin/hive
Hql基本语法
Hive官网(HQL)语法手册(英文版):https://cwiki.apache.org/confluence/display/Hive/LanguageManual
Hive的数据存储
1、Hive中所有的数据都存储在 HDFS 中,没有专门的数据存储格式(可支持Text,SequenceFile,ParquetFile,RCFILE等)
2、只需要在创建表的时候告诉 Hive 数据中的列分隔符和行分隔符,Hive 就可以解析数据。
3、Hive 中包含以下数据模型:DB、Table,External Table,Partition,Bucket。
(1):db:在hdfs中表现为${hive.metastore.warehouse.dir}目录下一个文件夹
(2):table:在hdfs中表现所属db目录下一个文件夹
(3):external table:外部表, 与table类似,不过其数据存放位置可以在任意指定路径
普通表: 删除表后, hdfs上的文件都删了
External外部表删除后, hdfs上的文件没有删除, 只是把文件删除了
(4):partition:在hdfs中表现为table目录下的子目录
(5):bucket:桶, 在hdfs中表现为同一个表目录下根据hash散列之后的多个文件, 会根据不同的文件把数据放到不同的文件中
数据库操作
创建数据库语法格式:
CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name
[COMMENT database_comment] //关于数据块的描述
[LOCATION hdfs_path] //指定数据库在HDFS上的存储位置
[WITH DBPROPERTIES (property_name=property_value, ...)]; //指定数据块属性
举例
create database if not exists t1 comment 'learning hive' with dbproperties('creator'='hadoop','date'='2018-04-05');
显示所有数据库
show databases;
显示数据库的详细属性信息
describe DATABASE|SCHEMA [extended] database_name。
删除数据库
语法格式
DROP DATABASE|SHCEMA [IF EXISTS] database_Name [RESTRICT|CASCADE]
默认情况下,hive 不允许删除包含表的数据库,有两种解决办法:
1、 手动删除库下所有表,然后删除库
2、 使用 cascade 关键字
drop database if exists t3 cascade;
切换数据库
user database_name;
查看正在使用哪个库
select current_database();
查看创建库的详细语句
show create database t1;
数据库表操作
创建表语法结构
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
详情请参见: https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL#LanguageManualD DL-CreateTable
最佳实践:
如果一份数据已经存储在HDFS上,并且要被多个用户或者客户端使用,最好创建外部表
反之,最好创建内部表。
内部表模版
CREATE TABLE page_view( viewTime INT, userid BIGINT, page_url STRING, referrer_url STRING, ip STRING COMMENT 'IP Address of the User') COMMENT 'This is the page view table' PARTITIONED BY(dt STRING, country STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\001' COLLECTION ITEMS TERMINATED BY '\002' MAP KEYS TERMINATED BY '\003' STORED AS TEXTFILE;
外部表模版
CREATE EXTERNAL TABLE page_view_ext( viewTime INT, userid BIGINT, page_url STRING, referrer_url STRING, ip STRING COMMENT 'IP Address of the User', country STRING COMMENT 'country of origination') COMMENT 'This is the staging page view table' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\054' STORED AS TEXTFILE LOCATION '/user/hadoop/warehouse/page_view';
内外部表转化
alter table table_name set TBLPROPROTIES ('EXTERNAL'='TRUE'); # 内部表转外部表 alter table table_name set TBLPROPROTIES ('EXTERNAL'='FALSE');# 外部表转内部表
分区表
