
爬虫入门
参考地址:
celery 分布式爬虫
https://www.jianshu.com/p/e5539d96641c
https://github.com/SpiderClub/weibospider
分布式、增量爬虫:https://www.cnblogs.com/zhangqing979797/p/10479120.html#autoid-0-2-0
Scrapy-Redis详解:https://cuiqingcai.com/6058.html
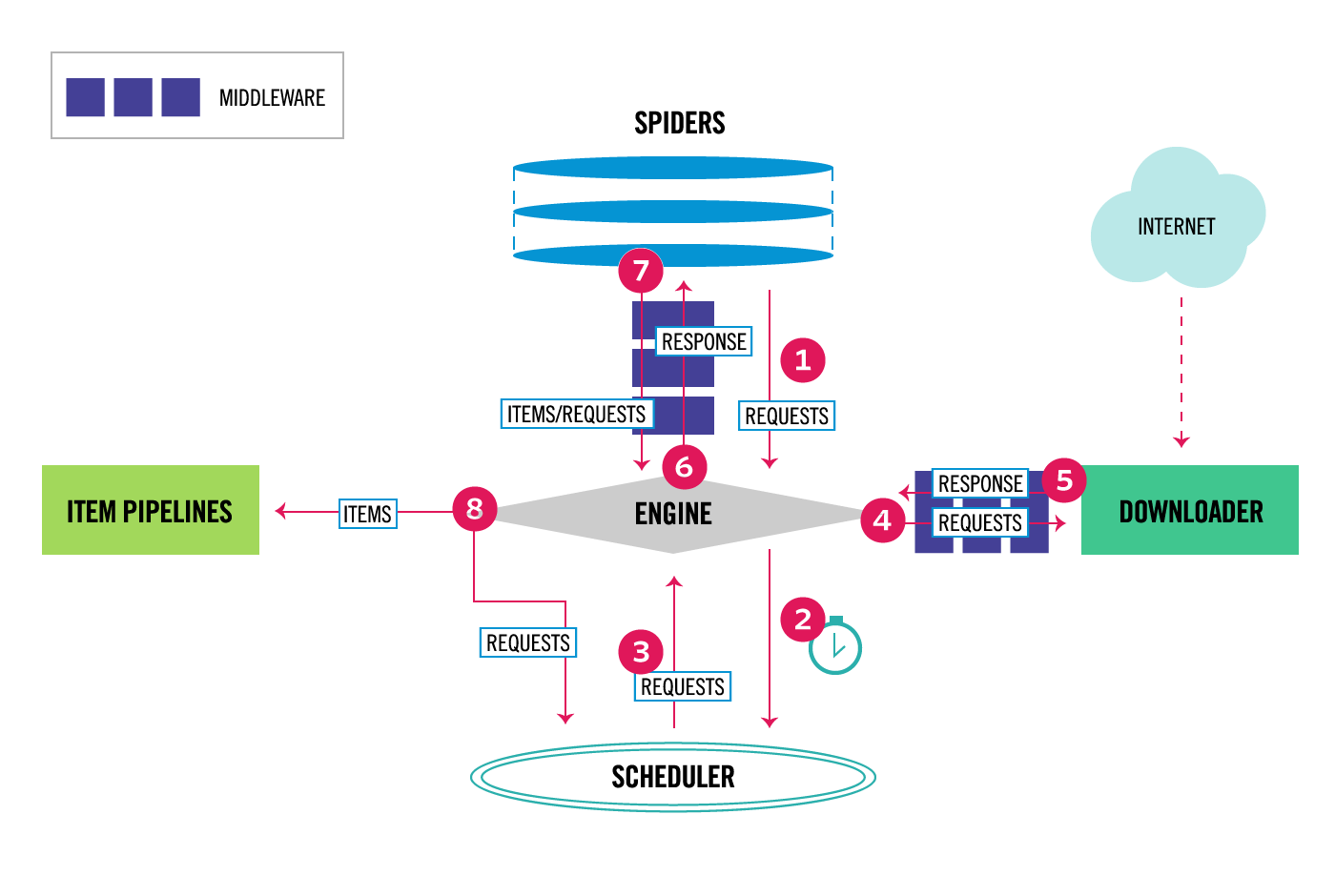

增量爬取和去重
作者:yuanquan521
链接:https://www.jianshu.com/p/be013900326b
来源:简书
增量爬取
当一个站点有数据更新的时候,需要进行增量爬取,通常有以下集中情况
-
某个特定页面数据更新
-
新增了页面
情况1的时候,我们对此特定页面的内容做哈希,当然要去除动态变化的那一部分,比如有的页面有验证码或者日期,程序定期执行,在执行的最开始检测此页面的哈希值跟上次抓取是否有变化,如果有变化就开始抓取。
情况2的时候,我们会对页面入口内容做哈希,并且存储分页面的URL哈希值,如果页面入口哈希值发生变化,获取新增的页面url列表,在这里需要用到url的去重,和数据去重类似,采用redis集合类型处理。
redis集合类型不允许添加重复的数据,当添加重复的时候时,返回0,并且添加失败。我们将所有的url list存入redis集合,当页面入口变化时,进行页面url去重,只抓取新增的页面。
爬取结果去重
结果去重常用的有两种方法:
- 布隆过滤器
- redis集合
redis集合
使用redis集合去重能够支持多线程多进程.
