
实验一:决策树算法实验
【实验目的】
- 理解决策树算法原理,掌握决策树算法框架;
- 理解决策树学习算法的特征选择、树的生成和树的剪枝;
- 能根据不同的数据类型,选择不同的决策树算法;
- 针对特定应用场景及数据,能应用决策树算法解决实际问题。
【实验内容】
- 设计算法实现熵、经验条件熵、信息增益等方法。
- 针对给定的房贷数据集(数据集表格见附录1)实现ID3算法。
- 熟悉sklearn库中的决策树算法;
- 针对iris数据集,应用sklearn的决策树算法进行类别预测。
【实验报告要求】
- 对照实验内容,撰写实验过程、算法及测试结果;
- 代码规范化:命名规则、注释;
- 查阅文献,讨论ID3、5算法的应用场景
实验过程
1.导包
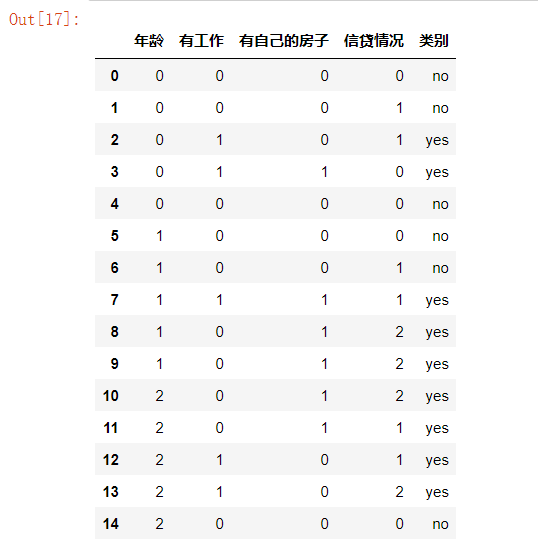
2.导入数据集

3.算法实现熵、经验条件熵、信息增益、决策树构建



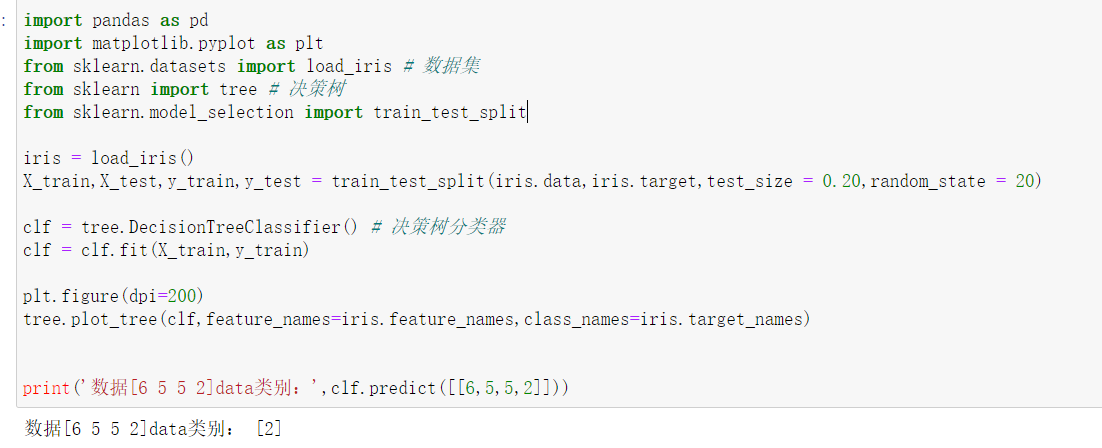
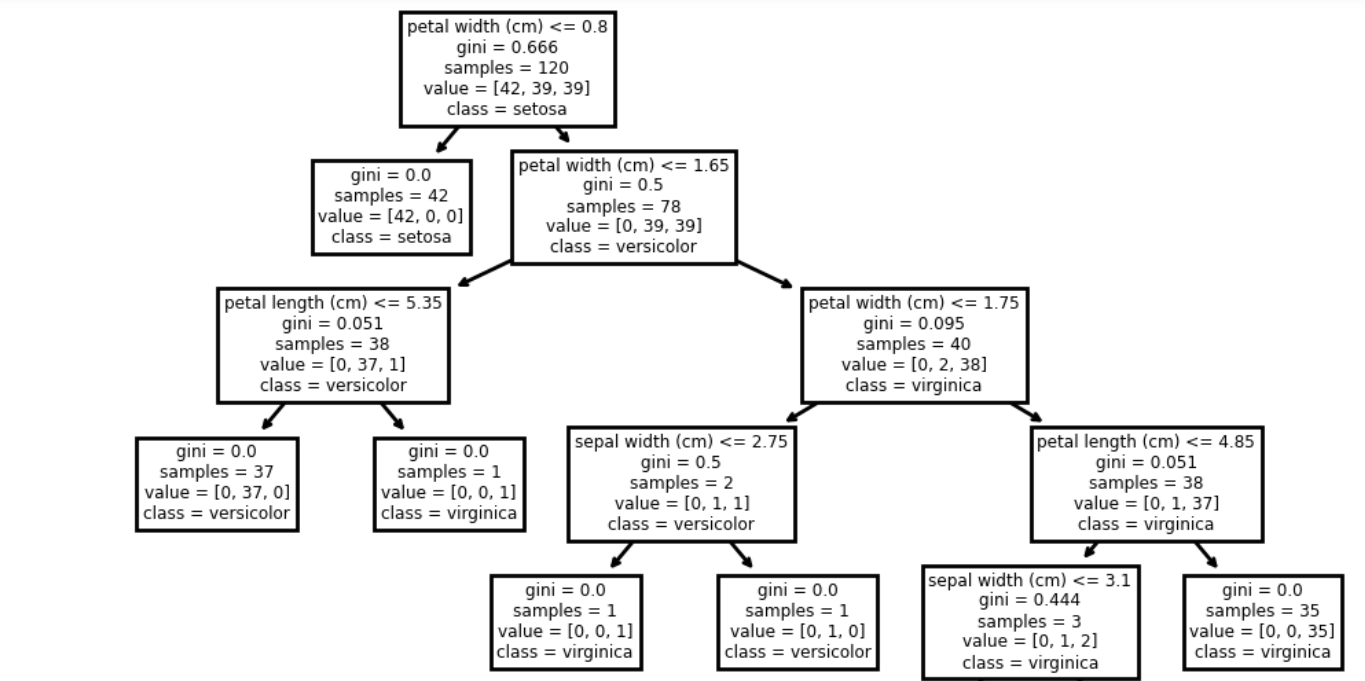
4.运用sklearn生成决策树