0: jdbc:hive2://hadoop3:10000> create external table student_ptn(id int, name string, sex string, age int,department string) . . . . . . . . . . . . . . .> partitioned by (city string) . . . . . . . . . . . . . . .> row format delimited fields terminated by "," . . . . . . . . . . . . . . .> location "/hive/student_ptn"; No rows affected (0.24 seconds) 0: jdbc:hive2://hadoop3:10000>
添加分区
alter table student_ptn add partition(city="beijing"); alter table student_ptn add partition(city="shenzhen");
如果某张表是分区表。那么每个分区的定义,其实就表现为了这张表的数据存储目录下的一个子目录
如果是分区表。那么数据文件一定要存储在某个分区中,而不能直接存储在表中。
分桶表
0: jdbc:hive2://hadoop3:10000> create external table student_bck(id int, name string, sex string, age int,department string) . . . . . . . . . . . . . . .> clustered by (id) sorted by (id asc, name desc) into 4 buckets . . . . . . . . . . . . . . .> row format delimited fields terminated by "," . . . . . . . . . . . . . . .> location "/hive/student_bck"; No rows affected (0.216 seconds) 0: jdbc:hive2://hadoop3:10000>
使用CTAS创建表
作用: 就是从一个查询SQL的结果来创建一个表进行存储
先向student表中导入数据
0: jdbc:hive2://hadoop3:10000> load data local inpath "/home/hadoop/student.txt" into table student; No rows affected (0.715 seconds) 0: jdbc:hive2://hadoop3:10000> select * from student; +-------------+---------------+--------------+--------------+---------------------+ | student.id | student.name | student.sex | student.age | student.department | +-------------+---------------+--------------+--------------+---------------------+ | 95002 | 刘晨 | 女 | 19 | IS | | 95017 | 王风娟 | 女 | 18 | IS | | 95018 | 王一 | 女 | 19 | IS | | 95013 | 冯伟 | 男 | 21 | CS | | 95014 | 王小丽 | 女 | 19 | CS | | 95019 | 邢小丽 | 女 | 19 | IS | | 95020 | 赵钱 | 男 | 21 | IS | | 95003 | 王敏 | 女 | 22 | MA | | 95004 | 张立 | 男 | 19 | IS | | 95012 | 孙花 | 女 | 20 | CS | | 95010 | 孔小涛 | 男 | 19 | CS | | 95005 | 刘刚 | 男 | 18 | MA | | 95006 | 孙庆 | 男 | 23 | CS | | 95007 | 易思玲 | 女 | 19 | MA | | 95008 | 李娜 | 女 | 18 | CS | | 95021 | 周二 | 男 | 17 | MA | | 95022 | 郑明 | 男 | 20 | MA | | 95001 | 李勇 | 男 | 20 | CS | | 95011 | 包小柏 | 男 | 18 | MA | | 95009 | 梦圆圆 | 女 | 18 | MA | | 95015 | 王君 | 男 | 18 | MA | +-------------+---------------+--------------+--------------+---------------------+ 21 rows selected (0.342 seconds) 0: jdbc:hive2://hadoop3:10000>
使用CTAS创建表
0: jdbc:hive2://hadoop3:10000> create table student_ctas as select * from student where id < 95012; WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases. No rows affected (34.514 seconds) 0: jdbc:hive2://hadoop3:10000> select * from student_ctas . . . . . . . . . . . . . . .