
Python笔记(三)
在昨天的《Python笔记(二)》中我们学习了函数的定义和使用。在最后,简单介绍了文档字符串(DocString)的使用,由于昨天时间比较急关于它的知识我总结的比较少,今天在这里稍微补充一下吧。DocString不仅适用于函数,也适用于模块和类(模块在今天的博客中会介绍)。文档字符串的惯例是一个多行字符串,它的首行以大写字母开始,句号结尾。第二行是空行,从第三行开始详细的概述。我在昨天的博客中使用了__doc__(注意是双下划线)调用了printMax()函数的文档字符串属性。对于文档字符串就补充这么多吧。下面开始今天的学习。
今天我学习了Python中的模块以及数据结构。下面先说模块。Python中模块的作用和C中的.h文件以及Java中的包的作用类似。使用模块你可以重复的使用其他程序中的函数和变量。下面这段代码我们作为模块:
1 #T.py 2 def main(): 3 print("I am main()") 4 5 date = '''2015/5/22'''
而在下面这段代码中我们使用import关键字引入模块,然后调用main()函数以及date变量:
1 #TT.py 2 import T 3 4 T.main() 5 print(T.date)
打印结果如下:

是不是有点似曾相识的感觉?刚刚说了,Python中的模块的作用和C中的.h文件以及JAVA中的包差不多。可能有人在想,如果我导入的一个模块内容很大,那么程序在运行的时候就是一件比较费时的事情。这个问题不用但心,在Python中为了让输入模块更加快捷,有一种方法是创建字节编译文件,这些文件以.pyc作为扩展名,我们在第一次使用模块的时候,会自动生成.pyc文件,这样的话,在我们下一次从别的程序输入这个模块的时候,.pyc文件就起作用了——它会快很多。另外一点是:这些字节文件与平台无关。在上面的代码中,我们使用import关键字将T.py文件中所有的内容都导入了,如果你只是想导入一部分函数或者变量,那么请使用下面的格式:from...import,但是书上建议我们避免使用这种方式,因为这种方式容易有名称上的冲突。
下面来说说模块的__name__属性。每个模块都有一个名称,在模块中可以通过语句来找出模块的名称。如果程序本身调用__name__属性,那么将会得到'__main__'字符串来标示自己,而在程序中调用其他模块并打印其__name__属性,那么将会得到那个模块的文件名。请看下面这段代码:
1 #module.py 2 3 def main(): 4 print('we are in %s'%__name__) 5 6 if __name__ == '__main__': 7 main()
在上面,我们定义了一个函数main(),用来打印出__name__属性。下面的if语句用来判断是否执行main()。下面是打印结果: 
从结果我们可以看出,在自己的程序中使用__name__属性打印的是'__main__'。在看下面这段代码:
1 #othermodule.py 2 import module #将模块module导入 3 4 module.main()
再看它打印出来的结果:

从两个结果对比便可验证我们上面所说的结论。对于模块,我们应该将这个模块放置在我们输入它的程序的同一目录中或者sys.path所列目录之一。
下面介绍Python中的序列。在Python中,序列包括:列表、元组、字典。
列表(list):处理一组有序项目的数据结构。和Java中的list接口类似,Python中列表中的项目应该包括在方括号中,并且项目之间由逗号(,)隔开。不过Python中的list和Java中的list还是有一定的区别。在Java中,为了数据的安全性,引入了泛型。在Java的集合框架中,泛型规定放入同一个集合对象的元素必须是同一类型的。而在Python中我们所说的列表是可变数据类型的,也就是说我们可以在列表中添加任何种类的对象,甚至其他列表。请看下面代码:
1 numberlist = [10,19,6,3,7,21,35] #定义一个列表 2 3 print('numberlist have %d numbers.'%len(numberlist)) 4 print('all of them are: ',end="") 5 for i in numberlist: #遍历 6 print(i,end=",") 7 8 print("now,I will add more numbers.") 9 numberlist.append(72); #添加同类型元素 10 numberlist.append('zhouxy');#添加不同类型元素 11 12 print('\nyes.numberlist have %d numbers.'%len(numberlist)) 13 print('all of them are: ',end="") 14 for i in numberlist: #遍历新的列表 15 print(i,end=",") 16 print("\nOK!")