5.针对iris数据集,应用sklearn的决策树算法进行类别预测
实验总结
决策树的原理
1、 构造原理,如何构造出一个决策树,即选择哪些属性分别作为根节点、中间节点以及叶节点。
2、剪枝原理,即给决策树瘦身,把对分类效果促进不明显的节点取掉的过程,分为前剪枝和后剪枝两种。
- 前剪枝,即在构造决策树的过程中就进行剪枝。
- 后剪枝,即将决策树构造完毕后再进行剪枝。
ID3算法
1、 ID3算法是基于信息增益计算的,信息增益是指划分可以带来纯度的提高,信息熵的下降。
2、信息增益计算:是父亲节点和信息熵减去所以子结点的加权信息熵,这个权重系数为每个子结点在父节点出现的概率,即每个子结点的归一化信息熵。
3、计算公式:
4、计算每个属性的信息增益,选择信息增益最大的作为根节点即可,其他节点选择也类似。
5、 ID3算法的特点
优点:算法简单,可解释性强;
缺点:对噪声敏感,且倾向于选择取值比较多的属性,尽管某些属性可能对分类任务没有太大的作用,但依然被选作最优属性。
C4.5算法
1、C4.5算法是ID3算法的改进,具体的,有以下四方面的改进:
采用信息增益率而非信息增益,解决了ID3倾向于选择取值多属性的问题。信息增益率=信息增益/属性熵。
采用悲观剪枝(属于后剪枝技术),通过递归估算每个内部节点的分类错误率来判断是否对其进行剪枝,这种剪枝方法不再需要一个单独的测试数据集,解决了ID3构造决策树容易产生过拟合的情况,提升了决策树的泛化能力。
C4.5算法通过选择具有最高信息增益的划分所对应的阈值,可以离散化处理连续属性。
针对数据集不完整情况,即存在缺失值,C4.5可以进行处理,乘以加权系数即可。
2、 C4.5算法的特点:
优点:C4.5算法在ID3算法的基础上,用信息增益率代替了信息增益,解决了噪声敏感的问题;并且可以对构造树进行剪枝、处理连续属性以及数值缺失等情况;
缺点:C4.5算法需要对数据集进行多次扫面,算法效率相对较低。
(参考文献:https://blog.csdn.net/weixin_43851352/article/details/107309851)