> ; +------------------+--------------------+-------------------+-------------------+--------------------------+ | student_ctas.id | student_ctas.name | student_ctas.sex | student_ctas.age | student_ctas.department | +------------------+--------------------+-------------------+-------------------+--------------------------+ | 95002 | 刘晨 | 女 | 19 | IS | | 95003 | 王敏 | 女 | 22 | MA | | 95004 | 张立 | 男 | 19 | IS | | 95010 | 孔小涛 | 男 | 19 | CS | | 95005 | 刘刚 | 男 | 18 | MA | | 95006 | 孙庆 | 男 | 23 | CS | | 95007 | 易思玲 | 女 | 19 | MA | | 95008 | 李娜 | 女 | 18 | CS | | 95001 | 李勇 | 男 | 20 | CS | | 95011 | 包小柏 | 男 | 18 | MA | | 95009 | 梦圆圆 | 女 | 18 | MA | +------------------+--------------------+-------------------+-------------------+--------------------------+ 11 rows selected (0.445 seconds) 0: jdbc:hive2://hadoop3:10000>
(6)复制表结构
create table student_copy like student;
2、查看表
查看表列表
查看数据库中所有表
show tables;
查看非当前使用的数据库中有哪些表
show tables in myhive;
查看数据库中以xxx开头的表
show tables like 'student_c*';
查看表的信息
desc student;
查看表的详细信息(格式不友好)
desc extended student;
查看表的详细信息(格式友好)
desc formatted student;
查看分区信息
show partitions student_ptn;
查看表的详细建表语句
show create table student_ptn;
3、修改表
修改表名
alter table student rename to new_student;
修改字段定义
A. 增加一个字段
alter table new_student add columns (score int);
B. 修改一个字段的定义
alter table new_student change name new_name string;
C. 删除一个字段
不支持
D. 替换所有字段
alter table new_student replace columns (id int, name string, address string);
修改分区信息
A. 添加分区
静态分区
添加一个
alter table student_ptn add partition(city="chongqing");
添加多个
alter table student_ptn add partition(city="chongqing2") partition(city="chongqing3") partition(city="chongqing4");
动态分区
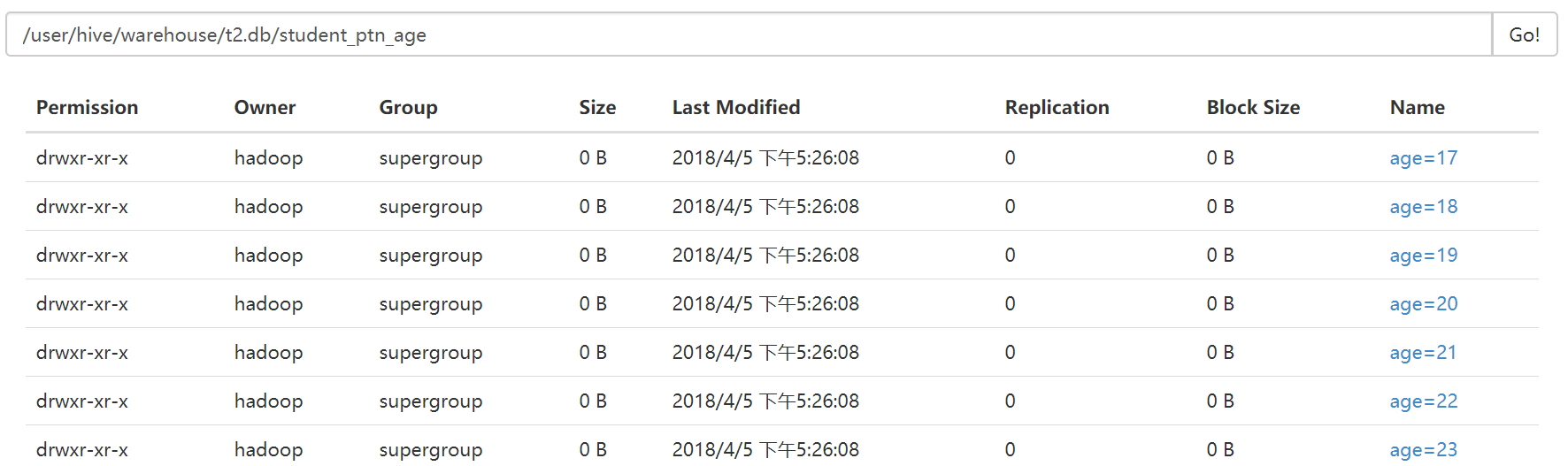
先向student_ptn表中插入数据,数据格式如下图
load data local inpath "/home/hadoop/student.txt" into table student_ptn partition(city="beijing");
现在我把这张表的内容直接插入到另一张表student_ptn_age中,并实现sex为动态分区(不指定到底是哪中性别,让系统自己分配决定)
首先创建student_ptn_age并指定分区为age
0: jdbc:hive2://hadoop3:10000> create table student_ptn_age(id int,name string,sex string,department string) partitioned by (age int);
从student_ptn表中查询数据并插入student_ptn_age表中
0: jdbc:hive2://hadoop3:10000> insert overwrite table student_ptn_age partition(age) . . . . . . . . . . . . . . .> select id,name,sex,department,age from student_ptn; WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases. No rows affected (27.905 seconds) 0: jdbc:hive2://hadoop3:10000>
B. 修改分区
修改分区,一般来说,都是指修改分区的数据存储目录
在添加分区的时候,直接指定当前分区的数据存储目录
0: jdbc:hive2://hadoop3:10000> alter table student_ptn add if not exists partition(city='beijing') . . . . . . . . . . . . . . .> location '/student_ptn_beijing' partition(city='cc') location '/student_cc'; No rows affected (0.306 seconds) 0: jdbc:hive2://hadoop3:10000>