上面的代码中我们初始化了一个列表numberlist,然后对它进行遍历,之后向他里面添加了新的元素,有同类型的元素,也有不同类型的元素。之后再遍历新的列表。结果如下:
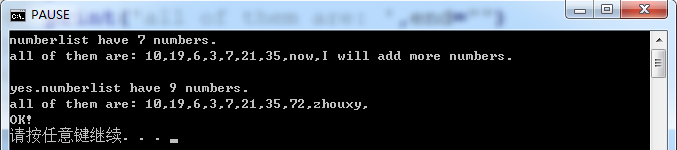
在上面我们使用了list的内置函数append()增加元素,如果你不知道list中有哪些函数,那么你可以使用help()命令。例如我这样:
元组:元组和列表十分类似,只不过元组和字符串一样是不可变的,也就是说你不能像列表一样修改元组。元组通过圆括号中用逗号分割项目定义。先看下面这段代码:
1 animal = ('cat','dog','pig') #初始化一个元组 2 print("number of animal is :",len(animal)) 3 4 new_animal = ('bird','monkey',animal) #创建一个新的元组,并将元组animal添加进去 5 print("number of animal is :",len(new_animal)) 6 7 print("all animal are:",animal) 8 print("all new_animal are:",new_animal) 9 10 print("new_animal[2] is:",new_animal[2]) 11 print("new_animal[2][2] is:",new_animal[2][2])
在上面的代码中,我们通过了一对方括号来指明某个项目的位置从而来访问元组中的项目,这被称作索引运算符。值得注意的是:一个空的元组由一对空()组成。然而单个元素的元组你必须在第一个元素之后加上逗号(,),就像这样:singleton = (2,)。下面是运行结果: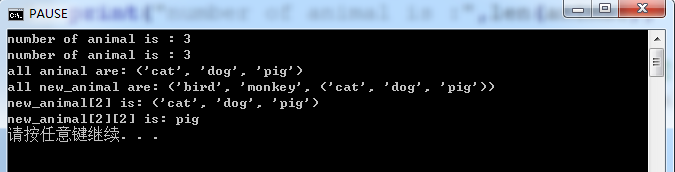
最后说说序列中的字典。字典:Python中字典和Java中的map类似,是键值对的存储形式。首先来看看Python中的字典是如何标记的,形式如下:dict={key1:value1,key2:value2}。注意它们的键值对用冒号分割,而各个对则用逗号分割,所有的这些都包括在花括号中,并且字典中的键值对是没有顺序的。如果你想它们有顺序,那么在使用前可以对它们进行排序。请看下面代码:
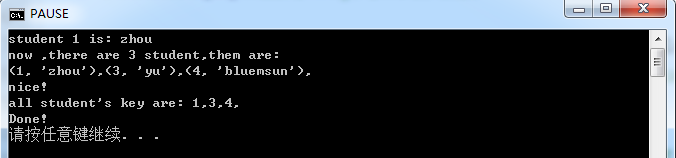
1 student = {1:'zhou',2:'xuan',3:'yu'} 2 print("student 1 is: %s"%student[1]) 3 4 student[4] = 'bluemsun'#添加新元素 5 del student[2]#删除key为2的元素 6 7 print("now ,there are %d student,them are:"%len(student),end="\n") 8 for key,value in student.items():#遍历字典student 9 print((key,value),end=",") 10 11 if 3 in student:#or student.has_key(3),判断某个学生是否在字典中 12 print("\nnice!") 13 14 allkeys = student.keys() 15 print("all student's key are: ",end='') 16 for key in allkeys: 17 print(key,end=",") 18 print('\nDone!')
这段程序很简单,参看我的注释就可以明白。还记得昨天学习的关键字参数吗?如果你换一个角度看它的话,你就会恍然大悟,其实你已经使用了字典。下面是运行结果:
最后来说一说序列中的索引操作符和切片操作符。索引操作符让我可以从序列中抓取一个特定的项目,切片操作符让我们可以获取序列中的一个切片,即部分序列。请看下面这段代码:
1 #seq.py 2 3 list = ['apple','mango','carrot','banana','orang'] 4 #使用索引操作符抓取特定项目 5 print("list[2] is :" ,list[2]) 6 7 #使用切片操作符获取list切片 8 print('list[1] to list[3] are :',list[1:3]) 9 print('list[1] to list[4] are :',list[1:]) #从位置1一直到最后 10 print('list[0] to list[3] are :',list[:3]) #从位置0到位置3 11 print('list[1] to list[3] are :',list[1:-2]) #从位置0到list的倒数第2个 12 print('list[1] to list[3] are :',list[:]) #获取整个序列 13 14 #使用切片操作符获取string切片 15 name = 'bluemsun' 16 print('name[1] to name[3] are :',name[1:6]) 17 print('name[1] to name[4] are :',name[1:]) 18 print('name[0] to name[3] are :',name[:5]) 19 print('name[1] to name[3] are :',name[3:-2]) 20 print('name[1] to name[3] are :',name[:])
索引同样可以是负数,即位置是从序列尾开始计算的。切片操作符是序列名后跟一个方括号,括号中有一对可选的数字,并用冒号分割,冒号是必须的。