利用redis集合无重复数据的特点,在redis建立集合,往其中添加数据的sha1值,添加成功返回1,表示无重复,添加失败返回0,表示集合中已经有重复数据
使用: 步骤:1. 建立redis连接池 2. 重复检查
下面的例子是接口,并提供example。
[Redis] server=192.168.0.100 pass=123@123 # -*- coding:utf-8 -*- """ File Name : 'distinct'.py Description: Author: 'chengwei' Date: '2016/6/2' '11:45' python: 2.7.10 """ import sys import hashlib import os import codecs import ConfigParser import redis reload(sys) sys.setdefaultencoding('utf-8') """ 利用redis的集合不允许添加重复元素来进行去重 """ def example(): pool, r = redis_init() temp_str = "aaaaaaaaa" result = check_repeate(r, temp_str, 'test:test') if result == 0: # do what you want to do print u"重复" else: # do what you want to do print u"不重复" redis_close(pool) def redis_init(parasecname="Redis"): """ 初始化redis :param parasecname: :return: redis连接池 """ cur_script_dir = os.path.split(os.path.realpath(__file__))[0] cfg_path = os.path.join(cur_script_dir, "db.conf") cfg_reder = ConfigParser.ConfigParser() secname = parasecname cfg_reder.readfp(codecs.open(cfg_path, "r", "utf_8")) redis_host = cfg_reder.get(secname, "server") redis_pass = cfg_reder.get(secname, "pass") # redis pool = redis.ConnectionPool(host=redis_host, port=6379, db=0, password=redis_pass) r = redis.Redis(connection_pool=pool) return pool, r def sha1(x): sha1obj = hashlib.sha1() sha1obj.update(x) hash_value = sha1obj.hexdigest() return hash_value def check_repeate(r, check_str, set_name): """ 向redis集合中添加元素,重复则返回0,不重复则添加成功,并返回1 :param r:redis连接 :param check_str:被添加的字符串 :param set_name:项目所使用的集合名称,建议如下格式:”projectname:task_remove_repeate“ :return: """ hash_value = sha1(check_str) result = r.sadd(set_name, hash_value) return result def redis_close(pool): """ 释放redis连接池 :param pool: :return: """ pool.disconnect() if __name__ == '__main__': example()
适合存储大量爬虫数据的数据库
作者:benny
来源:腾讯云
连接:https://cloud.tencent.com/developer/article/1166276
What's NoSQL
关系型数据库一直是计算机相关专业的必修课, 在过去的很长时间, 占据了互联网数据量的很大一部分. 但是随着大数据时代到来, 关系型数据库已然满足不了某些大数据的处理要求.


NoSQL,指的是非关系型的数据库。NoSQL也称作Not Only SQL的缩写,是对不同于传统的关系型数据库的数据库管理系统的统称。
NoSQL用于超大规模数据的存储。这些类型的数据存储不需要固定的模式,无需多余操作就可以横向扩展。
What's MongoDB
- MongoDB是一种非关系型数据库, 是一个面向文档存储的数据库,操作起来比较简单和容易.
- 可以通过本地或者网络创建数据镜像,这使得MongoDB有更强的扩展性.
- MongoDB支持RUBY,Python,Java,C++,PHP,C#等多种语言
- Mongo支持丰富的查询表达式。查询指令使用JSON形式的标记,可轻易查询文档中内嵌的对象及数组
- 内建支持Map和Reduce函数, 可对数据进行批量和聚合操作.
Why MongoDB
将目光放在MongoDB这样的文档型NoSQL身上, 是因为爬取的数据
- 对一致性要求不高
- 读写的速度要求较高
- 遇到数据字段发生变化时, 可以更方便的添加字段, 无需改变以前的数据结构.
How TO
Step 1 安装MongoDB
安装MongoDB, 参考文档https://docs.mongodb.com/manual/administration/install-community/
安装pymongo, 如果你使用pip安装方式, 直接在终端中键入 pip install pymongo
安装成功的检测, 在python的shell中 importpymongo不报错即可.
Step 2 添加项目配置
添加配置信息 在Scrapy项目的 settings.py中添加以下代码
MONGO_HOST = "127.0.0.1" #主机IP
MONGO_PORT = 27017 #端口号
MONGO_DB = "Spider" #库名
MONGO_COLL = "jobinfo" #collection名
# MONGO_USER = ""
# MONGO_PSW = ""
代码片中的端口号为默认端口号, 如果安装后进行了修改, 以修改后为准, 库名及Collection名同上.
MongoDB支持动态创建, 因此你并不需要提前创建数据库和下属的Collection
Step 3 启用MongoDB存储Pipeline
在你Scrapy项目的 pipelines.py中添加以下的方法(注意函数要写在某个Pipeline类中, 并在 settings.py中启用对应的Pipeline, 如果你已经启用, 直接添加即可):
# 在Python中使用mongoDB的所需的包 import pymongo # 配置mongoDB所需的包 from scrapy.conf import settings def __init__(self): # connect to db self.client = pymongo.MongoClient(host=settings['MONGO_HOST'], port=settings['MONGO_PORT']) # ADD if NEED account and password # 当需要使用数据库的用户名和密码, 取消以下的注释, MongoDB支持直接查询, 无需登录 # self.client.admin.authenticate(host=settings['MONGO_USER'], settings['MONGO_PSW']) # 设置数据库客户端类型 self.db = self.client[settings['MONGO_DB']] # 取得数据库句柄 self.coll = self.db[settings['MONGO_COLL']] 然后在同个文件下处理item的函数末尾中添加以下代码: def process_item(self, item, spider): # ..... postItem = dict(item) self.coll.insert(postItem) # 在终端中显示你的爬取数据 return item
Step 4 Enjoy
在终端中运行你的爬虫, 待数据爬取完毕, Spider迅速关闭, 而数据已经写入数据库! 在终端中键入
# 切换数据库 use Spider # 查找所有数据, pretty()函数用于格式化数据显示 # jobinfo为collection名称 db.jobinfo.find().pretty()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号