修改已经指定好的分区的数据存储目录
0: jdbc:hive2://hadoop3:10000> alter table student_ptn partition (city='beijing') set location '/student_ptn_beijing';
此时原先的分区文件夹仍存在,但是在往分区添加数据时,只会添加到新的分区目录
删除分区
alter table student_ptn drop partition (city='beijing');
删除表
drop table new_student;
清空表
truncate table student_ptn;
其他辅助命令

复合数据类型
# array create table person(name string,work_locations array<string>) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' COLLECTION ITEMS TERMINATED BY ','; # 数据 biansutao beijing,shanghai,tianjin,hangzhou linan changchu,chengdu,wuhan # 入库数据 LOAD DATA LOCAL INPATH '/home/hadoop/person.txt' OVERWRITE INTO TABLE person; select * from person; # biansutao ["beijing","shanghai","tianjin","hangzhou"] # linan ["changchu","chengdu","wuhan"] # map create table score(name string, score map<string,int>) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' COLLECTION ITEMS TERMINATED BY ',' MAP KEYS TERMINATED BY ':'; # 数据 biansutao '数学':80,'语文':89,'英语':95 jobs '语文':60,'数学':80,'英语':99 # 入库数据 LOAD DATA LOCAL INPATH '/home/hadoop/score.txt' OVERWRITE INTO TABLE score; select * from score; # biansutao {"数学":80,"语文":89,"英语":95} # jobs {"语文":60,"数学":80,"英语":99} # struct CREATE TABLE test(id int,course struct<course:string,score:int>) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' COLLECTION ITEMS TERMINATED BY ','; # 数据 1 english,80 2 math,89 3 chinese,95 # 入库 LOAD DATA LOCAL INPATH '/home/hadoop/test.txt' OVERWRITE INTO TABLE test; # 查询 select * from test; # 1 {"course":"english","score":80} # 2 {"course":"math","score":89} # 3 {"course":"chinese","score":95}
配置优化
# 开启任务并行执行 set hive.exec.parallel=true # 设置运行内存 set mapreduce.map.memory.mb=1024; set mapreduce.reduce.memory.mb=1024; # 指定队列 set mapreduce.job.queuename=jppkg_high; # 动态分区,为了防止一个reduce处理写入一个分区导致速度严重降低,下面需设置为false # 默认为true set hive.optimize.sort.dynamic.partition=false; # 设置变量 set hivevar:factor_timedecay=-0.3; set hivevar:pre_month=${zdt.addDay(-30).format("yyyy-MM-dd")}; set hivevar:pre_date=${zdt.addDay(-1).format("yyyy-MM-dd")}; set hivevar:cur_date=${zdt.format("yyyy-MM-dd")}; # 添加第三方jar包, 添加临时函数 add jar ***.jar; # 压缩输出,ORC默认自带压缩,不需要额外指定,如果使用非ORCFile,则设置如下 hive.exec.compress.output=true # 如果一个大文件可以拆分,为防止一个Map读取过大的数据,拖慢整体流程,需设置 hive.hadoop.suports.splittable.combineinputformat # 避免因数据倾斜造成的计算效率,默认false hive.groupby.skewindata # 避免因join引起的数据倾斜 hive.optimize.skewjoin # map中会做部分聚集操作,效率高,但需要更多内存 hive.map.aggr -- 默认打开 hive.groupby.mapaggr.checkinterval -- 在Map端进行聚合操作的条目数目 # 当多个group by语句有相同的分组列,则会优化为一个MR任务。默认关闭。 hive.multigroupby.singlemr # 自动使用索引,默认不开启,需配合row group index,可以提高计算速度 hive.optimize.index.filter
常用函数
# if 函数,如果满足条件,则返回A, 否则返回B if (boolean condition, T A, T B) # case 条件判断函数, 当a为b时则返回c;当a为d时,返回e;否则返回f case a when b then c when d then e else f end # 将字符串类型的数据读取为json类型,并得到其中的元素key的值 # 第一个参数填写json对象变量,第二个参数使用$表示json变量标识,然后用.读取对象或数组; get_json_object(string s, '$.key') # url解析 # parse_url('http://facebook.com/path/p1.php?query=1','HOST')返回'facebook.com' # parse_url('http://facebook.com/path/p1.php?query=1','PATH')返回'/path/p1.php' # parse_url('http://facebook.com/path/p1.php?query=1','QUERY')返回'query=1', parse_url() # explode就是将hive一行中复杂的array或者map结构拆分成多行 explode(colname) # lateral view 将一行数据adid_list拆分为多行adid后,使用lateral view使之成为一个虚表adTable,使得每行的数据adid与之前的pageid一一对应, 因此最后pageAds表结构已发生改变,增加了一列adid select pageid, adid from pageAds lateral view explode(adid_list) adTable as adid # 去除两边空格 trim() # 大小写转换 lower(), upper() # 返回列表中第一个非空元素,如果所有值都为空,则返回null coalesce(v1, v2, v3, ...) # 返回当前时间 from_unixtime(unix_timestamp(), 'yyyy-MM-dd HH:mm:ss') # 返回第二个参数在待查找字符串中的位置(找不到返回0) instr(string str, string search_str) # 字符串连接 concat(string A, string B, string C, ...) # 自定义分隔符sep的字符串连接 concat_ws(string sep, string A, string B, string C, ...) # 返回字符串长度 length() # 反转字符串 reverse() # 字符串截取 substring(string A, int start, int len) # 将字符串A中的符合java正则表达式pat的部分替换为C; regexp_replace(string A, string pat, string C) # 将字符串subject按照pattern正则表达式的规则进行拆分,返回index制定的字符 # 0:显示与之匹配的整个字符串, 1:显示第一个括号里的, 2:显示第二个括号里的 regexp_extract(string subject, string pattern, int index) # 按照pat字符串分割str,返回分割后的字符串数组 split(string str, string pat) # 类型转换 cast(expr as type) # 将字符串转为map, item_pat指定item之间的间隔符号,dict_pat指定键与值之间的间隔 str_to_map(string A, string item_pat, string dict_pat) # 提取出map的key, 返回key的array map_keys(map m) # 日期函数 # 日期比较函数,返回相差天数,datediff('${cur_date},d) datediff(date1, date2)
实际使用
# 增加分区 insert overwrite table table_name partition (d='${pre_date}') # 建表语句 # 进行分区,每个分区相当于是一个文件夹,如果是双分区,则第二个分区作为第一个分区的子文件夹 drop table if exists employees; create table if not exists employees( name string, salary float, subordinate array<string>, deductions map<string,float>, address struct<street:string,city:string,num:int> ) partitioned by (date_time string, type string) row format delimited fields terminated by '\t' collection items terminated by ',' map keys terminated by ':' lines terminated by '\n' stored as textfile location '/hive/...'; # hive桶 # 分区是粗粒度的,桶是细粒度的 # hive针对某一列进行分桶,对列值哈希,然后除以桶的个数求余的方式决定该条记录存放在哪个桶中 create table bucketed_user(id int, name string) clustered by (id) sorted by (name) into 4 buckets row format delimited fields terminated by '\t' stored as textfile; # 注意,使用桶表的时候我们要开启桶表 set hive.enforce.bucketing=true; # 将employee表中的name和salary查询出来插入到表中 insert overwrite table bucketed_user select salary, name from employees 如果字段类型是string,则通过get_json_object提取数据; 如果字段类型是struct或map,则通过col['xx']方式提取数据;
问题汇总
运行项目连接Mysql时出现警告Establishing SSL connection without server's identity verification is not recommende
原文详情:https://blog.csdn.net/qq_41785135/article/details/85118329
jdbk:mysql://localhost:3306/testdb?characterEncoding=utf-8&useSSL=false
附录:
Hive SQL之数据类型和存储格式
一、数据类型
1、基本数据类型
Hive 支持关系型数据中大多数基本数据类型
| 类型 | 描述 | 示例 |
|---|---|---|
| boolean | true/false | TRUE |
| tinyint | 1字节的有符号整数 | -128~127 1Y |
| smallint | 2个字节的有符号整数,-32768~32767 | 1S |
| int | 4个字节的带符号整数 | 1 |
| bigint | 8字节带符号整数 | 1L |
| float | 4字节单精度浮点数 | 1.0 |
| double | 8字节双精度浮点数 | 1.0 |
| deicimal | 任意精度的带符号小数 | 1.0 |
| String | 字符串,变长 | “a”,’b’ |
| varchar | 变长字符串 | “a”,’b’ |
| char | 固定长度字符串 | “a”,’b’ |
| binary | 字节数组 | 无法表示 |
| timestamp | 时间戳,纳秒精度 | 122327493795 |
| date | 日期 | ‘2018-04-07’ |
和其他的SQL语言一样,这些都是保留字。需要注意的是所有的这些数据类型都是对Java中接口的实现,因此这些类型的具体行为细节和Java中对应的类型是完全一致的。例如,string类型实现的是Java中的String,float实现的是Java中的float,等等。
2、复杂类型
| 类型 | 描述 | 示例 |
|---|---|---|
| array | 有序的的同类型的集合 | array(1,2) |
| map | key-value,key必须为原始类型,value可以任意类型 | map(‘a’,1,’b’,2) |
| struct | 字段集合,类型可以不同 | struct(‘1’,1,1.0), named_stract(‘col1’,’1’,’col2’,1,’clo3’,1.0) |
二、存储格式
Hive会为每个创建的数据库在HDFS上创建一个目录,该数据库的表会以子目录形式存储,表中的数据会以表目录下的文件形式存储。对于default数据库,默认的缺省数据库没有自己的目录,default数据库下的表默认存放在/user/hive/warehouse目录下。
textfile
textfile为默认格式,存储方式为行存储。数据不做压缩,磁盘开销大,数据解析开销大。
SequenceFile
SequenceFile是Hadoop API提供的一种二进制文件支持,其具有使用方便、可分割、可压缩的特点。
SequenceFile支持三种压缩选择:NONE, RECORD, BLOCK。 Record压缩率低,一般建议使用BLOCK压缩。
RCFile
一种行列存储相结合的存储方式。
ORCFile
数据按照行分块,每个块按照列存储,其中每个块都存储有一个索引。hive给出的新格式,属于RCFILE的升级版,性能有大幅度提升,而且数据可以压缩存储,压缩快 快速列存取。
Parquet
Parquet也是一种行式存储,同时具有很好的压缩性能;同时可以减少大量的表扫描和反序列化的时间。
三、数据格式
当数据存储在文本文件中,必须按照一定格式区别行和列,并且在Hive中指明这些区分符。Hive默认使用了几个平时很少出现的字符,这些字符一般不会作为内容出现在记录中。
Hive默认的行和列分隔符如下表所示。
| 分隔符 | 描述 |
|---|---|
| \n | 对于文本文件来说,每行是一条记录,所以\n 来分割记录 |
| ^A (Ctrl+A) | 分割字段,也可以用\001 来表示 |
| ^B (Ctrl+B) | 用于分割 Arrary 或者 Struct 中的元素,或者用于 map 中键值之间的分割,也可以用\002 分割。 |
| ^C | 用于 map 中键和值自己分割,也可以用\003 表示。 |
参考目录
Hive - 介绍: http://codingdict.com/article/8150
Hive入门及常用指令:https://blog.csdn.net/ddydavie/article/details/80667727
Hive教程(一) Hive入门教程:https://blog.csdn.net/yuan_xw/article/details/78197917
hive学习----Hive表的创建:https://www.cnblogs.com/fnlingnzb-learner/p/12217162.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号